当前位置:网站首页>Apache dolphin scheduler system architecture design
Apache dolphin scheduler system architecture design
2022-07-05 09:51:00 【Yang Linwei】
List of articles
01 introduction
This paper is about
Apache DolphinSchedulerReading notes on the official website , Original address :https://dolphinscheduler.apache.org/
In the previous post 《Apache DolphinScheduler introduction ( One is enough )》 Generally speaking DolphinScheduler Some of the concepts of , There is an introductory concept . This article mainly talks about DolphinScheduler The system architecture design of .
Before the introduction of this article , Need to understand some basic concepts :
- DAG: Full name Directed Acyclic Graph, abbreviation DAG. In Workflow Task Tasks are assembled in the form of directed acyclic graphs , Topology traversal from the node with zero degree , Until there is no successor node . An example is shown below :
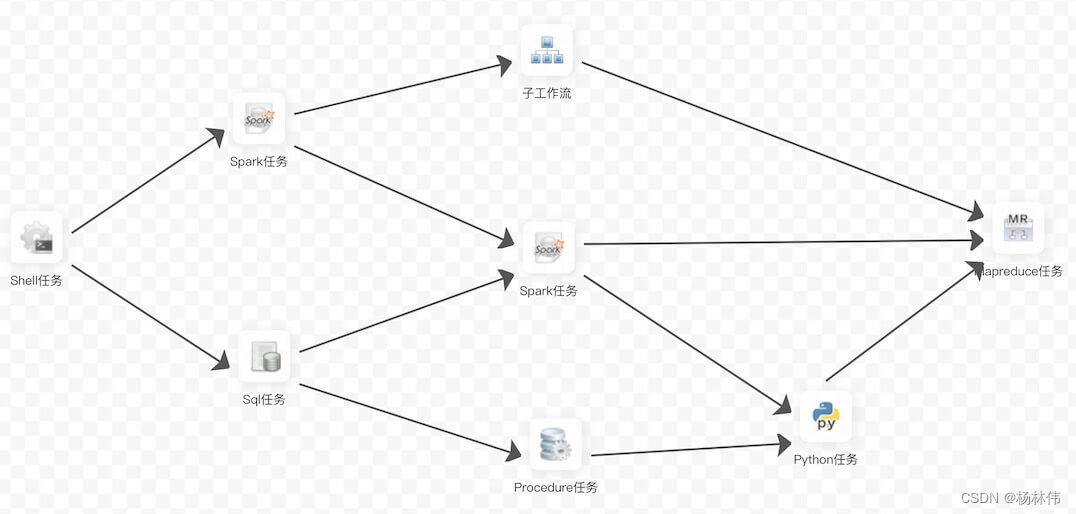
- Process definition : Visualization by dragging and dropping task nodes and establishing Association of task nodes DAG
- Process instance : A process instance is an instance of a process definition , It can be generated by manual startup or scheduled scheduling , Every time the process definition runs , Generate a process instance
- Task instance : A task instance is an instance of a task node in a process definition , Indicates the specific task execution status
- Task type : At present, there are SHELL、SQL、SUB_PROCESS( Sub process )、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT( rely on ), Also plan to support dynamic plug-in extensions , Be careful : One of them SUB_PROCESS It's also a separate process definition , It can be started separately
- Dispatch mode : System support is based on cron Regular scheduling and manual scheduling of expressions . Command types support : Start workflow 、 Execute from the current node 、 Restore the fault tolerant workflow 、 Resume the suspended process 、 Starting from the failed node 、 Complement number 、 timing 、 Heavy run 、 Pause 、 stop it 、 Thread recovery wait . among Restore the fault tolerant workflow and Thread recovery wait The two command types are used by the scheduling internal control , External cannot call
- Timing schedule : System USES quartz Distributed scheduler , And at the same time support cron Generation of expression visualization
- rely on : The system doesn't just support DAG Simple dependencies between predecessor and successor nodes , It also provides task dependent nodes , Support custom task dependencies between processes
- priority : Support the priority of process instances and task instances , If the priority of process instance and task instance is not set , The default is FIFO
- Email alert : Support SQL Mission Query results are sent by email , Process instance running result email alarm and fault tolerance alarm notification
