当前位置:网站首页>ACM mm 2022 video understanding challenge video classification track champion autox team technology sharing
ACM mm 2022 video understanding challenge video classification track champion autox team technology sharing
2022-07-01 17:26:00 【PaperWeekly】

PaperWeekly original · author | Caixiaochen , Caihengxing
Company | Fourth normal form
Research direction | Video understanding
ACM Multimedia( abbreviation ACM MM) Began in 1993 year , It is the top event for academic and industrial exchanges in the international multimedia field , It is also the only one in the multimedia field recommended by the Chinese computer society A International Academic Conference . Video understanding pre training challenge (Pre-training For Video Understanding Challenge) It is one of the important events held by it .
In this competition , Fourth normal form AutoX The team used a new time-domain multi-scale pre training video classification scheme , Won the first place in the video classification circuit with obvious advantages .

Introduction to the contest question
In recent years , With the rise of short video , There are hundreds of millions of multimedia videos on the Internet , These videos often have topics such as video 、 Weak markers such as classification , With high marking noise , Features such as large category span . Although the latest advances in computer vision have been in video classification 、 Video with text 、 Video target detection and other fields have achieved great success , How to effectively use a large number of unmarked or weakly marked videos that widely exist in the Internet is still a topic worthy of study . This time Pre-training For Video Understanding Challenge The competition aims to promote people's research on video pre training technology , Encourage the research team to design new pre training techniques to improve a series of downstream tasks .
In this article, we focus on the video classification track , The competition offers from Youtube The contents grabbed from the top 300 Pre training data set of 10000 videos YOVO-3M, Each video is included in Youtube The video title and a query As a video category ( Such as bowling、archery、tigher cat etc. ), At the same time, it provides a downstream task data set containing 100000 videos YOVO-downstream, Data set from 70173 Training set of videos 、16439 Verification set of videos and 16554 The test set of videos consists of , These videos are divided into 240 Of the predefined categories , Including objects ( Such as Aircraft、Pizza、Football) And human action ( Such as Waggle、High jump、Riding).
In this track , stay YouTube Video and YOVO-3M Corresponding query and title The foundation is , The goal of the contestants is to get a general representation of the video through pre training , It can be further used to promote the downstream tasks of video classification . The competition requires contestants to provide YOVO-3M Data sets ( As training data ) And published YOVO Downstream data sets ( As training data for downstream tasks ) Develop video classification system . Finally, the classification system is used in the downstream task data set top-1 Accuracy as a measure . meanwhile , There is no restriction on the use of external data sets .

query: brushing
title: Disney Jr Puppy Dog Pals Morning Routine Brushing Teeth, Taking a Bath, and Eating Breakfast!

Solution
We developed a “ Multiple time domain resolution integration ” technology , Improve the effect of model pre training and downstream tasks through integrated learning , And it integrates seven different network structures to learn different video representations . In the following pages , We will introduce the multi time domain resolution integration technology proposed by the team and briefly introduce several network structures we used in the competition .
2.1 Ensemble on Multiple Temporal Resolutions
Ensemble learning can significantly improve the performance of models in various tasks , One of the core of the variance reduction method is that different base learners are needed to learn different knowledge from the data , Thus, the final generalization performance can be improved through the consensus of different base learners .Bagging [13] Is one of the representative algorithms . We from Bagging Starting from the thought of , It is different from the way of training subsets by random sampling in the original algorithm , We use different time-domain sampling rates to sample video , Get training sets with different time-domain resolutions , So as to train different basic learners . Experiments show that our method can significantly improve the effect of integration , meanwhile , Because every basic learner can use all training videos , And then achieve higher single model performance , Our method is also better than the traditional Bagging Integration strategy .

