当前位置:网站首页>剪掉ImageNet 20%数据量,模型性能不下降!Meta斯坦福等提出新方法,用知识蒸馏给数据集瘦身...
剪掉ImageNet 20%数据量,模型性能不下降!Meta斯坦福等提出新方法,用知识蒸馏给数据集瘦身...
2022-07-05 09:35:00 【QbitAl】
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
这两天,推特上一个任务悬赏火得一塌糊涂。
一家AI公司提供25万美金(折合人民币约167万元),悬赏什么任务能让模型越大、性能反而越差。
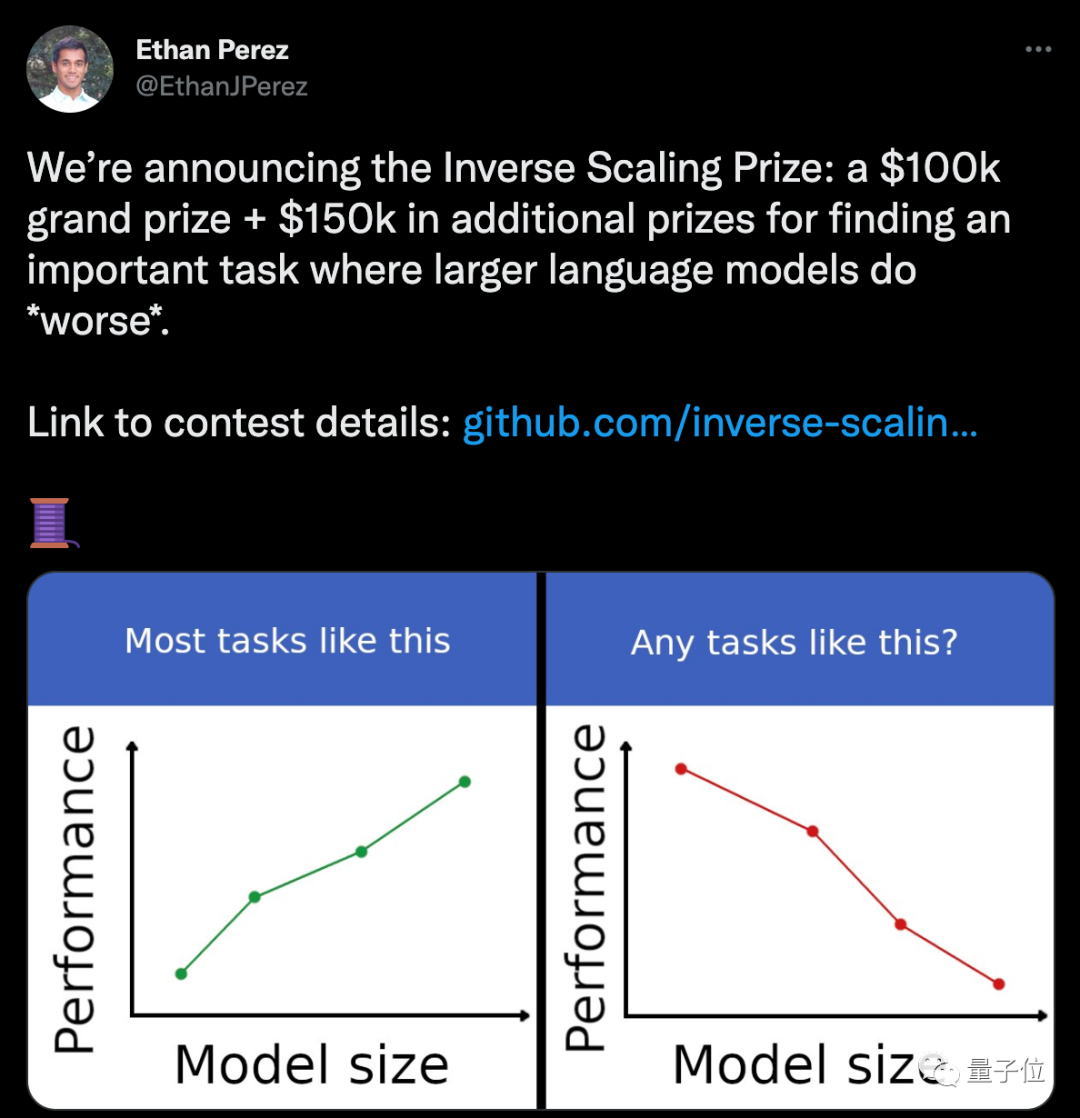
评论区里已经讨论得热火朝天了。
不过这事儿倒也不是单纯整活,而是为了进一步探索大模型。
毕竟,这两年大家越发意识到,AI模型不能单纯比“大”。
一方面,随着模型的规模越来越大,训练付出的成本开始呈现指数型增长;
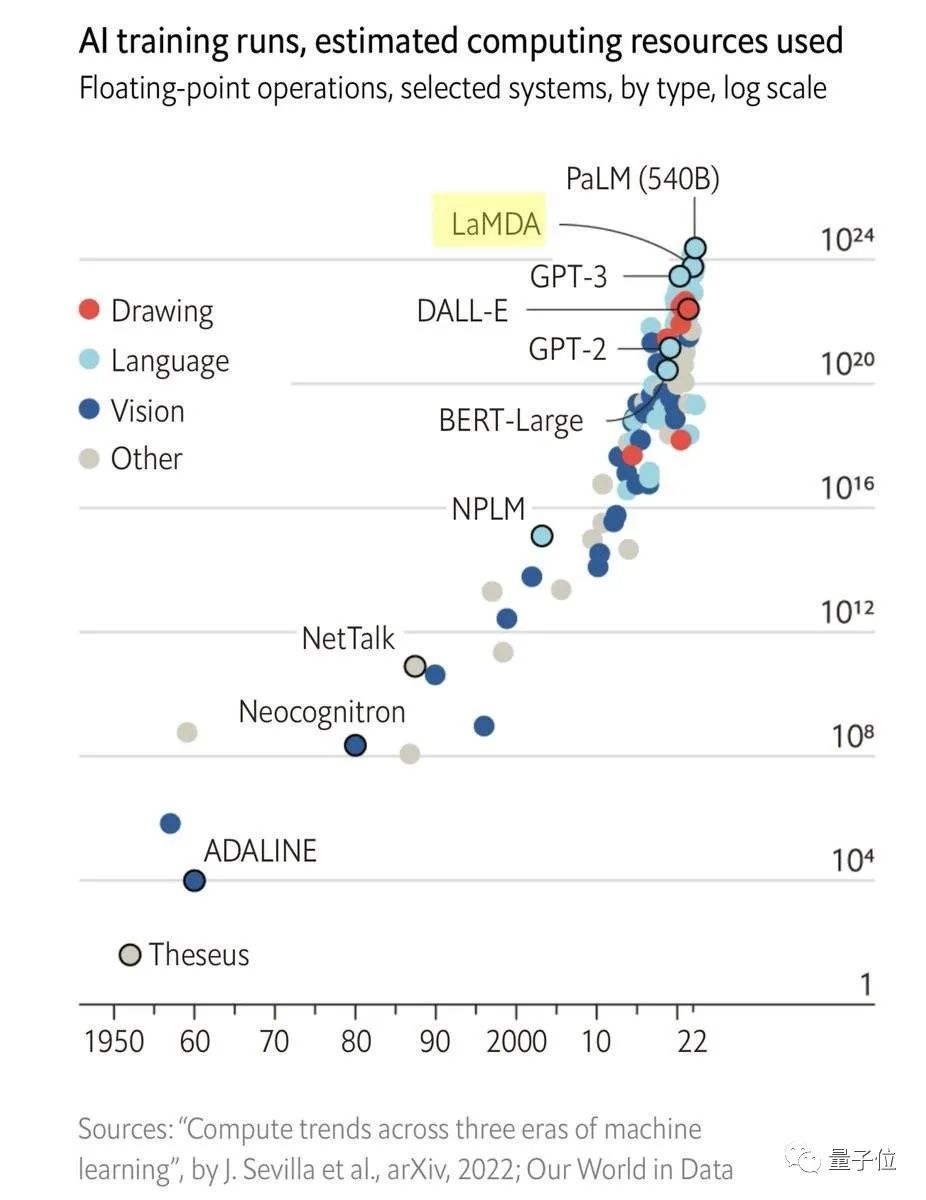
另一方面,模型性能的提升也已经逐渐到达瓶颈期,哪怕想要让误差再下降1%,都需要更多的数据集增量和计算增量。
比如对于Transformer而言,交叉熵损失想要从3.4奈特降低到2.8奈特,就需要原本10倍量的训练数据。
针对这些问题,AI学者们已经在从各种方向上找解决路子了。
Meta斯坦福的学者们,最近想到了从数据集上切入。
他们提出,对数据集进行知识蒸馏,使得数据集规模虽小,但还能保持模型性能不下降。
实验验证,在剪掉ImageNet 20%的数据量后,ResNets表现和使用原本数据时的正确率相差不大。
研究人员表示,这也为AGI实现找出了一条新路子。

超大数据集的效率并不高
本文提出的办法,其实就是对原本的数据集进行优化精简。
研究人员表示,过去许多方法都表明,许多训练示例是高度冗余的,理论上可以把数据集“剪”得更小。
而且最近也有研究提出了一些指标,可以根据训练示例的难度或重要性对它们进行排序,并通过保留其中一些难度高的示例,就能完成数据修剪。
基于前人的发现和研究,此次学者们进一步提出了一些可具体操作的方法。
首先,他们提出了一种数据分析方法,可以让模型只学习部分数据,就能实现同等的性能。
通过数据分析,研究人员初步得出结论:
一个数据集怎样修剪效果最好?这和它本身的规模有关。
初始数据量越多,越应该保留难度高的示例;
初始数据量越少,则应该保留难度低的示例。
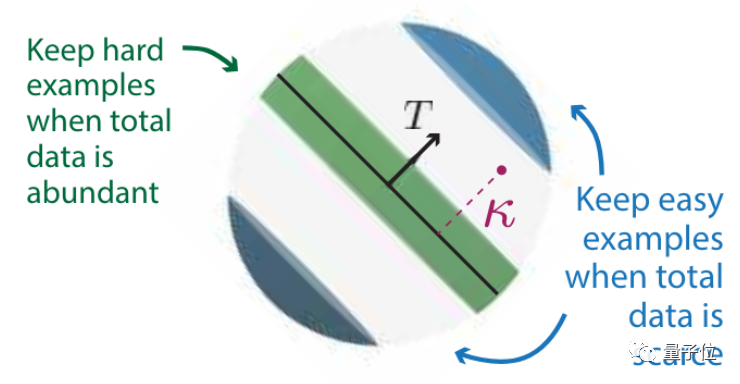
而在保留困难示例进行数据修剪后,模型和数据规模的对应关系,可以打破幂律分布。
常被提起的二八定律就是基于幂律提出的。
即20%的数据会影响80%的结果。
同时在此情况下,还能找到一个处于帕累托最优的下的极值。
这里所说的帕累托最优是指资源分配的一种理想状态。
它假设固定有一群人和可分配的资源,从一种分配状态调整到另一种分配状态,在没有使任何一个人变差的前提下,至少使得一个人变得更好。
在本文中,调整分配状态即可理解为,修剪多少比例的数据集。
然后,研究人员进行了实验来验证这一理论。
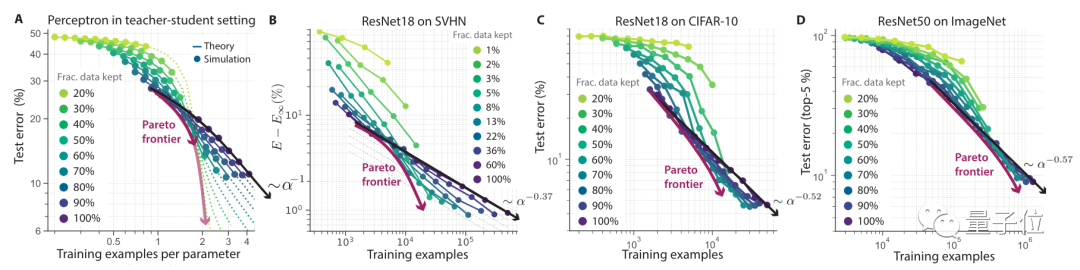
从实验结果来看,当数据集越大,修剪后的效果就越明显。
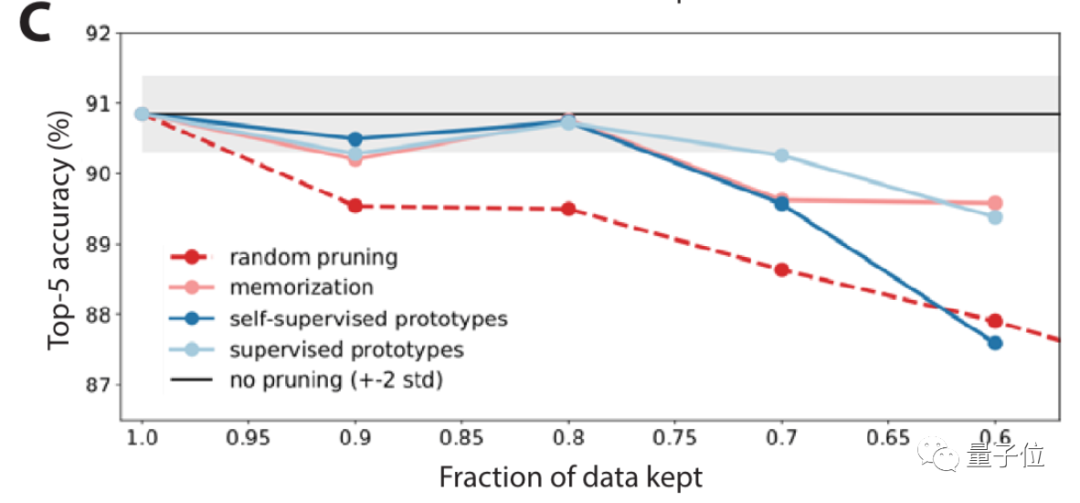
在SVHN、CIFAR-10、ImageNet几个数据集上,ResNet的错误率总体和数据集修剪规模呈反比。
在ImageNet上可以看到,数据集规模保留80%的情况下,和原本数据集训练下的错误率基本相同。
这一曲线也逼近了帕累托最优。
接下来,研究人员聚焦在ImageNet上,对10种不同情况进行了大规模基准测试。
结果表明,随机修剪以及一些修剪指标,在ImageNet上的表现并不够好。
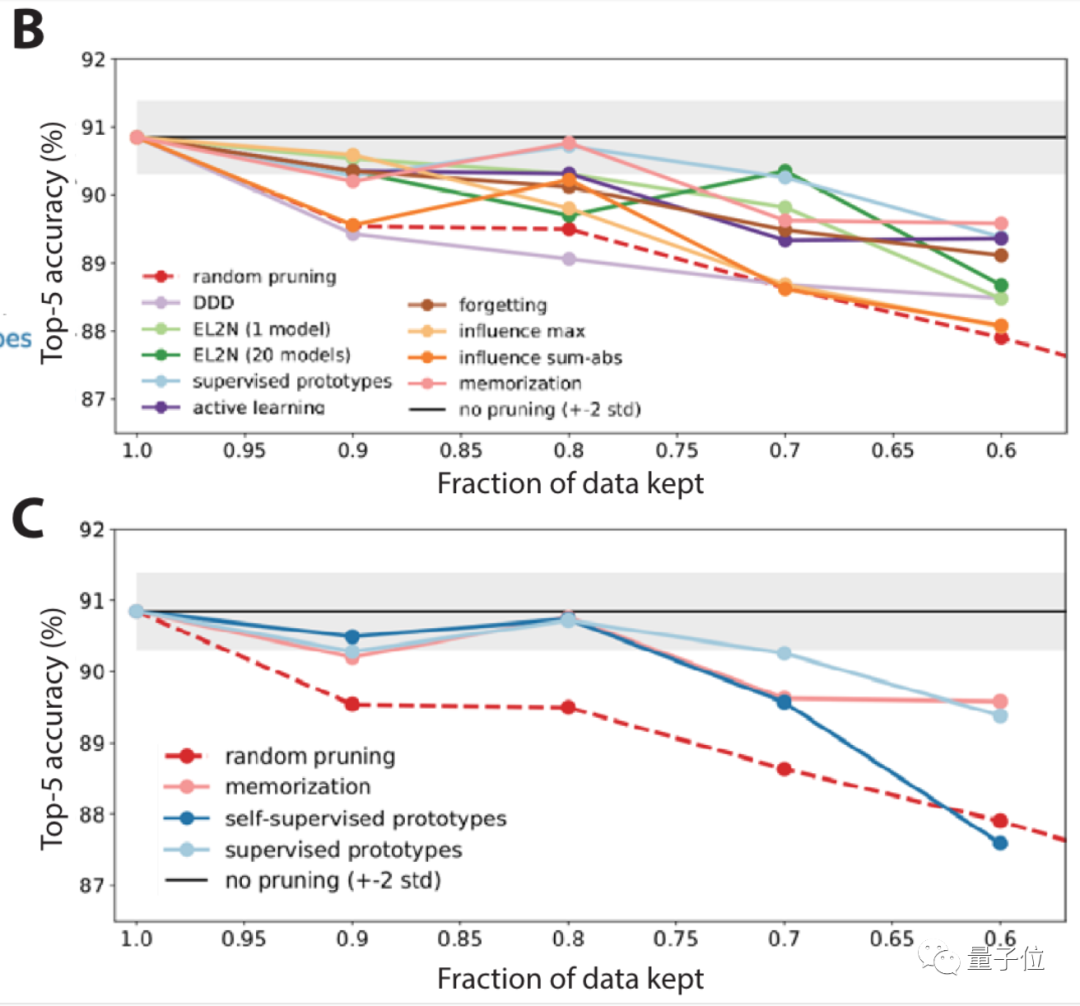
所以更进一步,研究人员还提出了一种自监督方法来修剪数据。
也就是知识蒸馏(教师学生模型),这是模型压缩的一种常见方法。
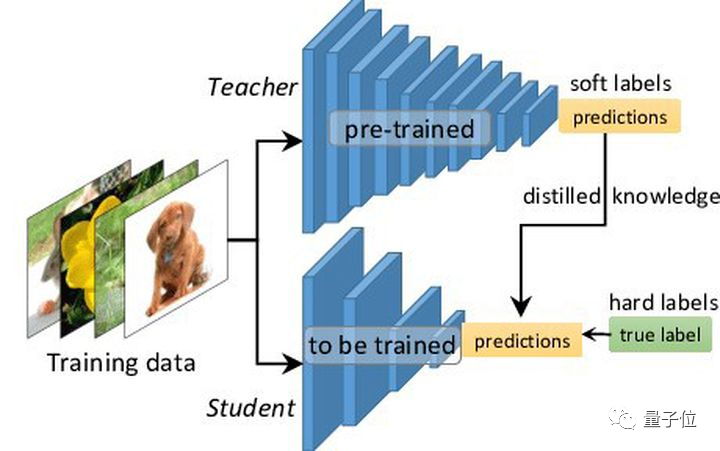
结果显示,在自监督方法下,它在找数据集中简单/困难示例上的表现都还不错。

使用自监督方法修剪数据后,正确率明显提高(图C中浅蓝色线)。
还存在一些问题
不过在论文中,研究人员也提到,虽然通过如上方法可以在不牺牲性能的情况下修剪数据集,但是有些问题仍旧值得关注。
比如数据集缩小后,想要训练出同等性能的模型,需要的时间可能会更长。