- Failure strategy : For tasks that run in parallel , If a mission fails , Provides two ways to handle failure strategies , Continue means that regardless of the status of parallel running tasks , Until the process fails . End means that once a failed task is found , At the same time Kill Drop running parallel tasks , The process failed
- Complement number : Fill in historical data , Support interval parallel and serial complement methods
02 System architecture
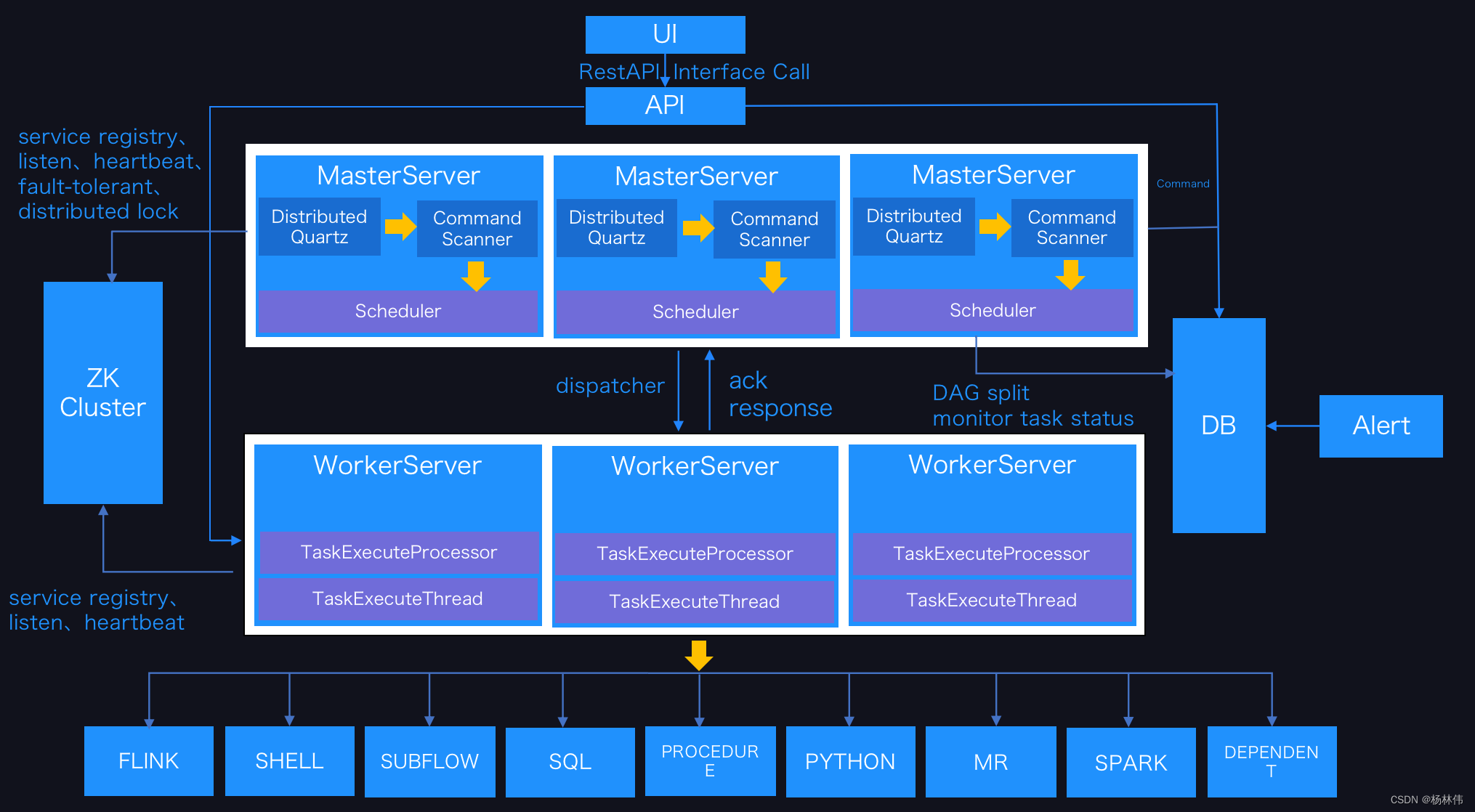
2.1 MasterServer
MasterServer Adopt the concept of distributed centerless design ,MasterServer Mainly responsible for DAG Task segmentation 、 Task submission monitoring , And listen to others at the same time MasterServer and WorkerServer Health status .
MasterServer When the service is started, it is directed to Zookeeper Register temporary nodes , By monitoring Zookeeper Temporary node changes for fault tolerance .
The service mainly includes :
- Distributed Quartz Distributed scheduling component , It is mainly responsible for the start and stop operation of timing tasks , When quartz When the mission is transferred ,Master The internal thread pool is responsible for the subsequent operation of the task
- MasterSchedulerThread It's a scanning thread , Scan the database regularly command surface , According to different command types, different business operations are carried out
- MasterExecThread Mainly responsible for DAG Task segmentation 、 Task submission monitoring 、 Logical processing of various command types
- MasterTaskExecThread Mainly responsible for task persistence
2.2 WorkerServer
WorkerServer It also adopts the concept of distributed centerless design ,WorkerServer Mainly responsible for the implementation of tasks and provide log services .WorkerServer When the service is started, it is directed to Zookeeper Register temporary nodes , And keep your heart beating .
The service contains :
- FetchTaskThread I'm mainly responsible for keeping from Task Queue Get the task , And call... According to different task types TaskScheduleThread Corresponding to the actuator .
- LoggerServer It's a RPC service , Provide log slice view 、 Refresh and download functions
2.3 ZooKeeper
ZooKeeper service , In the system MasterServer and WorkerServer All nodes pass through ZooKeeper For cluster management and fault tolerance . In addition, the system is based on ZooKeeper Event monitoring and distributed locking . We used to be based on Redis Over queuing , But we hope EasyScheduler Rely on as few components as possible , So at the end of the day Redis Realization .
2.4 Task Queue
Provide task queue operations , At present, queues are also based on Zookeeper To achieve . Because there is less information in the queue , Don't worry about too much data in the queue , In fact, we've tested millions of data storage queues , It has no effect on system stability and performance .
