当前位置:网站首页>Chapter 5 yarn resource scheduler
Chapter 5 yarn resource scheduler
2022-07-06 16:36:00 【Can't keep the setting sun】
Yarn It is a resource scheduling platform , Provide server computing resources for computing programs , Equivalent to a distributed operating system , and MapReduce Etc. is equivalent to the application running on the operating system .
5.1 Yarn Basic framework
YARN Mainly by ResourceManager、NodeManager、ApplicationMaster and Container Etc , As shown in the figure .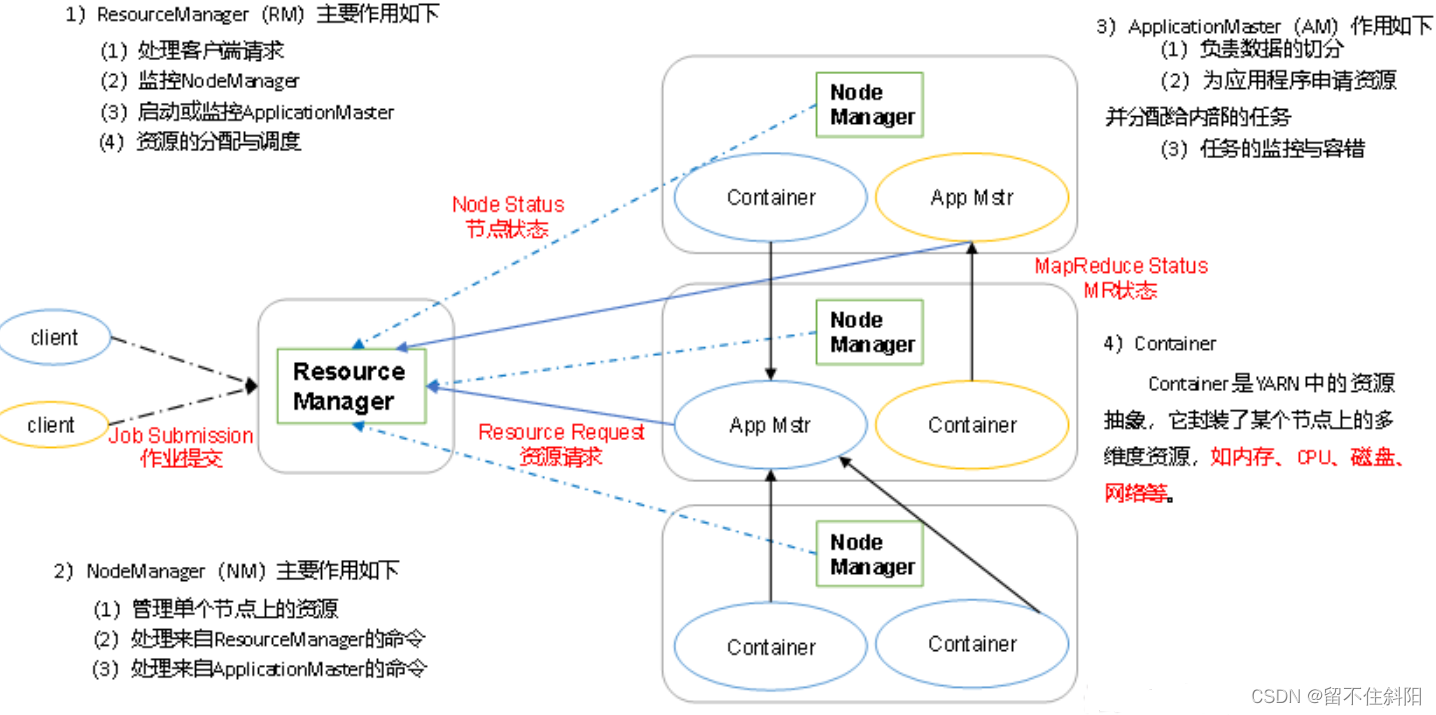
5.2 Yarn Working mechanism
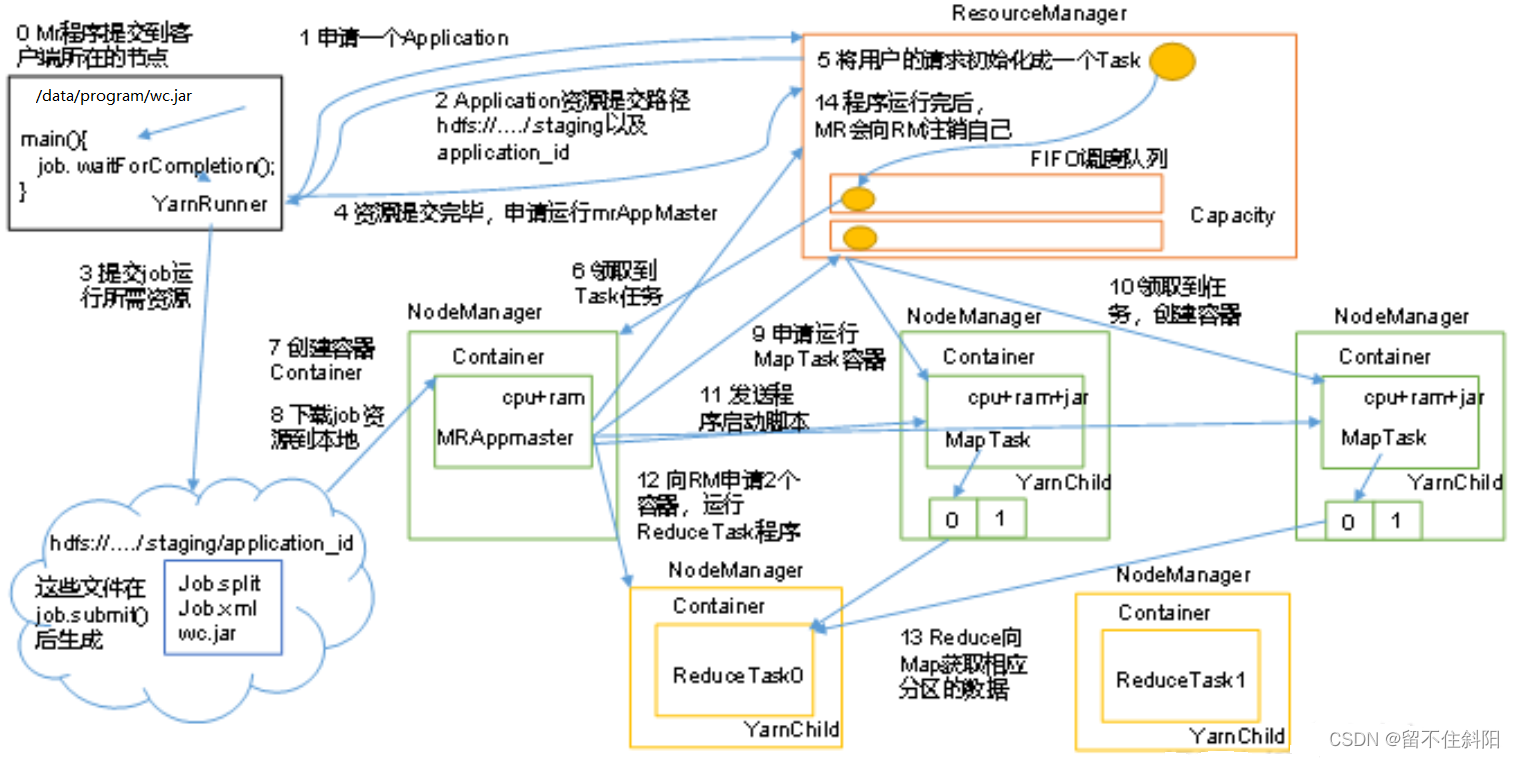
Details of working mechanism
- MR The program is submitted to the node where the client is located .
- YarnRunner towards ResourceManager Apply for one Application.
- RM Return the resource path of the application to YarnRunner.
- YarnRunner Submit the resources needed to run to HDFS On .
- After the program resources are submitted , Apply to run MRAppMaster.
- RM Initialize the user's request to a Task.
- One of them NodeManager Received Task Mission .
- The NodeManager Create a container Container, And produce MRAppMaster.
- Container from HDFS Copy resources to local .
- MRAppMaster towards RM Apply to run MapTask resources .
- RM Will run MapTask The task is assigned to the other two NodeManager, Two NodeManager Pick up tasks and create containers .
- MRAppMaster To receive the task from two NodeManager Send program startup script , these two items. NodeManager To start, respectively, MapTask.
- MrAppMaster Wait for all MapTask After running , towards RM Apply for containers , function ReduceTask.
- ReduceTask towards MapTask Get the data of the corresponding partition .
- After the program runs ,MRAppMaster Will send to RM Apply to cancel yourself .
5.3 Whole process of job submission
(1) Homework submission
The first 1 Step :Client call job.waitForCompletion Method , Submit... To the entire cluster MapReduce Homework .
The first 2 Step :Client towards RM Apply for an assignment id.
