当前位置:网站首页>Introduction to extensible system architecture
Introduction to extensible system architecture
2022-07-04 10:16:00 【JoesonChan】
Translated from :https://lethain.com/introduction-to-architecting-systems-for-scale/

Few computer science or software development programs attempt to teach the building blocks of scalable systems . In its place , The system architecture is usually By solving the pain of growing products Or with engineers who have learned from this painful process .
In this article , I will try to record some in Yahoo! Scalability architecture lessons learned when using the system on . and Digg.
I try to maintain the color convention of the chart :
- green Is an external request from an external client ( From the browser HTTP Request etc. ),
- Blue It's your code running in a container ( stay mod_wsgi On Running Django application , monitor RabbitMQ Of Python Script etc. ), as well as
- Red Is part of the infrastructure (MySQL,Redis,RabbitMQ etc. ).
Load balancing
An ideal system increases capacity linearly by adding hardware . In such a system , If you have one computer and add another , Then the capacity will double . If you have three , Then add another , Then the capacity will increase 33%. Let's call it Horizontal scalability .
In terms of faults , The ideal system will not be interrupted by server loss . The loss of servers should only reduce the system capacity by the same amount as the increase of the overall capacity when adding . We call this redundancy .
Horizontal scalability and redundancy are usually achieved through load balancing .
( This article will not cover Vertical scalability , Because it is usually unpopular for large systems , Because this is inevitable , That is, adding capacity in the form of capacity on other computers is cheaper than adding resources on one computer , And redundancy and vertical scaling may contradict each other .)

Load balancing is based on certain metrics ( Random , loop , Random variables weighted to machine capacity ) And its current state ( Can be used to request , Do not respond to , Higher error rate ) The process of distributing requests among multiple resources .
Need to be in the user request and Web Load balancing between servers , But the load must also be balanced at each stage , To achieve full scalability and redundancy of the system . A medium-sized system may balance the load at three levels :
- Users access your Web The server ,
- Web Server to internal platform layer ,
- Internal platform layer to database .
There are many ways to achieve load balancing .
Smart customers
Usually , Add the load balancing function to the database client ( cache , Service etc. ) It is an attractive solution for developers . It's the simplest solution , Whether it is attractive ? Usually not Is it the most attractive , Because it is the most attractive ? Sadly, there is no . Is it because it is easy to reuse and attractive ? It is sad , No, .
Developers tend to be smart clients , Because they're developers , So they are used to writing software to solve problems , And smart client is software .
Keep this warning in mind , What is a smart customer ? It's a client , It uses a set of service hosts and balances the load between them , Detect the failed host and avoid sending requests in its way ( They must also detect the recovered host , Deal with new hosts added , Make them interesting in order to work decently and have a horrible setup ).
Hardware load balancer
Load balancing is the most expensive ( But the performance is very good ) The solution is to buy a dedicated hardware load balancer ( Be similar to Citrix NetScaler). Although they can solve all kinds of problems , But hardware solutions are very expensive , And configuration “ It's not easy ”.
thus , Even large companies , Even if the budget is large , It also often avoids using dedicated hardware to meet all its load balancing requirements ; In its place , They only use them as the first point of contact from user requests to their infrastructure , And use other mechanisms ( Smart client or hybrid approach discussed in next section ) Load balance the traffic in the network .
Software load balancer
If you want to avoid the trouble of creating smart clients , And buy too much dedicated hardware , that Universe It's enough to provide mixed Services : Software load balancer .
HAProxy It is a good example of this method . It runs locally on each of your chassis , And each service you want to load balance has a locally bound port . for example , You may also have access to platform computers localhost:9000 when , Read pool in your database localhost:9001, And write pool in your database localhost:9002.HAProxy Health checks will be managed , And the computer will be deleted and returned to these pools according to your configuration , And balance all the computers in these pools .
For most systems , I suggest starting with software load balancer , Then turn to smart client or hardware load balancing only when necessary .
Get it
Load balancing helps you scale horizontally on an increasing number of servers , But caching will enable you to make better use of existing resources , And make other unattainable product requirements feasible .
Caching includes : Pre calculated results ( for example , Number of visits from each reference domain the previous day ), Pre generate expensive indexes ( for example , Suggested story based on user's click history ) And storing copies of frequently accessed data in a faster back end ( for example Memcache instead of PostgreSQL.
In practice , Caching is more important than load balancing in the development process , And starting with a consistent caching strategy can save time in the future . It also ensures that you do not optimize access patterns that cannot be replicated with your caching mechanism or that performance becomes unimportant after adding caching ( I found many highly optimized Cassandra Applications are a challenge for adding cache cleanly . unable / When can't you apply the cache policy of the database to your access mode , because Cassandra The data model is usually inconsistent with the cache ).
Application and database caching
There are two main ways to cache : Application cache and database cache ( Most systems rely heavily on both ).

