当前位置:网站首页>UFO: Microsoft scholars have proposed a unified transformer for visual language representation learning to achieve SOTA performance on multiple multimodal tasks
UFO: Microsoft scholars have proposed a unified transformer for visual language representation learning to achieve SOTA performance on multiple multimodal tasks
2022-07-04 14:48:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares papers 『UFO: A UniFied TransfOrmer for Vision-Language Representation Learning』, Microsoft scholars have proposed the unity of visual language representation learning Transformer,《UFO》, Achieve... On multiple multimodal tasks SOTA performance !
The details are as follows :

Thesis link :https://arxiv.org/abs/2004.12832
01
Abstract
In this paper , The author puts forward a unified Transformer(UFO), It can handle single-mode input ( Such as image or language ) Or multimodal input ( For example, images and problems concatenation), For visual language (VL) It means learning . Existing methods usually design a separate network for each mode and a specific fusion network for multimodal tasks .
In order to simplify the network structure , The author uses a single Transformer The Internet , stay VL Implement multi task learning during pre training , Include Image text contrast loss 、 Image text matching loss and based on bidirectional sum seq2seq Attention masked mask Language modeling loss . In different pre training tasks , same Transformer The network is used as an image encoder 、 Text encoder or converged network . According to the experiment , The authors observed less conflict between different tasks , In visual Q & A 、COCO Image caption ( Cross entropy optimization ) and nocaps(SPICE) Has reached a new level . On other downstream tasks , For example, image text retrieval ,UFO Also achieved competitive performance .
02
Motivation
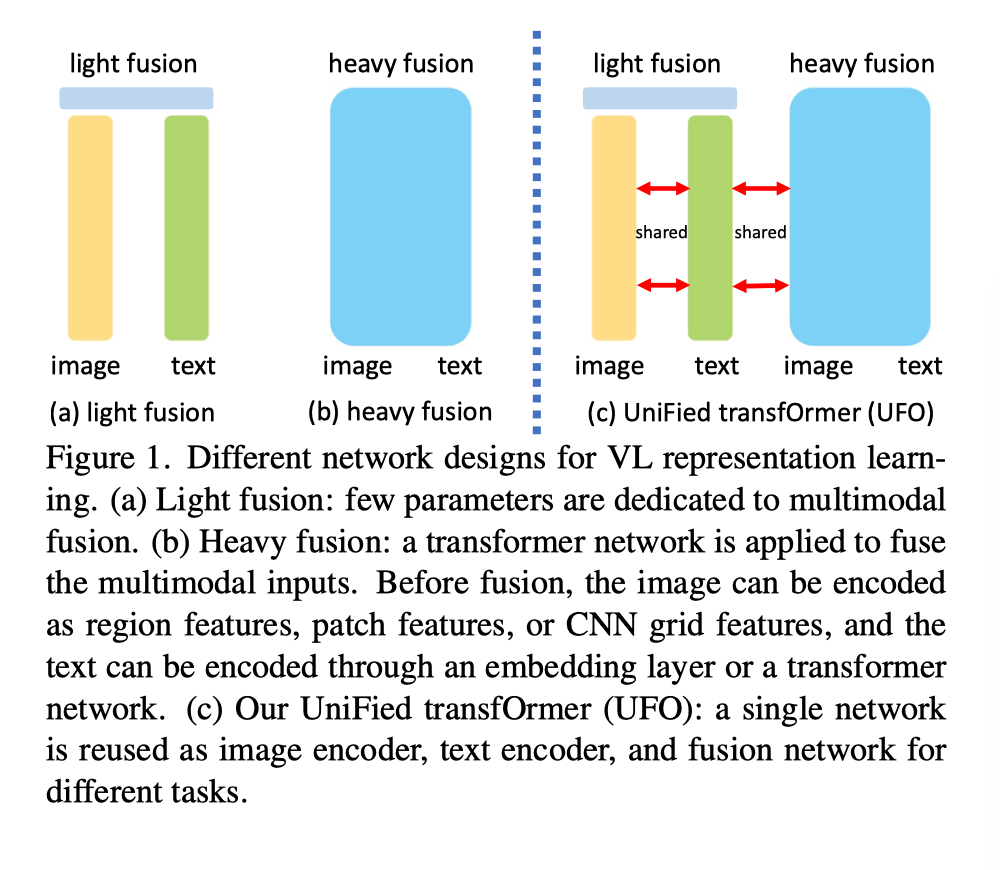
In recent years , Visual language (VL) Representation learning has made great progress , The model aims to understand vision / The relationship between language signals and modes . Applications include image captioning 、 Visual Q & A (VQA)、 Image text retrieval . Typical methods first extract features from each mode , Then feed them back to the fusion network , Learning together means . About the design of converged network , The existing methods can be roughly divided into two categories : Light integration and heavy integration , Pictured above (a) and (b) Shown .
