当前位置:网站首页>Pointnet understanding (step 4 of pointnet Implementation)
Pointnet understanding (step 4 of pointnet Implementation)
2022-07-02 07:38:00 【xiaobai_ Ry】
PointNet The first 4 Step ——PointNet understand

front , We talked about the challenge of point cloud , Challenges for point cloud ,PointNet The paper proposes the following solutions .
One 、 Point cloud solution

1.1 Permutation invariance

The designed network must meet the permutation invariance ,N It's just a piece of data N! A permutation invariance . Symmetric functions can satisfy the above permutation invariance , as follows :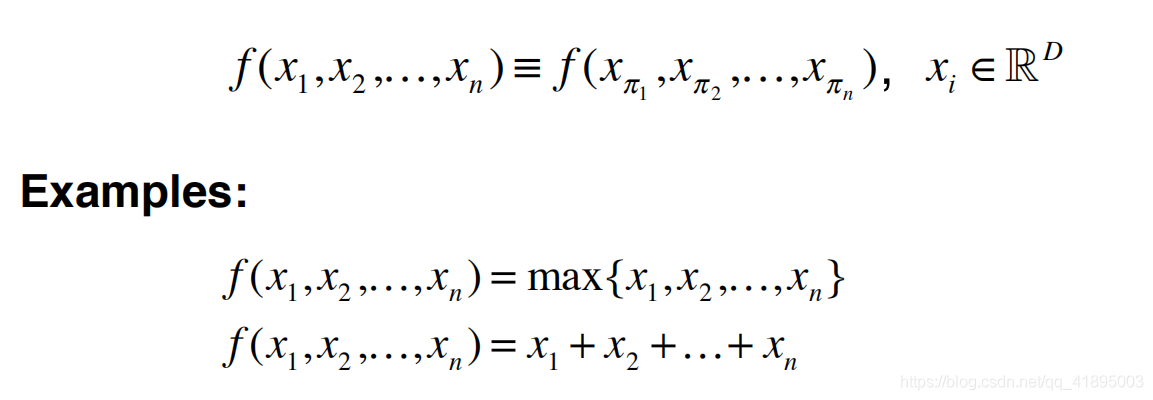
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
Directly perform symmetry operations on data , Although it satisfies the permutation invariance , It is easy to lose a lot of geometry and meaningful information . For example, when taking the maximum value , Only get the farthest point , Average. , Only get the center of gravity .
How not to lose
Map every point to high-dimensional space , Do symmetry operations on data in higher dimensional space . For the expression of three-dimensional points in high-dimensional space , It must be redundant , But because of the redundancy of