当前位置:网站首页>[pytorch record] automatic hybrid accuracy training torch cuda. amp
[pytorch record] automatic hybrid accuracy training torch cuda. amp
2022-07-01 19:19:00 【magic_ ll】
Nvidia stay Volta Introduce... Into the architecture Tensor Core unit , To support FP32 and FP16 Calculation of mixing accuracy .tensor core It is a calculation unit of matrix multiplication and accumulation , Every tensor core When the 64 Floating point mixed precision operations (FP16 Matrix multiplication and FP32 Add up ).
In the same year, a pytorch Expand apex, To support the automatic mixing accuracy training of model parameters .
Pytorch1.6 After the version , Start native support amp, namelytorch.cuda.amp, yes nvidia Developers contribute to pytorch Inside , Only support tensor core Of CUDA Hardware can enjoy amp Advantages .
1 FP16 Semi precision
FP16 and FP32, Is the binary floating-point data type used by the computer .
FP16 Half precision , Use 2 Bytes .FP32 namely Float.
among ,sign Is positive or negative ,exponent Bitwise index 2 ( n − 15 + 1 ) 2^{(n-15+1)} 2(n−15+1), The specific details are not explained here . Baidu when you need to see .
float The representation of a type in memory
Use alone FP16:
- advantage :
- Reduce the occupation of video memory , So as to support more batchsize、 Larger model and larger input size Training , Sometimes, it will improve the accuracy
Speed up the calculation of training and reasoning , It can double the speed- shortcoming :
- Spillover problem :
because FP16 The dynamic range ratio of FP32 The numerical range of is much smaller , Therefore, it is easy to have up overflow and down overflow in the calculation process , And then there was "NAN" The problem of . In deep learning , Because the gradient of the activation function is often smaller than the weight gradient , It is more prone to overflow .
When the first L When the gradient of the layer overflows , The first L-1 The weights of all previous layers cannot be updated- Rounding error
finger When the ladder goes through hours , Less than the minimum interval in the current interval , This gradient update may fail . such as
FP16 Of 2 − 3 + 2 − 14 = 2 − 3 2^{-3}+2^{-14}=2^{-3} 2−3+2−14=2−3, At this point, rounding error occurs : stay [ 2 − 3 , 2 − 2 ] [2^{-3}, 2^{-2}] [2−3,2−2] between , Than 2 − 3 2^{-3} 2−3 The next big number is ( 2 − 3 + 2 − 13 2^{-3}+2^{-13} 2−3+2−13)
import numpy as np a = np.array(2**(-3),dtype=np.float16) b = np.array(2**(-14),dtype=np.float16) c = a+b print(a) # 0.125 print('%f'%b) # 0.000061 print(c) # 0.125pytorch Data types in :
stay pytorch in , Altogether 10 Type of tensor:
torch.FloatTensor– 32bit floating point (pytorch Created by default tensor The type of )torch.DoubleTensor– 64bit floating pointtorch.HalfTensor– 16bit floating piont1torch.BFloat16Tensor– 16bit floating piont2torch.ByteTensor– 8bit integer(unsigned)torch.CharTensor– 8bit integer(signed)torch.ShortTensor– 16bit integer(signed)torch.IntTensor– 32bit integer(signed)torch.LongTensor– 64bit integer(signed)torch.BoolTensor– Booleanimport torch tensor = torch.zeros(20,20) print(tensor.type())