Light fusion ( chart (a)) Separate encoders for images and text , For example, in CLIP and ALIGN in . The image encoder can be ResNet or vision transformer, Text coders are usually transformer. Fusion is based on the contrast loss of cosine similarity , The representation of the two modes can be aligned to the same semantic space . A good application is image text retrieval , Each image or text description is represented as a fixed vector , For fast similarity search .
Few parameters are assigned in light fusion , Upper figure (b) The shown re fusion method is applied on the single-mode feature transformer Network to learn together means . Images can be displayed through Faster RCNN Code as object feature , Grid features are encoded by convolutional neural network , Or it can be encoded as patch features . Text can be through transformer The network or simple embedding layer is encoded as token Express . Through the heavy convergence network , The final representation can better capture the contextual connections between modes . A typical application is VQA, The network predicts answers based on images and questions .
Existing methods design different network architectures for different tasks . because transformer The network is available for all these components , So in this paper , The author attempts to design a single unity for light fusion and heavy fusion scenes transformer(UFO), Pictured above (c) Shown . For light fusion missions ,transformer Used as image encoder and text encoder at the same time . For re fusion tasks , same transformer Be reused as a fusion module , To process the two signals together .
In the input transformer Before , The original image pixels are grouped into patch, And projection through linear mapping . The text description is projected to the same dimension through the embedded layer . such , Assign as few learnable parameters as possible in modal specific processing , And use most of it for sharing transformer The Internet . According to how much representation capability should be allocated to each individual mode and how much should be allocated to the joint representation , Automatically adjust the network .
In order to make the network have the ability of single-mode input , The author in VL Preliminary training (VLP) Apply image to output during - Text contrast (ITC) Loss . For multimodal fusion capability , The author adopts the method based on bidirectional and seq2seq Image text matching of attention (ITM) Loss and shielding language modeling (MLM) Loss . In order to optimize the network with multiple tasks , The author randomly selects a task in each iteration to improve efficiency , And make use of momentum teacher To guide learning . Through extensive ablation studies , The author observes that there is less conflict between these tasks . In some cases , Different tasks can even help each other .