information , We synthesize through symmetry operation , It can reduce the loss of information , Keep enough point cloud information . thus , You can design this PointNet The prototype of , be called PointNet(vanilla):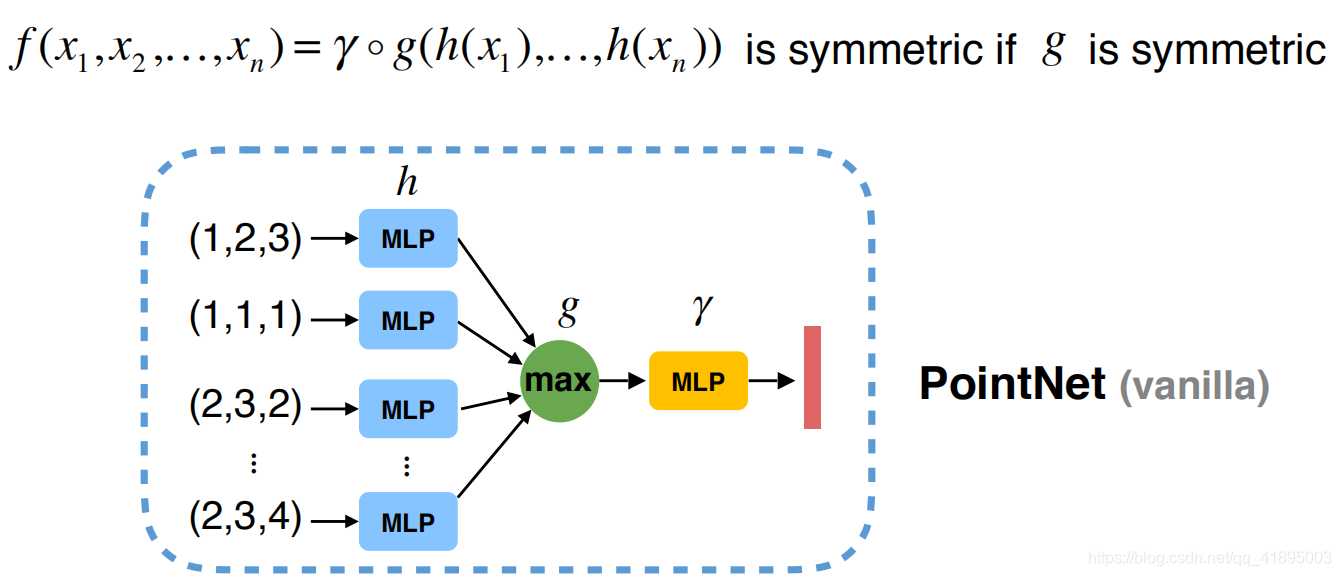
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
adopt MLP Project each point into high-dimensional space , adopt max Do symmetry .
MLP Why can it be projected into high-dimensional space ( This is an explanation for Xiaobai , Click here to )
PointNet Can arbitrarily approximate symmetric functions ( By increasing the depth and width of Neural Networks ):
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
1.2 Rotation invariance ( Geometric invariance )
Rotation invariance refers to , By spinning , All points (x,y,z) The coordinates of change , But it's still the same object , As shown below :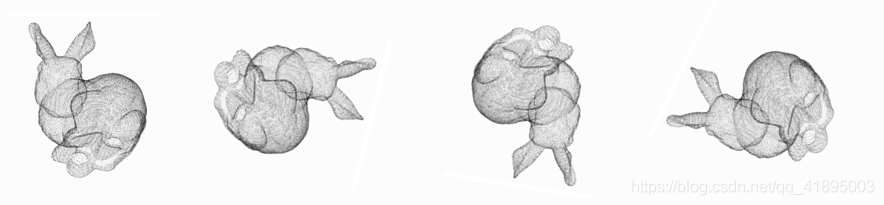
So for ordinary PointNet(vanilla), If you input the same object with different rotation angles successively , It may not recognize it well . The method in the paper is a new one T-Net Network to learn point cloud rotation , Calibrate the object , The rest PointNet(vanilla) Just classify or segment the calibrated object .
