当前位置:网站首页>Point cloud data understanding (step 3 of pointnet Implementation)
Point cloud data understanding (step 3 of pointnet Implementation)
2022-07-02 07:25:00 【xiaobai_ Ry】
PointNet Realization of the first 3 Step —— Point cloud understands
1. The representation of three-dimensional data
The expression form of three-dimensional data is generally divided into 4 Kind of : The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
| Three dimensional data form | brief introduction | legend |
|---|---|---|
| point clouds( Point cloud ) | That is, the collection of points in three-dimensional space ; from N individual D Point composition of dimension , When D=3 It can be expressed as three-dimensional coordinate points (x,y,z) , Every point is made by some (xyz) Location determined , We can also specify other properties for it ( Such as RGB Color ). They are the original form when lidar data is obtained , Stereo vision system and RGB-D data ( Contains the image marked with the depth value of each pixel ) It is usually converted into point clouds before further processing . | ( source : Caltech ) 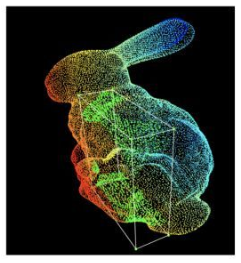 |
| Mesh | It consists of triangular patches and square patches , It comes from polygon mesh . A polygon mesh consists of a set of convex polygon surfaces with common vertices , Can approximate a geometric surface . We can regard the point cloud as a three-dimensional point set sampled from the surface of the basic continuous set ; Polygonal meshes hope to represent these basic surfaces in an easy to render way . Although polygonal meshes were originally designed for computer graphics , But it is also very useful for 3D vision . We can get polygon meshes from point clouds in several different ways , These include Kazhdan And other people in 2006 Put forward in 「 Poisson surface reconstruction 」. | ( source : University of Washington ) |
| Volumetric( Voxel ) | Voxel mesh is developed from point cloud , Used by three-dimensional grid objects 0 and 1 characterization . Voxels are like pixels in three-dimensional space , We can regard voxel mesh as quantitative 、 Fixed size point cloud . However , Point clouds can cover countless points in the form of floating-point pixel coordinates anywhere in space ; Voxel mesh is a kind of three-dimensional mesh , Each of these units ( Or called 「 Voxel 」) Have fixed size and discrete coordinates . | ( source : Indian Institute of technology ) |
| multi-view( Multiple perspectives ) | Multi angle RGB Image or RGB-D Images . Multi view representation is from different simulation perspectives (「 Virtual camera 」) Get the rendered two-dimensional image set of polygon mesh , Thus, the three-dimensional geometric structure can be expressed in a simple way . Simply from multiple cameras ( Such as stereo vision system stereo) The difference between capturing images and building multi view representations is , Multi view actually needs to build a complete 3D Model , And render it from multiple arbitrary viewpoints , To fully express the underlying geometry . Different from the other three representations above , Multi view representation is usually only used to put 3D Data is converted into a format that is easy to process or visualize . | ( source : Stanford university )  |
2. Relevant framework and knowledge understanding
Please check this Reprint blog , This blog post is reprinted from the heart of machine , The original text comes from The Gradient.
It is highly recommended to check the above reprinted blog , We will know more about the advantages and disadvantages of point cloud and related 3D data .
3. Summary of advantages and disadvantages of point cloud
advantage
I believe that after reading chapter 2 After the point , Understand the relevant framework and data , Here is a summary of the following advantages of point cloud .
- Can be directly measured
Point clouds can be directly generated by scanning objects with lidar , Point cloud is closer to the original representation of the device . Raw data is conducive to end-to-end learning .
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding - The expression of point cloud is simpler , An object can be represented as a N*D Matrix .
about Mesh, You need to choose triangular patches or quadrilaterals , You also need to choose how to connect , The size of the triangle ;
For voxels , You need to select the resolution ;
For multiple perspectives , You need to choose the shooting angle .The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
- Contains geometric information
There are challenges

Figure from : University of Oxford
| There are challenges | explain |
|---|---|
| Irregular | Point cloud data is irregular |
| non-uniform | Point clouds are dense in some places , Some places are sparse |
| orderless | Point cloud is essentially a long string of points (nx3 matrix , among n It's points ). In Geometry , The order of a point does not affect its representation of the overall shape in space , for example , The same point cloud can be represented by two completely different matrices . |
| Rotation | The same point cloud has a certain rigidity change in space ( To rotate or translate ), Coordinates change . |
4. Point cloud related work development 
Figure from : University of Oxford
Figure from : University of Oxford
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
Turn into 2D,3D Some information will be erased ; Feature extraction is limited by manual extraction .
5. Point cloud solution