Application caching requires explicit integration in the application code itself . Usually , It will check whether there are values in the cache ; If not , Then retrieve the value from the database ; Then write the value to the cache ( If you are using observation The least recently used cache algorithm The cache of , Then this value is particularly common ). This code usually looks like ( Especially this is a A read-only cache , Because if the value is missing from the cache , It will read the value from the database ):
key = "user.%s" % user_id user_blob = memcache.get(key) if user_blob is None: user = mysql.query("SELECT * FROM users WHERE user_id=\"%s\"", user_id) if user: memcache.set(key, json.dumps(user)) return user else: return json.loads(user_blob) The other side of the coin is the database cache .

When opening the database , You will get some degree of default configuration , This will provide a degree of caching and performance . These initial settings will be optimized for common use cases , And by adjusting them to the access mode of the system , It can usually greatly improve performance .
The advantage of database caching is , Your application code can “ free ” Get faster , And talented DBA Or operation engineers can find quite a lot of performance without changing the code ( My colleagues Rob Coli Recently, we spent some time to optimize our configuration Cassandra Line cache , And successfully completed the chart that he spent a week harassing us , These charts show I / O The load drops sharply , The request delay is also greatly improved ).
Memory cache
In terms of raw performance , The most efficient cache is the cache that stores the entire data set in memory .Memcached and Redis Are examples of in memory caching ( Be careful : Can be Redis Configured to store some data to disk ). It's because it's right RAM The interview of It's faster than accessing the disk Order of magnitude .
On the other hand , Usually available RAM Less than disk space , Therefore, a strategy is needed to keep only the hot subset of data in the memory cache . The most direct strategy is Least recently used Strategy , And by the Memcache Use ( And from 2.2 version ,Redis It can also be configured to adopt it ).LRU Work by prioritizing less commonly used data and evicting less commonly used data , And it's almost always the right caching strategy .
Content distribution network
Content distribution network Is a special kind of cache ( Some people may use the usage of this term , But I think it's suitable ), This cache plays a role in sites that serve a large number of static media .

