当前位置:网站首页>A network composed of three convolution layers completes the image classification task of cifar10 data set
A network composed of three convolution layers completes the image classification task of cifar10 data set
2022-07-08 00:52:00 【Vertira】
paddle A network composed of three convolution layers cifar10 Image classification task of dataset
Article content source paddle Official website , The code is not very complete , Some have been modified , Ensure complete running code and effect diagram
Abstract : This example tutorial will demonstrate how to use the convolutional neural network of the propeller to complete the task of image classification . This is a relatively simple example , A network consisting of three convolution layers will be used cifar10 Image classification task of dataset .
One 、 Environment configuration
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import ToTensor
import numpy as np
import matplotlib.pyplot as plt
print(paddle.__version__)
paddle How to install and configure It's omitted here
Two 、 Load data set
This case will use the API Complete the data set download and prepare the data iterator for the subsequent training tasks .cifar10 Data set from 60000 The size of Zhang is 32 * 32 Color picture composition , Among them is 50000 Pictures form a training set , in addition 10000 Pictures form the test set . These pictures are divided into 10 Categories , A model will be trained to classify pictures correctly .
transform = ToTensor()
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
3、 ... and 、 Build a network
Next, use the propeller to define one, which uses three two-dimensional convolutions ( Conv2D ) And use after each convolution relu Activation function , Two two-dimensional pooling layers ( MaxPool2D ), And two linear transformation layers , Let's take one (32, 32, 3) The shape image is mapped to 10 Outputs , This corresponds to 10 Categories of categories .
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3))
self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3))
self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3))
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
Four 、 model training & forecast ¶
Next , Use a cycle to train the model , will :
Use
paddle.optimizer.AdamOptimizer to optimize .Use
F.cross_entropyTo calculate the loss value .Use
paddle.io.DataLoaderTo load data and build batch.
epoch_num = 10
batch_size = 32
learning_rate = 0.001
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
train_loader = paddle.io.DataLoader(cifar10_train,
shuffle=True,
batch_size=batch_size)
valid_loader = paddle.io.DataLoader(cifar10_test, batch_size=batch_size)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
if batch_id % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
model = MyNet(num_classes=10)
train(model)
Running results
start training ...
epoch: 0, batch_id: 0, loss is: [2.7433677]
epoch: 0, batch_id: 1000, loss is: [1.5053985]
[validation] accuracy/loss: 0.5752795338630676/1.1952502727508545
epoch: 1, batch_id: 0, loss is: [1.2686675]
epoch: 1, batch_id: 1000, loss is: [0.6766195]
[validation] accuracy/loss: 0.6521565318107605/0.9908956289291382
epoch: 2, batch_id: 0, loss is: [0.97449476]
epoch: 2, batch_id: 1000, loss is: [0.7748282]
[validation] accuracy/loss: 0.680111825466156/0.9200474619865417
epoch: 3, batch_id: 0, loss is: [0.7913307]
epoch: 3, batch_id: 1000, loss is: [1.0034081]
[validation] accuracy/loss: 0.6979832053184509/0.8721970915794373
epoch: 4, batch_id: 0, loss is: [0.6251695]
epoch: 4, batch_id: 1000, loss is: [0.6004331]
[validation] accuracy/loss: 0.6930910348892212/0.8982931971549988
epoch: 5, batch_id: 0, loss is: [0.6123275]
epoch: 5, batch_id: 1000, loss is: [0.8438066]
[validation] accuracy/loss: 0.710463285446167/0.8458449840545654
epoch: 6, batch_id: 0, loss is: [0.47533002]
epoch: 6, batch_id: 1000, loss is: [0.41863057]
[validation] accuracy/loss: 0.7125598788261414/0.8965839147567749
epoch: 7, batch_id: 0, loss is: [0.64983004]
epoch: 7, batch_id: 1000, loss is: [0.61536294]
[validation] accuracy/loss: 0.7009784579277039/0.9212258458137512
epoch: 8, batch_id: 0, loss is: [0.79953825]
epoch: 8, batch_id: 1000, loss is: [0.6168741]
[validation] accuracy/loss: 0.7134584784507751/0.8829751014709473
epoch: 9, batch_id: 0, loss is: [0.33510458]
epoch: 9, batch_id: 1000, loss is: [0.3573485]
[validation] accuracy/loss: 0.6938897967338562/0.9611227512359619
Show the code of the graph
plt.plot(val_acc_history, label = 'validation accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 0.8])
plt.legend(loc='lower right')
It is shown as follows

边栏推荐
- SDNU_ ACM_ ICPC_ 2022_ Summer_ Practice(1~2)
- 玩转Sonar
- ABAP ALV LVC模板
- Development of a horse tourism website (realization of login, registration and exit function)
- Thinkphp内核工单系统源码商业开源版 多用户+多客服+短信+邮件通知
- 接口测试要测试什么?
