当前位置:网站首页>基于pytorch的YOLOv5单张图片检测实现
基于pytorch的YOLOv5单张图片检测实现
2022-07-02 06:25:00 【wxplol】
当我们训练完yolov5模型后,如何使用这个模型呢?这里简单写一下,可以看到大部分代码在detect.py中都可以找到,算是我自己对这个代码的改装吧,有需要的可以看看。
# coding=utf-8
import torch
import torchvision
import torch.nn as nn
import os
import time
import numpy as np
import math
import random
import cv2.cv2 as cv2
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Ensemble(torch.nn.ModuleList):
'''模型集成'''
def __init__(self):
super(Ensemble,self).__init__()
def forward(self, x, augment=False):
y = []
for module in self:
y.append(module(x, augment)[0])
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 1) # nms ensemble
return y, None # inference, train output
class YOLOV5(object):
def __init__(self,conf_thres=0.25,
iou_thres=0.45,
classes=None,
imgsz=640,
weights="./weights/image_detect.pt"):
# 超参数设置
self.conf_thres=conf_thres#置信度阈值
self.iou_thres=iou_thres#iou阈值
self.classes=classes#分类个数
self.imgsz=imgsz #归一化大小
# Load model
self.device=torch.device('cpu')
self.model = self.attempt_load(weights,map_location=self.device) # load FP32 model
self.stride = int(self.model.stride.max()) # model stride
self.imgsz = self.check_img_size(imgsz, s=self.stride) # check img_size
def attempt_load(self,weights, map_location=None):
# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
model = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt = torch.load(w, map_location=map_location) # load
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
m.inplace = True # pytorch 1.7.0 compatibility
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if len(model) == 1:
return model[-1] # return model
else:
print('Ensemble created with %s\n' % weights)
for k in ['names', 'stride']:
setattr(model, k, getattr(model[-1], k))
return model # return ensemble
def make_divisible(self,x, divisor):
# Returns x evenly divisible by divisor
return math.ceil(x / divisor) * divisor
def check_img_size(self,img_size, s=32):
# Verify img_size is a multiple of stride s
new_size = self.make_divisible(img_size, int(s)) # ceil gs-multiple
if new_size != img_size:
print('WARNING: --img-size %g must be multiple of max stride %g, updating to %g' % (img_size, s, new_size))
return new_size
def letterbox(self,img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True,
stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
def box_iou(self,box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
""" Return intersection-over-union (Jaccard index) of boxes. Both sets of boxes are expected to be in (x1, y1, x2, y2) format. Arguments: box1 (Tensor[N, 4]) box2 (Tensor[M, 4]) Returns: iou (Tensor[N, M]): the NxM matrix containing the pairwise IoU values for every element in boxes1 and boxes2 """
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
def xywh2xyxy(self,x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def non_max_suppression(self,prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False,
multi_label=False,
labels=()):
"""Runs Non-Maximum Suppression (NMS) on inference results Returns: list of detections, on (n,6) tensor per image [xyxy, conf, cls] """
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = self.xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = self.box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
def clip_coords(self,boxes, img_shape):
# Clip bounding xyxy bounding boxes to image shape (height, width)
boxes[:, 0].clamp_(0, img_shape[1]) # x1
boxes[:, 1].clamp_(0, img_shape[0]) # y1
boxes[:, 2].clamp_(0, img_shape[1]) # x2
boxes[:, 3].clamp_(0, img_shape[0]) # y2
def scale_coords(self,img1_shape, coords, img0_shape, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding
coords[:, [1, 3]] -= pad[1] # y padding
coords[:, :4] /= gain
self.clip_coords(coords, img0_shape)
return coords
def plot_one_box(self,x, img, color=None, label=None, line_thickness=3):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def infer(self,img_path,agnostic_nms=False):
# read image
image=cv2.imread(img_path)
# Padded resize
img = self.letterbox(image, self.imgsz, stride=self.stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
pred = self.model(img, augment=False)[0]
# Apply NMS
pred = self.non_max_suppression(pred, self.conf_thres, self.iou_thres, classes=None, agnostic=agnostic_nms)
# Process detections
s=""
s += '%gx%g ' % img.shape[2:] # print string
result=[]
for i, det in enumerate(pred): # detections per image
# Rescale boxes from img_size to im0 size
det[:, :4] = self.scale_coords(img.shape[2:], det[:, :4], image.shape).round()
for *xyxy, conf, cls in reversed(det):
x1,y1,x2,y2= int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])
result.append([x1,y1,x2,y2])
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {img_path}{'s' * (n > 1)}, " # add to string
# Write results
# Get names and colors
names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
for *xyxy, conf, cls in reversed(det):
label = f'{names[int(cls)]} {conf:.2f}'
self.plot_one_box(xyxy, image, label=label, color=colors[int(cls)], line_thickness=3)
# 显示预测结果
print(s)
print(result)
cv2.namedWindow("result",0)
cv2.imshow("result", image)
cv2.waitKey(0) # 1 millisecond
#后处理
return result
if __name__=="__main__":
yolov5=YOLOV5()
yolov5.infer("data/1.png")
这是我自己训练的图片检测模型,结果如下:
github链接:yolov5前向推理实现
参考链接:
yolov5
onnxruntime-for-yolov5
边栏推荐
- 【信息检索导论】第一章 布尔检索
- 读《敏捷整洁之道:回归本源》后感
- 使用MAME32K进行联机游戏
- [introduction to information retrieval] Chapter 6 term weight and vector space model
- view的绘制机制(二)
- Oracle EBS interface development - quick generation of JSON format data
- Play online games with mame32k
- [model distillation] tinybert: distilling Bert for natural language understanding
- 架构设计三原则
- Oracle segment advisor, how to deal with row link row migration, reduce high water level
猜你喜欢
Play online games with mame32k
![[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table](/img/3f/09f040baf11ccab82f0fc7cf1e1d20.png)
[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table