2 Hybrid accuracy training mechanism
Automatic mixing accuracy (Automatic Mixed Precision, AMP) Training , Is training a numerical accuracy of 32 The model of , Operation of some operators The numerical accuracy is FP16, The operation accuracy of other operators is FP32. Which specific operators use precision ,amp It is automatically set , No additional user settings are required .
This does not change the model 、 Without reducing the accuracy of model training , It can shorten the training time , Reduce storage requirements , So as to support more batchsize、 Larger model and larger input size Training .
torch.cuda.ampIt provides users with a very convenient hybrid accuracy training mechanism , By usingamp.autocastandamp.GradScalerTo achieve :
- Users do not need to manually adjust the model parameters dtype,amp It will automatically select the appropriate numerical precision for the operator
- In back propagation ,FP16 Gradient numerical overflow problem ,amp Provides a gradient scaling operation , And before the optimizer updates the parameters , Will automatically adjust the gradient unscaling. Therefore, it will not have any impact on the super parameters of model optimization .
The specific implementation process is as follows :Normal neural network training : Forward calculation loss、 Reverse gradient calculation 、 Gradient update .
Mixed precision training : Copy the weight copy and convert to FP16 Model 、 Forward calculation loss、loss Zoom in 、 Reverse gradient calculation 、 Gradient reduction 、FP16 The gradient of is updated to FP32 Model .Concrete amp Training process :
- Maintain a FP32 A copy of the numerical accuracy model
- At each iteration
- Copy and convert to FP16 Model .
- Forward propagation (FP16 Model parameters of )
FP16 The operator of , Direct calculation operation ; Yes FP32 The operator of , The input and output are FP16, The accuracy of the calculation is FP32. The same goes for the reverse- loss Zoom in s times
- Back propagation , That is, reverse gradient calculation (FP16 Model parameters and parameter gradients )
- The gradient times 1/s
- utilize FP16 Gradient update of FP32 Model parameters of
Where the amplification factor s The choice of , Choosing a constant is not appropriate . because loss And the value of the gradient is variable , therefore s You need to follow loss To dynamically change .
Healthy loss Drop in oscillation , thereforeGradScalerThe design of the s every other N individual iteration Multiply by one greater than 1 The coefficient of , stay scale loss;
- Maintain a FP32 A copy of the numerical accuracy model
- At each iteration
- Copy and convert to FP16 Model .
- Forward propagation (FP16 Model parameters of )
- loss Zoom in s times
- Back propagation , That is, reverse gradient calculation (FP16 Model parameters and parameter gradients )
- Check if there is
infperhapsnanThe gradient of the parameters of . If there is , Reduce s, Back to step 1- The gradient times 1/s
- utilize FP16 Gradient update of FP32 Model parameters of
The basic operations of user training with mixed accuracy are as follows :
from torch.cuda.amp import GradScaler as GradScaler # amp rely on Tensor core framework , therefore model Parameter must be cuda tensor type model = Net().cuda() optimizer = optim.SGD(model.parameters(), ...) # GradScaler Object is used to automatically do gradient scaling scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() # stay autocast enable Area operation forward with autocast(): # model Make one FP16 Copy of ,forward output = model(input) loss = loss_fn(output, target) # use scaler,scale loss(FP16),backward obtain scaled Gradient of (FP16) scaler.scale(loss).backward() # scaler Update parameters , Will automatically unscale gradient # If there is nan or inf, Auto skip scaler.step(optimizer) # scaler factor to update scaler.update()The details are as follows .
3 aotucast
classs aotucast(device_type, enable=True, **kwargs)
- [device_type] (string) Indicates whether to use ‘cuda’ perhaps ‘cpu’ equipment
- [enabled] (bool, The default is True) Indicates whether automatic projection is enabled in the area ( Automatic conversion )
- [dtype] (torch_dpython type ) Said the use of torch.float16/ torch.bfloat16
- [cache_enabled] (bool, The default is True) Indicates whether to use autocast Weight cache in
explain :
- autocast Instances of can be used as context managers Or decorator , Set the area to run with mixed accuracy
3.1 autocast operator
stay pytorch in , In the use of autocast Region , Some operators will be automatically converted to FP16 Calculate . Only CUDA Operators are eligible for automatic conversion .
- amp Auto convert to FP16 The operators of are :
- Auto convert to FP32 The operator of :
- There are still operators not listed , image dot,add,cat… Are based on the greater numerical accuracy in the data , To operate , That is to say FP32 Participate in calculation , Just press the FP32, Is full of FP16 Participate in calculation , Namely FP16.
3.2 Display the conversion accuracy
Get into autocast-enabled Regional time , Tensors can be of any type . When using automatic projection , Should not be called on models or inputs half() or bfloat16().
but , When used as a context manager , Calculation of mixing accuracy enable The area gets FP16 The variable of numerical accuracy is enable Outside the region, it should be explicitly converted to FP32, Otherwise, the use process may lead to the error of type mismatch# Create some tensors in the default data type ( It is assumed here that FP32) a_float32 = torch.rand((8, 8), device="cuda") b_float32 = torch.rand((8, 8), device="cuda") c_float32 = torch.rand((8, 8), device="cuda") d_float32 = torch.rand((8, 8), device="cuda") with autocast(): # torch.mm Is in autocast In the list of operators , Will be converted to FP16. # Input is FP32, But with FP16 Precision operation calculation , And the output FP16 data # This process does not need to be set manually e_float16 = torch.mm(a_float32, b_float32) # It can also be a mixed input type f_float16 = torch.mm(d_float32, e_float16) # but In the exit autocast after , Use autocast Area generated FP16 variable , You need to convert the displayed into FP32. g_float32 = torch.mm(d_float32, f_float16.float())
autocast You can also nest :# Create some tensors in the default data type ( It is assumed here that FP32) a_float32 = torch.rand((8, 8), device="cuda") b_float32 = torch.rand((8, 8), device="cuda") c_float32 = torch.rand((8, 8), device="cuda") d_float32 = torch.rand((8, 8), device="cuda") with autocast(): e_float16 = torch.mm(a_float32, b_float32) with autocast(enabled=False): f_float32 = torch.mm(c_float32, e_float16.float()) g_float16 = torch.mm(d_float32, f_float32)3.3 autocast As a decoration
This situation is generally used in distributed training .autocast Designed as “thread local” Of , So only in main thread Set up autocast The area is not work Of :
The general call form of non distributed training is :
model = MyModel() with autocast(): output = model(input)
Distributed training will usenn.DataParalle()ornn.DistributedDataParallel, Creating model Then add the corresponding code , as follows , But this is not effective , there autocast Only in main thread Work in China :model = MyModel() DP_model = nn.DataParalle(model) ## add to with autocast(): output = DP_model(input)
For in other thread At the same time , You need to define forward Also set autocast. There are two ways , Add decorators 、 Add context manager .## The way 1: Decorator class myModel(nn.Module): @autocast() def forward(self, input): pass ## The way 2: Context manager class myModule(nn.Module): def forward(self, input): with autocast(): pass ## Call in main function model = MyModel() DP_model = nn.DataParalle(model) ## add to with autocast(): output = DP_model(input)


