当前位置:网站首页>Natural language processing - BM25 commonly used in search
Natural language processing - BM25 commonly used in search
2020-11-06 01:22:00 【Elementary school students in IT field】
BM25 Algorithm is a common formula used to score correlation degree , The idea is simple , The main thing is to calculate a query The relevance of all the words and documents in it , Then I'm adding up the scores , And the relevance score of each word is mainly affected by tf/idf Influence .
About Bim
BIM( Binary hypothesis model ) For word features , Just consider whether the word is in doc There has been , Not considering the relevant characteristics of the word itself ,BM25 stay BIM On the basis of the introduction of words in the query weight , Words in doc Weights in , And some empirical parameters , therefore BM25 In practical application, the effect is much better than BIM Model .
Concrete bm25
bm25 Algorithms are commonly used to calculate query Similar to the relevance of the article . In fact, the principle of this algorithm is very simple , Is what will need to be calculated query Divide words into w1,w2,…,wn, Then find out the relevance of each word and article , Finally, the correlation degree is accumulated , Finally, we can get the result of text similarity calculation .
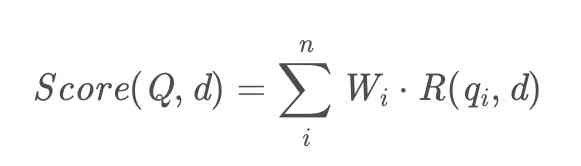
First Wi It means the first one i The weight of a word , We usually use TF-IDF Algorithm to calculate the weight of words, the second term of the formula R(qi,d) That means we query query Every word and article in d The relevance of , This one involves complex operations , Let's take a slow look at . Generally speaking Wi We usually use the inverse text frequency IDF Calculation formula :
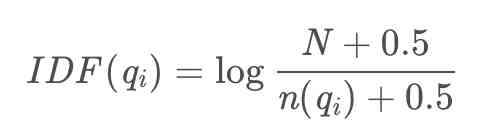
In this formula ,N Represents the total number of documents ,n(qi) Indicates the number of articles containing the word , To avoid that the denominator in the logarithm is equal to 0, We add... To the denominator 0.5, This 0.5 It's called the adjustment coefficient , So when n(qi) When I was younger IDF The more it's worth , The greater the weight of the signifier .
Here's a chestnut :“bm25” This word only appears in a few articles ,n(qi) It will be very small , that “bm25” Of IDF It's worth a lot ;“ We ”,“ yes ”,“ Of ” Such a word , Basically in every article there will be , that n(qi) It's very close to N, therefore IDF Value is very close to 0,
Then let's look at the second term in the formula R(qi,d), Now let's look at the formula for the second term :
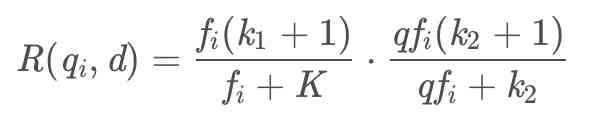
In this formula , Generally speaking ,k1、k2 and b It's all regulatory factors ,k1=1、k2=1、b = 0.75,qfi Express qi In the query query Frequency of occurrence in ,fi Express qi In the document d Frequency of occurrence in , Because in general ,qi In the query query Only once will , So the qfi=1 and k2=1 Put it in the formula above , The latter one is equal to 1, In the end, you can get :
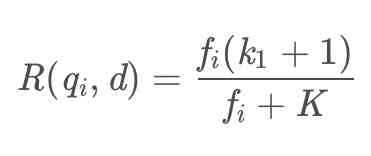
Let's see K, In fact, here K The value of is also an abbreviation of the formula , We put K Expand to see :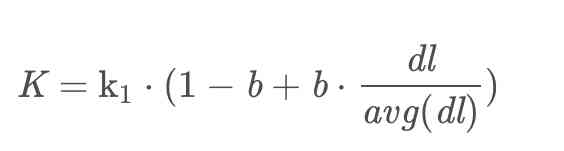
stay K In the expansion of dl Represents the length of the document ,avg(dl) Represents the average length of the document ,b Is the regulatory factor mentioned earlier , It can be seen from the formula that when the length of the article is fixed than the average length of the article , Regulatory factors b The bigger it is , The greater the weight of the article's length , On the contrary, the smaller . In regulating factors b Fixed time , When the length of the article is larger than the average length of the article , be K The bigger it is ,R(qi,d) The smaller . We put K The expansion of to bm25 Go to... In the formula :
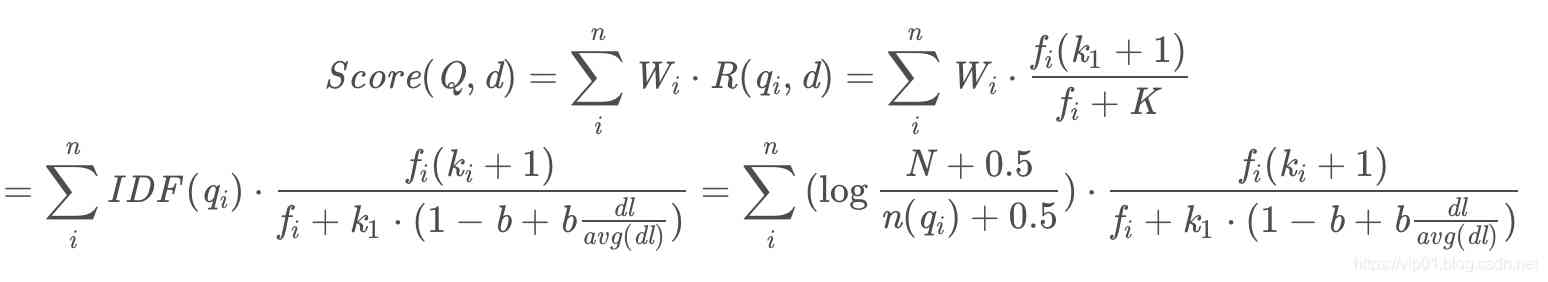
That's all bm25 The flow of the algorithm .
Here is the implementation process :
版权声明
本文为[Elementary school students in IT field]所创,转载请带上原文链接,感谢
边栏推荐
- 数字城市响应相关国家政策大力发展数字孪生平台的建设
- After reading this article, I understand a lot of webpack scaffolding
- Skywalking series blog 2-skywalking using
- 從小公司進入大廠,我都做對了哪些事?
- 关于Kubernetes 与 OAM 构建统一、标准化的应用管理平台知识!(附网盘链接)
- How to encapsulate distributed locks more elegantly
- Relationship between business policies, business rules, business processes and business master data - modern analysis
- 大数据应用的重要性体现在方方面面
- DevOps是什么
- 2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
猜你喜欢

