当前位置:网站首页>入门:人脸专集1 | 级联卷积神经网络用于人脸检测(文末福利)
入门:人脸专集1 | 级联卷积神经网络用于人脸检测(文末福利)
2022-08-04 19:10:00 【计算机视觉研究院】
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
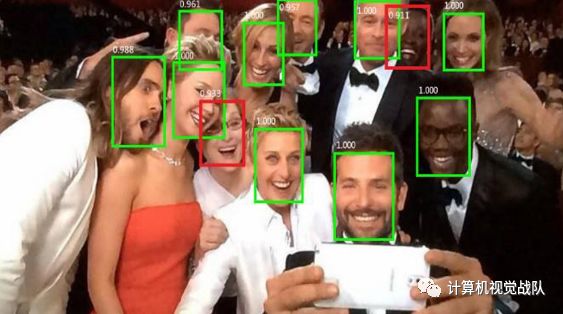
说到人脸检测,应该是近几年不老的话题了,如果要将这技术真的落实到现在产品,其实还有很长的路,不知道大家有没有发现,很多无人超市开始走下坡路,也许不仅仅是技术的原因之一吧,但是我们只针对技术来说,其实还是有很多不足需要去解决,这也是之后我们人脸这个专集和大家要说的,那我们就开始吧!
01
简 要
说到人脸检测,应该是近几年不老的话题了,如果要将这技术真的落实到现在产品,其实还有很长的路,不知道大家有没有发现,很多无人超市开始走下坡路,也许不仅仅是技术的原因之一吧,但是我们只针对技术来说,其实还是有很多不足需要去解决,这也是之后我们人脸这个专集和大家要说的,那我们就开始吧!
级联算法在人脸检测中得到了广泛的应用,其中首先可以使用计算量小的分类器来缩小大部分背景,同时保持召回。
今天说的这个技术就是提出了一种由两个主要步骤组成的级联卷积神经网络方法。第一阶段采用低像素候选窗口作为输入,使浅层卷积神经网络快速提取候选窗口;在第二阶段,调整来自前一阶段的窗口的大小,并将其分别用作对应网络层的输入。在训练期间,对hard-样本进行联合在线训练,并采用soft非极大抑制算法对数据集进行测试。整个网络在FDDB上实现了更好的性能。
开始详细讲解,先和大家回忆经典网络
02
Fully Convolution Network
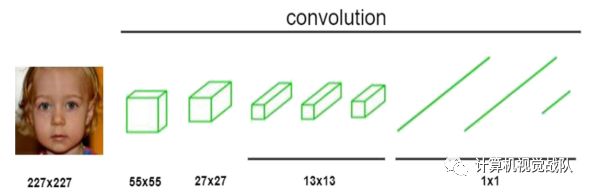
如上图所示,不知道细心的同学有发现差别所在不???
差别:全连接结构和完全卷积结构之间的区别表现在每一层的图像大小上。
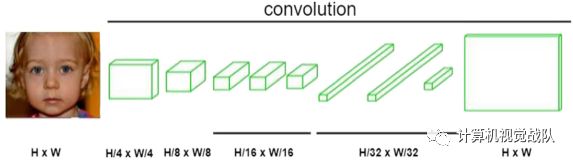
经过两次卷积和池化运算后,原始图像的分辨率由227×227变为55×55,第二次池化后图像大小为27×27,输出到第五层,图像大小减小到13×13。然而,在FCN中,以H×W大小的图像为输入,经过两次卷积和池化运算后,图像质量下降到原来图像的四分之一。然后,在每个池化层之后,图像的长度和宽度减少一半。
因此,卷积特征是原来尺寸输出的第五层的十六分之一。最后,将特征缩小到原来大小的三十二分之一。结果表明,经过多次卷积和池化运算后,图像大小明显减小。上面提到的最后一层可以得到最小尺寸的热图。它可以看作是重要的高维特征图。随后,对图像进行上采样并将其放大到原始图像大小,所述位置的像素结果与分类结果相对应。由于无条件图像大小的显著优势,在三个多分辨率网络中分别采用全卷积层,使得输入图像大小不再受限。