4 GradScaler class
When mixed accuracy training is used , There is a situation that cannot converge , The reason is that the value of the activation gradient is too small , It caused an overflow . By using
torch.cuda.amp.GradScaler, Zoom in loss Value To prevent gradient underflow.torch.cuda.amp.GradScaler(init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000, enabled=True)
- 【init_scale】 scale factor The initial value of the
- 【growth_factor】 Every scale factor The growth factor of
- 【backoff_factor】scale factor The coefficient of descent
- 【growth_interval】 Every multiple interval growth scale factor
- 【enabled】 Do you do scale
4.1 GradScaler Methods
scale(output)Method
Yes outputs become scale factor, And back to . If enabled=False, Go straight backstep(optimizer, *args, **kwargs)Method
Completed two functions : Yes, gradient unscale; Check gradient overflow , without nan/inf, Is executed optimizer Of step, If there is one, just skipupdate(new_scale=None)Method
update Method in each iteration You need to call before the end , If parameter update skips , Will give scale factor multiply backoff_factor, Or when it comes to growth iteration, Just give it to scale factor ride growth_factor. You can also use new_scale Direct updating scale factor.
Example :
model=Net().cuda() optimizer=optim.SGD(model.parameters(),...) scaler = GradScaler() # Instantiate a before training GradScaler object for epoch in epochs: for input,target in data: optimizer.zero_grad() with autocast(): # Open back and forth autocast output=model(input) loss = loss_fn(output,targt) scaler.scale(loss).backward() # For gradient magnification #scaler.step() First, the gradient value unscale Come back , If the gradient value is not inf or NaN, Call optimizer.step() To update the weights , otherwise , Ignore step call , So as to ensure that the weight is not updated . scaler.step(optimizer) scaler.update() # Be ready to , See if you want to increase scaler4.2 GradScaler More applications in gradient processing
Gradient clipping
scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() with autocast(): output = model(input) loss = loss_fn(output, target) scaler.scale(loss).backward() # to unscale gradient , At this time clip threshold In order to correctly use the gradient scaler.unscale_(optimizer) # clip gradient torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm) # unscale_() Has been explicitly called ,scaler perform step No longer unscalse Update parameters , Yes nan/inf I'll also skip scaler.step(optimizer) scaler.update()
Gradient accumulationscaler = GradScaler() for epoch in epochs: for i, (input, target) in enumerate(data): with autocast(): output = model(input) loss = loss_fn(output, target) # loss according to The accumulated times are normalized loss = loss / iters_to_accumulate # scale Unified loss and backward scaler.scale(loss).backward() if (i + 1) % iters_to_accumulate == 0: # may unscale_ here if desired # (e.g., to allow clipping unscaled gradients) # step() and update() proceed as usual. scaler.step(optimizer) scaler.update() optimizer.zero_grad()
Gradient penaltyfor epoch in epochs: for input, target in data: optimizer.zero_grad() with autocast(): output = model(input) loss = loss_fn(output, target) # Prevent overflow , If it's not autocast Area , First use scaled loss obtain scaled gradient scaled_grad_params = torch.autograd.grad(outputs=scaler.scale(loss), inputs=model.parameters(), create_graph=True) # gradient unscale inv_scale = 1./scaler.get_scale() grad_params = [p * inv_scale for p in scaled_grad_params] # stay autocast Area ,loss Plus the gradient penalty term with autocast(): grad_norm = 0 for grad in grad_params: grad_norm += grad.pow(2).sum() grad_norm = grad_norm.sqrt() loss = loss + grad_norm scaler.scale(loss).backward() # may unscale_ here if desired # (e.g., to allow clipping unscaled gradients) # step() and update() proceed as usual. scaler.step(optimizer) scaler.update()4.5 Multiple models
Just use one scaler Operate on multiple models , but scale(loss) and step(optimizer) Execute separately
scaler = torc h.cuda.amp.GradScaler() for epoch in epochs: for input, target in data: optimizer0.zero_grad() optimizer1.zero_grad() with autocast(): output0 = model0(input) output1 = model1(input) loss0 = loss_fn(2 * output0 + 3 * output1, target) loss1 = loss_fn(3 * output0 - 5 * output1, target) # there retain_graph And amp irrelevant , It appears here because in this example , Two backward() Calls share some parts of the graph . scaler.scale(loss0).backward(retain_graph=True) scaler.scale(loss1).backward() # If you want to check or modify the gradient of the parameters it owns , You can choose the corresponding optimizer Perform explicit unzoom . scaler.unscale_(optimizer0) scaler.step(optimizer0) scaler.step(optimizer1) scaler.update()
5 Precautions for mixing accuracy
- As far as possible in have Tensor Core Architecturally GPU Use amp.
In the absence of Tensor Core Architecturally GPU Upper use amp, The video memory will be significantly reduced , But the speed will drop more . Concrete , stay Turing Architecturally GTX 1660 Upper use amp, Computing time increases Double , The video memory is less than half of the original- Constant range : In order to ensure that the calculation does not overflow , First, ensure that the manually set constant does not overflow . Such as epsilon、INF etc.
- Dimension It is best to 8 Multiple : Dimension is 8 Multiple , Best performance
边栏推荐
- How to realize the bottom layer of read-write lock in go question bank 16
- kubernetes命令入门(namespaces,pods)
- June issue | antdb database participated in the preparation of the "Database Development Research Report" and appeared on the list of information technology and entrepreneurship industries
- 如何运营好技术相关的自媒体?
- How to use the low code platform of the Internet of things for personal settings?
- Solution of intelligent supply chain management platform in aquatic industry: support the digitalization of enterprise supply chain and improve enterprise management efficiency
- Chaos engineering platform chaosblade box new heavy release
- Prices of Apple products rose across the board in Japan, with iphone13 up 19%
- Golang error handling
- Yyds dry inventory ravendb start client API (III)
猜你喜欢