Point cloud is a kind of data that is very easy to do geometric transformation , Just multiply the matrix . As shown in the figure below , One N×3 Multiply the point cloud matrix by A 3×3 The rotation matrix of can get the matrix after rotation transformation , So learn one from the input point cloud 3×3 Matrix , You can correct it .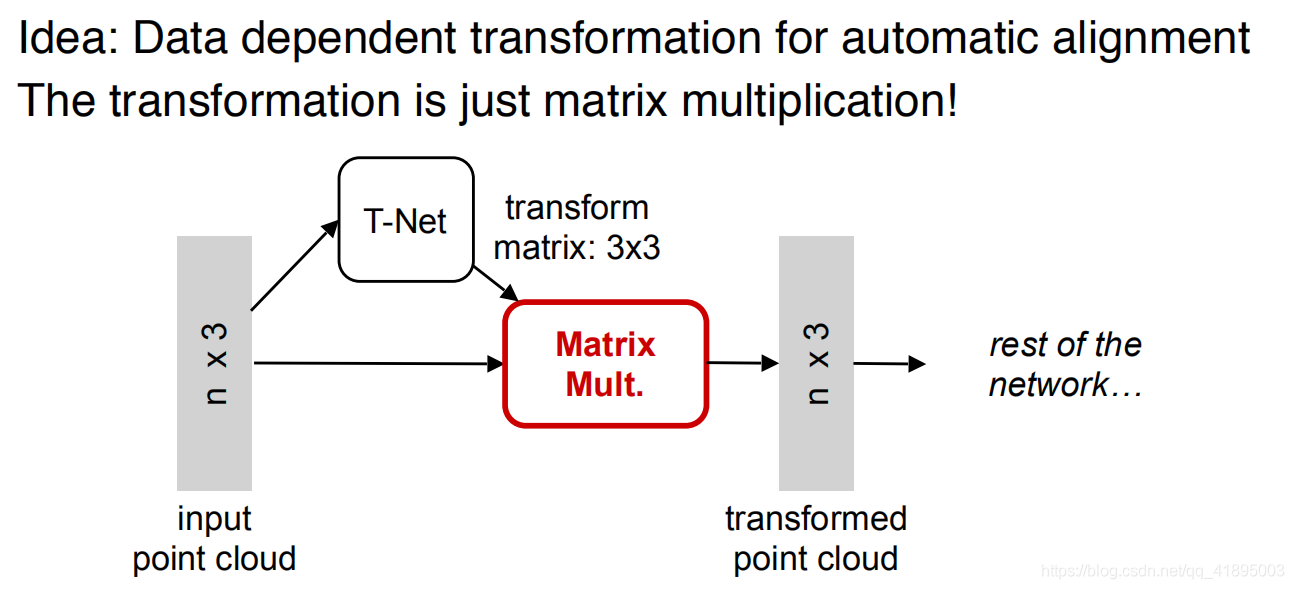
Similarly, map the point cloud to K After the redundant space of dimension , Right again K Check the point cloud features of dimension , But this proofreading needs to introduce a regularization penalty term , We want it to be as close as possible to an orthogonal matrix .【 Regularization is due to the difficulty of high-dimensional space optimization , Regularization can reduce the difficulty of optimization .】
summary :maxpooling Solve permutation invariance ( Disorder ) problem , Spatial transformation network solves the problem of rotation invariance
Two 、PointNet
Point cloud classification network :
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding *
say concretely , For each of these N×3 Point cloud input of , The network first goes through a T-Net Align it in space ( Rotate to the front ), Re pass MLP Map it to 64 On the high dimensional space of dimension , Again 64 Align the dimension space , Finally, it maps to 1024 Dimensional space . Now for every point , There is one. 1024 Vector representation of dimensions , And this vector representation for a 3 Dimensional point clouds are obviously redundant , Therefore, at this time, maximum pooling is introduced max pool operation , take 1024 Only the largest one remains on all channels of dimension , That's what we got 1×1024 The overall characteristics of . The global feature is through a cascaded fully connected network ( That's the last MLP), Finally, one K Classification results .
Point cloud segmentation network :

The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding *
The segmentation of point cloud can be defined as a classification problem of each point , If you know the classification of each point , This point can be divided into fixed categories . Of course , We cannot segment each point directly through the global coordinates . A simple and effective way is , We can put local characteristics , The features of a single point are combined with the global coordinates , Realize the function of segmentation . The simplest way is , We can put the overall characteristics , Repeat N All over , Then each one is connected with the features of the original single point .【 Explanation of insertion : As mentioned above, local features and global features are combined (64+1024=1088), So it's not difficult to explain 1088 The origin of . Now? , A single point has 1088 dimension .】 It is equivalent to a single point being retrieved in the global feature ( That is, to look at the global characteristics of a single point “ I ” Where in this global feature ,“ I ” Which category should it belong to ?). We will do another for each connected feature MLP The change of , Finally, classify each point into M class , Equivalent to output M individual score.