2.5 Alert
Provide alarm related interface , The interface mainly includes two types of alarm data storage 、 Query and notification function . The notification function includes email notification and SNMP( Temporary unrealized ) Two kinds of .
2.6 API
API The interface layer , Mainly responsible for processing the front end UI The request of the layer . The service is provided uniformly RESTful api Providing request services to the outside world . The interfaces created include 、 Definition 、 Inquire about 、 modify 、 Release 、 Offline 、 Manual start 、 stop it 、 Pause 、 recovery 、 Starting from this node and so on .
2.7 UI
The front page of the system , Various visual interfaces provided by the operating system , See [ Function is introduced ] part .
04 Architectural thinking
4.1 Central thinking
The design concept of centralization is relatively simple , Nodes in a distributed cluster are divided according to their roles , In general, there are two roles :
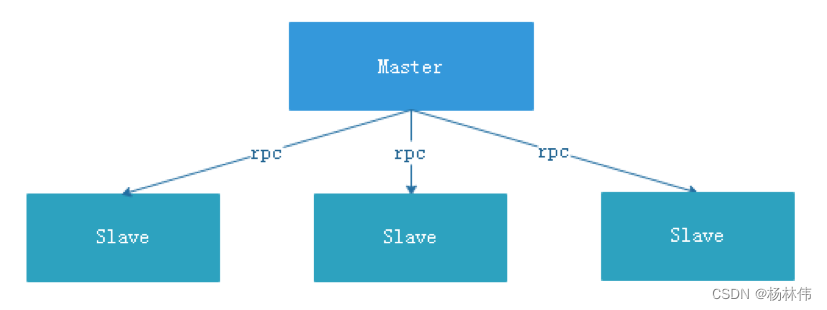
- Master Is responsible for the task distribution and supervision Slave Health status , Can dynamically balance tasks to Slave On , So that Slave Nodes are not “ Busy to die ” or ” Idle death ” The state of .
- Worker Is responsible for the execution of tasks and maintenance and Master The heart of , In order to Master You can assign tasks to Slave.
There are some problems in the design of centralization thought :
- once Master There is a problem , Then there is no leader , The whole cluster will crash . To solve this problem , majority Master/Slave The architecture mode adopts the master / slave mode Master The design of , It can be hot standby or cold standby , It can also be automatic switching or manual switching , And more and more new systems are beginning to have automatic election switching Master The ability of , To improve the usability of the system .
- Another problem is if Scheduler stay Master On , Although it can support a DAG Different tasks run on different machines in , But it will Master Over load of . If Scheduler stay Slave On , Is a DAG All tasks in can only be submitted on one machine , When there are more parallel tasks ,Slave The pressure may be greater .
4.2 Decentralized thinking
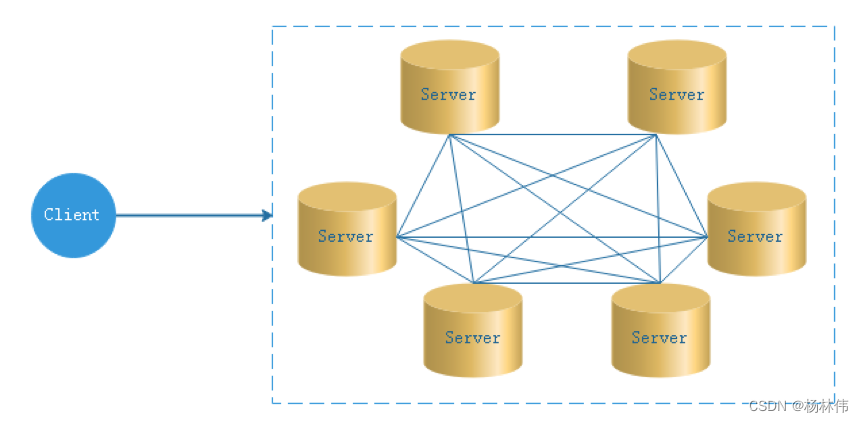
In decentralized design , Usually not Master/Slave The concept of , All the characters are the same , Status is equal , The global Internet is a typical decentralized distributed system , Any node device connected to the network down machine , Will only affect a very small range of functions .
The core design of decentralized design is that there is no one different from other nodes in the whole distributed system ” managers ”, So there is no single point of failure . But because there is no ” managers ” Nodes, so each node needs to communicate with other nodes to get the necessary machine information , And the unreliable line of distributed system communication , It greatly increases the difficulty of the above functions .
actually , Truly decentralized distributed systems are rare . On the contrary, dynamic centralized distributed systems are emerging . In this framework , The managers in the cluster are selected dynamically , Instead of preset , And when the cluster fails , Nodes in the cluster will spontaneously hold " meeting " To vote for a new " managers " To take charge of the work . The most typical case is ZooKeeper And Go The realization of language Etcd.
EasyScheduler Decentralization is Master/Worker Sign up to Zookeeper in , Realization Master Clusters and Worker The cluster has no center , And use Zookeeper Distributed locks to elect one of them Master or Worker by “ managers ” To perform the task .
4.3 Distributed lock practice
EasyScheduler Use ZooKeeper Distributed lock to achieve only one at a time Master perform Scheduler, Or just one Worker Submission of execution tasks .
