当前位置:网站首页>Yolov5 Lite: experiment and thinking of repovgg re parameterization on the industrial landing of Yolo
Yolov5 Lite: experiment and thinking of repovgg re parameterization on the industrial landing of Yolo
2022-07-08 02:20:00 【pogg_】

QQ Communication group :993965802
The copyright of this article belongs to GiantPandaCV, Please do not reprint without permission
This experiment mainly draws lessons from repvgg The idea of re parameterization , The original 3×3conv Replace with Repvgg Block, For the original YOLO Model rising point .
Preface : Once before shufflenetv2 And yolov5 The combination of , The purpose is to adapt arm Series of chips , Give Way yolov5 It can also achieve real-time performance on the end-side equipment . But in gpu perhaps npu Has also been trying to experiment , The purpose of such experiments is clear , It's not demanding , Mainly hope yolov5 It can speed up while maintaining the original accuracy .
experiment
This time the model is mainly for reference repvgg The idea of re parameterization , The original 3×3conv Replace with repvgg block, In the process of training , Using a multi branch model , And when deploying and reasoning , It uses the model of converting multiple branches into one path .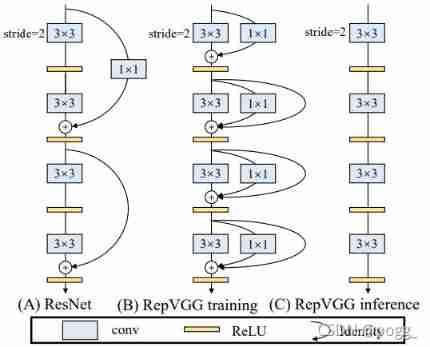
analogy repvgg The views expressed in the paper , there baseline The choice is yolov5s, Yes yolov5s Of 3×3conv refactoring , Separate one 1×1conv The side branch of .
In reasoning , Fuse collateral branches into 3×3 In convolution of , The model at this time is the same as the original yolov5s There is no difference in the model 
Before that , Use the most direct way to yolov5s Make magic changes , That is, directly replace backbone The way , But it is found that the parameter quantity and FLOPs Higher , The reproduction accuracy is closest to yolov5s Yes. repvgg-A1, as follows backbone Replace with A1 Of yolov5s:
Then , In order to suppress Flops And the increase of parameters , Take use of repvgg block Replace yolov5s Of 3×3conv The way .
The difference between the two Flops The ratio and parameter ratio are about 2.75 and 1.85.
performance
Through ablation experiments , It is concluded that the yolov5s And fusion repvgg block Of yolov5s The performance differences are as follows :
Evaluated here yolov5s stay map The indicators are different from the official website , After two tests, it was 55.8 and 35.8, But the test results are similar to https://github.com/midasklr/yolov5prune as well as Issue #3168 · ultralytics/yolov5 Almost the same . Use repvgg block restructure yolov5s Of 3×3 Convolution , stay [email protected] and @.5:.95 The indicators can be improved by at least one point .
After training repyolov5s Need to carry out convert, Will the collateral 1×1conv To merge , Otherwise, the reasoning will be better than the original yolov5s slow 20%.
Use convert.py Yes repvgg block Re parameterize , The main codes are as follows , Reference resources https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py:
# --------------------------repvgg refuse---------------------------------
def reparam conv(self): # fuse model Conv2d() + BatchNorm2d() layers
""" :param rbr_dense: 3×3 Convolution module :param rbr_1x1: 1×1 Collateral branch inception :param _pad_1x1_to_3x3_tensor: Yes 1×1 Of inception To expand :return: """
print('Reparam and Fusing Block... ')
for m in self.model.modules():
# print(m)
if type(m) is RepVGGBlock:
if hasattr(m, 'rbr_1x1'):
# print(m)
kernel, bias = m.get_equivalent_kernel_bias()
conv_reparam = nn.Conv2d(in_channels=m.rbr_dense.conv.in_channels,
out_channels=m.rbr_dense.conv.out_channels,
kernel_size=m.rbr_dense.conv.kernel_size,
stride=m.rbr_dense.conv.stride,
padding=m.rbr_dense.conv.padding, dilation=m.rbr_dense.conv.dilation,
groups=m.rbr_dense.conv.groups, bias=True)
conv_reparam.weight.data = kernel
conv_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
m.rbr_dense = conv_reparam
# m.__delattr__('rbr_dense')
m.__delattr__('rbr_1x1')
m.deploy = True
m.forward = m.fusevggforward # update forward
continue
# print(m)
if type(m) is Conv and hasattr(m, 'bn'):
# print(m)
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
We can do it by calling onnx Model for convert The models before and after are visualized :
Reasoning
map Indicators are only part of the reference , And part of it is about reparam and fuse After yolov5s Will it be because repvgg block Slow down due to implantation . In theory ,reparam After repvgg block Equivalent to 3×3 Convolution , However, the convolution is better than ordinary 3×3 Convolution is more compact .
After three tests coco val2017 After the dataset (5000 Zhang and single sheet reasoning ), obtain repyolov5s The estimated time of the leaflet is 14/14/14(ms)、yolov5s by 16/16/16(ms), Here I discussed with white God , White God believes that there may be test errors in the extremely close reasoning time between the two , Without any persuasion .
But to be sure convert After yolov5s Reasoning speed will not be because repvgg block Implant and slow down . In order to avoid contingency and measurement error , It's used here 500/5000/64115/118287 This picture is tested for reasoning :
The test results are as follows :
test
The detection effect should also be an indicator of concern , Use the above two models , Ensure that other parameters are consistent , Detect the picture , The effect is as follows :