5.1 Permutation invariance
The designed network must meet the permutation invariance ,N It's just a piece of data N! A permutation invariance . Symmetric functions can satisfy the above permutation invariance , as follows :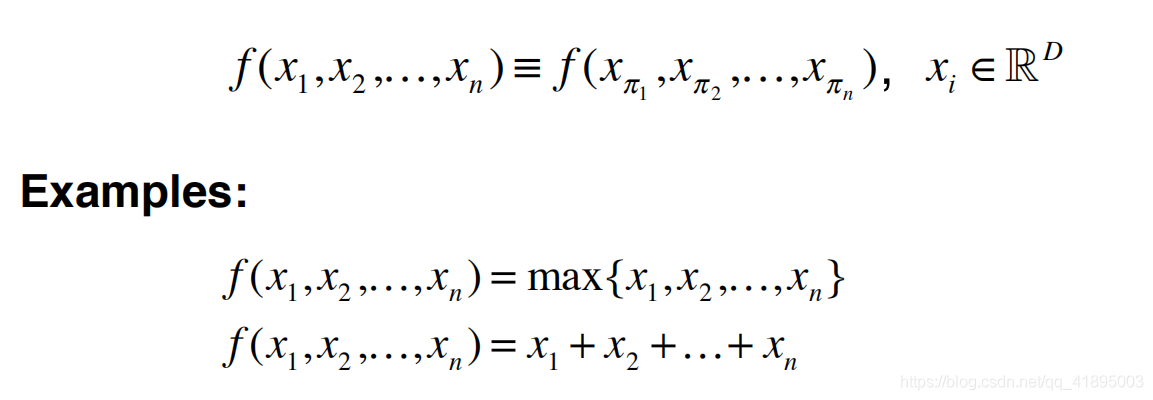
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
Directly perform symmetry operations on data , Although it satisfies the permutation invariance , It is easy to lose a lot of geometry and meaningful information . For example, when taking the maximum value , Only get the farthest point , Average. , Only get the center of gravity .
How not to lose
Map every point to high-dimensional space , Do symmetry operations on data in higher dimensional space . For the expression of three-dimensional points in high-dimensional space , It must be redundant , But because of the redundancy of information , We synthesize through symmetry operation , It can reduce the loss of information , Keep enough point cloud information . thus , You can design this PointNet The prototype of , be called PointNet(vanilla):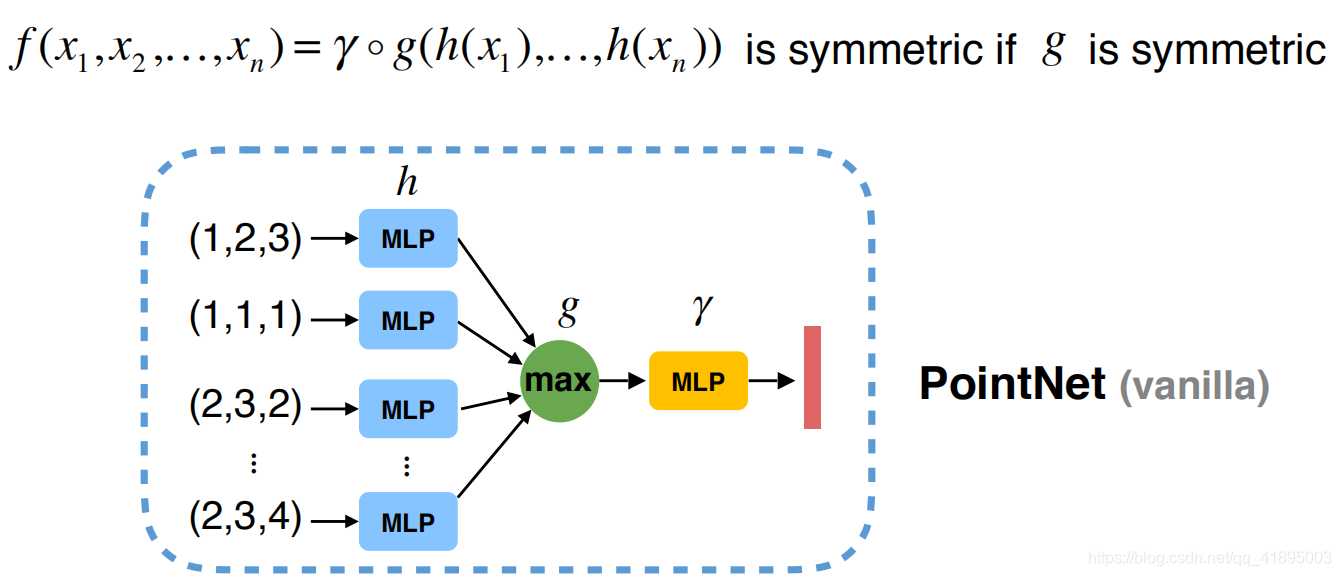
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
adopt MLP Project each point into high-dimensional space , adopt max Do symmetry .
MLP Why can it be projected into high-dimensional space ( This is an explanation for Xiaobai , Click here to )
PointNet Can arbitrarily approximate symmetric functions ( By increasing the depth and width of Neural Networks ):
The picture comes from Qi Rui Zhongtai, a doctoral student at Stanford University : Deep learning on point cloud and its application in 3D scene understanding
5.2 Rotation invariance ( Geometric invariance )
Rotation invariance refers to , By spinning , All points (x,y,z) The coordinates of change , But it's still the same object , As shown below :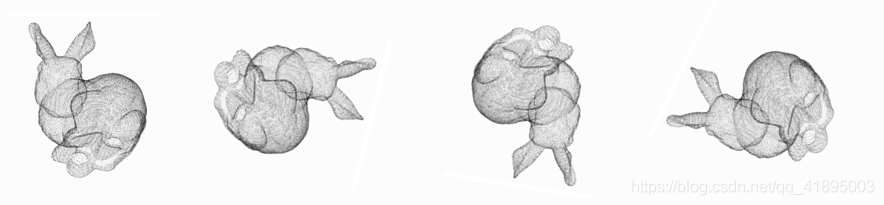
So for ordinary PointNet(vanilla), If you input the same object with different rotation angles successively , It may not recognize it well . The method in the paper is a new one T-Net Network to learn point cloud rotation , Calibrate the object , The rest PointNet(vanilla) Just classify or segment the calibrated object .
Point cloud is a kind of data that is very easy to do geometric transformation , Just multiply the matrix . As shown in the figure below , One N×3 Multiply the point cloud matrix by A 3×3 The rotation matrix of can get the matrix after rotation transformation , So learn one from the input point cloud 3×3 Matrix , You can correct it .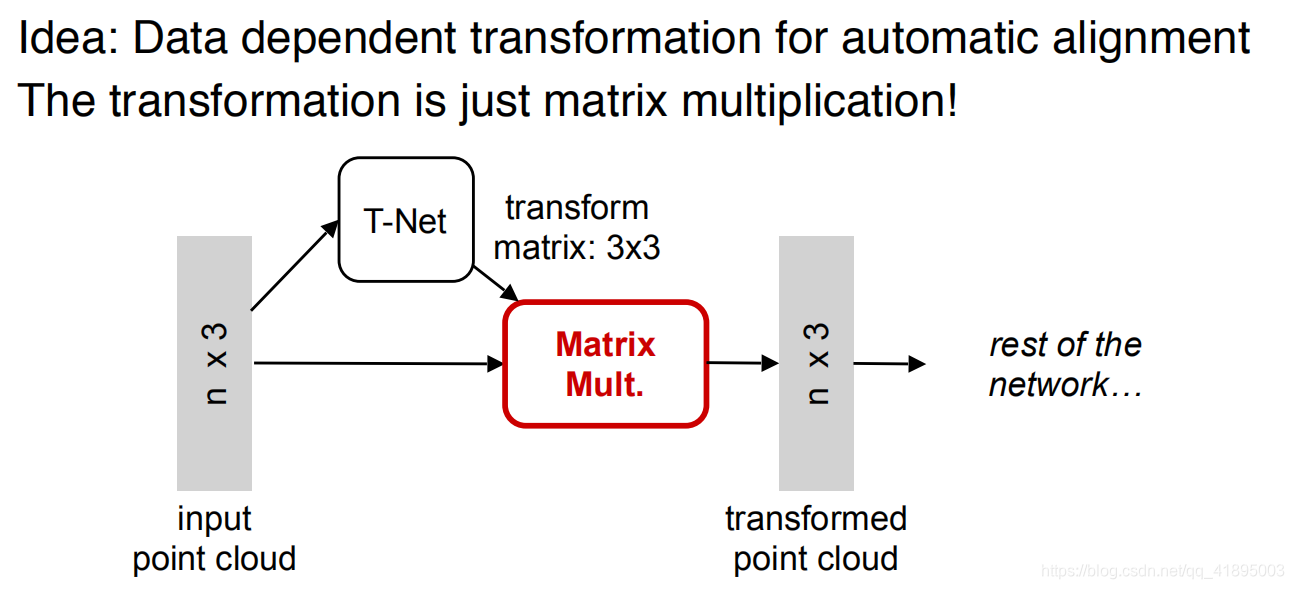
Similarly, map the point cloud to K After the redundant space of dimension , Right again K Check the point cloud features of dimension , But this proofreading needs to introduce a regularization penalty term , We want it to be as close as possible to an orthogonal matrix .【 Regularization is due to the difficulty of high-dimensional space optimization , Regularization can reduce the difficulty of optimization .】
Point cloud classification network :