The core process algorithm of obtaining distributed lock is as follows :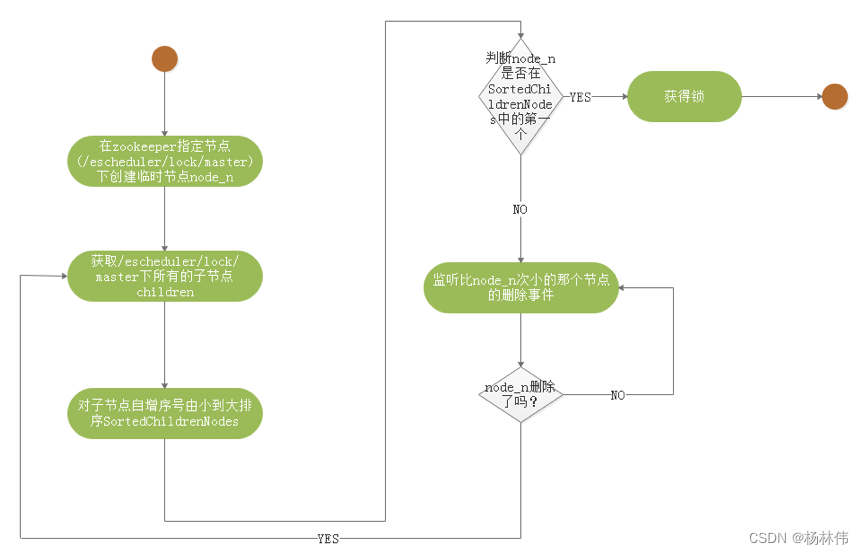
EasyScheduler in Scheduler Flow chart of thread distributed lock implementation :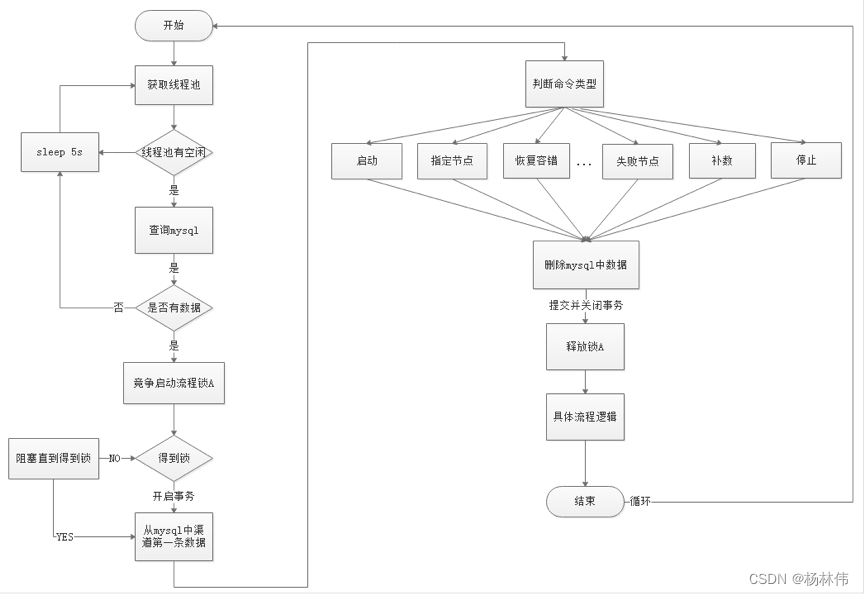
4.4 Thread shortage, loop waiting problem
If one DAG There are no subprocesses in , If Command The number of data in is greater than the threshold set by the thread pool , Then the direct process waits or fails .
If a big one DAG Many subprocesses are nested in , The following figure will produce “ Death etc. ” state :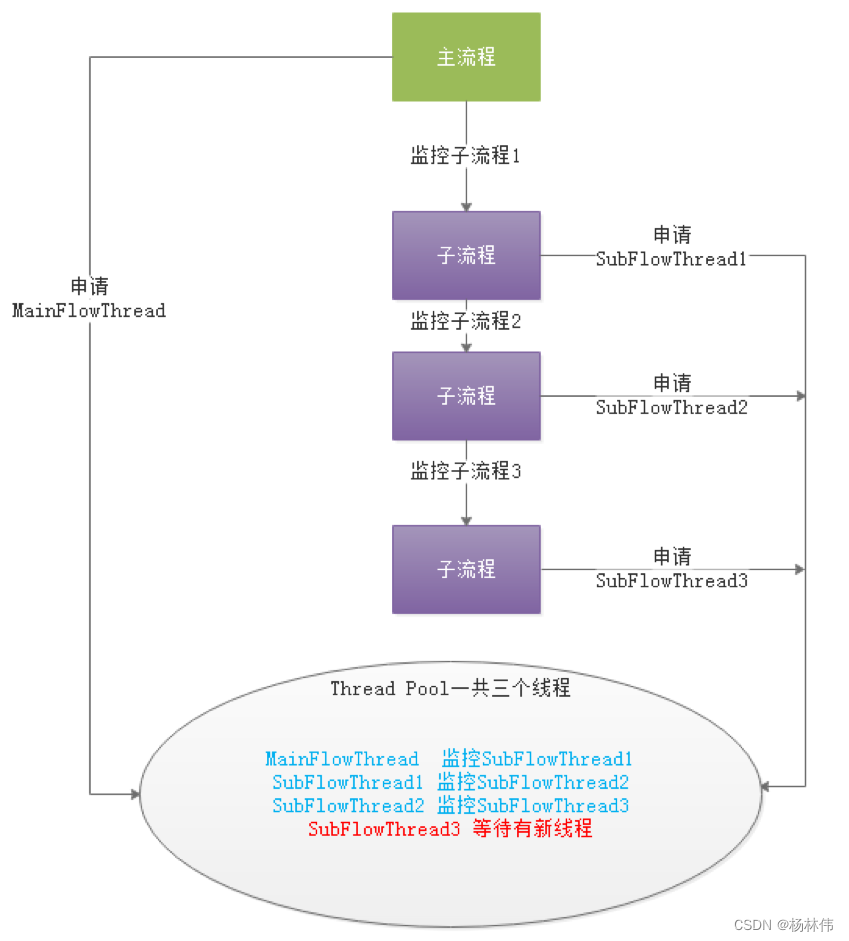
Above picture MainFlowThread wait for SubFlowThread1 end ,SubFlowThread1 wait for SubFlowThread2 end , SubFlowThread2 wait for SubFlowThread3 end , and SubFlowThread3 Waiting for a new thread in the thread pool , Then the whole DAG The process can't end , As a result, the thread cannot be released . In this way, the waiting state of the child parent process loop is formed . At this point, unless you start a new Master To add threads to break this ” deadlock ”, Otherwise, the scheduling cluster will no longer be available .