The first 3 Step :RM to Client Return to the job Resource submission path and job id.
The first 4 Step :Client Submit jar package 、 Slice information and configuration files to the specified resource submission path .
The first 5 Step :Client After submitting resources , towards RM Apply to run MRAppMaster.
(2) Job initialization
The first 6 Step : When RM received Client After request , Will be job Add to task scheduler .
The first 7 Step : Some free NM Take it Job.
The first 8 Step : The NM establish Container, And produce MRAppMaster.
The first 9 Step :MRAppMaster download Client Commit resources to local .
(3) Task assignment
The first 10 Step :MRAppMaster towards RM Apply to run multiple MapTask Task resources .
The first 11 Step :RM take MapTask The task is assigned to the other two NodeManager, another NodeManager Pick up tasks and create containers .
(4) Task run
The first 12 Step :MRAppMaster To receive the task from two NodeManager Send program startup script , these two items. NodeManager To start, respectively, MapTask,MapTask Process the data .
The first 13 Step :MrAppMaster Wait for all MapTask After running , towards RM Apply for containers , function ReduceTask.
The first 14 Step :ReduceTask towards MapTask Get the data of the corresponding partition .
The first 15 Step : After the program runs ,MRAppMaster Will send to RM Apply to cancel yourself .
(5) Progress and status updates
YARN The tasks in will have their progress and status ( Include counter) Back to application manager , Client per second ( adopt mapreduce.client.progressmonitor.pollinterval Set up ) Request progress updates from app Manager , Show it to the user .
(6) Homework done
In addition to ResourceManager Request out of job progress , Every client 5 Seconds will pass through the call waitForCompletion() To check whether the homework is finished . The time interval can pass through mapreduce.client.completion.pollinterval To set up . When the homework is done , Application manager and Container Will clean up the working state . The job information will be stored by the job history server for later user verification .
5.4 Resource scheduler
at present ,Hadoop There are three kinds of job scheduler :FIFO、Capacity Scheduler and Fair Scheduler.Hadoop2.7.2 The default resource scheduler is Capacity Scheduler.
See... For specific settings yarn-default.xml file
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
1. First in, first out scheduler (FIFO)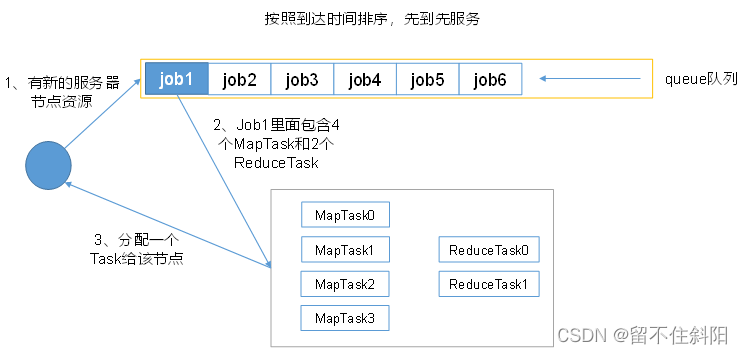
2. Capacity scheduler (Capacity Scheduler)
In the figure queueA Allocate up to 20% resources ,queueB Distribute 50%,queueC Distribute 30%. among queueC, Configure tenants ss、cls.
- Multi queue : Each queue can be configured with a certain amount of resources , Each queue uses FIFO Scheduling strategy .
- Capacity Guarantee : The administrator can set the minimum resource guarantee and upper resource limit for each queue ( As shown in figure, queueA Distribute 20% Resource cap )
- flexibility : If there are resources left in a queue , It can be temporarily shared with queues that need resources , Once a new application is submitted to the queue , The resources seconded from other queues will be returned to this queue .
- multi-tenancy : Support multi-user shared clusters ( As shown in figure, queueC, Configure tenants ss、cls) Run simultaneously with multiple applications ; In order to prevent the same user's jobs from monopolizing the resources in the queue , The scheduler limits the amount of resources that jobs submitted by the same user take up .
