当前位置:网站首页>Learn CV one from scratch activation function
Learn CV one from scratch activation function
2022-07-08 02:18:00 【pogg_】

Preface : I believe a lot of contacts cv Of students have studied activation functions , Activation function is very important for a neuron , A good activation function can make a qualitative leap in your model , What exactly is an activation function ? What are the common activation functions ? What are their advantages and disadvantages ?
1. What is an activation function ?
I believe everyone in high school biology has studied the nervous system , In fact, neural networks draw on the research results of biology on brain nerves , Let's take the neuron of a biological brain for example ~
The part of bifurcation and bulge is dendrite, also known as synapse , It is used to receive electrical signals from the outside , Synapses surround neurons , It sends signals received by synapses ( Multiple electrical signals , Like many inputs) Integrate into a feedback message .
however , Not every batch of electrical signals will cause feedback , When the electric signal input to the neuron is not strong enough , Neurons will not produce any response . If the electrical signal is greater than a certain limit , It will react , And transmit the electrical signal it generates to other neurons .
And how to expand or reduce the electrical signal , You need something similar to a magnifying and shrinking device , Activation function in neural network , It plays this role .
in addition , The learning ability of neural network is very limited , Unable to solve nonlinear problems , Superposition of simple neural networks cannot solve the nonlinear classification problem , The activation function can , This is also an important significance of the activation function , To activate neurons .
2. Common activation functions

2.1 Sigmoid Activation function


advantage :
- sigmoid The output range of the function is 0 and 1 Between . Because the output value is between 0 and 1 Between , So it standardizes the output of each neuron .
- Because the probability of anything only exists in 0 and 1 Between , therefore sigmoid It's the perfect choice .
- Smooth gradient , Prevent output values “ jumping ”.
- This function is differentiable , It means , We can find any two points sigmoid The slope of the curve .
- A clear prediction , That is very close to 1 or 0( or true, or false)
shortcoming :
- Gradients tend to disappear ( When sigmoid When the function value is too high or too low , The derivative becomes very small , namely << 1. This will lead to gradient disappearance and poor deep network learning .)
- Function output does not begin with 0 Centered , It will reduce the efficiency of weight update . sigmoid Functions perform exponential operations , This is expensive for computers , More slowly .
2.2 Tanh Hyperbolic tangent activation function 

Tanh It's a hyperbolic tangent function . tanh Functions and sigmoid The curve of the function is similar . But it is better than sigmoid Functions have some advantages , As follows (sigmoid And tanh contrast ):

characteristic :
- First , When input is either large or small , The two outputs are almost smooth , The gradient is very small , It is not conducive to weight update . The difference is the output interval .tanh The output interval of is (-1,1), The whole function starts with 0 Centered , be better than sigmoid.
- stay tanh In the figure , Negative input will be strongly mapped to negative , And zero input is mapped to near zero .
2.3 ReLU(Rectified Linear Unit) Activation function


advantage :
- When the input is positive , There is no gradient saturation problem —— Gradient saturation is often related to the activation function , such as sigmod and tanh It belongs to a typical function that is easy to enter the gradient saturation region , That is, after the independent variable enters a certain interval , The gradient change will be very small , It is shown on the graph that after the function curve enters some areas , Getting closer and closer to a straight line , The gradient changes very little , Gradient saturation will cause the gradient to change slowly in the training process , Thus, the model training is slow )
- The calculation speed is much faster .ReLU Functions have only linear relationships . Whether forward or backward , All ratio sigmoid and tanh Much faster .(sigmoid and tanh Need to calculate the index , It will be slow .)
- At present, many embedded fp16、int8 Quantitative models are commonly used relu function , Because of the fast
shortcoming :
- Dead ReLU problem —— When the input is negative ,ReLU Is completely inactive , That is, once you enter a negative number ,ReLU Will die . In the process of forward propagation , The impact of such problems is relatively small . But in the process of back propagation , If you enter a negative number , The gradient will be completely zero , This is related to sigmoid Functions and tanh Functions have the same problem .
- ReLU The output of the function is either 0 Or a positive number , explain ReLU The function does not take 0 A function that is centered on .
2.4 Leaky ReLU Activation function


advantage ( comparison relu):
- Leaky ReLU By way of x The very small linear component of gives negative input ( Usually a=0.01) To adjust the negative zero gradient problem . Leaky ReLU Help to increase
- ReLU The scope of the function , The value range is from 0 To infinity → Negative infinity to positive infinity
notes : Theoretically ,Leaky ReLU have ReLU All the advantages of , add Dead ReLU There will be no problem , But in practice , Not fully proved Leaky ReLU Always better than ReLU. however , Used to YOLO Series of friends are very familiar with this function , stay tiny You can often see this function in version .
2.5 ELU Exponential linear activation function


advantage ( be relative to Leaky ReLU and ReLU for ):

