当前位置:网站首页>JPA规范总结和整理
JPA规范总结和整理
2022-07-05 12:53:00 【Willow】
文章目录
JPA基本注解
1. 基本注解
@Entity
- 标注用于实体类声明语句之前,指出该Java 类为实体类,将映射到指定的数据库表。name 属性(可选)实体名称。 缺省为实体类的非限定名称。该名称用于引用查询中的实体。
- 不与@Table结合的话 表名默认为SnakeCas(命名策略)为表名
- 若使用name属性,且没有与@Table结合,则表名为name值的SnakeCase
@Entity
public class UserInfo{
...} 表名 user_info
@Entity(name="user_info")
public class User{
...} 表名 user_info
@Entity
@Table(name = 'user_info')
public class User{
...} 表名 user_info
@Table
- 当实体类与其映射的数据库表名不同名时需要使用@Table标注说明,该标注与@Entity标注并列使用,置于实体类声明语句之前,可写于单独语句行,也可与声明语句同行。
- Table标注的常用选项是name,用于指明数据库的表名
- Table标注还有一个两个选项 catalog和schema用于设置表所属的数据库目录或模式,通常为数据库名。Mysql不支持catalog,schema是数据库名。一般不需要设置。
- uniqueConstraints 用来批量命名唯一键,其作用等同于多个:@Column(unique = true),通常不须设置。
@Entity
@Table(name = "user_info", uniqueConstraints = {
@UniqueConstraint(columnNames = "department_id")})
public class User {
@Column(name = "department_id", nullable = false, columnDefinition = "varchar(64) comment '部门Id'")
private String departmentId;
}
@Id
- Id 标注用于声明一个实体类的属性映射为数据库的主键列。
- Id标注也可置于属性的getter方法之前。
@GeneratedValue(不填,默认auto)
- JPA通用策略生成器,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment。
- 在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略:
- IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
- AUTO: JPA自动选择合适的策略,是默认选项;
- SEQUENCE:通过序列产生主键,通过 @SequenceGenerator注解指定序列名,MySql不支持这种方式
- TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。该策略一般与另外一个注解一起使用@TableGenerator。
- generator:使用指定的主键生成器时,这里设置为生成器名称
@GenericGenerator
- 自定义主键生成策略
- name:生成器名称
- strategy:预定义的Hibernate 策略或完全限定的类名。uuid: 采用128位的uuid算法生成主键,uuid被编码为一个32位16进制数字的字符串。占用空间大(字符串类型)。native: 对于oracle采用 Sequence 方式,对于MySQL和SQL Server采用identity(自增主键生成机制),native就是将主键的生成工作交由数据库完成,hibernate不管(很常用)。 其他策略等等。
代码中常用,使用uuid生成主键
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "company_info")
public class Company {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "company_name")
private String companyName;
}
@Column
- 当实体的属性与其映射的数据库表的列不同名时需要使用@Column 标注说明,该属性通常置于实体的属性声明语句之前,还可与 @Id 标注一起使用。
- Column 标注的常用属性是name,用于设置映射数据库表的列名。此外,该标注还包含其它多个选填属性:
- unique:是否是唯一标识,默认为 false(不唯一)
- nullable:否允许为 null,默认为true(null)
- insertable:表示在 ORM 框架执行插入操作时,该字段是否应出现INSETRT语句中,默认为true
- updatable:表示在 ORM 框架执行更新操作时,该字段是否应该出现在 UPDATE 语句中,默认为 true。对于一经创建就不可以更改的字段,该属性非常有用,如对于birthday字段。或者创建时间/注册时间(可以将其设置为false不可修改)
- length:数据长度,仅对String类型的字段有效,默认值255
- precision、scale:precision属性和scale属性表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数,默认值均为0.
- columnDefinition:表示该字段在数据库中的实际类型.通常ORM框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是DATE,TIME还是TIMESTAMP.此外,String的默认映射类型为VARCHAR, 如果要将String类型映射到特定数据库的BLOB或TEXT字段类型,该属性非常有用。
- Column标注也可置于属性的getter方法之前
@Basic(未加注解的默认注解)
- Basic 表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为@Basic
- fetch: 表示该属性的读取策略,有EAGER和LAZY两种,分别表示立即加载和延迟加载,默认为 EAGER.
- optional:表示该属性是否允许为null, 默认为true
2. @Transient
- 表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性.