3、 ... and 、PointNet experimental result
The following experimental results are from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding *
From the above experimental results :pointnet At that time, both segmentation and classification results exceeded the voxel series network at that time , At the same time, due to the characteristics of less parameters , Train fast , It belongs to lightweight network .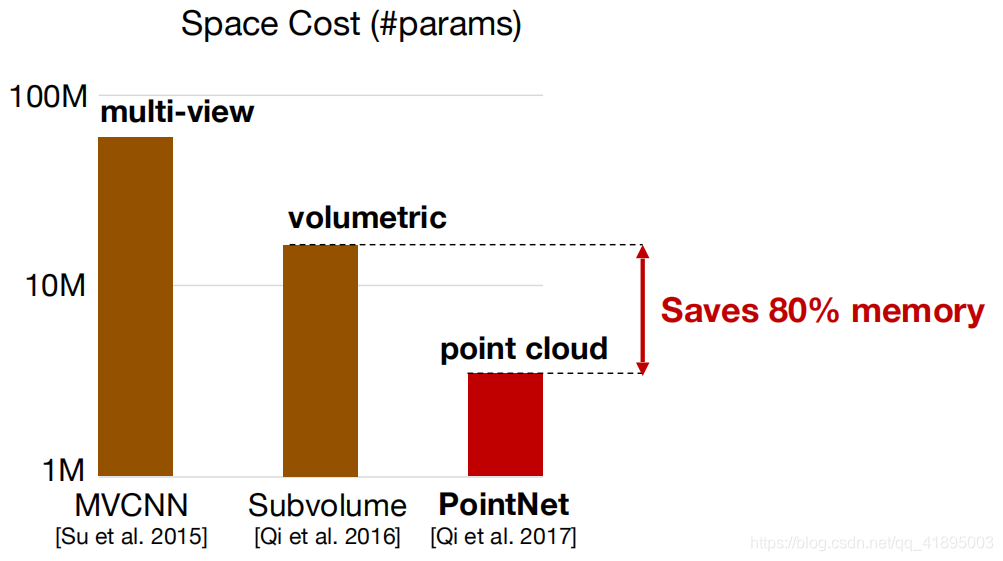
PointNet Suitable for mobile devices such as mobile phones .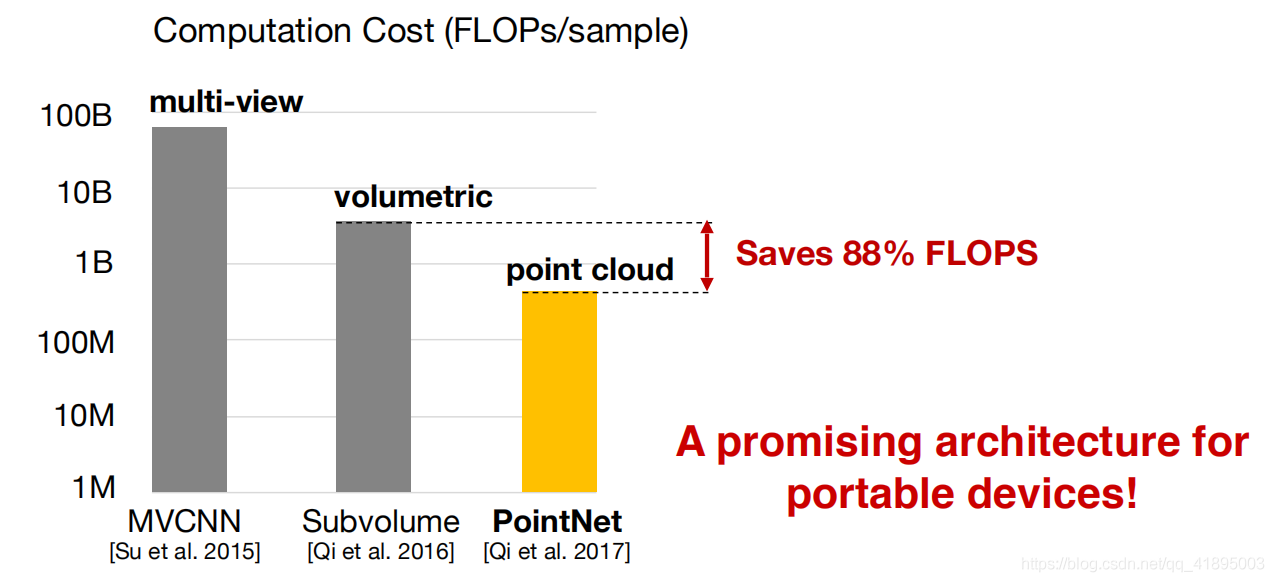
PointNet Robust , Insensitive to the loss of points :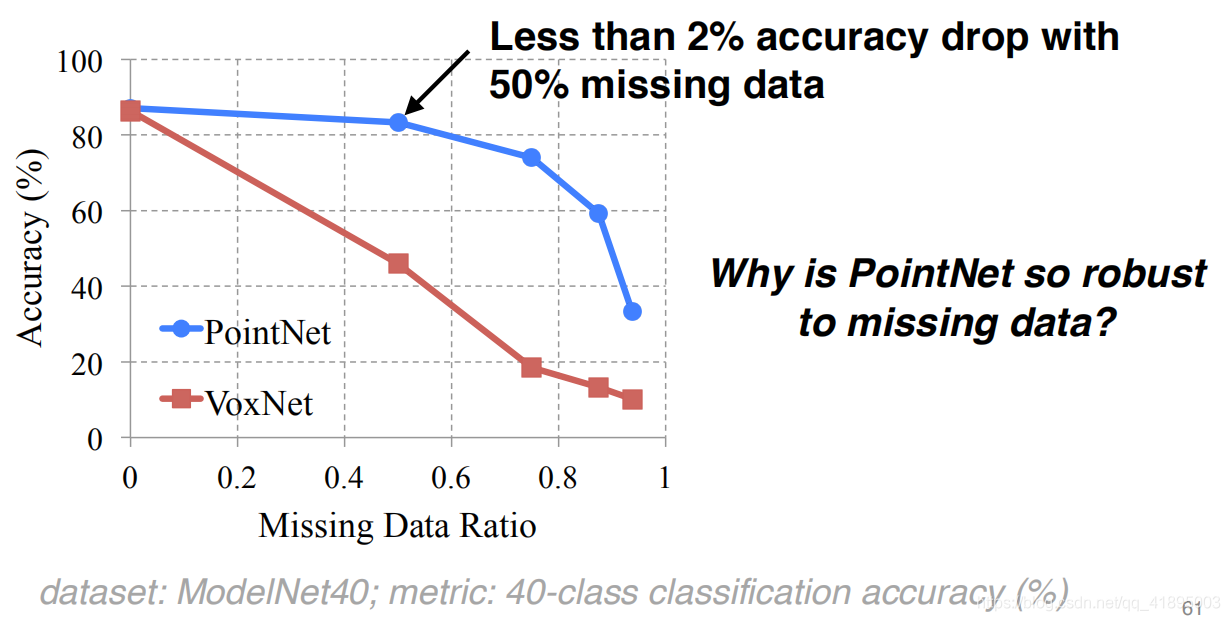
The paper found that , The points that can activate the network to the greatest extent are the backbone points of the object ( The second line below ), Take samples from it , It's easy to get the original structure . So this is PointNet The source of the network's lack of robustness .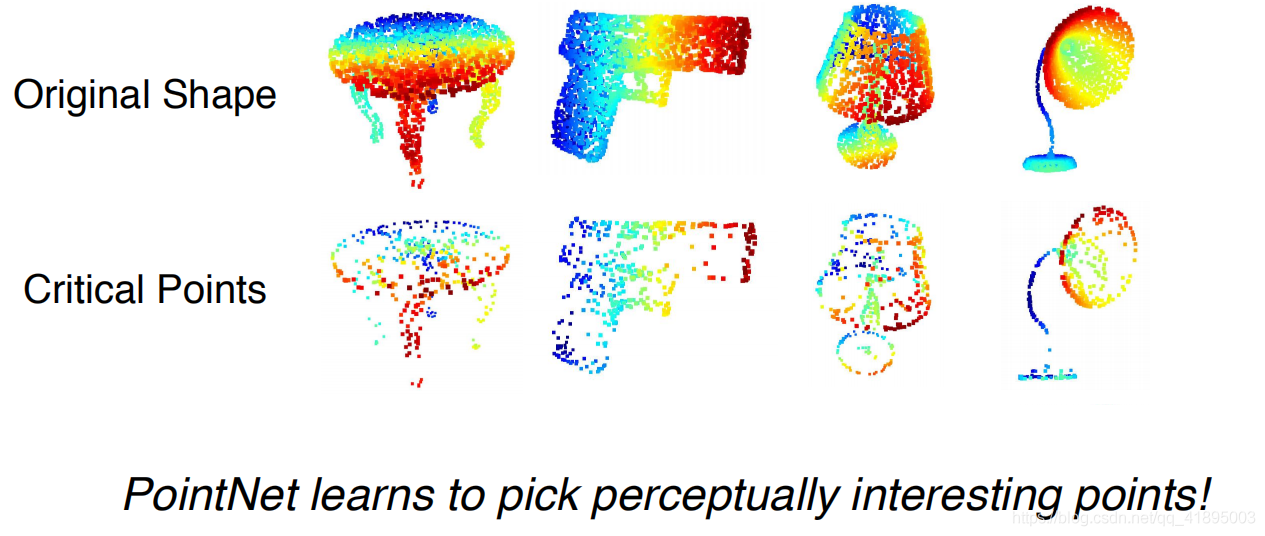
