当前位置:网站首页>[Galaxy Kirin V10] [server] NUMA Technology
[Galaxy Kirin V10] [server] NUMA Technology
2022-07-04 10:32:00 【GUI Anjun @kylinos】
1、numa Introduce
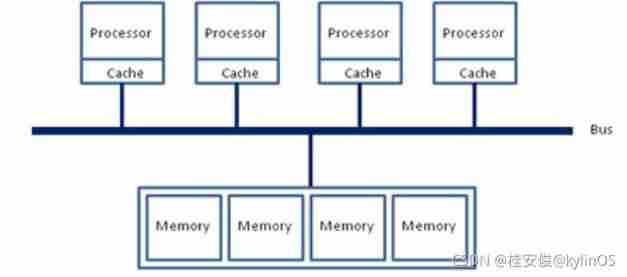
In the early , about x86 A computer of architecture , At that time, the memory controller had not been integrated CPU, All memory accesses need to be completed through Beiqiao chip . The memory access at this time is shown in the following figure , go by the name of UMA(uniform memory access, Consistent memory access ). Such access is very easy to achieve at the software level : The bus model ensures that all memory accesses are consistent , There is no need to consider the differences before different memory addresses .
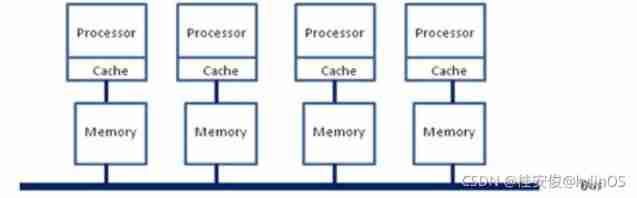
After that x86 The platform has experienced a change from “ Spelling frequency ” To “ Put together the number of cores ” The transformation of , More and more cores are crammed into the same chip as much as possible , The competing access of each core to memory bandwidth has become a bottleneck ; Software at this time 、OS For SMP Multi core CPU The support of is becoming more and more mature ; Plus various commercial considerations ,x86 The platform also pushed the boat forward NUMA(Non-uniform memory access, Inconsistent memory access ). Under this framework , Every Socket There will be an independent memory controller IMC(integrated memory controllers, Integrated memory controller ), Belong to different socket Within IMC Through between QPI link Communications .
Then there is further architecture evolution , Because each socket There will be more than one in every city core Make memory access , This will happen in every core There is a similar phenomenon in the interior of the first SMP Memory access bus with similar architecture , This bus is called IMC bus.
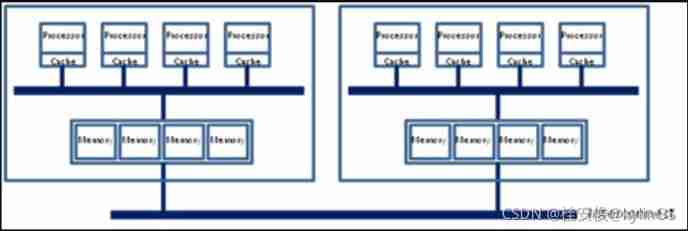
therefore , The obvious , Under this framework , Two socket Their management 1/2 The memory slot of , If you want to access something that does not belong to this socket Of memory must pass QPI link. That is to say, there is a local problem of memory access / long-range (local/remote) The concept of , There will be a significant difference in memory latency . That's why NUMA The reason why the performance of some applications under the architecture is worse .
Back to the present world CPU, The engineering implementation is actually more complicated . In view of , Two Socket Between them through their own 9.6GT/s Of QPI link Mutual visits . And each Socket In fact, there are 2 A memory controller . Double channel , Each controller has two more memory channels (channel), Each channel supports up to 3 Root memory module (DIMM). Theoretically, the largest order socket Support 76.8GB/s The memory bandwidth of , And two QPI link, Every QPI link Yes 9.6GT/s Rate (~57.6GB/s) in fact QPI link There has been a bottleneck .