- 如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Basic
@Entity
@Table(name = "company_info")
public class Company {
@Id
@Column(name = "id")
@GenericGenerator(name="idGenerator", strategy="uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Transient
private String history;
@Column(name = "name")
private String name;
}
[email protected]
- 直接映射枚举类型的字段
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "company_info")
public class Company {
@Column(name = "status", columnDefinition = "tinyint(2) DEFAULT 0 NOT NULL COMMENT '公司状态(0.正常,1.倒闭)'")
@Enumerated
private CompanyStatus status;
}
4. @Temporal
- 在数据库中,表示Date类型的数据有DATE, TIME, 和 TIMESTAMP三种精度(即单纯的日期,时间,或者两者兼备). 在进行属性映射时可使用@Temporal注解来调整精度.
@Entity
@Data
@Table(name = "company_info")
public class Company {
@Column(name = "tmp_time")
@Temporal(TemporalType.DATE)
private Date tmpTime;
}
[email protected]、@DynamicUpdate
@DynamicInsert属性:设置为true,表示insert对象的时候,生成动态的insert语句,如果这个字段的值是null就不会加入到insert语句中。
如希望数据库插入日期或时间戳字段时,在对象字段为空定的情况下,表字段能自动填写当前的日期。@DynamicUpdate属性:设置为true,表示update对象的时候,生成动态的update语句,如果这个字段的值是null就不会被加入到update语句中。
如只想更新某个属性,但是却把整个属性都更改了,这并不是希望的结果。期望的结果是只更新需要更改的几个字段。
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "user")
@DynamicInsert
@DynamicUpdate
public class User {
@Id
@Column(name = "id", columnDefinition = "varchar(64)")
@GenericGenerator(name="idGenerator", strategy="uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "name", columnDefinition = "varchar(128) default null")
private String name;
@Basic
private Integer age;
@Column(name = "create_time")
private Long createTime;
@Column(name = "remark", columnDefinition = "varchar(255) default null")
private String remark;
}
保存一条数据时,如果加上@DynamicInsert时,sql为:
Hibernate: insert into user (age, create_time, name, id) values (?, ?, ?, ?)
若去掉@DynamicInsert时,sql为:
Hibernate: insert into user (age, create_time, name, remark, id) values (?, ?, ?, ?, ?)
[email protected]
- @Access:指定实体的访问模式(Access mode),包括AccessType.FIELD及AccessType.PROPERTY。
- 字段访问(@Column注解在属性上),通过字段来获取或设置实体的状态,getter和setter方法可能存在或不存在。这样JPA默认的访问类型为AccessType.FIELD。
- 属性访问(@Column注解在get方法上),持久化属性必须有getter和setter方法,属性的类型由getter方法的返回类型决定,同时必须与传递到setter方法的单个参数的类型相同。这样JPA默认的访问类型为AccessType.PROPERTY。
7.复合主键实现
@[email protected]
- @Embeddable:注释Java类的,表示类是嵌入类
- @EmbeddedId:复合主键
1.必须要实现Serializable接口
2.需要有无参的构造函数
当需要多个属性作为复合主键时,可以把该属性做为一个内部类嵌套在实体类中,使用@[email protected]实现
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "statistics_record")