▲ Fusion With Multiple Temporal Resolusion
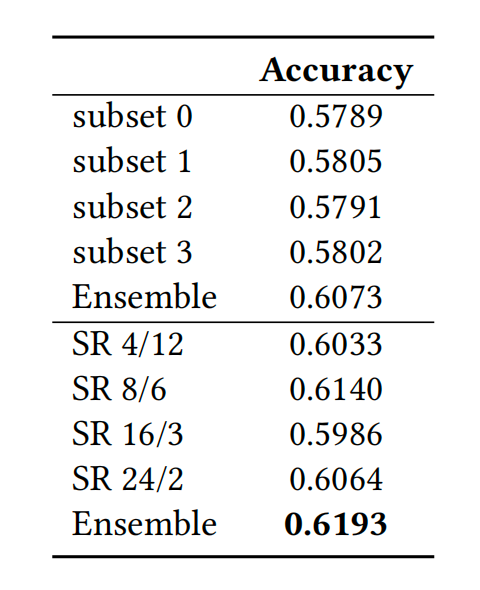
▲ Integrated experiment
2.2 Backbones
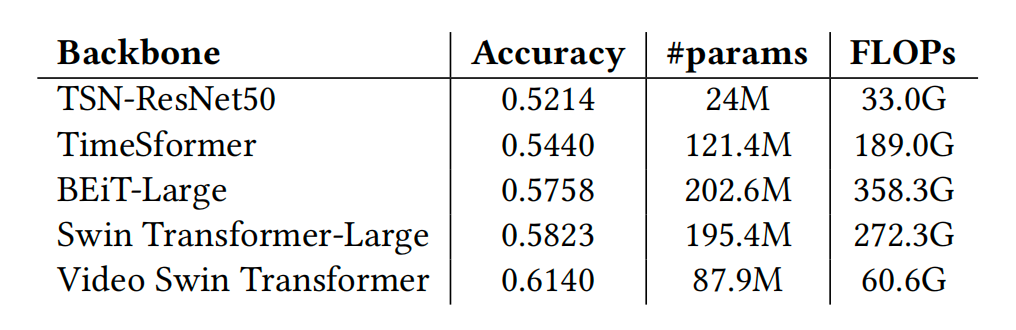
We tested Temporal Segment Network [10,11]、TimeSformer [2]、BEiT [1]、Swin Transformer [7]、Video Swin Transformer [8] Five kinds Frame-based The Internet and Spatiotemporal The Internet . In the experiment ,Video Swin Transformer Achieved the best model effect . We also compare the computational complexity of different network structures .
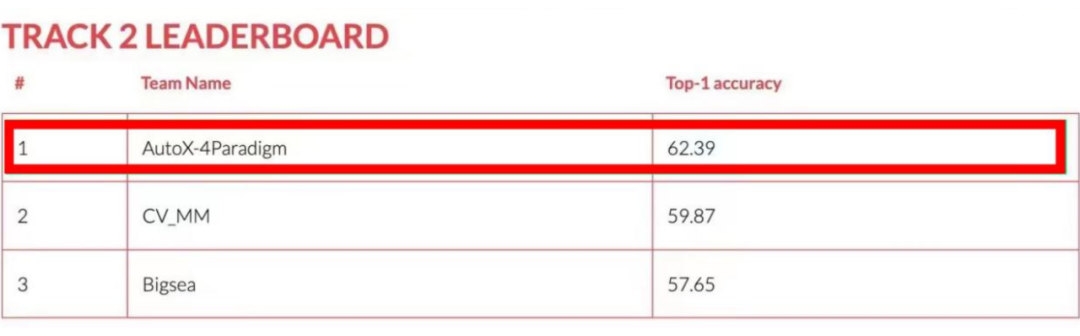
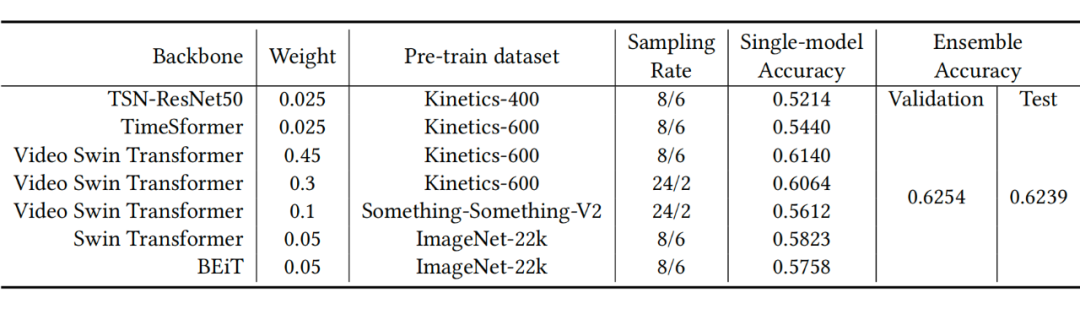
In the final submission , We will have seven different network structures 、 Model integration with different pre training data sets and different sampling rates , The optimal test set is obtained top-1 precision 62.39, Finally, I won the first place in the video classification circuit of this race .