毕业季 | 华为专家亲授面试秘诀:如何拿到大厂高薪offer?
Today, with the popularity of micro services, how does service mesh exist?

Altair HyperWorks 2022 software installation package and installation tutorial
2. Create your own NFT collections and publish a Web3 application to show them start and run your local environment

制造业SRM管理系统供应商全方位闭环管理,实现采购寻源与流程高效协同

Cdga | if you are engaged in the communication industry, you should get a data management certificate
MATLAB中subplot函数的使用
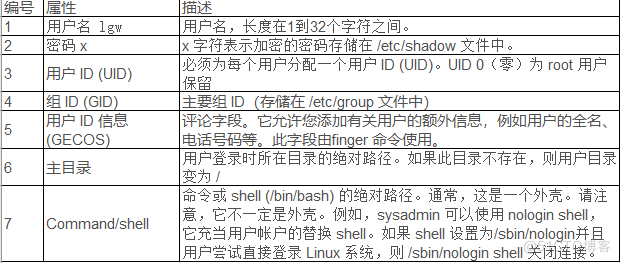
11. Users, groups, and permissions (1)

Lake Shore M91快速霍尔测量仪
M91 fast hall measuring instrument - better measurement in a shorter time
随机推荐
Leetcode-141 circular linked list
2020, the regular expression for mobile phone verification of the latest mobile phone number is continuously updated
从零开始学 MySQL —数据库和数据表操作
Lake Shore continuous flow cryostat transmission line
ACM mm 2022 video understanding challenge video classification track champion autox team technology sharing
SuperVariMag 超导磁体系统 — SVM 系列
Prices of Apple products rose across the board in Japan, with iphone13 up 19%
MATLAB中subplot函数的使用
Three simple methods of ES6 array de duplication
kubernetes命令入门(namespaces,pods)
Digital business cloud: from planning to implementation, how does Minmetals Group quickly build a new pattern of digital development?
Docker deploy mysql8.0
How to operate technology related we media well?
宝,运维100+服务器很头疼怎么办?用行云管家!
Bao, que se passe - t - il si le serveur 100 + O & M a mal à la tête? Utilisez le majordome xingyun!
ES6数组去重的三个简单办法
ECS summer money saving secret, this time @ old users come and take it away
3. "Create your own NFT collections and publish a Web3 application to show them" cast NFT locally
Database foundation: select basic query statement
Specification of lumiprobe reactive dye indocyanine green