Kernel NUMA Default behavior of ,Linux The kernel , The document defines NUMA Data structure and operation mode . In one, enabled NUMA Supported by Linux in ,Kernel Does not remove task memory from a NUMA node Move to another NUMA node.
Once a process is enabled , Where it is NUMA node They won't be moved , In order to optimize the performance as much as possible , In normal dispatch ,CPU Of core It will be used as much as possible local Visit the local core, Throughout the life cycle of a process ,NUMA node remain unchanged .
Once someone NUMA node The load of exceeds that of another node A threshold ( Default 25%), I think we need to be here node Reduce the load on , Different NUMA Structure and different load conditions , The system gives a delay task migration —— Similar to the leaky cup algorithm . In this case, memory will be generated remote visit .
NUMA node There are different topologies between , each node There will be a distance between visits (node distances) The concept of , Such as numactl -H The result of the command has such a description :node distances:
node 0 1 2 3
0: 10 11 21 21
1: 11 10 21 21
2: 21 21 10 11
3: 21 21 11 10
It can be seen that :0 node To 0 node The distance between is 10, This must be the closest distance , Not to mention .0-1 The distance between them is far less than 2 or 3 Distance of . This distance is convenient for the system to choose the most suitable one in complex situations NUMA Set up .
2、numa Tool installation
# yum install numa* -y
3、numa see
See if... Is supported numa
# dmesg | grep -i numa
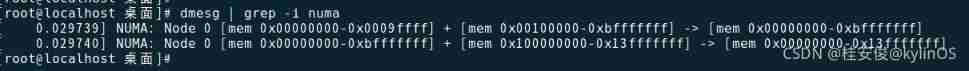
see numa state
# numastat
[[email protected] desktop ]# numastat
node0
numa_hit 2186088 #numa_hit Is to allocate memory on this node , The last number of times allocated from this node
numa_miss 0 #numa_miss Is to allocate memory on this node , The number of times it was finally allocated from other nodes
numa_foreign 0 #numa_foregin Is to allocate memory on other nodes , The number of times it was finally allocated from this node
interleave_hit 27325 #interleave_hit Is to use interleave The number of times the policy was last allocated from that node ;
local_node 2186088 #local_node The number of times processes on this node have been allocated on this node
other_node 0 #other_node Is the number of times other node processes have allocated on that node
[[email protected] desktop ]#
#lscpu | grep -i numa // Look at each numa node Of cpu Information

see Numa node Information
# numactl --hardware
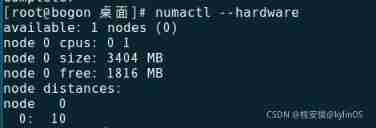
see numa The binding information
# numactl --show
[[email protected] desktop ]# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 # Nuclear binding
cpubind: 0 #CPU binding
nodebind: 0 #node binding
membind: 0 # Memory binding 4、numa test
( Accessing the memory of different nodes IO)
1) write test
# numactl --cpubind=0 --membind=0 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.823497 s, 1.3 GB/s
# numactl --cpubind=0 --membind=1 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.936182 s, 1.1 GB/s
Obviously, accessing the memory of the same node is faster than accessing the memory of different nodes .
2) read test
# numactl --cpubind=0 --membind=0 dd if=/dev/shm/A of=/dev/null bs=1K count=1024K
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.09543 s, 980 MB/s
# numactl --cpubind=0 --membind=1 dd if=/dev/shm/A of=/dev/null bs=1K count=1024K
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.11862 s, 960 MB/s
Conclusion and write identical . But the gap is small .
5、numa Open and close
NUMA Can be in BIOS and OS Two level switch , In fact, there is no detailed information about the difference between the two levels of switches on the Internet . There is a saying that :BIOS and OS The closing of the NUMA stay interleave There are differences in granularity ,BIOS It should be cache line(64B) Granularity , and OS Use the kernel page table, so it is a page (4kB) Granularity . In effect BIOS The performance should be more stable , but OS The configuration of is relatively more convenient .
BIOS layer Of NUMA Set up :
1. see BIOS Is the layer on NUMA
# grep -i numa /var/log/dmesg
# 1. If "No NUMA configuration found"
# shows NUMA by disable.
#
# 2. If not "No NUMA configuration found"
# shows NUMA by enable.
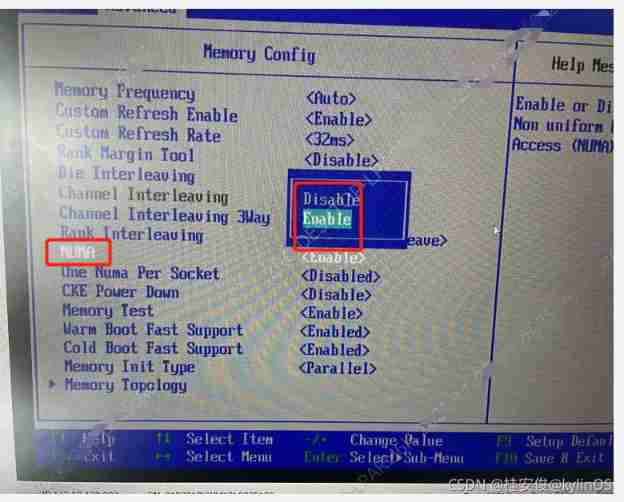
2. modify BIOS interleave
Be careful , because BIOS A wide variety , Please take the actual situation as the case may be .
Parameter path :
BIOS: interleave
The set value :
Disable # interleave close , Turn on NUMA.
Enable # interleave Turn on , close NUMA.
With TaiShan 200 The server bios For example :