For starting a new Master To break the ice , It seems to be a bit unsatisfactory , So we propose three ways to reduce this risk :
- Calculate all Master The total number of threads , And then for every one of them DAG Need to calculate the number of threads it needs , That is to say DAG Pre calculation before process execution . Because there are so many Master Thread pool , So it's impossible to get the bus number in real time .
- To single Master Thread pool to judge , If the thread pool is full , Let the thread fail directly .
- Add a resource deficient Command type , If the thread pool is insufficient , Then suspend the main process . In this way, the thread pool has new threads , It is possible to wake up the suspended process due to insufficient resources .
Be careful :Master Scheduler The thread is getting Command The time is FIFO In the form of .
So we chose the third way to solve the problem of insufficient threads .
4.5 Fault tolerant design
Fault tolerance is divided into service downtime fault tolerance and task retrial , Service failure tolerance is divided into Master Fault tolerance and Worker Fault tolerance in two cases
4.5.1 Failure tolerance
Service fault tolerance design depends on ZooKeeper Of Watcher Mechanism , The implementation principle is shown in the figure :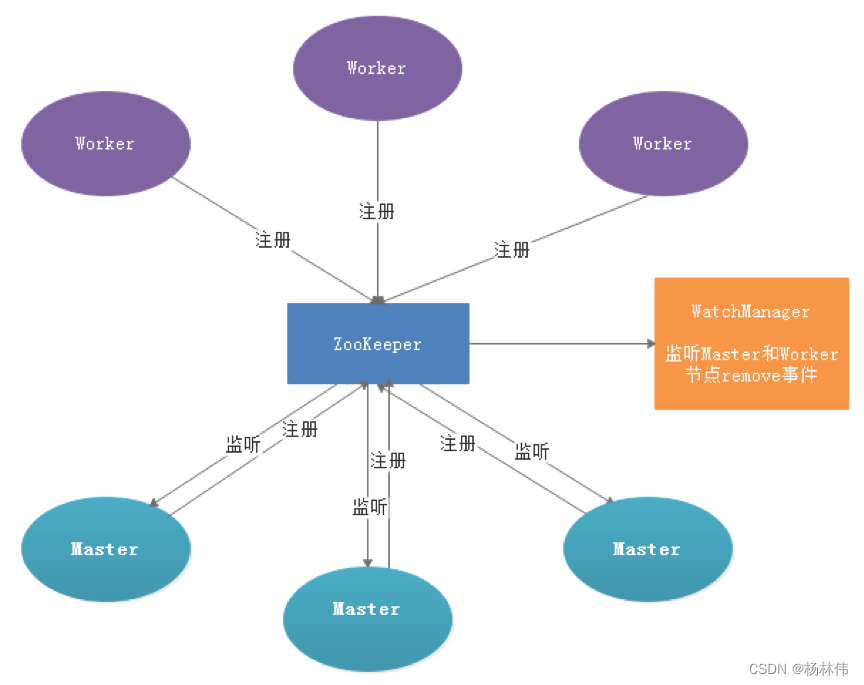
among Master Monitoring other Master and Worker The catalog of , If it detects remove event , Process instance fault tolerance or task instance fault tolerance will be carried out according to specific business logic .