summary
Use repvgg block Yes yolov5s Improvement , Through ablation experiments , Sum up the following points :
- The fusion repvgg block Of yolov5s It can rise points on both large and small targets ; Use fusion repvgg
- block and leakyrelu Of yolov5s Biyuan yolov5s stay map It's lower 0.5 percentage , But the speed can be improved 15%( Mainly replaced Silu What functions do );
- If you don't do convert, Personally, this fusion experiment is meaningless , The side branches will seriously affect the running speed of the model ;
- C3 Block and Repvgg Block stay cpu Low cost performance , stay gpu and npu The maximum gain can only be achieved by using on
- Use reparameterized yolov5 There is a price , The cost and loss are all in training , It will occupy more graphics card about 5-10% Explicit memory of , Training time will also increase
- Consider using repvgg block Yes yolov3-spp and yolov4 Of 3×3 Convolution for reconstruction
The code and pre training model will be put on my warehouse later :
https://github.com/ppogg/YOLOv5-Lite
边栏推荐
- 数据链路层及网络层协议要点
- Leetcode question brushing record | 27_ Removing Elements
- th:include的使用
- [knowledge map paper] r2d2: knowledge map reasoning based on debate dynamics
- 力扣4_412. Fizz Buzz
- Infrared dim small target detection: common evaluation indicators
- Leetcode question brushing record | 283_ Move zero
- Mqtt x newsletter 2022-06 | v1.8.0 release, new mqtt CLI and mqtt websocket tools
- 电路如图,R1=2kΩ,R2=2kΩ,R3=4kΩ,Rf=4kΩ。求输出与输入关系表达式。
- EMQX 5.0 发布:单集群支持 1 亿 MQTT 连接的开源物联网消息服务器
猜你喜欢
JVM memory and garbage collection-3-object instantiation and memory layout

Opengl/webgl shader development getting started guide
Semantic segmentation | learning record (2) transpose convolution

Dnn+yolo+flask reasoning (raspberry pie real-time streaming - including Yolo family bucket Series)

MQTT X Newsletter 2022-06 | v1.8.0 发布,新增 MQTT CLI 和 MQTT WebSocket 工具
COMSOL --- construction of micro resistance beam model --- final temperature distribution and deformation --- addition of materials

Unity 射线与碰撞范围检测【踩坑记录】
![[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning](/img/c1/4c147a613ba46d81c6805cdfd13901.jpg)
[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning

leetcode 865. Smallest Subtree with all the Deepest Nodes | 865.具有所有最深节点的最小子树(树的BFS,parent反向索引map)
excel函数统计已存在数据的数量
随机推荐
如何用Diffusion models做interpolation插值任务?——原理解析和代码实战
LeetCode精选200道--链表篇
Force buckle 5_ 876. Intermediate node of linked list
Yolo fast+dnn+flask realizes streaming and streaming on mobile terminals and displays them on the web
Kwai applet guaranteed payment PHP source code packaging
leetcode 873. Length of Longest Fibonacci Subsequence | 873. 最长的斐波那契子序列的长度
EMQX 5.0 发布:单集群支持 1 亿 MQTT 连接的开源物联网消息服务器
Redismission source code analysis
常见的磁盘格式以及它们之间的区别
CorelDRAW2022下载安装电脑系统要求技术规格
Exit of processes and threads
Ml self realization / linear regression / multivariable
Opengl/webgl shader development getting started guide
Literature reading and writing
云原生应用开发之 gRPC 入门
leetcode 869. Reordered Power of 2 | 869. Reorder to a power of 2 (state compression)
Node JS maintains a long connection
阿南的判断
Ncnn+int8+yolov4 quantitative model and real-time reasoning
分布式定时任务之XXL-JOB