如何将数据变成资产?吸引数据科学家
钻石标准--Diamond Standard
Troubleshooting and summary of JVM Metaspace memory overflow

Summary of common algorithms of linked list
Vue 3 responsive Foundation
Subordination judgment in structured data
Filecoin主网上线以来Filecoin矿机扇区密封到底是什么意思
一篇文章带你了解CSS 渐变知识

I've been rejected by the product manager. Why don't you know
PHP应用对接Justswap专用开发包【JustSwap.PHP】
随机推荐
Filecoin主网上线以来Filecoin矿机扇区密封到底是什么意思
ipfs正舵者Filecoin落地正当时 FIL币价格破千来了
Keyboard entry lottery random draw
Want to do read-write separation, give you some small experience
How to encapsulate distributed locks more elegantly
In depth understanding of the construction of Intelligent Recommendation System
PN8162 20W PD快充芯片,PD快充充电器方案
What is the difference between data scientists and machine learning engineers? - kdnuggets
Python + appium automatic operation wechat is enough
做外包真的很难,身为外包的我也无奈叹息。
htmlcss
html
如何玩转sortablejs-vuedraggable实现表单嵌套拖拽功能
中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
Polkadot series (2) -- detailed explanation of mixed consensus
After brushing leetcode's linked list topic, I found a secret!
华为云“四个可靠”的方法论
Not long after graduation, he earned 20000 yuan from private work!
xmppmini 專案詳解:一步一步從原理跟我學實用 xmpp 技術開發 4.字串解碼祕笈與訊息包
ES6学习笔记(四):教你轻松搞懂ES6的新增语法