Master Fault tolerant flowchart :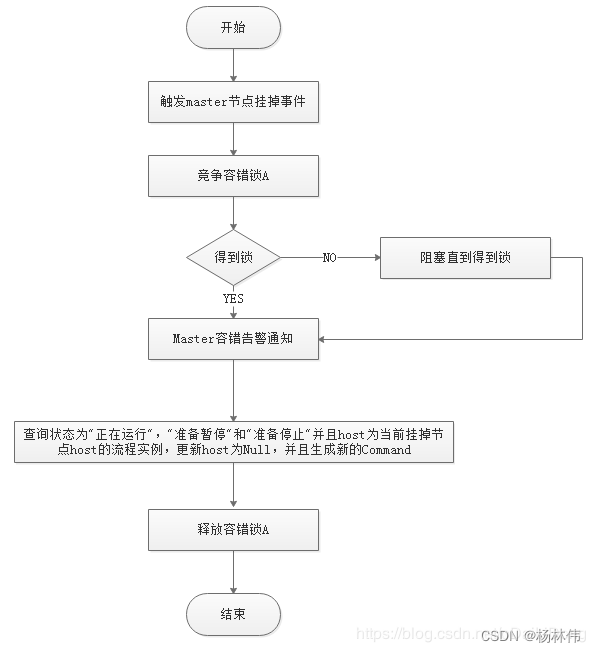
ZooKeeper Master After the fault tolerance is completed, it will be replaced by EasyScheduler in Scheduler Thread scheduling , Traverse DAG find ” Running ” and “ Submit successfully ” The task of , Yes ” Running ” Monitor the status of its task instances , Yes ” Submit successfully ” We need to judge Task Queue Is there already , If it exists, the status of the task instance is also monitored , If it doesn't exist, re submit the task instance .
Worker Fault tolerant flowchart :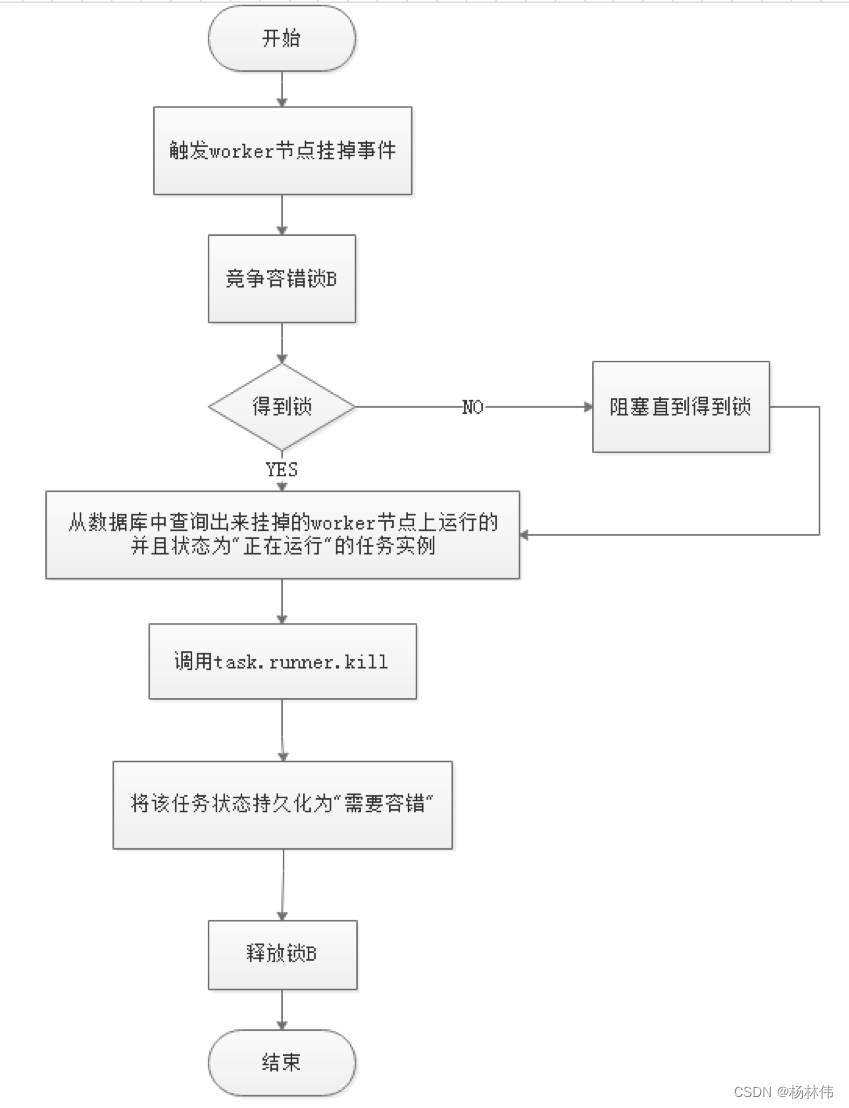
Master Scheduler Once the thread finds that the task instance is ” Need fault tolerance ” state , Then take over the task and re submit it .
Be careful : because ” The network jitter ” The node may lose and ZooKeeper The heart of , So the node's remove event . In this case , We use the simplest way , That is, once the node and ZooKeeper Timeout connection occurred , Will directly Master or Worker Service stopped .
4.5.2 Task failed retry
First of all, we need to distinguish the task failure and try again 、 Process failure recovery 、 The concept of process failure and rerun :
- The task failed to try again is task level , It's done automatically by the scheduling system , For example, a Shell Task set the number of retries to 3 Time , So in Shell If the task fails, it will try to run it again at most 3 Time
- Process failure recovery is process level , It's done manually , Recovery is performed only from the failed node or from the current node
- Process failure and rerun is also process level , It's done manually , The rerun starts at the starting point
Let's get to the point , We divide the task nodes in workflow into two types .