public class RecordInfo {
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Embeddable
public static class RecordKey implements Serializable {
@Column(name = "id")
private Integer id;
@Column(name = "country_code")
private String countryCode;
}
@EmbeddedId
private RecordInfo.RecordKey key;
@Column(name = "count")
private Long count;
}
@@IdClass
- @IdClass:注解复合主键的类
复合主键类必须满足:
- 实现Serializable接口;
- 有默认的public无参数的构造方法;
- 重写equals和hashCode方法。
// 复合主键类
public class RecordKey implements Serializable {
@Column(name = "id")
private Integer id;
@Column(name = "country_code")
private String countryCode;
}
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@IdClass(RecordKey.class)
@Table(name = "statistics_record")
public class RecordInfo {
@Id
private Integer id;
@Id
private String countryCode;
@Column(name = "count")
private Long count;
}
@[email protected]
- @Embedded:注释属性的,表示该属性的类是嵌入类。
- @AttributeOverrides:里面只包含了@AttributeOverride类型数组。
- @AttributeOverride:包含要覆盖的@Embeddable类中字段名name和新增的@Column字段的属性。
@Data
@Embeddable
public class RecordKey implements Serializable {
private Integer articleId;
private String countryCode;
}
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "statistics_article")
public class RecordInfo {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Embedded
@AttributeOverrides( {
@AttributeOverride(name = "articleId", column = @Column(name = "article_id")),
@AttributeOverride(name = "countryCode", column = @Column(name = "country_code")) })
private RecordKey key;
@Column(name = "count")
private Long count;
}
8. 实体间关联关系
@OneToOne关系映射
标注一对一的关系。
- fetch:立即加载和延迟加载
- cascade:当前类对象操作了之后,级联对象的操作。
- REMOVE:级联删除操作。删除当前实体时,与它有映射关系的实体也会跟着被删除。
- MERGE:级联更新(合并)操作。当前对象中的数据改变,会相应地更新级联对象中的数据。
- DETACH:级联脱管/游离操作。如果要删除一个实体,但是它有外键无法删除,你就需要这个级联权限了。它会撤销所有相关的外键关联。
- REFRESH:级联刷新操作。更新数据前先刷新对象和级联对象,再更新。
- PERSIST:级联持久化(保存)操作。持久保存拥有方实体时,也会持久保存该实体的所有相关数据。
- ALL,当前类增删改查改变之后,关联类跟着增删改查,拥有以上所有级联操作权
- mappedBy:拥有关联关系的域,如果关系是单向的就不需要,双向关系表,那么拥有关系的这一方有建立、解除和更新与另一方关系的能力,而另一方没有,只能被动管理,这
个属性被定义在关系的被拥有方。 - orphanRemoval:如果设置为true,当关系被断开时,多方实体将被删除。否则会将对象的引用置为null。
- targetEntity:表示该属性关联的实体类型.该属性通常不必指定,orm框架根据属性类型自动判断
实体People :用户。
实体Address:家庭住址。
People和Address是一对一的关系。
两种方式描述JPA的一对一关系:
- 通过外键的方式(一个实体通过外键关联到另一个实体的主键);
- 通过一张关联表来保存两个实体一对一的关系。
- 通过外键的方式
people 表(id,name,sex,birthday,address_id)
address 表(id,phone,zipcode,address)
@JoinColum:保存表与表之间关系的字段,它要标注在实体属性上。一般修饰在主控方,用来定义一对一,一对多等关系列。