- No, Dead ReLU problem , The average value of the output is close to 0, With 0 Centered .
- ELU By reducing the effect of offset , Make the normal gradient closer to the unit natural gradient , So that the mean value can be accelerated to zero
- ELU Saturation is negative when the input is small , So as to reduce the forward spread of information changes .
2.6 PRelu(Parametric ReLU) Activation function


Parameters α It's usually 0 To 1 A number between , Generally small ,0.01 It becomes leaky relu function .
- If α =0, f(x) become ReLU
- If α=0.01,f(x) Become leaky relu
- If α It's a learnable parameter , be f(x) Turn into PReLU
advantage :
- In the negative region ,PReLU There is a small slope , It can also be avoided Dead ReLU The problem of .
- And ELU comparison ,PReLU Is the linear operation of negative region . Although the slope is small , But it does not tend to 0, This has certain advantages ,a It can be adjusted according to the network , Compared to other rule Derivative series are more flexible .
2.7 Softmax Activation function
I can't find this picture , To be supplemented by the boss .....
Softmax Used as a Multiple classification problems The activation function of , For length is K Any real vector of ,Softmax It can be compressed into a length of K The real vector of , Its value is (0, 1) Within the scope of , The sum of the elements in the vector is 1.
Sigmoid = Multi label classification problem = Multiple correct answers = Exclusive output ( For example, the chest X Light check 、 In the hospital ). Building classifiers , When solving a problem that has more than one correct answer , use Sigmoid The function processes each raw output value separately .
Softmax = Multi category classification problem = There is only one correct answer = Mutually exclusive output ( For example, handwritten numbers , Iris ). Building classifiers , When solving a problem with only one correct answer , use Softmax The function processes the raw output values .Softmax The denominator of the function synthesizes all the factors of the original output value , It means ,Softmax The different probabilities obtained by the function are related to each other .
softmax And sigmoid Difference of function :
- If the model output is a non mutex class , And you can select multiple categories at the same time , Then Sigmoid Function to calculate the original output value of the network .
- If the model output is a mutex class , And only one category can be selected , Then Softmax Function to calculate the original output value of the network .
- Sigmoid Function can be used to solve the multi label problem ( Goats are both sheep and animals ),Softmax Function is used to solve the single label problem ( Face ID Confirm common ).
- For a classification scenario , When Softmax When the function can be used ,Sigmoid Function must be able to use ( take top-1)
2.8 Swish Activation function (YOLOv5 In Chinese, it means SiLU function )


Swish Our design has been influenced by LSTM And high-speed networks gating Of sigmoid The inspiration of using function . Let's use the same one gating Value to simplify gating Mechanism , This is called self-gating( automatic control ).
self-gating The advantage is that it only requires a simple scalar input , And ordinary. gating Multiple scalar inputs are required . This makes things like Swish And so on. self-gated Activation functions can easily replace activation functions with a single scalar input ( for example ReLU), Without changing the hidden capacity or the number of parameters .
advantage :
- 「 Boundlessness 」 It helps to prevent... During slow training , Gradients are getting closer 0
And lead to saturation ;( meanwhile , Boundedness also has advantages , Because bounded activation functions can have strong regularization , And the larger negative input problem can also be solved ); - Smoothness plays an important role in optimization and generalization .
2.9 Maxout Activation function
maxout The activation function is not a fixed function , Unlike Sigmod、Relu、Tanh Such as function , Is a fixed functional equation , It is a learnable activation function , Because our parameters are learning to change , It is a piecewise linear function , As shown below .


stay Maxout layer , The activation function is the maximum value of the input , So only 2 individual maxout The multi-layer perceptron of the node can fit any Convex function
Convex function Is a kind of characteristic of mathematical function . A convex function is a convex subset defined in a vector space C( In Euclidean space , A convex set is for every pair of points in the set , Each point on the line segment connecting the pair of points is also in the set ) Real valued functions on .
Single Maxout A node can be interpreted as a piecewise linear approximation of a real valued function (PWL) , The line segment between any two points on the function graph is located in the graph ( Convex function ) On top of .
Let's say two convex functions h_1(x) and h_2(x), By two Maxout Node approximation , function g(x) Is a continuous PWL function .
therefore , By two Maxout The nodes make up Maxout A layer can well approximate any continuous function .
Then what is approaching ?
Any convex function , Can be approximated by linear piecewise functions . In fact, we can put the activation function we learned before :relu、abs Activation function , As a linear function divided into two segments , As shown in the diagram below 
maxout The ability of fitting is very strong , It can fit any convex function . The most intuitive explanation is that any convex function can be fitted by piecewise linear function with any accuracy ( After studying advanced mathematics, you should be able to understand ), and maxout Take again k The maximum value of hidden layer nodes , these ” Concealed aquifer " Nodes are also linear , So in different value ranges , The maximum value can also be regarded as piecewise linear ( The number of segments is the same as k It's about )
2.10 hard-Swish Activation function