03
Spatial Pyramid Pooling
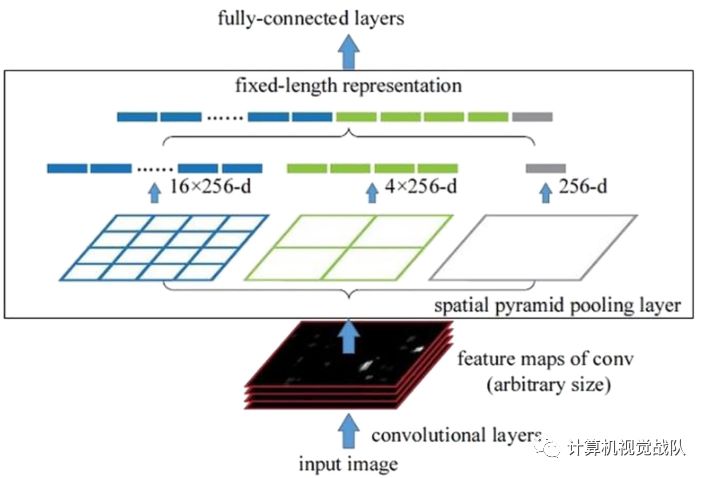
SPP-Net只在整个图像上运行一次CNN模型。然后,将通过选择性搜索得到的候选区域映射到特征映射。利用空间金字塔池化和支持向量机对候选目标进行分类。通过不固定尺寸的输入图像可以获得任意大小的卷积特征,只需保证输入到全连接层的大小是固定的。
使用FCN结构,这样就不能再限制输入图像的大小了。它将产生一个固定大小的输出。因此,总体结构不同于RCNN。下图给出了空间金字塔池层结构的流程图。
04
Cascade Structure
级联结构在人脸检测中得到了广泛的应用,首先可以利用计算量小的分类器来去除大部分背景,同时保持召回。
级联分类器在多个AdaBoost弱分类器或强分类器上对不同的特征进行顺序处理。级联结构如下图所示。该流程图不仅通过对多个弱分类器的组合,生成了一个强级联分类器,而且提高了分类器的速度。然而,以往方法的每个阶段都是独立训练的。因此,不同CNN的优化是相互独立的。
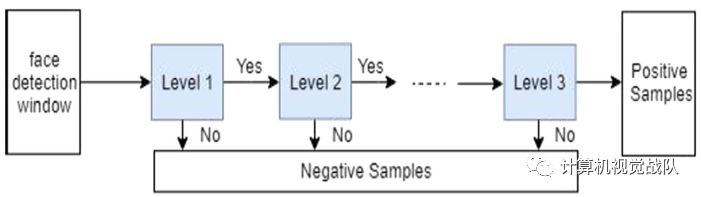

接下来开始今天技术的详解
结构设计
在这一部分中,我们将描述一个级联CNN的人脸检测使用三种不同分辨率的输入图像(12×12,24×24和48×48)。将输入图像调整到不同的尺度,形成图像金字塔。
首先,通过微网络(全卷积候选网络,FCPN)消除大量的非人脸窗口;然后,将候选窗口的其余部分输入到第二阶段(多尺度网络,MSN)。MSN-24表示输入大小为24×24的分支,而MSN-48表示输入大小为48×48的分支。将MSN-24第五层的卷积特征(即概率分布信息)与MSN-48融合。对不同级联阶段进行hard-样本挖掘和联合训练,完成人脸分类和边界框回归两项任务。
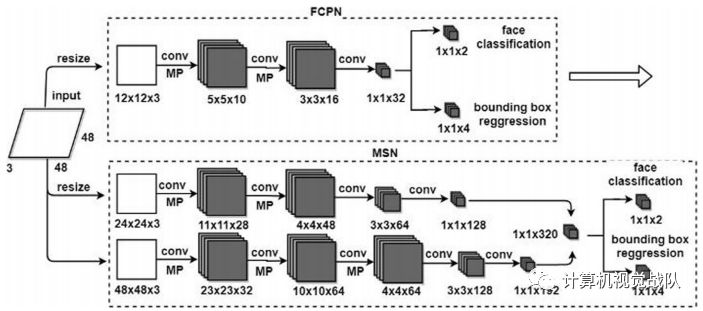
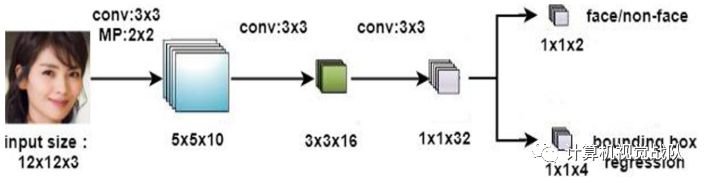
在工作中,输入图像被调整到不同尺度,以创建一个图像金字塔。检测过程分为两个阶段。第一阶段是全卷积候选网络(FCPN),它采用低分辨率浅卷积神经网络结构,快速有效地消除大量背景窗口,如下图所示。
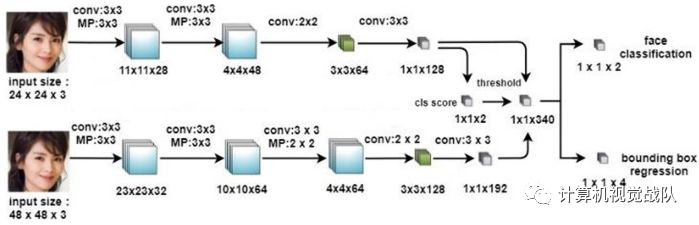
第二阶段是多尺度网络(MSN),它结合了加权阈值两种高分辨率卷积神经网络的特点,进一步滤除hard-样本,细化边界框。结构如下图。这两个阶段详细说明见“计算机视觉协会”知识星球。
接下来详细说说难样本挖掘!