关联的实体的主键一般是用来做外键的。但如果此时不想主键作为外键,则需要设置referencedColumnName属性。当然这里关联实体(Address)的主键 id 是用来做主键,所以这里第20行的 referencedColumnName = “id” 实际可以省略。
@Entity
public class People {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "name", nullable = true, length = 20)
private String name;//姓名
@Column(name = "sex", nullable = true, length = 1)
private String sex;//性别
@Column(name = "birthday", nullable = true)
private Timestamp birthday;//出生日期
@OneToOne(cascade=CascadeType.ALL)//People是关系的维护端,当删除 people,会级联删除 address
@JoinColumn(name = "address_id", referencedColumnName = "id")//people中的address_id字段参考address表中的id字段
private Address address;//地址
}
@Entity
public class Address {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "phone", nullable = true, length = 11)
private String phone;//手机
@Column(name = "zipcode", nullable = true, length = 6)
private String zipcode;//邮政编码
@Column(name = "address", nullable = true, length = 100)
private String address;//地址
//如果不需要根据Address级联查询People,可以注释掉
// @OneToOne(mappedBy = "address", cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false)
// private People people;
}
- 通过关联表的方式来保存一对一的关系。
关联表:people_address (people_id,address_id)
@JoinTable:用于构建一对多,多对多时的连接表,默认会以主控表加下划线加反转表为表名。JoinColumns:该属性值可接受多个@JoinColumn,用于配置连接表中外键列的信息,这些外键列参照当前实体对应表的主键列。inverseJoinColumns:该属性值可接受多个@JoinColumn,用于配置连接表中外键列的信息,这些外键列参照当前实体的关联实体对应表的主键列。
@Entity
public class People {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;//id
@Column(name = "name", nullable = true, length = 20)
private String name;//姓名
@Column(name = "sex", nullable = true, length = 1)
private String sex;//性别
@Column(name = "birthday", nullable = true)
private Timestamp birthday;//出生日期
@OneToOne(cascade=CascadeType.ALL)//People是关系的维护端
@JoinTable(name = "people_address",
joinColumns = @JoinColumn(name="people_id"),
inverseJoinColumns = @JoinColumn(name = "address_id"))//通过关联表保存一对一的关系
private Address address;//地址
}
@Entity
public class Address {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "phone", nullable = true, length = 11)
private String phone;//手机
@Column(name = "zipcode", nullable = true, length = 6)
private String zipcode;//邮政编码
@Column(name = "address", nullable = true, length = 100)
private String address;//地址
//如果不需要根据Address级联查询People,可以注释掉
// @OneToOne(mappedBy = "address", cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false)
// private People people;
}
@OneToMany和@ManyToOne
标示一对多和多对一关系。
实体 Author:作者。