3. Fair scheduler (Fair Scheduler)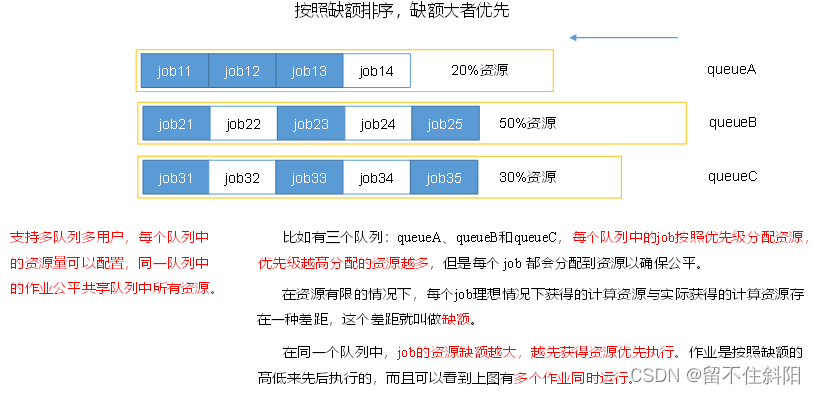
5.5 Speculative execution of tasks
1. Homework completion time depends on the slowest task completion time
An assignment consists of several Map The tasks and Reduce The composition of the task . Due to aging hardware 、 Software Bug etc. , Some tasks can be very slow .
reflection : There are 99% Of Map It's all done , There are only a few Map It's always slow , can't finish , What do I do ?
2. Speculate on the execution mechanism
Find the task that's holding you back , For example, the running speed of a task is much slower than the average speed of the task . Start a backup task for the tardy task , Running at the same time . Who runs first , And whose results to use .
3. Prerequisites for performing speculative tasks
(1) Every Task There can only be one backup task
(2) At present Job Completed Task Must be no less than 0.05(5%)
(3) Enable speculative execution parameters .mapred-site.xml The file is open by default .
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks may be executed in parallel.</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks may be executed in parallel.</description>
</property>
4. Speculative execution mechanism condition cannot be enabled
(1) There is a serious load skew between tasks ;
(2) special task , For example, the task writes data to the database .
5. Algorithm principle
Suppose a moment , Mission T The progress of implementation is progress, Then we can infer the final completion time of the task through a certain algorithm (estimateEndTime). On the other hand , If you start a backup task for that task right now , Then we can infer its possible completion time estimateEndTime’
estimatedRunTime=(currentTimestamp-taskStartTime)/progress
Guess the running time =( current time - Task start time )/ Task schedule
estimateEndTime=taskStartTime+estimatedRunTime
Guess the end time = Task start time + Guess the running time
estimateEndTime'=currentTimestamp+averageRunTime
Guess the end time of the backup task = current time + The average time to complete a task
(1) MR Always choose (estimateEndTime-estimateEndTime’) The task with the biggest difference , And start the backup task for it ;
(2) In order to prevent the waste of resources caused by starting a large number of backup tasks at the same time ,MR The maximum number of backup tasks started at the same time is set for each job ;
(3) The speculative execution mechanism actually adopts the classical optimization algorithm : Space for time , It starts multiple tasks at the same time to process the same data , And let these tasks compete to shorten data processing time . obviously , This method needs more computing resources . In the case of cluster resource shortage , The mechanism should be used reasonably , Try to use a little more resources , Reduce the calculation time of the job .
边栏推荐
- Research Report on market supply and demand and strategy of China's four seasons tent industry
- Tert butyl hydroquinone (TBHQ) Industry Research Report - market status analysis and development prospect forecast
- Candy delivery (Mathematics)
- 拉取分支失败,fatal: ‘origin/xxx‘ is not a commit and a branch ‘xxx‘ cannot be created from it
- Educational Codeforces Round 130 (Rated for Div. 2)A~C
- AcWing:第58场周赛
- Oneforall installation and use
- Codeforces - 1526C1&&C2 - Potions
- (POJ - 3579) median (two points)
- Tree of life (tree DP)
猜你喜欢


随机推荐
<li>圆点样式 list-style-type
Pytorch extract skeleton (differentiable)
How to insert mathematical formulas in CSDN blog
Input can only input numbers, limited input
China tetrabutyl urea (TBU) market trend report, technical dynamic innovation and market forecast
QT实现窗口置顶、置顶状态切换、多窗口置顶优先关系
Market trend report, technological innovation and market forecast of China's double sided flexible printed circuit board (FPC)
Click QT button to switch qlineedit focus (including code)
SF smart logistics Campus Technology Challenge (no T4)
Problem - 922D、Robot Vacuum Cleaner - Codeforces
简单尝试DeepFaceLab(DeepFake)的新AMP模型
Calculate the time difference
Candy delivery (Mathematics)
Flag framework configures loguru logstore
Summary of game theory
QNetworkAccessManager实现ftp功能总结
(lightoj - 1236) pairs forming LCM (prime unique decomposition theorem)
解决Intel12代酷睿CPU单线程调度问题(二)
300th weekly match - leetcode
QT按钮点击切换QLineEdit焦点(含代码)