03
Method
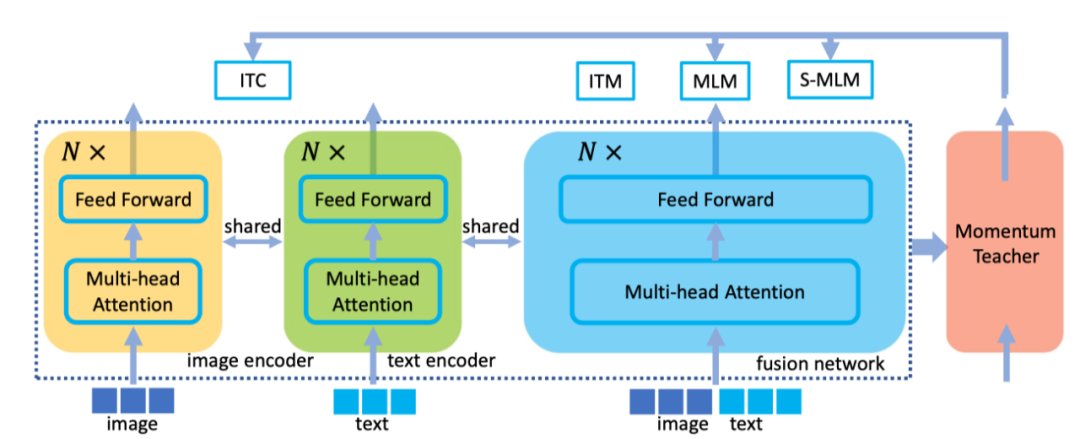
UFO The key idea is to use only one transformer The Internet , It is reused as an image encoder 、 Text encoder or fusion encoder . The author follows the widely used pre training - Fine tune the program to train the network . During pre training , The author obtained a large number of images - Text to corpus , And enforce multiple losses to enhance network capabilities . For single-mode signals , The author uses images - Text comparison loss . For multimodal fusion tasks , The author adopts a method based on two-way (MLM) And one way (S-MLM) The image of attention - Text matching loss (ITM) And masking language modeling losses . The figure above shows the pre training framework .
3.1. Network Structure
Adopted by the author transformer The Internet as backbone. The main reason is transformer Network in image task 、 Language tasks and VL Good performance on the task . Other options are Convolutional Neural Networks (CNN) Or all MLP structure , However, it is not clear how such networks can be effectively applied to all three functions .
transformer The input of the network is a series token, Every token They are all expressed as d Dimension vector . in order to tokenize Images , The author divides the original image into disjoint patch, Every patch Linear projection to... Through a learnable linear layer d In the dimension . Add learnable two-dimensional position embedding to each patch In the middle , And attach the image [CLS] token. The text description is first tokenized, Then embed it into d Dimensional space . Then add [CLS] The beginning of token and EOS The end of token To wrap text sequences . To each text token Add learnable one-dimensional position embedding .
here , Images [CLS] And the text [CLS] It's two different token. Send input to transformer Before the Internet , Add mode specific embeddedness to the corresponding input . about VL Mission , Two modal inputs are sent to transformer Before concatenated. Although the input may have different token length , but transformer The network can naturally handle different input lengths .
3.2. Pre-training Tasks
Image-Text Contrastive Loss
Images - Text contrast (ITC) The loss is training the network to process images or texts , And align the matching pairs to similar representations . For the image , The network is used as an image encoder , And choose with [CLS] token The corresponding output is used as a representation . For the text , The network is reused as a text encoder , And [EOS] token The corresponding network is used as a representation . Text [CLS] token Used for image text matching loss . Let sum be the second I Representation of images and text . Given a training batch Medium N Yes , The loss is :
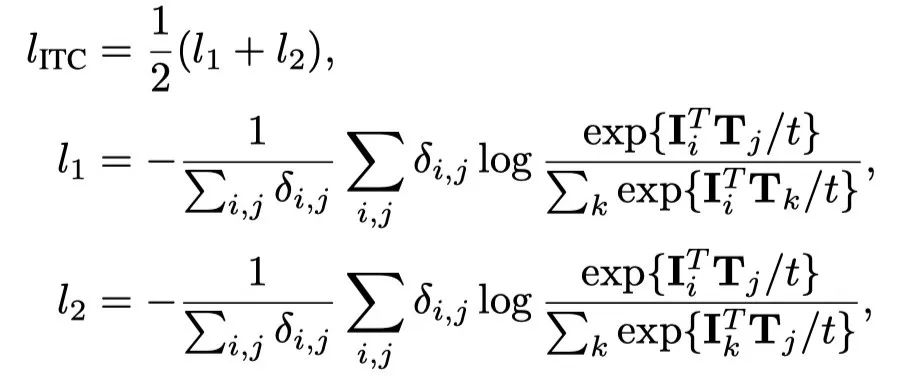
among ,t It's learnable , Initialize to 1. If the first i Images and j Text pairing , The indicator of is 1, Otherwise 0. This is to process images ( Or the text ) With multiple texts ( Or image ) Associated data .
