当前位置:网站首页>Reading the paper [sensor enlarged egocentric video captioning with dynamic modal attention]
Reading the paper [sensor enlarged egocentric video captioning with dynamic modal attention]
2022-07-07 05:34:00 【hei_ hei_ hei_】
Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
Summary
- publish :ACMM 2021
- Code :MMAC
- idea: This paper proposes a new video description task , Self centered visual description ( For example, first person perspective 、 Third person perspective ), It can be used for closer visual description . meanwhile , In order to alleviate motion blur caused by equipment and other reasons 、 Occlusion and so on , An auxiliary tool for visual description using sensors .
In network design , There are mainly two modules :AMMT Modules are used to merge visual features h v h_v hv And sensor characteristics h s h_s hs Get merged features h V + S h_{V+S} hV+S, Then these three characteristics ( h v , h s , h V + S h_v, h_s, h_{V+S} hv,hs,hV+S) Input to DMA Selective attention learning in the module . Then input GRU In the middle of word Generate
Detailed design
1. feature extraction
- Visual features h V h_V hV:Vgg16
- Sensor characteristics h S h_S hS:LSTM( sequential )
2. Asymmetric Multi-modal Transformation(AMMT)
In essence, it is feature merging
Source :FiLM: Visual Reasoning with a General Conditioning Layer, Knowledge point reference feature-wise linear modulation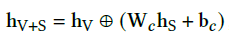
ps: initialization W c = I , b c = 0 W_c=I, b_c=0 Wc=I,bc=0, Is initialized to concate, With the deepening of training , Learn the merging characteristics of the two
Note that the output features here are three kinds of features :
(1) Visual features h V h_V hV
(2) Sensor characteristics h S h_S hS
(3) Merged features h V + S h_{V+S} hV+S
- Some use asymmetric explanations
On the one hand, it can alleviate the over fitting caused by data redundancy ; On the other hand , Sensor data sometimes contains unwanted noise , Therefore, it needs to be adjusted .
3. Dynamic Modal Attention (DMA)
Dynamically select attention for three features 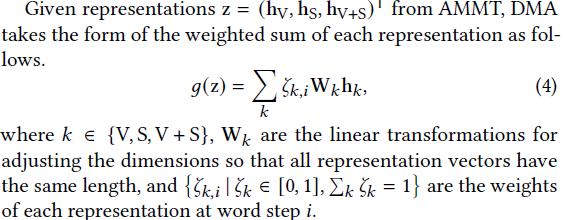
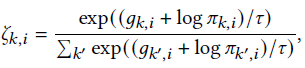

It's used here Gumbel Softmax
ps: Reasons for using three features : Because in many cases , It is desirable to use only a single mode ( for example , Sensor data containing unwanted noise ).
边栏推荐
- A cool "ghost" console tool
- [paper reading] semi supervised left atrium segmentation with mutual consistency training
- nodejs获取客户端ip
- [question] Compilation Principle
- Jhok-zbl1 leakage relay
- Sorry, I've learned a lesson
- 【js组件】自定义select
- 拼多多商品详情接口、拼多多商品基本信息、拼多多商品属性接口
- AOSP ~binder communication principle (I) - Overview
- 做自媒体视频剪辑,专业的人会怎么寻找背景音乐素材?
猜你喜欢

DOM-节点对象+时间节点 综合案例
漏电继电器JELR-250FG

漏电继电器LLJ-100FS
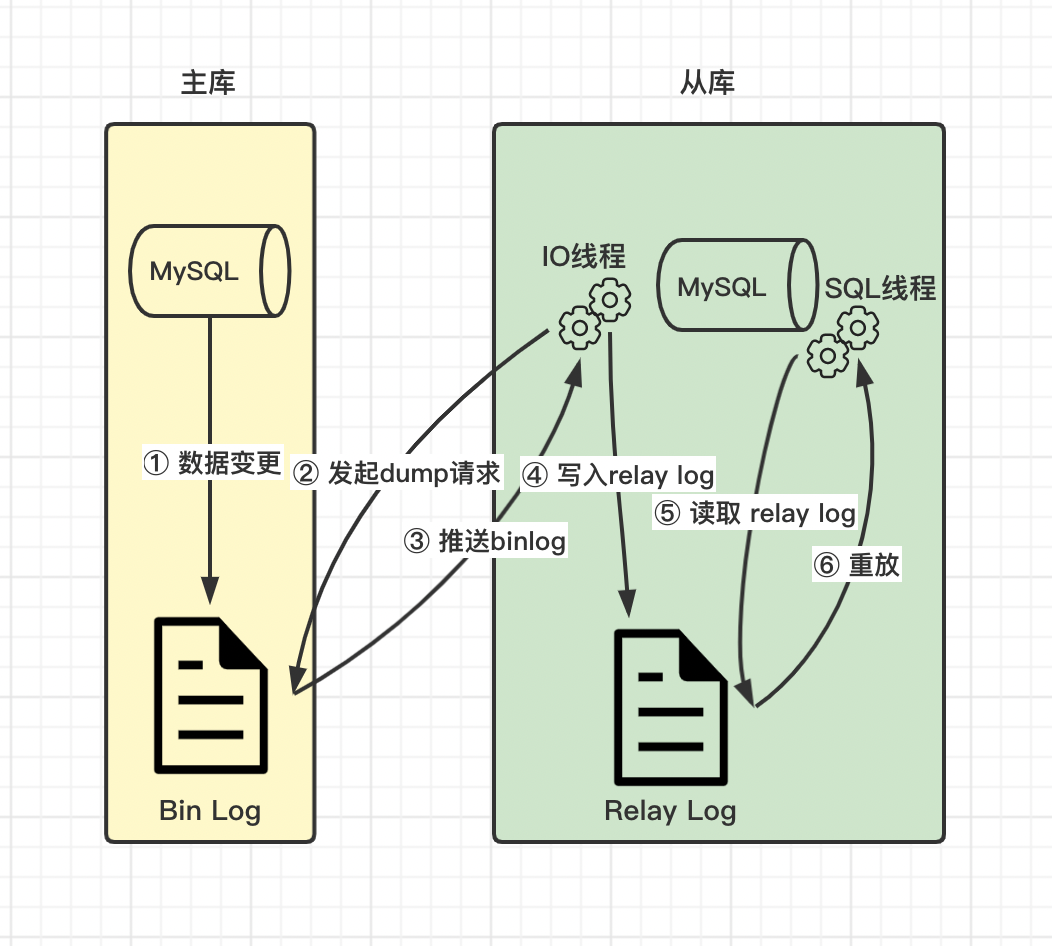
Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
![[binary tree] binary tree path finding](/img/34/1798111e9a294b025806a4d2d5abf8.png)
[binary tree] binary tree path finding
DOM node object + time node comprehensive case