实体 Article:文章。
Author和Article是一对多关系(双向)。JPA使用@OneToMany和@ManyToOne来标识一对多的双向关联。一端(Author)使用@OneToMany,多端(Article)使用@ManyToOne。
在JPA规范中,一对多的双向关系由多端(Article)来维护。就是说多端(Article)为关系维护端,负责关系的增删改查。一端(Author)则为关系被维护端,不能维护关系。
一端(Author)使用@OneToMany注释的mappedBy="author"属性表明Author是关系被维护端。
多端(Article)使用@ManyToOne和@JoinColumn来注释属性author,@ManyToOne表明Article是多端,@JoinColumn设置在article表中的关联字段(外键)。
最终生成的表结构
article 表(id,title,content,author_id)
author 表(id,name)
@Entity
public class Author {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(nullable = false, length = 20)
private String name;//姓名
@OneToMany(mappedBy = "author",cascade=CascadeType.ALL,fetch=FetchType.LAZY)
//级联保存、更新、删除、刷新;延迟加载。当删除用户,会级联删除该用户的所有文章
//拥有mappedBy注解的实体类为关系被维护端
//mappedBy="author"中的author是Article中的author属性
private List<Article> articleList;//文章列表
}
@Entity
public class Article {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(nullable = false, length = 50)
private String title;
@Lob // 大对象,映射 MySQL 的 Long Text 类型
@Basic(fetch = FetchType.LAZY) // 懒加载
@Column(nullable = false)
private String content;//文章全文内容
@ManyToOne(cascade={
CascadeType.MERGE,CascadeType.REFRESH},optional=false)//可选属性optional=false,表示author不能为空。删除文章,不影响用户
@JoinColumn(name="author_id")//设置在article表中的关联字段(外键)
private Author author;//所属作者
}
@ManyToMany关系映射
标注多对多的关系。
实体Role:角色。
实体Permission:权限。
角色和权限是多对多的关系。一个角色可以有多个权限,一个权限也可以被很多角色拥有。
最终生成的表结构
user_permission 表(id,permission_name)
user_role 表(id,department_id, create_time, description, name, update_time)
user_role_to_permission 表(role_id, permission_id)
JPA中使用@ManyToMany来注解多对多的关系,由一个关联表来维护。这个关联表的表名默认是:主表名+下划线+从表名。(主表是指关系维护端对应的表Role,从表指关系被维护端对应的表Permission)。这个关联表只有两个外键字段,分别指向主表ID和从表ID。字段的名称默认为:主表名+下划线+主表中的主键列名,从表名+下划线+从表中的主键列名。
注意:
1、多对多关系中一般不设置级联保存、级联删除、级联更新等操作。
2、本例中,由于加了@JoinTable注解,关联关系表会按照注解指定的生成。否则去掉注解,指定Role为关系维护端,所以生成的关联表名称为:user_role_permission,关联表的字段为:role_id 和permission_id。
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "user_permission")
public class Permission implements Comparable<Permission> {
@Id
@Column(name = "id")
private String id;
@Column(name = "permission_name", nullable = false)
private String permissionName;
@ManyToMany(mappedBy="permissions")
private Set<Role> roles;
@Override
public boolean equals(Object object) {
if (object instanceof Permission) {
return ((Permission)object).getRule().equals(this.permissionName);
}
return false;
}
@Override
public int compareTo(Permission target) {