Convolution is usually followed by ReLU Nonlinear activation ,ReLU6 It's just plain ReLU, However, the maximum output is limited to 6, This is for mobile devices float16/int8 It can also have good numerical resolution at low accuracy . If the ReLU There is no limit to the range of activation , The output range is 0 To infinity , If the activation value is very large , Distributed over a wide range , It is low precision float16/int8 It can't accurately describe such a large range of values , There will be a loss of accuracy . The picture below is ReLU and ReLU6 Function curve of .

Hard-Swish Compared to the function Swish The advantages of functions :
paper:https://arxiv.org/pdf/1905.02244.pdf
- In the paper , The author mentioned , Although this kind of Swish Nonlinearity improves accuracy , But in an embedded environment , His calculation cost is expensive , Because it is better than computing on mobile devices sigmoid Functions are much more expensive .
- Author use hard-Swish and hard-Sigmoid To replace the ReLU6 and SE-block Medium Sigmoid layer , But only in the second half of the network will ReLU6 Replace with h-Swish, Because the author found that Swish Function can only be used in a deeper network layer to reflect its advantages .
- In quantization mode ,Sigmoid Functional ratio ReLU6 The calculation cost of is much higher , That's why we have this ReLU6 Version of h-Swish.
2.11 hard-Swish Activation function


advantage :
- The supreme borderless ( That is, a positive value can reach any height ) Avoid saturation due to capping .
- Theoretically, a slight allowance for negative values allows for better gradient flow , Not like it ReLU A hard zero boundary like in (RuLU Dead The situation of ).
- The smooth activation function allows better information to penetrate the neural network , So as to get better accuracy and generalization .
shortcoming :
- The amount of calculation must be greater than relu Big , It takes up a lot more memory
YOLOv4 Used Mish Function as activation function , It does have some effect :

Reference resources :
[1] https://medium.com/analytics-vidhya/activation-functions-all-you-need-to-know-355a850d025e
[2] https://en.wikipedia.org/wiki/Activation_function
[3]https://github.com/ultralytics/yolov5/blob/31336075609a3fbcb4afe398eba2967b22056bfa/utils/activations.py%23L30
边栏推荐
- In depth analysis of ArrayList source code, from the most basic capacity expansion principle, to the magic iterator and fast fail mechanism, you have everything you want!!!
- burpsuite
- Clickhouse principle analysis and application practice "reading notes (8)
- Keras' deep learning practice -- gender classification based on inception V3
- 线程死锁——死锁产生的条件
- leetcode 869. Reordered Power of 2 | 869. 重新排序得到 2 的幂(状态压缩)
- 生命的高度
- JVM memory and garbage collection-3-runtime data area / method area
- CorelDRAW2022下载安装电脑系统要求技术规格
- Emqx 5.0 release: open source Internet of things message server with single cluster supporting 100million mqtt connections
猜你喜欢
Ml self realization /knn/ classification / weightlessness
Can you write the software test questions?
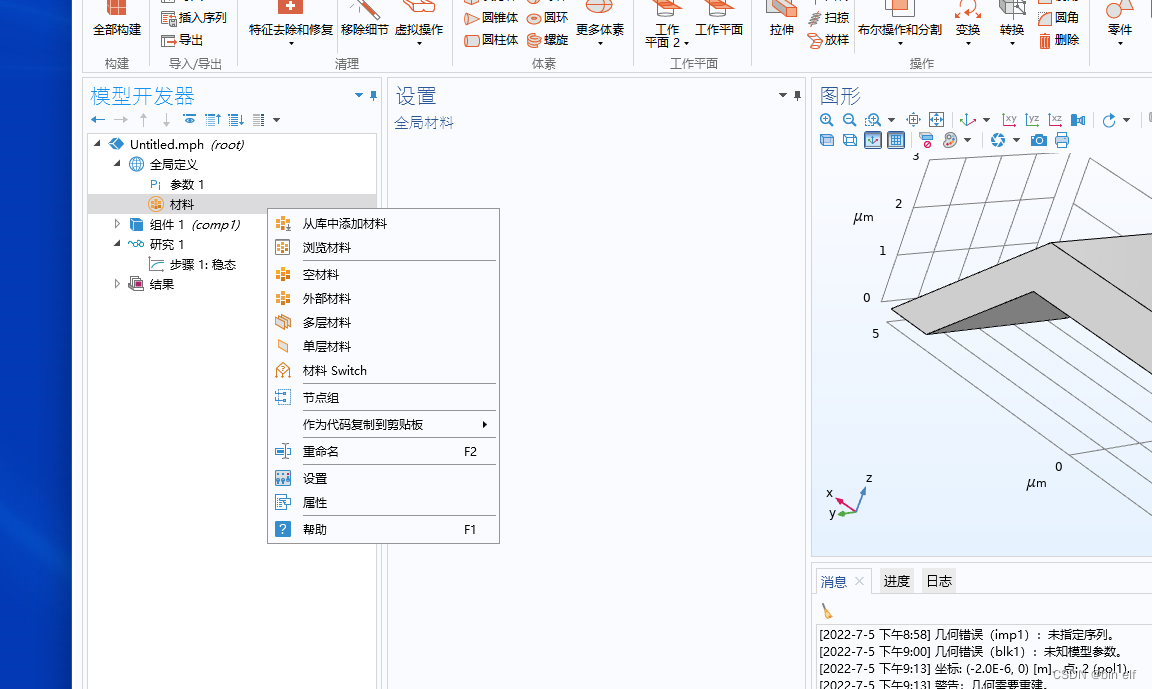
COMSOL --- construction of micro resistance beam model --- final temperature distribution and deformation --- addition of materials