与传统分类器训练中的难样本挖掘不同,在训练过程中自适应地选择难样本。在每一批中,计算候选区域的损失函数,并根据损失值对它们进行排序。选取损失值最高70%的目标区域作为难样本,忽略其余30%的简单样本。
为了评估该方法的有效性,训练了两种不同的比较模型(w/和w/o难样本的在线训练),并对测试集的性能进行了评估。下图给出了两个不同的结果。实线显示了难样品的挖掘性能。虚线显示不使用此方法的效果。实验结果表明,难样本的在线训练有助于提高检测性能,在FDDB上提供1.5%的性能增益。
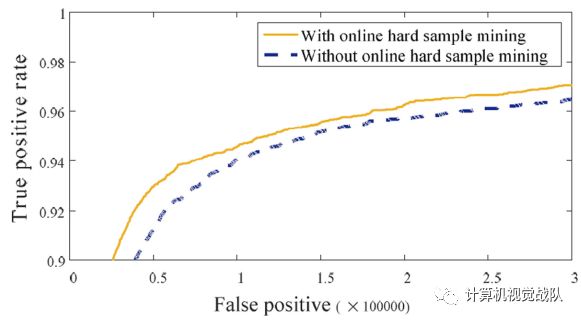
Soft极大抑制也会”计算机视觉协会“知识星球详细讲解,为啥会有如此高的性能提升!
实 验
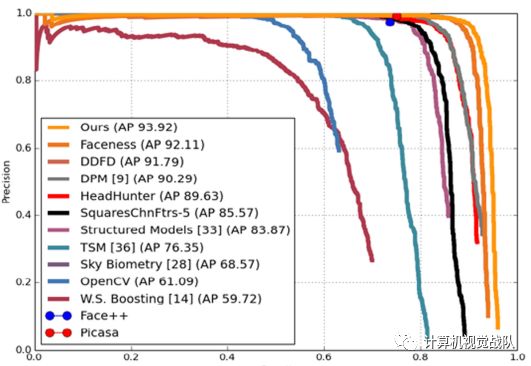
图 在Pascal Faces数据集上的结果
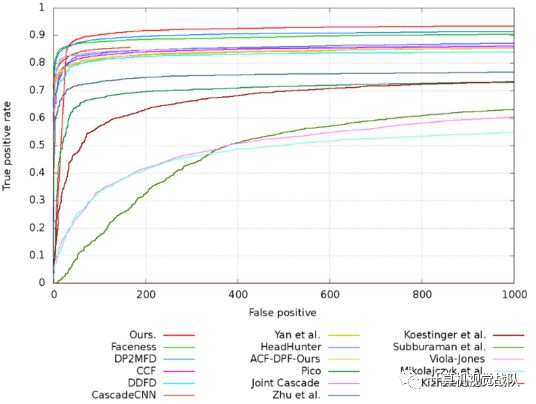
图 在FDDB人脸数据集上discROC的结果
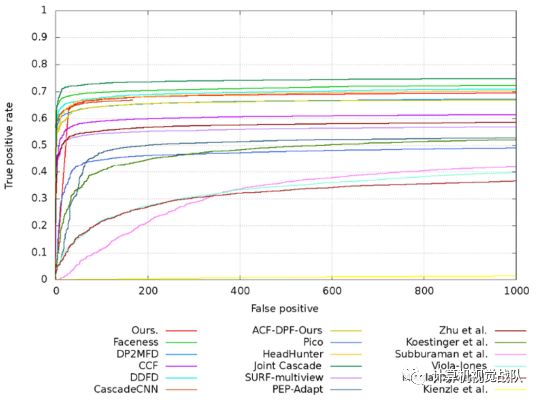
图 在FDDB人脸数据集上contROC的结果
检测可视化




THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
我们开创“计算机视觉协会”知识星球两年有余,也得到很多同学的认可,最近我们又开启了知识星球的运营。我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

边栏推荐
猜你喜欢



随机推荐
测试工程师如何突破职业瓶颈?
【简答题】月薪4k和月薪8k的区别就在这里
入选爱分析·银行数字化厂商全景报告,网易数帆助力金融数字化场景落地
企业应当实施的5个云安全管理策略
老电脑怎么重装系统win10
Redis数据库—定义、特点、安装、如何启动与停止
PostgreSQL的 SPI_接口函数
机器学习之支持向量机实例,线性核函数 多项式核函数 RBF高斯核函数 sigmoid核函数
lc marathon 8.3
The Development and Current Situation of Object Detection
关于使用腾讯云HiFlow场景连接器每天提醒签到打卡
重构指标之如何监控代码圈复杂度
什么是内部客户服务?
手把手教你CSP系列之script-src
Video Object Detection
Homework 8.3 Thread Synchronization Mutex Condition Variables
ELECTRA:Pre-training Text Encoders as Discriminators Rather Than Generators
How can test engineers break through career bottlenecks?
Finger Vein Recognition-matlab
路由技术