say concretely , For each of these N×3 Point cloud input of , The network first goes through a T-Net Align it in space ( Rotate to the front ), Re pass MLP Map it to 64 On the high dimensional space of dimension , Again 64 Align the dimension space , Finally, it maps to 1024 Dimensional space . Now for every point , There is one. 1024 Vector representation of dimensions , And this vector representation for a 3 Dimensional point clouds are obviously redundant , Therefore, at this time, maximum pooling is introduced max pool operation , take 1024 Only the largest one remains on all channels of dimension , That's what we got 1×1024 The overall characteristics of . The global feature is through a cascaded fully connected network ( That's the last MLP), Finally, one K Classification results .
Point cloud segmentation network :
 The segmentation of point cloud can be defined as a classification problem of each point , If you know the classification of each point , This point can be divided into fixed categories . Of course , We cannot segment each point directly through the global coordinates . A simple and effective way is , We can put local characteristics , The features of a single point are combined with the global coordinates , Realize the function of segmentation . The simplest way is , We can put the overall characteristics , Repeat N All over , Then each one is connected with the features of the original single point .【
The segmentation of point cloud can be defined as a classification problem of each point , If you know the classification of each point , This point can be divided into fixed categories . Of course , We cannot segment each point directly through the global coordinates . A simple and effective way is , We can put local characteristics , The features of a single point are combined with the global coordinates , Realize the function of segmentation . The simplest way is , We can put the overall characteristics , Repeat N All over , Then each one is connected with the features of the original single point .【 Explanation of insertion : As mentioned above, local features and global features are combined (64+1024=1088), So it's not difficult to explain 1088 The origin of . Now? , A single point has 1088 dimension .】 It is equivalent to a single point being retrieved in the global feature ( That is, to look at the global characteristics of a single point “ I ” Where in this global feature ,“ I ” Which category should it belong to ?). We will do another for each connected feature MLP The change of , Finally, classify each point into M class , Equivalent to output M individual score.
边栏推荐
- Sqli-labs customs clearance (less2-less5)
- Ceaspectuss shipping company shipping artificial intelligence products, anytime, anywhere container inspection and reporting to achieve cloud yard, shipping company intelligent digital container contr
- SSM实验室设备管理
- SSM二手交易网站
- SSM personnel management system
- Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
- 华为机试题
- Get the uppercase initials of Chinese Pinyin in PHP
- Sparksql data skew
- ORACLE 11G利用 ORDS+pljson来实现json_table 效果
猜你喜欢