Image-Text Matching Loss
Network input matches or does not match image text pairs concatenation. Mismatch pairs are constructed by randomly selecting text descriptions for a given image in the data set . The network needs to predict whether it matches , This is a binary task . here , The author uses the representation of text [CLS] As a joint expression , And then use MLP Layer to predict . Cross entropy loss is used to punish mispredictions .
Masked Language Modeling Loss
Network input is image token And part mask Text token Series connection of , and transformer The network is trained to predict masked token. The author chooses 15% The text of token To make predictions . Each selected token All others token Replace ,[MASK] token Occupy 80%; Random token Occupy 10%, Not changed token Occupy 10%.MLM The head applies to mask token Output , Used to predict cross entropy loss , Expressed as .
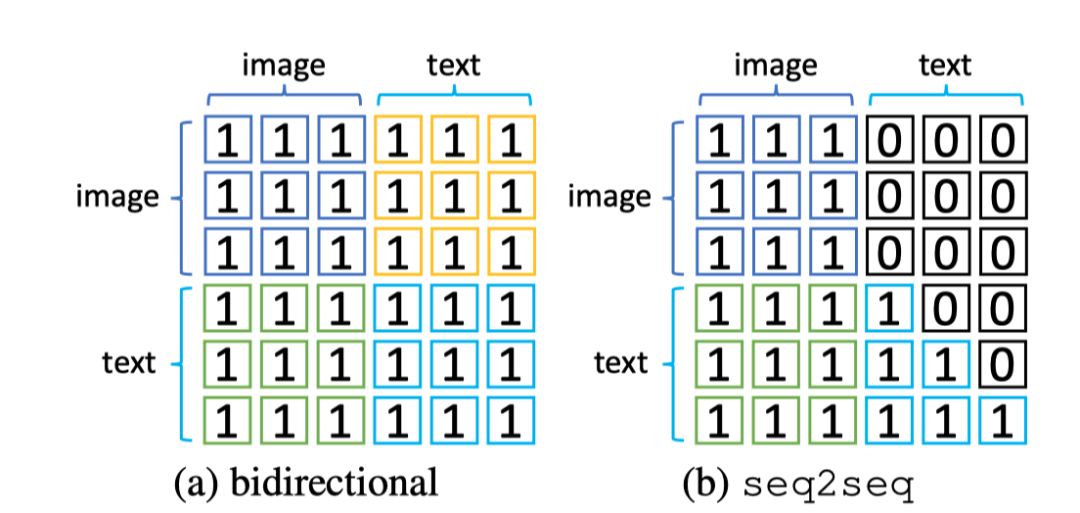
When applying the pre trained model to the image caption task , The author changed the attention mask , Make the current text token Can only rely on the previous token. therefore , The author also combines another method based on seq2seq Pay attention to mask Language modeling loss , And express it as . The figure above shows MLM and S-MLM Attention mask .
3.3. Pre-training Strategies
One Loss per Iteration

The above table summarizes the characteristics of each pre training loss . In different losses , The input format is different ,transformer Used as different roles , The attention mask may also be different . For the sake of simplicity , In each iteration , The author randomly selects a pre training loss , And calculate the gradient of parameter update . According to the experiment , The author found , When the total amount of loss calculation is the same , This strategy is more effective than calculating all the losses in each iteration .