return this.getId().compareTo(target.getId());
}
}
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "user_role")
@ToString(exclude = "permissions")
public class Role {
@Id
@Column(name = "id")
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "create_time")
private Long createTime;
@Column(name = "update_time")
private Long updateTime;
@Column(name = "name")
private String name;
@Column(name = "description")
private String description;
@Column(name = "department_id")
private String departmentId;
@ManyToMany(fetch = FetchType.EAGER, cascade = CascadeType.ALL)
@JoinTable(name = "user_role_permission", joinColumns = {
@JoinColumn(name = "role_id")},
inverseJoinColumns = {
@JoinColumn(name = "permission_id")})
private List<Permission> permissions;
}
9. spring-data-jpa注解@Query、@Modifying
@Query
@Query注解用于使用JPQL执行数据库操作,或者使用原生sql对数据库操作,只支持对数据查询的操作,如果需要进行对数据的修改(update或delete)那就必须配合@Modifying注解使用。
使用命名参数的方式,配合@Param注解一起使用
@Modifying
用于提示JPA该操作是修改操作。
- clearAutomatically:为 true 时,执行完modifying query后就会清理缓存。
- flushAutomatically:为 true 时,执行modifying query前会先调用flush操作。
注意:@Modifying需要与@Transactional配合使用才能正常使用
@Modifying的主要作用是声明执行的SQL语句是更新(增删改)操作,@Transactional的主要作用是提供事务支持
默认情况下JPA的每个操作都是事务的,在默认情况下,JPA的事务会设置为只读。声明了@Transactional,本质上是声明了@Transactional(readOnly=false),这样覆盖了默认的@Transactional配置便可以执行修改。
@Repository
public interface CompanyRepository extends JpaRepository<Company, Serializable> {
// 使用JPQL执行查询
@Query(value = "select distinct entity from Company entity where entity.id = :id")
Company findById(@Param("id") String id);
// 使用原生sql执行删除操作,配合@Modifying、 @Transactional使用
@Modifying
@Transactional(propagation = Propagation.REQUIRED)
@Query(value = "DELETE FROM company_info where id=:companyId", nativeQuery = true)
void deleteByCompanyId(@Param("companyId") String companyId);
}
insertable = false, updatable = false
SpringDataJPA对数据库操作方式
继承JpaRepository接口
继承JpaRepository接口,可以按照规范创建查询方法(一般按照java驼峰式书写规范加一些特定关键字),或者使用@Query自定义查询方法。
@Repository
public interface CompanyRepository extends JpaRepository<Company, Serializable> {
// 使用规范创建查询方法
List<Company> findByCountryAndDeleteFlagIsFalse(@Param("country") String country);
// 使用@Query自定义方法
@Query(value = "select distinct entity from Company entity where entity.id = :id")
Company findById(@Param("id") String id);
}
动态复杂查询使用EntityManager
需要联多个表或根据不同的条件进行查询的复杂sql,可以使用EntityManager的方法进行查询。最常用的是针对复杂原生sql的查询,使用createNativeQuery方法。
获取EntityManager:可以通过@PersistenceContext注解标注在EntityManager类型的字段上,这样得到的EntityManager就是容器管理的。