summary
This time ACM Multimedia 2022 Video understanding contest , We use the integration strategy of multiple time-domain sampling , At the same time, integrate a variety of different network structures and pre training data sets , Finally, it won the first place in the video classification circuit of this race , It proposes a new way for video understanding and pre training .

reference
[1] Hangbo Bao, Li Dong, and Furu Wei. 2021. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 (2021).
[2] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is space-time attention all you need for video understanding?. In ICML, Vol. 2. 4.
[3] Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. 2018. A short note about kinetics-600. arXiv preprint arXiv:1808.01340
(2018).
[4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
[5] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. 2017. The" something something" video database for learning and evaluating visual common sense. In Proceedings of the IEEE international conference on computer vision. 5842–5850.
[6] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950 (2017).
[7] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10012–10022.
[8] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. 2022. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3202–3211.
[9] Yingwei Pan, Yehao Li, Jianjie Luo, Jun Xu, Ting Yao, and Tao Mei. 2020. Autocaptions on GIF: A Large-scale Video-sentence Dataset for Vision-language Pre-training. arXiv preprint arXiv:2007.02375 (2020).
[10] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. 2016. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision. Springer,20–36.
[11] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. 2018. Temporal segment networks for action recognition in videos. IEEE transactions on pattern analysis and machine intelligence 41, 11 (2018), 2740–2755.
[12] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[13] Breiman L . Bagging predictors[J]. Machine Learning, 1996.
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- 剑指 Offer 20. 表示数值的字符串
- (1) CNN network structure
- [flask introduction series] cookies and session
- Babbitt | yuan universe daily must read: Naixue coin, Yuan universe paradise, virtual stock game Do you understand Naixue's tea's marketing campaign of "operation pull full"
- 深度优先遍历和广度优先遍历[通俗易懂]
- Report on research and investment prospects of UHMWPE industry in China (2022 Edition)
- Leetcode records - sort -215, 347, 451, 75
- China PBAT resin Market Forecast and Strategic Research Report (2022 Edition)
- ACL 2022 | 分解的元学习小样本命名实体识别
- 【Try to Hack】vulnhub DC4
猜你喜欢

Alibaba cloud, Zhuoyi technology beach grabbing dialogue AI

Sword finger offer 20 String representing numeric value
Computed property “xxx“ was assigned to but it has no setter.

【splishsplash】关于如何在GUI和json上接收/显示用户参数、MVC模式和GenParam
剑指 Offer 20. 表示数值的字符串

【PyG】文档总结以及项目经验(持续更新
How to use JMeter function and mockjs function in metersphere interface test
6月刊 | AntDB数据库参与编写《数据库发展研究报告》 亮相信创产业榜单
[pyg] document summary and project experience (continuously updated

String类
随机推荐
Sword finger offer 20 String representing numeric value
Petrv2: a unified framework for 3D perception of multi camera images
Machine learning 11 clustering, outlier discrimination
深度优先遍历和广度优先遍历[通俗易懂]
RadHat搭建内网YUM源服务器
pyqt5中,在控件上画柱状图
JDBC: deep understanding of Preparedstatement and statement[easy to understand]
中国茂金属聚乙烯(mPE)行业研究报告(2022版)
(17) DAC conversion experiment
Depth first traversal and breadth first traversal [easy to understand]
[flask introduction series] cookies and session
Redis distributed lock
SQL question brushing 584 Looking for user references
《中国智慧环保产业发展监测与投资前景研究报告(2022版)》
(28) Shape matching based on contour features
Cookies and session keeping technology
机器学习11-聚类,孤立点判别
中国酶制剂市场预测与投资战略研究报告(2022版)
C language input / output stream and file operation
National Security Agency (NSA) "sour Fox" vulnerability attack weapon platform technical analysis report