Momentum Teacher
The author added a Momentum Teacher To guide pre training . To be specific ,Momentum Teacher yes transformer Network cloning , The parameters are updated to the exponential moving average of the target network parameters . Set as the parameter of the target network , Parameters for teachers . In each iteration :
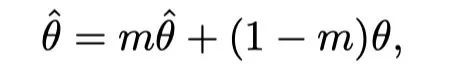
among m In the experiment, it is set to 0.999. about ITC/MLM/S-MLM Pre training loss , The same input and attention masks are also fed to Momentum Teacher, The output is used as a soft target for the output of the target network . stay ITC in , Let it be the first i The first image and the second j Similarity between texts , yes Momentum Teacher Similarity in the network . then , stay ITC Add distillation loss at the top , As shown below :
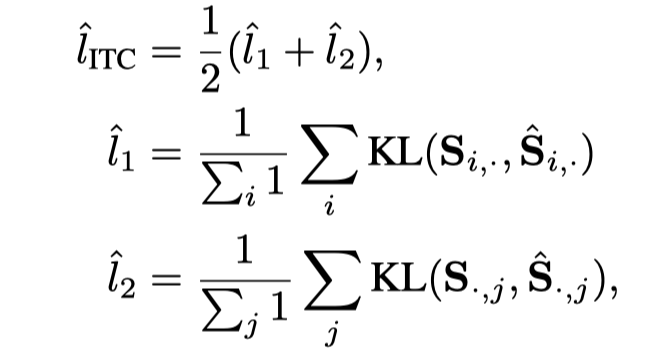
among , Indicates input softmax Upper Kullback–Leibler Divergence loss . about MLM Loss , hypothesis g Is corresponding to masked token The forecast logits,g Is from Momentum Teacher Of logits, Then the distillation loss is . Again , Also have S-MLM Distillation loss of .
04
experiment
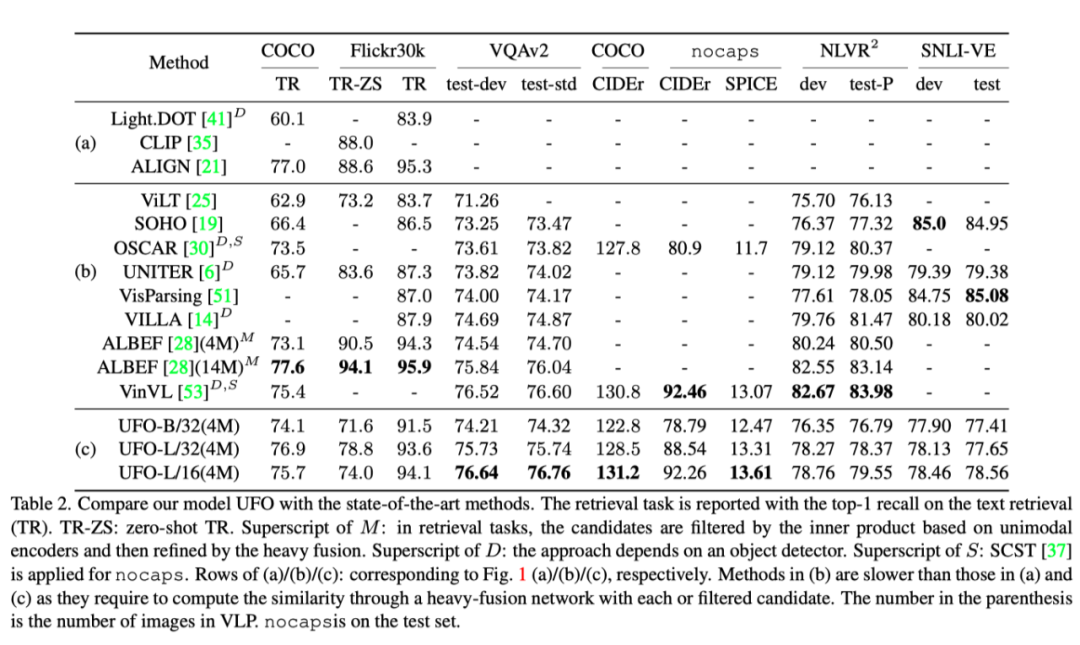
The above table shows the data sets and tasks , What this article puts forward UFO And others SOTA The results of the method are compared .