边栏推荐
- conda常用命令
- Using MATLAB to realize: power method, inverse power method (origin displacement)
- Get the uppercase initials of Chinese Pinyin in PHP
- Win10+vs2017+denseflow compilation
- 【信息检索导论】第三章 容错式检索
- Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
- 优化方法:常用数学符号的含义
- 机器学习理论学习:感知机
- 【信息检索导论】第六章 词项权重及向量空间模型
- 基于pytorch的YOLOv5单张图片检测实现
猜你喜欢
Win10+vs2017+denseflow compilation
![[paper introduction] r-drop: regulated dropout for neural networks](/img/09/4755e094b789b560c6b10323ebd5c1.png)
[paper introduction] r-drop: regulated dropout for neural networks
软件开发模式之敏捷开发(scrum)
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization

Machine learning theory learning: perceptron
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization

超时停靠视频生成
![[in depth learning series (8)]: principles of transform and actual combat](/img/2e/89920de2273b6f1bc3b21a19c2ecbe.png)
[in depth learning series (8)]: principles of transform and actual combat

Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
Spark SQL task performance optimization (basic)
随机推荐
解决latex图片浮动的问题
Implementation of purchase, sales and inventory system with ssm+mysql
Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
架构设计三原则
yolov3训练自己的数据集(MMDetection)
Generate random 6-bit invitation code in PHP
spark sql任务性能优化(基础)
MMDetection安装问题
【信息检索导论】第一章 布尔检索
半监督之mixmatch
Pratique et réflexion sur l'entrepôt de données hors ligne et le développement Bi
图片数据爬取工具Image-Downloader的安装和使用
Machine learning theory learning: perceptron
【深度学习系列(八)】:Transoform原理及实战之原理篇
Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
Drawing mechanism of view (I)
《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
【Paper Reading】
Conversion of numerical amount into capital figures in PHP
A slide with two tables will help you quickly understand the target detection