阿里云的神龙架构是怎么工作的 | 科普图解
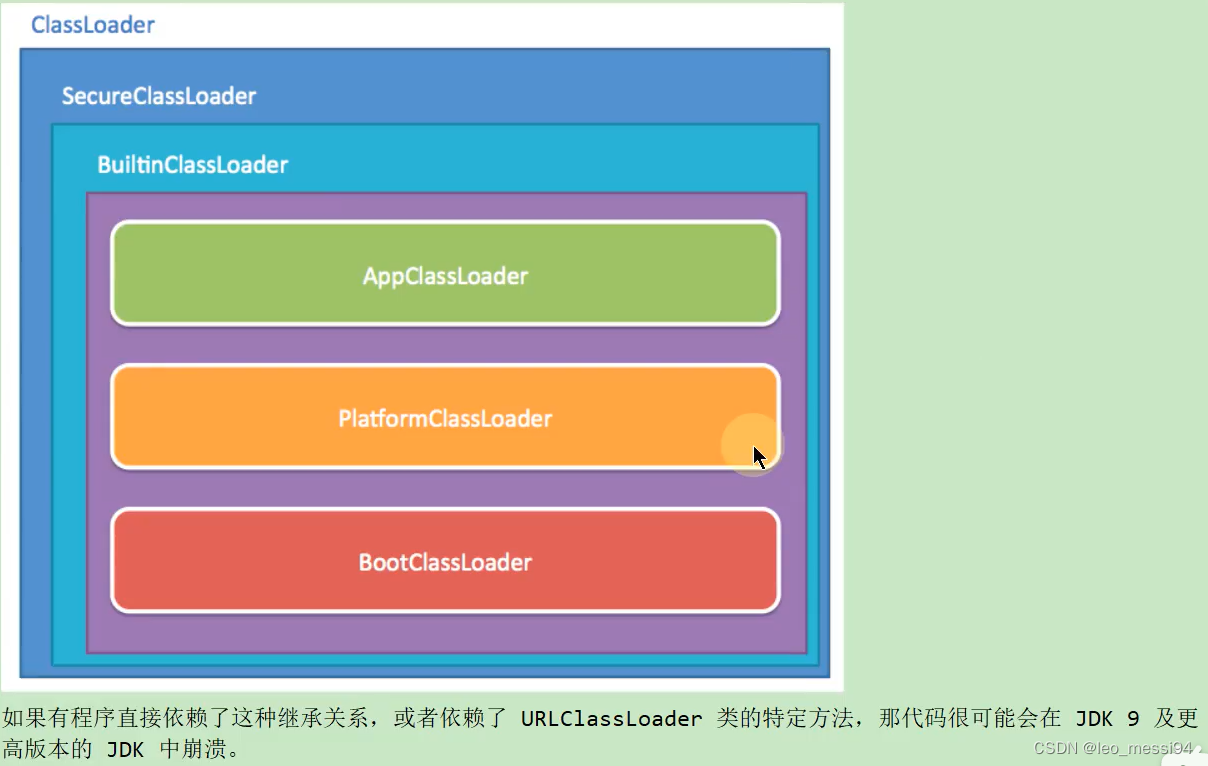
JVM(十九) -- 字节码与类的加载(四) -- 再谈类的加载器

张平安:加快云上数字创新,共建产业智慧生态

How digitalization affects workflow automation
随机推荐
[JS component] custom select
Mysql database learning (7) -- a brief introduction to pymysql
Two person game based on bevy game engine and FPGA
分布式事务介绍
Digital innovation driven guide
[论文阅读] A Multi-branch Hybrid Transformer Network for Corneal Endothelial Cell Segmentation
Scheduledexecutorservice timer
1.AVL树:左右旋-bite
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
Pytest testing framework -- data driven
利用OPNET进行网络单播(一服务器多客户端)仿真的设计、配置及注意点
《4》 Form
基于NCF的多模块协同实例
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
不同网段之间实现GDB远程调试功能
[JS component] date display.
论文阅读【Open-book Video Captioning with Retrieve-Copy-Generate Network】
分布式事务解决方案之TCC
[PHP SPL notes]
[optimal web page width and its implementation] [recommended collection "