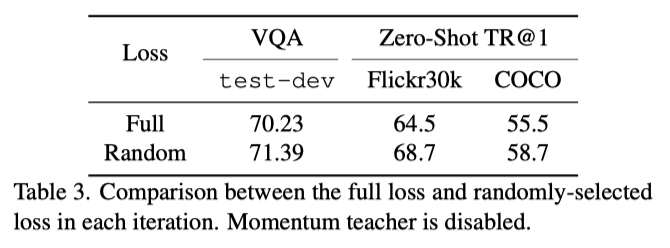
The above table shows the comparison of ablation results between each randomly selected loss function and using all loss functions in training , It can be seen that the effect of using random loss function is better .
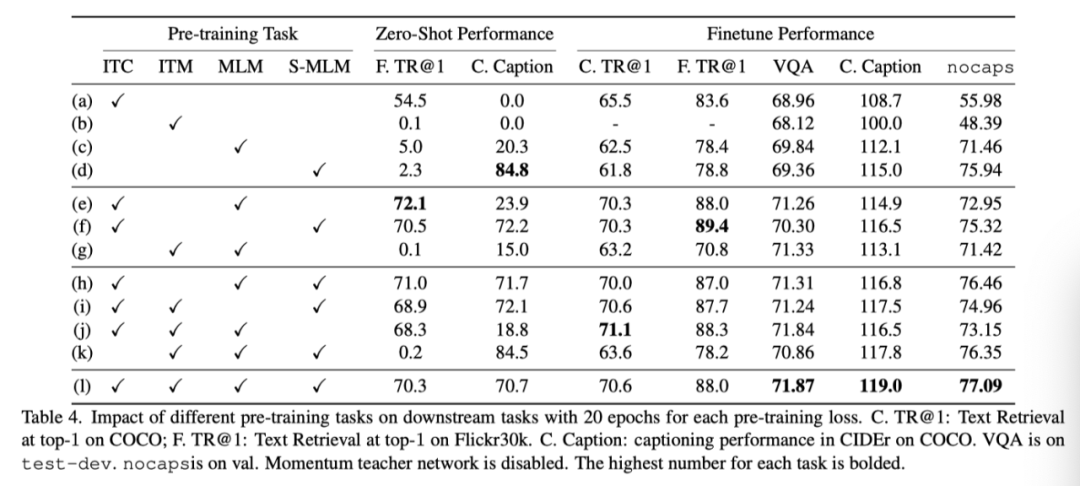
The above table shows the comparison of ablation results of different pre training methods .
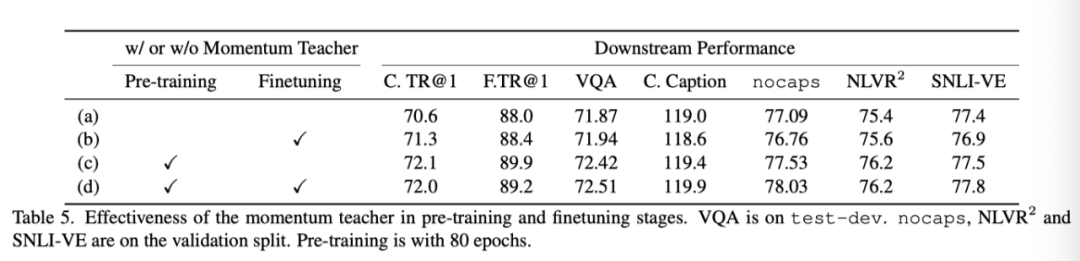
The above table shows whether to use momentum teacher The experimental results of .