Ml self realization / logistic regression / binary classification
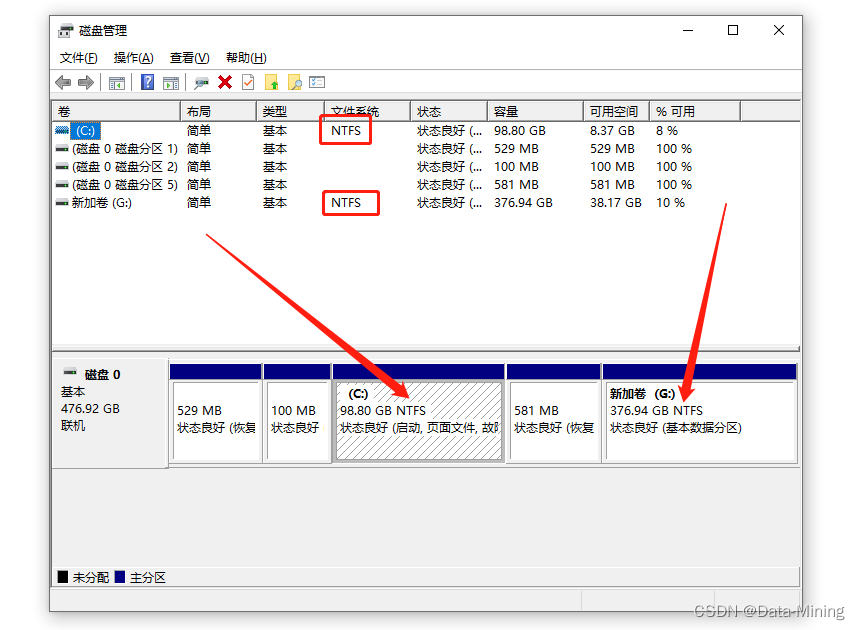
Common disk formats and the differences between them

Key points of data link layer and network layer protocol

How does the bull bear cycle and encryption evolve in the future? Look at Sequoia Capital
th:include的使用
![[recommendation system paper reading] recommendation simulation user feedback based on Reinforcement Learning](/img/48/3366df75c397269574e9666fcd02ec.jpg)
[recommendation system paper reading] recommendation simulation user feedback based on Reinforcement Learning

Nanny level tutorial: Azkaban executes jar package (with test samples and results)

随机推荐
VIM string substitution
How to use diffusion models for interpolation—— Principle analysis and code practice
Can you write the software test questions?
From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
实现前缀树
线程死锁——死锁产生的条件
科普 | 什么是灵魂绑定代币SBT?有何价值?
很多小夥伴不太了解ORM框架的底層原理,這不,冰河帶你10分鐘手擼一個極簡版ORM框架(趕快收藏吧)
Random walk reasoning and learning in large-scale knowledge base
Exit of processes and threads
Kwai applet guaranteed payment PHP source code packaging
Master go game through deep neural network and tree search
力争做到国内赛事应办尽办,国家体育总局明确安全有序恢复线下体育赛事
Ml self realization / linear regression / multivariable
Key points of data link layer and network layer protocol
[recommendation system paper reading] recommendation simulation user feedback based on Reinforcement Learning
Yolo fast+dnn+flask realizes streaming and streaming on mobile terminals and displays them on the web
leetcode 866. Prime Palindrome | 866. 回文素数
"Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.1 data operation_ Learning thinking and exercise answers
Keras深度学习实战——基于Inception v3实现性别分类