CDN Reduces the burden of providing static media from your application server ( It is usually best suited to serve dynamic pages rather than static media ), And provide geographical distribution . Overall speaking , Your static assets will load faster , And less pressure on the server ( But this is the new business expenditure pressure ).
In a typical CDN Setting up , The request will first be made to CDN Request static media , If CDN Available locally , be CDN This content will be provided (HTTP Header for configuration CDN How to cache a given content ). If the file is not available , be CDN The file will be queried from your server , Then cache it locally and provide it to the requesting user ( In this configuration , They act as read-only caches ).
If your site is not big enough , Unable to use your own CDN, Then you can static.example.com Use lightweight HTTP The server ( for example Nginx) Separate static media from separate subdomains ( for example ) Provide services , And will DNS Switch from the server to CDN Release later .
Cache invalidation
Although the cache is great , But it does require you to cache and real data sources ( That is database ) Maintain consistency between , Thus risking really strange application behavior .
The solution to this problem is called Cache invalidation .
If you are dealing with a single data center , This is usually a simple question , But if you have multiple code paths to write to the database and cache , It is easy to introduce errors ( If you don't use it , This almost always happens ) Caching strategies have been considered when writing applications ). At a higher level , The solution is : Every time you change a value , Write the new value to the cache ( This is called Write directly Cache ), Or simply delete the current value from the cache , And allows you to fill in the passthrough cache before selecting ( The choice between read and write caching depends on the details of your application , But usually I prefer write through caching , Because they can reduce the incidence of stampede events in the back-end database ).
For scenarios involving fuzzy queries ( for example , If you try something like SOLR And Add application level cache before full-text search engine of class ) Or modify an unknown number of elements ( for example , Delete all objects created more than a week ago ).
In these cases , You must consider relying entirely on the database cache , Add too much expiration time to cached data , Or redesign the logic of the application to avoid this problem ( for example , Instead of DELETE FROM a WHERE..., Retrieve all eligible items , Invalidate the corresponding cache line , And then delete the row explicitly through the primary key ).
Offline processing
As the system becomes more and more complex , It is almost always necessary to perform processing that cannot be performed synchronously with customer requests , Because this will cause unacceptable delay ( for example , You want to spread users' actions in the social graph ) ), Or because it needs to happen regularly ( for example , To create a daily summary analysis ).
Message queue
For processing , You want to execute inline with the request , But it's too slow , The simplest solution is to create a message queue ( for example RabbitMQ). Message queuing makes your Web Applications can quickly publish messages to queues , And let other user processes execute processing outside the scope and time range of the client request .
Offline work handled by consumers and Web The division between online work performed by an application depends entirely on the interface you expose to users . Usually , You will :
- Almost no work is performed among users ( Only schedule tasks ), And notify your users that the task will occur offline , Generally, the polling mechanism is used to update the interface after the task is completed ( for example , Follow these steps in Slicehost Configure new VM) Pattern ), or
- Perform enough work online , So that the user looks as if the task has been completed , Then tie up the suspended terminal ( stay Twitter or Facebook The news posted on may be updated by tweeting in the timeline / Message to follow this pattern , But it will update your followers' time span ; Real time updates Scobleizer Of It is not feasible for all followers .

Message queuing has another benefit , That is, they enable you to create a separate computer pool to perform offline processing , Without adding Web The burden of application servers . This allows you to target resource increases at current performance or throughput bottlenecks , Instead of uniformly increasing resources on bottleneck and non bottleneck systems .
Schedule regular tasks
Almost all large systems need to perform tasks on a daily or hourly basis , But unfortunately , Wait for an acceptable , Widely supported solutions are still a problem . meanwhile , You may still be right cron Feel confused , But you can use cronjobs Publish messages to users , It means cron The machine is only responsible for scheduling , Instead of performing all processing .
Who knows the recognized tool for solving this problem ? I've seen many homemade systems , But there is no clean and reusable system . Of course , You can use cronjobs Stored in the computer Puppet Configuration in progress , This makes it easy to recover from the loss of the computer , However, manual recovery is still required , This may be acceptable , But it's not perfect .
Mapping reduction
If your large application is processing large amounts of data , Sometimes you may use Hadoop as well as Hive or HBase Add pair map-reduce Of Support .

Adding a map reduction layer can execute data and... In a reasonable time / Or handle intensive operations . You can use it to calculate suggested users in the social graph or generate analysis reports .
For systems small enough , You can usually avoid using SQL Temporary queries on databases , However, once the amount of data stored or the writing load, the database needs to be fragmented , And usually requires a dedicated secondary server , Then the method may not be easily extended . Execute these queries ( here , You may want to use a system designed to analyze large amounts of data , Instead of dealing with databases ).
Platform level
Most applications communicate directly with the database Web Application started . For most applications , This method is usually enough , But there are some compelling reasons to add a platform layer , for example ,Web The application communicates with the platform layer , And the platform layer communicates with the database .