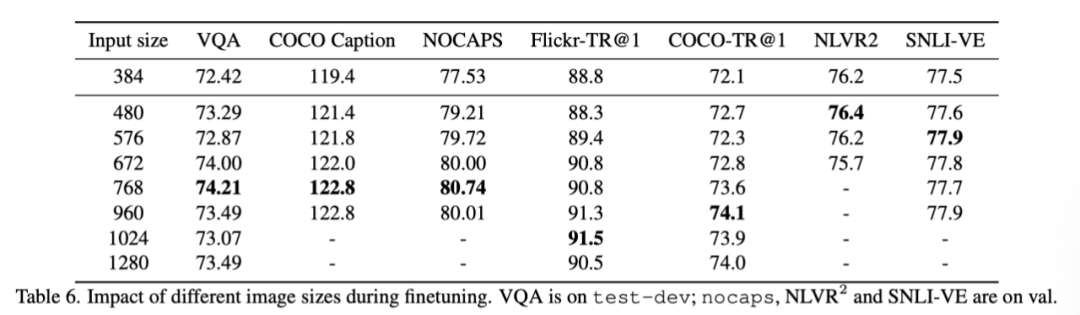
The above table shows the study of different input image sizes for each downstream task . stay VQA、 Image captioning and retrieval tasks , The greater the input , The more accurate . meanwhile , The optimal input size for different tasks is also different , This indicates that different tasks may expect different levels of image understanding granularity .
05
summary
The author puts forward a unified Transformer(UFO), It can process single-mode input and multi-mode input of image or text . In the process of visual language pre training , Learning networks understand different signals through multiple losses , Including image text contrast loss 、 Image text matching loss and based on bidirectional sum seq2seq Masked mask Language modeling loss .
A lot of experiments show that , Compared with the existing method , The single model in this paper can obtain competitive results , Existing methods usually design specific networks for each mode and mode fusion . Because the model of this paper is in VLP There are only 400 Ten thousand images have reached large size (24 layer ), Therefore, the author hopes to enlarge the model size and pre training data at the same time in the future .
Reference material
[1]https://arxiv.org/abs/2004.12832

END
Welcome to join 「 Visual language 」 Exchange group notes :VL

边栏推荐
- scratch古堡历险记 电子学会图形化编程scratch等级考试三级真题和答案解析2022年6月
- LVGL 8.2 Draw label with gradient color
- What is the difference between Bi financial analysis in a narrow sense and financial analysis in a broad sense?
- Halo effect - who says that those with light on their heads are heroes
- Digi XBee 3 RF: 4个协议,3种封装,10个大功能
- [MySQL from introduction to proficiency] [advanced chapter] (IV) MySQL permission management and control
- flink sql-client. SH tutorial
- 数据湖(十三):Spark与Iceberg整合DDL操作
- C language small commodity management system
- Five minutes of machine learning every day: why do we need to normalize the characteristics of numerical types?
猜你喜欢
LVGL 8.2 text shadow
No servers available for service: xxxx
Five minutes of machine learning every day: how to use matrix to represent the sample data of multiple characteristic variables?

软件测试之测试评估

开发中常见问题总结
Expose Ali's salary and position level

如何配和弦
Chapter 17 process memory
![[information retrieval] link analysis](/img/dc/4956e8e21d8ce6be1db1822d19ca61.png)
[information retrieval] link analysis
LVGL 8.2 Draw label with gradient color
随机推荐
Codeforce:c. sum of substrings
LVGL 8.2 Draw label with gradient color
openresty 限流
Leetcode 61: rotating linked list
A collection of classic papers on convolutional neural networks (deep learning classification)
Combined with case: the usage of the lowest API (processfunction) in Flink framework
leecode学习笔记-约瑟夫问题
自动控制原理快速入门+理解
函数计算异步任务能力介绍 - 任务触发去重
LVGL 8.2 text shadow
Leetcode 1200 minimum absolute difference [sort] the way of leetcode in heroding
Yyds dry goods inventory # solve the real problem of famous enterprises: continuous maximum sum
内存管理总结
Scratch Castle Adventure Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
Deep learning 7 transformer series instance segmentation mask2former
Opencv learning notes - linear filtering: box filtering, mean filtering, Gaussian filtering
开发中常见问题总结
Explain of SQL optimization
Redis daily notes
LeetCode 1200 最小絕對差[排序] HERODING的LeetCode之路