- 1293_FreeRTOS中xTaskResumeAll()接口的实现分析
- 浪潮云溪分布式数据库 Tracing(二)—— 源码解析
- Fofa attack and defense challenge record
- 51 communicates with the Bluetooth module, and 51 drives the Bluetooth app to light up
猜你喜欢
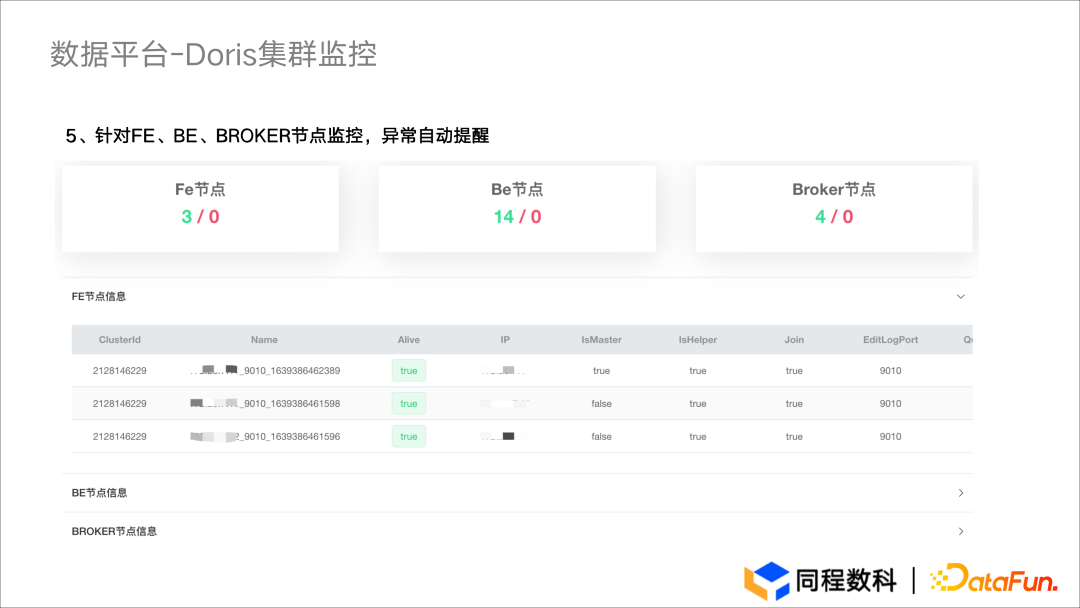
应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
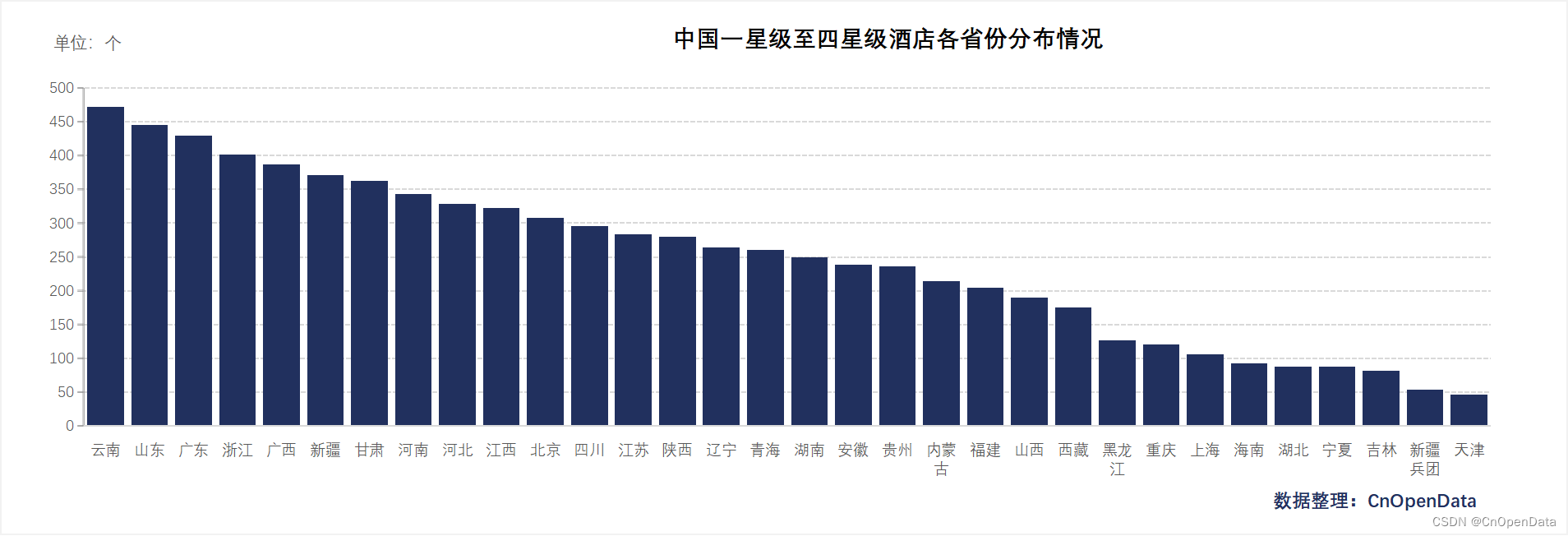
新库上线 | CnOpenData中国星级酒店数据

备库一直有延迟,查看mrp为wait_for_log,重启mrp后为apply_log但过一会又wait_for_log
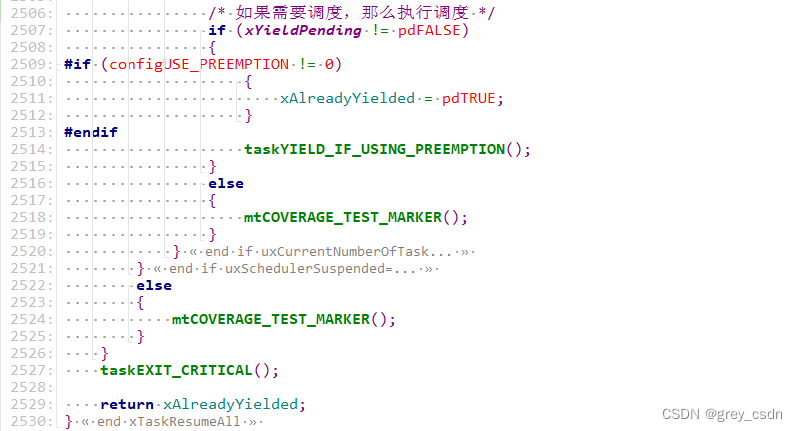
1293_ Implementation analysis of xtask resumeall() interface in FreeRTOS
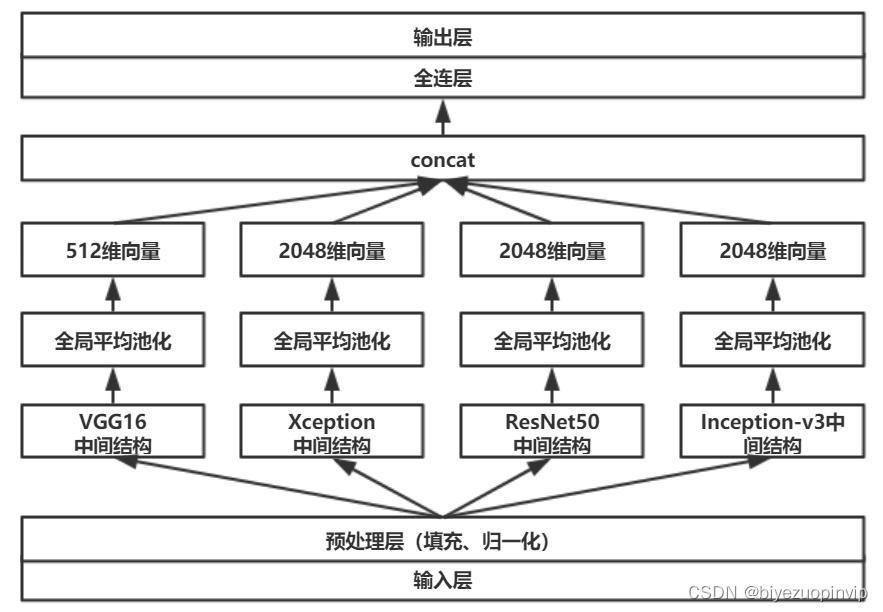
基于卷积神经网络的恶意软件检测方法
第一讲:链表中环的入口结点
Installation and configuration of sublime Text3

SDNU_ ACM_ ICPC_ 2022_ Summer_ Practice(1~2)

华为交换机S5735S-L24T4S-QA2无法telnet远程访问
My best game based on wechat applet development
随机推荐
Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades(KDD20)
Deep dive kotlin collaboration (the end of 23): sharedflow and stateflow
股票开户免费办理佣金最低的券商,手机上开户安全吗
v-for遍历元素样式失效
Stock account opening is free of charge. Is it safe to open an account on your mobile phone
詹姆斯·格雷克《信息简史》读后感记录
After going to ByteDance, I learned that there are so many test engineers with an annual salary of 40W?
Prompt configure: error: required tool not found: libtool solution when configuring and installing crosstool ng tool
Cve-2022-28346: Django SQL injection vulnerability
Is it safe to open an account on the official website of Huatai Securities?
51 communicates with the Bluetooth module, and 51 drives the Bluetooth app to light up
【测试面试题】页面很卡的原因分析及解决方案
German prime minister says Ukraine will not receive "NATO style" security guarantee
Deep dive kotlin synergy (XXII): flow treatment
Summary of the third course of weidongshan
The weight of the product page of the second level classification is low. What if it is not included?
How is it most convenient to open an account for stock speculation? Is it safe to open an account on your mobile phone
Lecture 1: the entry node of the link in the linked list
fabulous! How does idea open multiple projects in a single window?
基于卷积神经网络的恶意软件检测方法