- One is the business node , This kind of node corresponds to an actual script or processing statement , such as Shell node ,MR node 、Spark node 、 Dependent nodes, etc .
- There is also a logical node , This kind of node does not do actual script or statement processing , It is just the logical processing of the whole process flow , For example, subprocess section, etc .
Each business node can configure the number of failed retries , When the task node fails , Will automatically retry , Until it succeeds or exceeds the configured number of retries . Logical node does not support failure retry . But the tasks in the logical node support retrying .
If a task fails in the workflow, the maximum number of retries is reached , The workflow will fail and stop , Failed workflow can be manually rerun or process recovery operations
5. Task priority design
The situation of completing tasks at the same time , You can't set the priority of a process or task , So we redesigned it , At present, we design as follows :
According to the priority of different process instances over the same process instance, the task priority within the same process is prior to the task submission within the same process, and the task is processed from high to low .
The specific implementation is based on the task instance json Parsing priorities , Then prioritize the process instances _ Process instance id_ Task priority _ Mission id The information is kept in ZooKeeper In the task queue , When fetching from a task queue , Through string comparison, we can get the most priority task to be executed
The priority of process definition is to consider that some processes need to be processed before others , This can be configured when the process is started or scheduled , share 5 level , In turn HIGHEST、HIGH、MEDIUM、LOW、LOWEST. Here's the picture

The priority of tasks is also divided into 5 level , In turn HIGHEST、HIGH、MEDIUM、LOW、LOWEST. Here's the picture 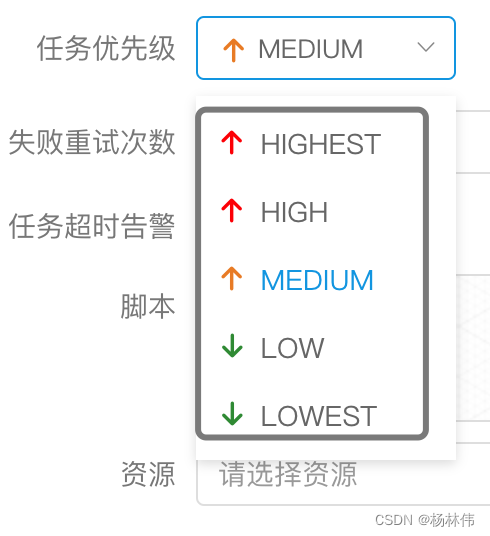
6. Logback and gRPC Achieve log access
because Web(UI) and Worker Not necessarily on the same machine , So you can't view a log like you would a local file . There are two options :
Put the log in ES On search engines
adopt gRPC Communication to obtain remote log information
Between considering as much as possible EasyScheduler The lightness of , So I chose gRPC Realize remote access to log information .
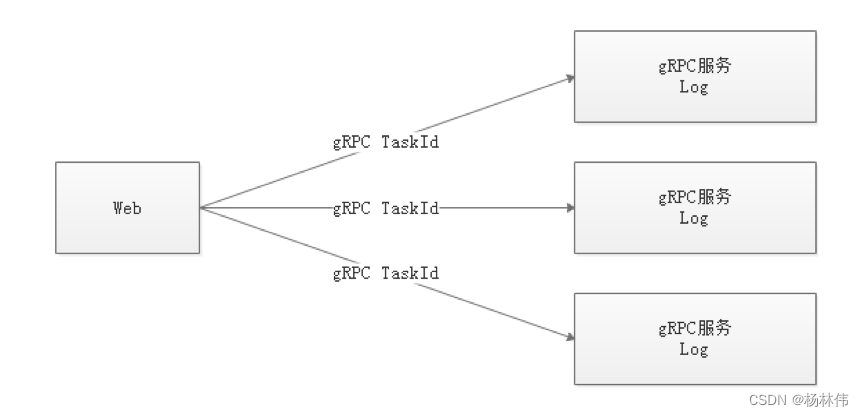
We use custom Logback Of FileAppender and Filter function , Each task instance generates a log file .
FileAppender The main implementation is as follows :
/** * task log appender */
public class TaskLogAppender extends FileAppender<ILoggingEvent> {
...
@Override
protected void append(ILoggingEvent event) {
if (currentlyActiveFile == null){
currentlyActiveFile = getFile();
}
String activeFile = currentlyActiveFile;
// thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
String threadName = event.getThreadName();
String[] threadNameArr = threadName.split("-");
// logId = processDefineId_processInstanceId_taskInstanceId
String logId = threadNameArr[1];
...