ORACLE EBS ADI 开发步骤

第一个快应用(quickapp)demo
![[introduction to information retrieval] Chapter 6 term weight and vector space model](/img/42/bc54da40a878198118648291e2e762.png)
[introduction to information retrieval] Chapter 6 term weight and vector space model
The first quickapp demo

Explain in detail the process of realizing Chinese text classification by CNN

The boss said: whoever wants to use double to define the amount of goods, just pack up and go

JSP intelligent community property management system
![[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table](/img/3f/09f040baf11ccab82f0fc7cf1e1d20.png)
[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table

User login function: simple but difficult

Feeling after reading "agile and tidy way: return to origin"
随机推荐
Cognitive science popularization of middle-aged people
一份Slide两张表格带你快速了解目标检测
Oracle rman半自动恢复脚本-restore阶段
[torch] some ideas to solve the problem that the tensor parameters have gradients and the weight is not updated
Delete the contents under the specified folder in PHP
中年人的认知科普
Ding Dong, here comes the redis om object mapping framework
【Torch】解决tensor参数有梯度,weight不更新的若干思路
Oracle rman自动恢复脚本(生产数据向测试迁移)
CRP implementation methodology
RMAN incremental recovery example (1) - without unbacked archive logs
Check log4j problems using stain analysis
User login function: simple but difficult
oracle-外币记账时总账余额表gl_balance变化(上)
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
使用Matlab实现:幂法、反幂法(原点位移)
[model distillation] tinybert: distilling Bert for natural language understanding
Pyspark build temporary report error
SSM实验室设备管理
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'