@Repository
public class UserNativeRepositoryImpl {
@PersistenceContext
private EntityManager entityManager;
public List<User> getUsersByCondition(String id, String name, Integer age) {
List<User> result = Collections.emptyList();
String selectSql = " SELECT * FROM user ";
StringBuilder whereSql = new StringBuilder("where 1=1 ");
if (!StringUtils.isEmpty(id)){
whereSql.append(" and id =:id");
}
if (!Objects.isNull(age)){
whereSql.append(" and age =:age");
}
if (!StringUtils.isEmpty(name)){
whereSql.append(" and name like :search");
}
String sql = selectSql + whereSql.toString();
Query nativeQuery = entityManager.createNativeQuery(sql);
if (!StringUtils.isEmpty(id)){
nativeQuery.setParameter("id", id);
}
if (!Objects.isNull(age)){
nativeQuery.setParameter("age", age);
}
if (!StringUtils.isEmpty(name)){
nativeQuery.setParameter("search", "%" + name + "%");
}
nativeQuery.unwrap(NativeQueryImpl.class).setResultTransformer(new IgnoreTypeResultTransformer(User.class));
result = nativeQuery.getResultList();
return result;
}
}
List<User> usersByCondition = userNativeRepository.getUsersByCondition("", "", 20);
继承JpaSpecificationExecutor接口
JpaSpecificationExecutor(JPA规则执行者)是JPA2.0提供的Criteria API的使用封装,可以用于动态生成Query来满足业务中的各种复杂场景。
Spring Data JPA为我们提供了JpaSpecificationExecutor接口,只要简单实现toPredicate方法就可以实现复杂的查询。所有查询都要求传入一个Specification对象。
// 实体类 user
@Entity(name = "user")
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User {
@Id
@Column(name = "id", columnDefinition = "varchar(64)")
@GenericGenerator(name="idGenerator", strategy="uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "name", columnDefinition = "varchar(128) default null")
private String name;
@Basic
private Integer age;
@Column(name = "create_time")
private Long createTime;
@Column(name = "remark", columnDefinition = "varchar(255) default null")
private String remark;
}
// 操作数据库,继承JpaSpecificationExecutor接口
@Repository
public interface UserRepository extends JpaRepository<User, Serializable>, JpaSpecificationExecutor<User> {
}
// 查询符合条件的所有对象,输入一个Specification对象
public List<User> getUsers(String id, String name, Integer age) {
return userRepository.findAll(buildQuery(id, name, age));
}
private Specification<User> buildQuery(String id, String name, Integer age) {
return (Specification<User>) (root, criteriaQuery, criteriaBuilder) -> {
List<Predicate> addConditions = new ArrayList<>();
if (!StringUtils.isEmpty(id)) {