super.subAppend(event);
}
}
With / Process definition id/ Process instance id/ Task instance id.log Generate logs in the form of
Filter match to TaskLogInfo Start thread name :
TaskLogFilter The implementation is as follows :
/** * task log filter */
public class TaskLogFilter extends Filter<ILoggingEvent> {
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getThreadName().startsWith("TaskLogInfo-")){
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
}
边栏推荐
- 微信小程序获取住户地区信息
- Unity skframework framework (XXIII), minimap small map tool
- 卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
- 分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
- Roll up, break 35 - year - old Anxiety, animation Demonstration CPU recording Function call Process
- On July 2, I invite you to TD Hero online press conference
- 揭秘百度智能测试在测试自动执行领域实践
- Viewpager pageradapter notifydatasetchanged invalid problem
- Tutorial on building a framework for middle office business system
- [sourcetree configure SSH and use]
猜你喜欢
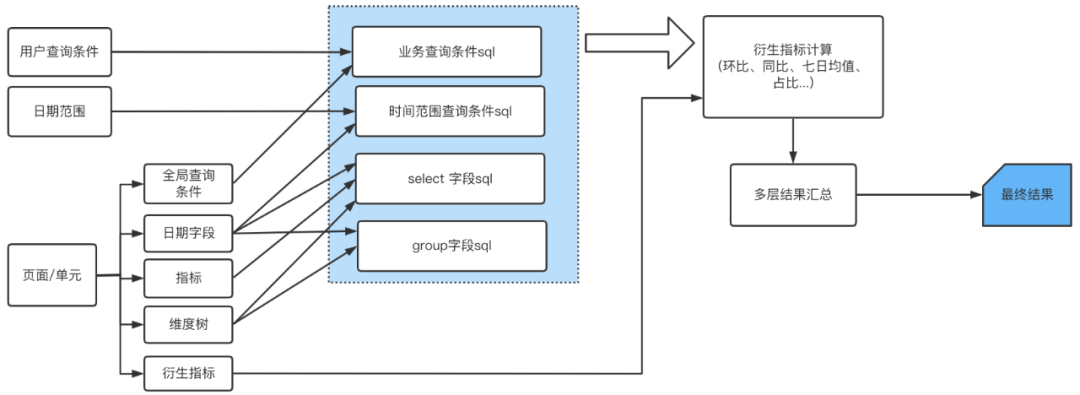
Data visualization platform based on template configuration
小程序启动性能优化实践
Unity SKFramework框架(二十二)、Runtime Console 运行时调试工具
Solve liquibase – waiting for changelog lock Cause database deadlock
Unity SKFramework框架(二十三)、MiniMap 小地图工具
初识结构体

7 月 2 日邀你来TD Hero 线上发布会
How to implement complex SQL such as distributed database sub query and join?
【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识
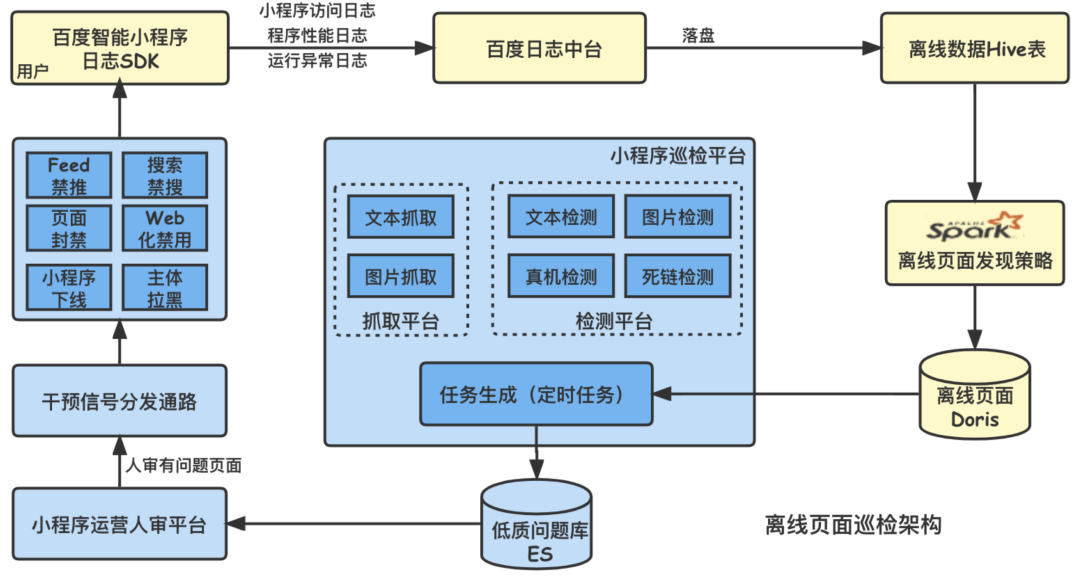
Evolution of Baidu intelligent applet patrol scheduling scheme
随机推荐
Unity skframework framework (XXIII), minimap small map tool
【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识
Evolution of Baidu intelligent applet patrol scheduling scheme
百度交易中台之钱包系统架构浅析
E-commerce apps are becoming more and more popular. What are the advantages of being an app?
Are databases more popular as they get older?
百度评论中台的设计与探索
[ManageEngine] how to make good use of the report function of OpManager
移动端异构运算技术-GPU OpenCL编程(进阶篇)
搞数据库是不是越老越吃香?
TDengine ×英特尔边缘洞见软件包 加速传统行业的数字化转型
Cross process communication Aidl
Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
TDengine可通过数据同步工具 DataX读写
Small program startup performance optimization practice
Common fault analysis and Countermeasures of using MySQL in go language
What are the advantages of the live teaching system to improve learning quickly?
Observation cloud and tdengine have reached in-depth cooperation to optimize the cloud experience of enterprises
Gradientdrawable get a single color
Unity skframework framework (XXII), runtime console runtime debugging tool