当前位置:网站首页>Python filtering sensitive word records
Python filtering sensitive word records
2020-11-06 01:28:00 【Elementary school students in IT field】
sketch :
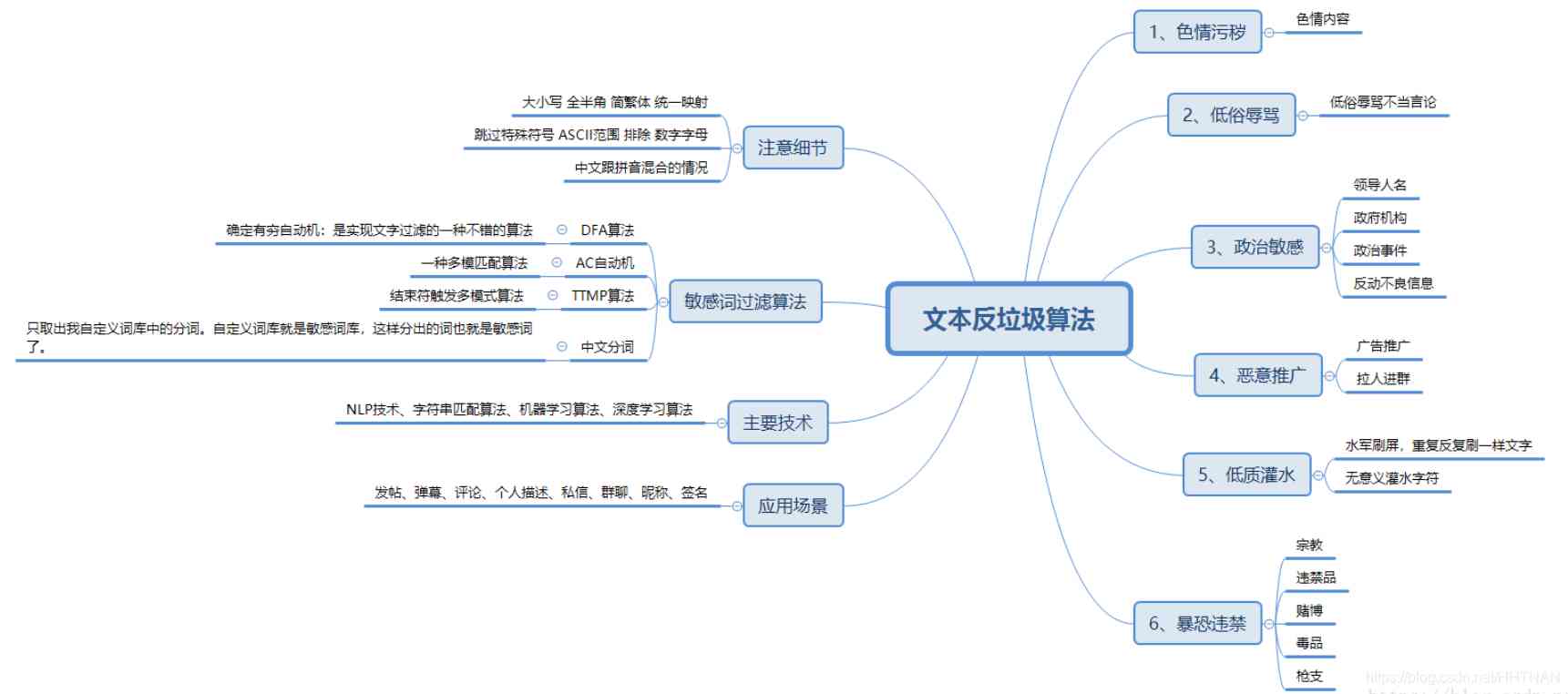
On sensitive word filtering can be seen as a text anti spam algorithm , for example
subject : Sensitive word text file filtered_words.txt, When the user enters sensitive words , Then use asterisk * Replace , For example, when the user enters 「 Beijing is a good city 」, Has become a 「** It's a good city 」
Code :
#coding=utf-8
def filterwords(x):
with open(x,'r') as f:
text=f.read()
print text.split('\n')
userinput=raw_input('myinput:')
for i in text.split('\n'):
if i in userinput:
replace_str='*'*len(i.decode('utf-8'))
word=userinput.replace(i,replace_str)
return word
print filterwords('filtered_words.txt')
Another example is the anti yellow series :
Develop sensitive word filters , Prompt users to enter comments , If the user's input contains special characters :
List of sensitive words li = [" Aoi Sora "," Tokyo fever ",” Wutenglan ”,” Yui Hatano ”]
Replace the sensitive words in the user's input with ***, And add it to a list ; If the user's input doesn't have sensitive words , Add it directly to the list above .
content = input(' Please enter your content :')
li = [" Aoi Sora "," Tokyo fever "," Wutenglan "," Yui Hatano "]
i = 0
while i < 4:
for li[i] in content:
li1 = content.replace(' Aoi Sora ','***')
li2 = li1.replace(' Tokyo fever ','***')
li3 = li2.replace(' Wutenglan ','***')
li4 = li3.replace(' Yui Hatano ','***')
else:
pass
i += 1
Practical cases :
Together bat Interview questions : Quick replacement 10 One hundred million titles 5 Ten thousand sensitive words , What are the solutions ?
There are a billion titles , In a file , One title per line . Yes 5 Ten thousand sensitive words , There is another file . Write a program to filter out all sensitive words in all headings , Save to another file .
1、DFA Filter sensitive words algorithm
In the algorithm of text filtering ,DFA Is a better algorithm .DFA namely Deterministic Finite Automaton, That is to say, definite finite automata .
The core of the algorithm is to establish many sensitive word trees based on sensitive words .
python Realization DFA Algorithm :
# -*- coding:utf-8 -*-
import time
time1=time.time()
# DFA Algorithm
class DFAFilter():
def __init__(self):
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
with open(path,encoding='utf-8') as f:
for keyword in f:
self.add(str(keyword).strip())
def filter(self, message, repl="*"):
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
return ''.join(ret)
if __name__ == "__main__":
gfw = DFAFilter()
path="F:/ Text anti spam algorithm /sensitive_words.txt"
gfw.parse(path)
text=" Xinjiang riot apple new product launch "
result = gfw.filter(text)
print(text)
print(result)
time2 = time.time()
print(' The total time is :' + str(time2 - time1) + 's')
Running effect :
Xinjiang riot apple new product launch
**** Apple launch **
The total time is :0.0010344982147216797s
2、AC Automata filter sensitive words algorithm
AC automata : A common example is to give n Word , Give me another paragraph that contains m One character article , Let you find out how many words appear in the article .
Simply speak ,AC Automata is a dictionary tree +kmp Algorithm + Mismatch pointer
# -*- coding:utf-8 -*-
import time
time1=time.time()
# AC Automata algorithm
class node(object):
def __init__(self):
self.next = {}
self.fail = None
self.isWord = False
self.word = ""
class ac_automation(object):
def __init__(self):
self.root = node()
# Add sensitive word function
def addword(self, word):
temp_root = self.root
for char in word:
if char not in temp_root.next:
temp_root.next[char] = node()
temp_root = temp_root.next[char]
temp_root.isWord = True
temp_root.word = word
# Failed pointer function
def make_fail(self):
temp_que = []
temp_que.append(self.root)
while len(temp_que) != 0:
temp = temp_que.pop(0)
p = None
for key,value in temp.next.item():
if temp == self.root:
temp.next[key].fail = self.root
else:
p = temp.fail
while p is not None:
if key in p.next:
temp.next[key].fail = p.fail
break
p = p.fail
if p is None:
temp.next[key].fail = self.root
temp_que.append(temp.next[key])
# Find sensitive word functions
def search(self, content):
p = self.root
result = []
currentposition = 0
while currentposition < len(content):
word = content[currentposition]
while word in p.next == False and p != self.root:
p = p.fail
if word in p.next:
p = p.next[word]
else:
p = self.root
if p.isWord:
result.append(p.word)
p = self.root
currentposition += 1
return result
# Load sensitive lexicon functions
def parse(self, path):
with open(path,encoding='utf-8') as f:
for keyword in f:
self.addword(str(keyword).strip())
# The substitution function of sensitive words
def words_replace(self, text):
"""
:param ah: AC automata
:param text: Text
:return: Filter the text after sensitive words
"""
result = list(set(self.search(text)))
for x in result:
m = text.replace(x, '*' * len(x))
text = m
return text
if __name__ == '__main__':
ah = ac_automation()
path='F:/ Text anti spam algorithm /sensitive_words.txt'
ah.parse(path)
text1=" Xinjiang riot apple new product launch "
text2=ah.words_replace(text1)
print(text1)
print(text2)
time2 = time.time()
print(' The total time is :' + str(time2 - time1) + 's')
Running results :
Xinjiang riot apple new product launch
**** Apple launch **
The total time is :0.0010304450988769531s