OS layer Of NUMA Set up
1、 close numa
# vim /etc/default/grub // Add as shown in the figure below :numa=off

# grub2-mkconfig -o /etc/grub2.cfg // To regenerate the /etc/grub2.cfg The configuration file
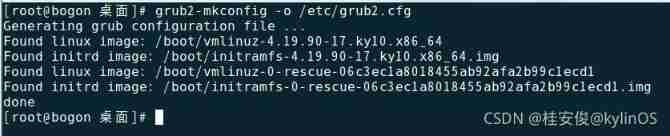
# reboot // Restart the system
# dmesg | grep -i numa // Check whether it is closed after restart

# cat /porc/cmdline // Confirm the current kernel startup parameters

2、 open numa
Refer to close numa Setting process , Only need to /etc/default/grub Added in numa=off Get rid of , Then regenerate grub2.conf, Restart the system
边栏推荐
- What is devsecops? Definitions, processes, frameworks and best practices for 2022
- Batch distribution of SSH keys and batch execution of ansible
- How to quickly parse XML documents through C (in fact, other languages also have corresponding interfaces or libraries to call)
- Const's constant member function after the function; Form, characteristics and use of inline function
- What is an excellent architect in my heart?
- Devop basic command
- MongoDB数据日期显示相差8小时 原因和解决方案
- Virtual machine configuration network
- uniapp 处理过去时间对比现在时间的时间差 如刚刚、几分钟前,几小时前,几个月前
- Reprint: summation formula of proportional series and its derivation process
猜你喜欢
![[200 opencv routines] 218 Multi line italic text watermark](/img/3e/537476405f02f0ebd6496067e81af1.png)
[200 opencv routines] 218 Multi line italic text watermark
Dynamic address book
Realsense of d435i, d435, d415, t265_ Matching and installation of viewer environment
Dichotomy search (C language)
如果不知道這4種緩存模式,敢說懂緩存嗎?
When I forget how to write SQL, I
uniapp 小于1000 按原数字显示 超过1000 数字换算成10w+ 1.3k+ 显示

Jianzhi offer 04 (implemented in C language)

The bamboo shadow sweeps the steps, the dust does not move, and the moon passes through the marsh without trace -- in-depth understanding of the pointer
Occasional pit compiled by idea
随机推荐
Map container
From programmers to large-scale distributed architects, where are you (I)
有老师知道 继承RichSourceFunction自定义读mysql怎么做增量吗?
Sword finger offer 31 Stack push in and pop-up sequence
If you don't know these four caching modes, dare you say you understand caching?
Uniapp--- initial use of websocket (long link implementation)
Write a program to define an array with 10 int elements, and take its position in the array as the initial value of each element.
Es entry series - 6 document relevance and sorting
C language structure to realize simple address book
/*Rewrite the program, find the value of the element, and return the iterator 9.13: pointing to the found element. Make sure that the program works correctly when the element you are looking for does
Some summaries of the third anniversary of joining Ping An in China
Servlet基本原理与常见API方法的应用
VLAN part of switching technology
Network disk installation
Lavel document reading notes -how to use @auth and @guest directives in lavel
Realsense d435 d435i d415 depth camera obtains RGB map, left and right infrared camera map, depth map and IMU data under ROS
Button wizard business running learning - commodity quantity, price reminder, judgment Backpack
Knapsack problem and 0-1 knapsack problem
Architecture introduction
leetcode1229. Schedule the meeting