addConditions.add(criteriaBuilder.equal(root.get("id").as(String.class), id));
}
if (!Objects.isNull(age)) {
addConditions.add(criteriaBuilder.equal(root.get("age").as(Integer.class), age));
}
if (!StringUtils.isEmpty(name)) {
addConditions.add(criteriaBuilder.like(root.get("name").as(String.class), new StringBuffer("%").append(name).append("%").toString()));
}
Predicate and = criteriaBuilder.and(addConditions.toArray(new Predicate[addConditions.size()]));
return criteriaQuery.where(and).getRestriction();
};
}
边栏推荐
- Put functions in modules
- RHCSA5
- 实现 1~number 之间,所有数字的加和
- 滴滴开源DELTA:AI开发者可轻松训练自然语言模型
- MySQL giant pit: update updates should be judged with caution by affecting the number of rows!!!
- 【云原生】Nacos-TaskManager 任务管理的使用
- Shu tianmeng map × Weiyan technology - Dream map database circle of friends + 1
- DataPipeline双料入选中国信通院2022数智化图谱、数据库发展报告
- Overflow toolbar control in SAP ui5 view
- Write macro with word
猜你喜欢
SAP SEGW 事物码里的导航属性(Navigation Property) 和 EntitySet 使用方法

Le rapport de recherche sur l'analyse matricielle de la Force des fournisseurs de RPA dans le secteur bancaire chinois en 2022 a été officiellement lancé.
使用 jMeter 对 SAP Spartacus 进行并发性能测试

LB10S-ASEMI整流桥LB10S
uni-app开发语音识别app,讲究的就是简单快速。
Notes for preparation of information system project manager --- information knowledge
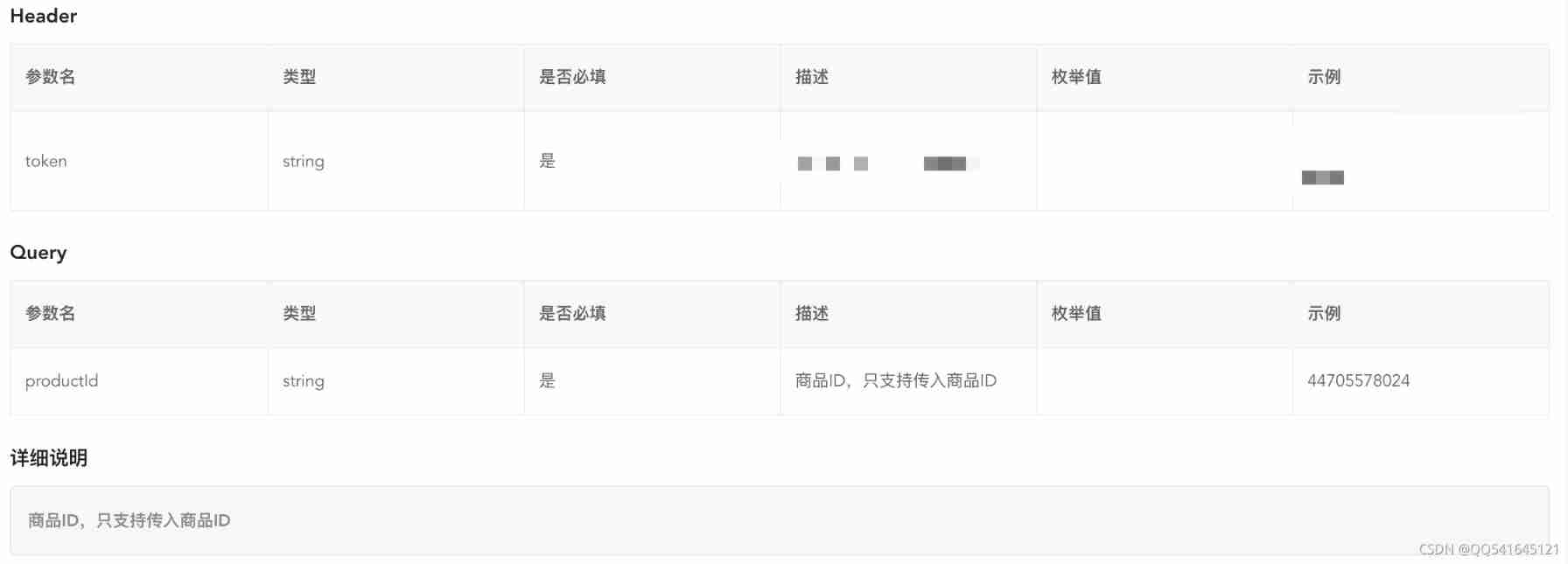
Taobao product details API | get baby SKU, main map, evaluation and other API interfaces
开发者,云原生数据库是未来吗?
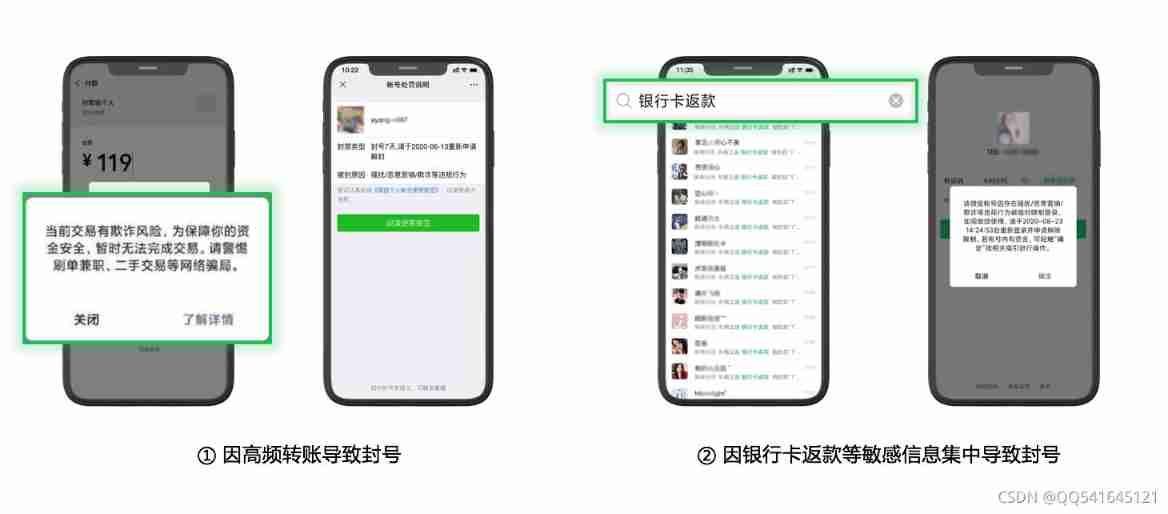
Four common problems of e-commerce sellers' refund and cash return, with solutions
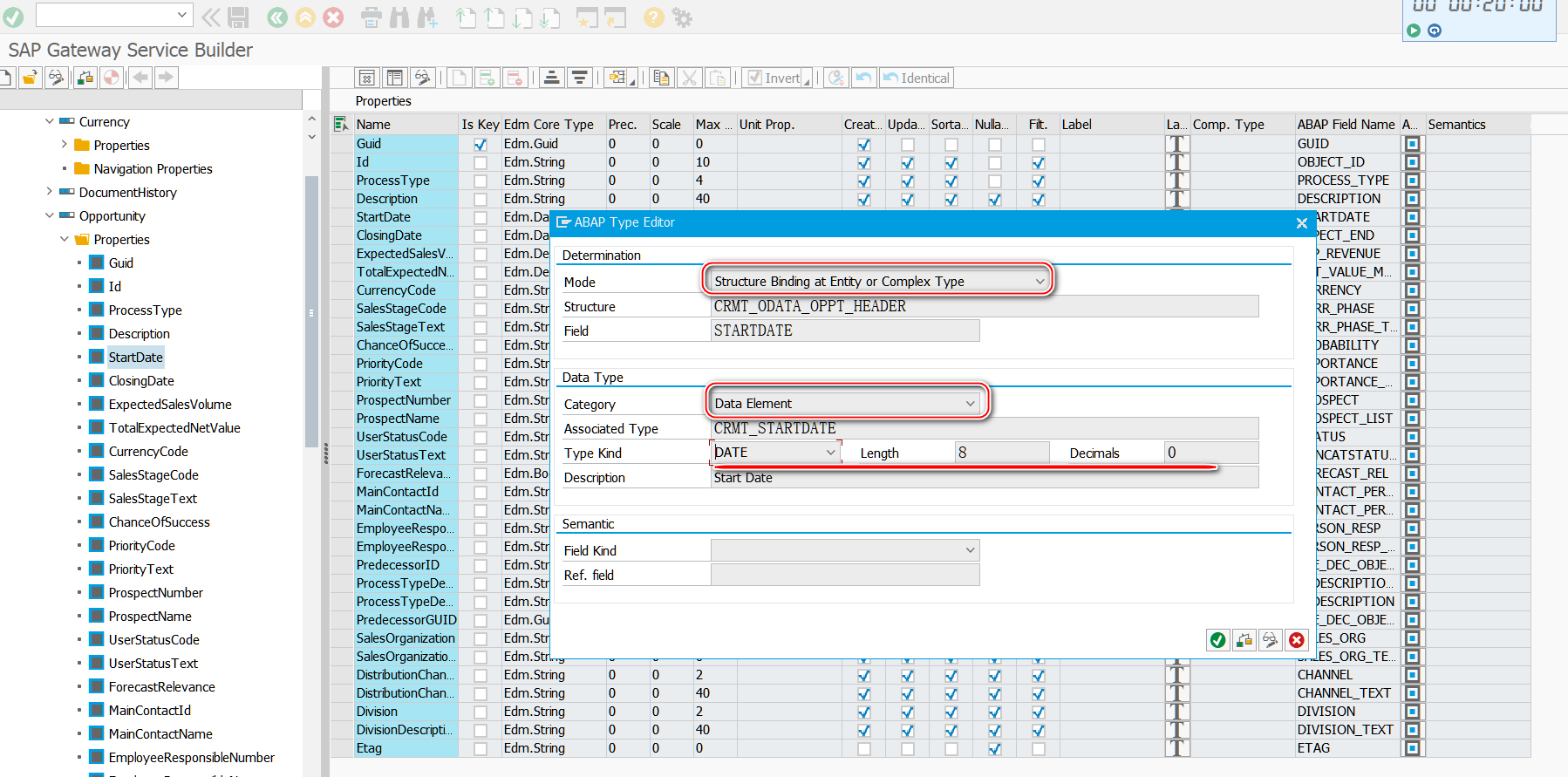
A specific example of ABAP type and EDM type mapping in SAP segw transaction code
随机推荐
SAP SEGW 事物码里的 ABAP Editor
你的下一台电脑何必是电脑,探索不一样的远程操作
How to protect user privacy without password authentication?
Notes for preparation of information system project manager --- information knowledge
A deep long article on the simplification and acceleration of join operation
What is the difference between Bi software in the domestic market
155. 最小栈
mysql拆分字符串做条件查询
Rocky basics 1
How can non-technical departments participate in Devops?
RHCSA4
[cloud native] use of Nacos taskmanager task management
Taobao short video, why the worse the effect
从外卖点单浅谈伪需求
Put functions in modules
Halcon template matching actual code (I)
无密码身份验证如何保障用户隐私安全?
SAP UI5 DynamicPage 控件介绍
Reverse Polish notation
Cf:a. the third three number problem