First , Connect the platform and Web The separation of applications allows you to extend each part independently . If you add a new API, You can add a platform server instead of Web Add unnecessary capacity to the application layer .( Usually , Playing the role of a server will lead to a higher level of configuration optimization , This is not available for general-purpose computers ; Your database computer will usually have a high I / O load , And will benefit from solid-state drives , But your well configured application server may not read data from disk at all during normal operation , But it may benefit from more CPU.)
secondly , Adding a platform layer is a way to use the infrastructure for a variety of products or interfaces (Web Applications ,API,iPhone Applications, etc ) Methods , There is no need to write too much for processing cache , Redundant template code of database, etc .
Third , Sometimes unknown aspects of the platform layer are , They make it easier for organizations to expand . The best situation is , The platform exposes clear interfaces independent of products , Thus masking the implementation details . If you do well , This will allow multiple independent teams to exploit the capabilities of the platform , And allow another team to implement / Optimize the platform itself .
I was going to do some modest detail in dealing with multiple data centers , But the topic is really worth mentioning , So I just want to mention cache invalidation and data replication / Consistency became quite interesting at that stage .
I'm sure , I made some controversial statements in this article , I hope dear readers will defend it , So that we can all learn something . Thank you for reading !
边栏推荐
- uniapp 处理过去时间对比现在时间的时间差 如刚刚、几分钟前,几小时前,几个月前
- 7-17 crawling worms (15 points)
- C # use gdi+ to add text with center rotation (arbitrary angle)
- Latex insert picture, insert formula
- Safety reinforcement learning based on linear function approximation safe RL with linear function approximation translation 2
- PHP code audit 3 - system reload vulnerability
- libmysqlclient.so.20: cannot open shared object file: No such file or directory
- Exercise 9-3 plane vector addition (15 points)
- 转载:等比数列的求和公式,及其推导过程
- SQL replying to comments
猜你喜欢
Hands on deep learning (41) -- Deep recurrent neural network (deep RNN)
Hands on deep learning (46) -- attention mechanism
入职中国平安三周年的一些总结
How web pages interact with applets
Reasons and solutions for the 8-hour difference in mongodb data date display

Hands on deep learning (40) -- short and long term memory network (LSTM)

【OpenCV 例程200篇】218. 多行倾斜文字水印
【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
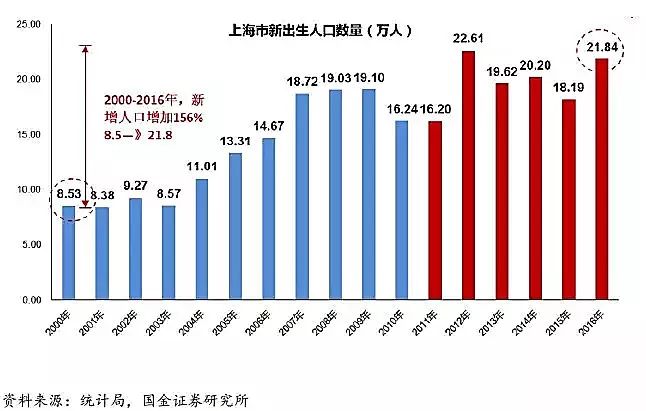
用数据告诉你高考最难的省份是哪里!

Latex learning insertion number - list of filled dots, bars, numbers
随机推荐
Debug:==42==ERROR: AddressSanitizer: heap-buffer-overflow on address
【Day2】 convolutional-neural-networks
C # use gdi+ to add text with center rotation (arbitrary angle)
Golang 类型比较
Hands on deep learning (41) -- Deep recurrent neural network (deep RNN)
使用 C# 提取 PDF 文件中的所有文字(支持 .NET Core)
Custom type: structure, enumeration, union
uniapp 小于1000 按原数字显示 超过1000 数字换算成10w+ 1.3k+ 显示
ASP. Net to access directory files outside the project website
Regular expression (I)
On Multus CNI
[200 opencv routines] 218 Multi line italic text watermark
浅谈Multus CNI
System.currentTimeMillis() 和 System.nanoTime() 哪个更快?别用错了!
leetcode1-3
MySQL develops small mall management system
IIS configure FTP website
Normal vector point cloud rotation
用数据告诉你高考最难的省份是哪里!
直方图均衡化