Two table Association of pyspark in idea2020 (field names are the same)
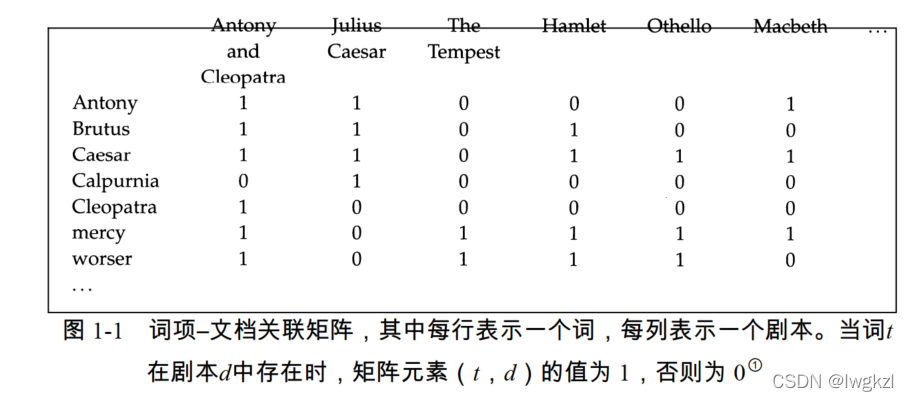
【信息检索导论】第一章 布尔检索

ORACLE EBS ADI 开发步骤

SSM学生成绩信息管理系统

Take you to master the formatter of visual studio code
Alpha Beta Pruning in Adversarial Search
![[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization](/img/24/09ae6baee12edaea806962fc5b9a1e.png)
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization
软件开发模式之敏捷开发(scrum)
随机推荐
Point cloud data understanding (step 3 of pointnet Implementation)
类加载器及双亲委派机制
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'
Module not found: Error: Can't resolve './$$_ gendir/app/app. module. ngfactory'
SSM学生成绩信息管理系统
Oracle segment advisor, how to deal with row link row migration, reduce high water level
ssm人事管理系统
Oracle 11g sysaux table space full processing and the difference between move and shrink
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
【BERT,GPT+KG调研】Pretrain model融合knowledge的论文集锦
第一个快应用(quickapp)demo
Proteus -- RS-232 dual computer communication
CONDA creates, replicates, and shares virtual environments
oracle-外币记账时总账余额表gl_balance变化(上)
ORACLE APEX 21.2安裝及一鍵部署
一个中年程序员学习中国近代史的小结
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
外币记账及重估总账余额表变化(下)
ssm垃圾分类管理系统
JSP intelligent community property management system