因此,在进行数据集修剪时,应该平衡缩减规模和训练增长时间两方面因素。
与此同时,对数据集进行修剪,势必会丧失一些群体的样本,由此也可能造成模型在某一个方面出现弊端。
在这方面会容易引起道德伦理方面的问题。
研究团队
本文作者之一Surya Ganguli,是量子神经网络科学家。

此前,他在斯坦福读本科期间,同时学习了计算机科学、数学和物理三个专业,之后拿下了电气工程与计算机科学硕士学位。
论文地址:
https://arxiv.org/abs/2206.14486
边栏推荐
- Android privacy sandbox developer preview 3: privacy, security and personalized experience
- 卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
- Baidu app's continuous integration practice based on pipeline as code
- E-commerce apps are becoming more and more popular. What are the advantages of being an app?
- OpenGL - Coordinate Systems
- [JS sort according to the attributes in the object array]
- How to implement complex SQL such as distributed database sub query and join?
- Tutorial on building a framework for middle office business system
- SQL learning alter add new field
- Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
猜你喜欢
Online chain offline integrated chain store e-commerce solution
Design and exploration of Baidu comment Center
百度智能小程序巡檢調度方案演進之路
OpenGL - Lighting

7 月 2 日邀你来TD Hero 线上发布会
移动端异构运算技术-GPU OpenCL编程(进阶篇)
The writing speed is increased by dozens of times, and the application of tdengine in tostar intelligent factory solution

The popularity of B2B2C continues to rise. What are the benefits of enterprises doing multi-user mall system?

百度交易中台之钱包系统架构浅析

Community group buying has triggered heated discussion. How does this model work?
随机推荐
A detailed explanation of the general process and the latest research trends of map comparative learning (gnn+cl)
Dry goods sorting! How about the development trend of ERP in the manufacturing industry? It's enough to read this article
How to correctly evaluate video image quality
Vs code problem: the length of long lines can be configured through "editor.maxtokenizationlinelength"
Android privacy sandbox developer preview 3: privacy, security and personalized experience
TDengine × Intel edge insight software package accelerates the digital transformation of traditional industries
[how to disable El table]
Three-level distribution is becoming more and more popular. How should businesses choose the appropriate three-level distribution system?
从“化学家”到开发者,从甲骨文到 TDengine,我人生的两次重要抉择
What should we pay attention to when developing B2C websites?
LeetCode 556. 下一个更大元素 III
MYSQL 对字符串类型排序不生效问题
分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
About getfragmentmanager () and getchildfragmentmanager ()
Community group buying exploded overnight. How should this new model of e-commerce operate?
[object array A and object array B take out different elements of ID and assign them to the new array]
Unity SKFramework框架(二十二)、Runtime Console 运行时调试工具
Idea debugs com intellij. rt.debugger. agent. Captureagent, which makes debugging impossible
The writing speed is increased by dozens of times, and the application of tdengine in tostar intelligent factory solution
Small program startup performance optimization practice