版权声明
本文为[Elementary school students in IT field]所创,转载请带上原文链接,感谢
边栏推荐
- 一篇文章带你了解CSS3 背景知识
- 阿里云Q2营收破纪录背后,云的打开方式正在重塑
- 100元扫货阿里云是怎样的体验?
- ES6学习笔记(五):轻松了解ES6的内置扩展对象
- Subordination judgment in structured data
- NLP model Bert: from introduction to mastery (1)
- Linked blocking Queue Analysis of blocking queue
- Skywalking series blog 2-skywalking using
- 钻石标准--Diamond Standard
- Python + appium automatic operation wechat is enough
猜你喜欢

What is the side effect free method? How to name it? - Mario

一篇文章带你了解CSS3 背景知识
一篇文章带你了解CSS对齐方式
Examples of unconventional aggregation
有了这个神器,快速告别垃圾短信邮件
ES6学习笔记(五):轻松了解ES6的内置扩展对象

How long does it take you to work out an object-oriented programming interview question from Ali school?
Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
JVM memory area and garbage collection
Grouping operation aligned with specified datum
随机推荐
如何玩转sortablejs-vuedraggable实现表单嵌套拖拽功能
Subordination judgment in structured data
Did you blog today?
一篇文章带你了解CSS对齐方式
Python saves the list data
I think it is necessary to write a general idempotent component
Examples of unconventional aggregation
至联云解析:IPFS/Filecoin挖矿为什么这么难?
How long does it take you to work out an object-oriented programming interview question from Ali school?
Architecture article collection
In order to save money, I learned PHP in one day!
前端工程师需要懂的前端面试题(c s s方面)总结(二)
Word segmentation, naming subject recognition, part of speech and grammatical analysis in natural language processing
Thoughts on interview of Ali CCO project team
Deep understanding of common methods of JS array
vue任意关系组件通信与跨组件监听状态 vue-communication
5.4 static resource mapping
Network security engineer Demo: the original * * is to get your computer administrator rights! 【***】
High availability cluster deployment of jumpserver: (6) deployment of SSH agent module Koko and implementation of system service management
6.5 request to view name translator (in-depth analysis of SSM and project practice)