当前位置:网站首页>Flink 解析(一):基础概念解析
Flink 解析(一):基础概念解析
2022-07-06 09:32:00 【Stray_Lambs】
目录
Flink 基本概念
目前在实时的框架当中,Flink可以说是具有一席之地的。Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如Hadoop YARN、Apache Mesos和Kubernetes,但也可以设置作为独立集群甚至库运行。并且Flink是作为流批一体化的计算框架,可以对有限数据流和无限数据流进行有状态或无状态的计算(即可以流式计算或者批量计算)。
Flink作为流批一体化的框架,其中流式处理是使用DataStream,而批处理则是使用DataSet。其中由以下几个核心组件。

Flink 运行时(runtime)由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。先放一张官网的架构图,简单的了解一下。
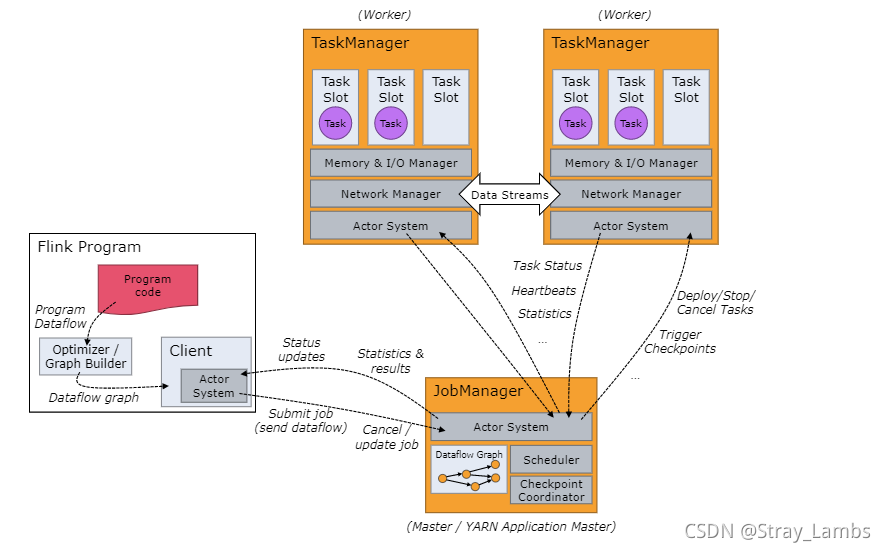
这里简单的说一下大概的整体流程:
当Flink集群启动后,首先会启动一个JobManager以及一个或者多个TaskManager。由客户端Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给JobManager。TaskManager之间以流的形式进行数据的传输。上述这些都是独立的JVM进程。
- Client为提交Job的客户端,可以是运行在任何机器上的,只要是与JobManager环境相连通即可。提交Job后,Client可以结束进程或者是等待结果返回都可以。
- JobManager主要是负责从Client接收到Job和Jar包等资源后,会生成优化后的执行计划,并以Task的单元调度到各个TaskManager去执行。
- TaskManager在启动的时候就设置好了slot槽位数,每个slot能启动一个Task,且Task为线程,这一点跟Spark的fork线程相类似。从JobManager接收需要部署的Task之后,与上游建立Netty连接,接收数据并进行处理。
- Flink架构中的角色间的通信使用的是Akka,比如JobManager与Client之间的通信,而数据之间的传输使用Netty。
1、Job Manager
JobManager是作业管理器,是一个主进程。主要工作负责:协调分布式计算;负责调度任务;协调checkpoint;协调故障恢复。具有以下三个组件组成:
- ResourceManager
ResourceManager 负责 Flink 集群中的资源申请、释放、分配,在HA中,RM还负责选取leader Job Manager。它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher
分发器(非必须)。Dispatcher 提供了一个 REST 接口(GET/PUT/DELETE/POST),用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI (localhost:8081)用来⽅便地展示和监控作业执⾏的信息。Dispatcher在架构中可能并不是必需的,这取决于应⽤提交运⾏的⽅式。
- JobMaster
JobMaster 负责管理单个JobGraph的执行。负责任务的接收,负责JobManagerRunner(封装了JobMaster)的启动。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
2、Task Manager
Task Manager(以下简称TM)是Flink中的⼯作进程(任务管理器)。通常在Flink中会有多个TM运⾏,每⼀个Task Manager都包含了⼀定数量的插槽(slots)。插槽的数量限制了TM能够执⾏的任务数量。其中每一个TM是一个JVM进程,而每一个slot是一个线程。
当启动一个TM时,TM会向Resource Manager反向注册它的slot;在后续的任务调度中,收到RM的指令后就会提供slot给JobManager。Job Manager就可以向slot分配任务来执行。在执行dataflow中的task时,TM将会进行缓存和交换数据(比如shuffle)。
任务提交流程
1、独立集群(Standalone)

2、Yarn集群

Yarn集群模式下,Client需要将jar包以及相关配置上传至HDFS中,并且会向RM以Session会话的方式提交Job(即jar包)。提交完成后,由RM在空闲的NodeManager中去启动ApplicationMaster去当作应用主节点,有点类似与Spark中的Driver。其中该NodeManager包含了JobManger,然后JobManager向HDFS中加载打包上传好的jar包和相关配置,根据需要去向RM申请启动TaskManager。当启动完成相应的TaskManager后,TM将会向RM反向注册slot。
程序与数据流
Flink程序由三部分组成:Source、Transformation和Sink。其中Source负责读取数据源,Transformation利用各种算子进行处理加工,Sink负责输出。

在运行期间,Flink上运行的程序会被映射成“逻辑数据流”(dataflows),每个dataflow以一个或多个source开始以一个或多个sinks结束。每一个dataflow都类似于DAG有向无环图。
执行图
Flink当中的执行图可以分成四层:
StreamGraph->JobGraph->ExecutionGraph->物理执行图
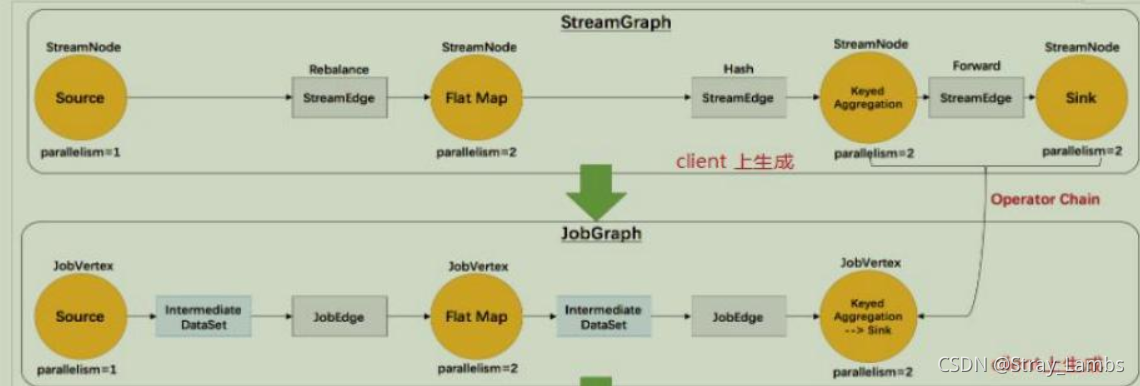
- StreamGraph: 根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。 在Client中生成。
- JobGraph:StreamGraph经过优化后生成了JobGraph,提交给了JobManager的数据结构。主要的优化为,将多个符合条件的节点chain在一起作为一个节点。在Client中生成。
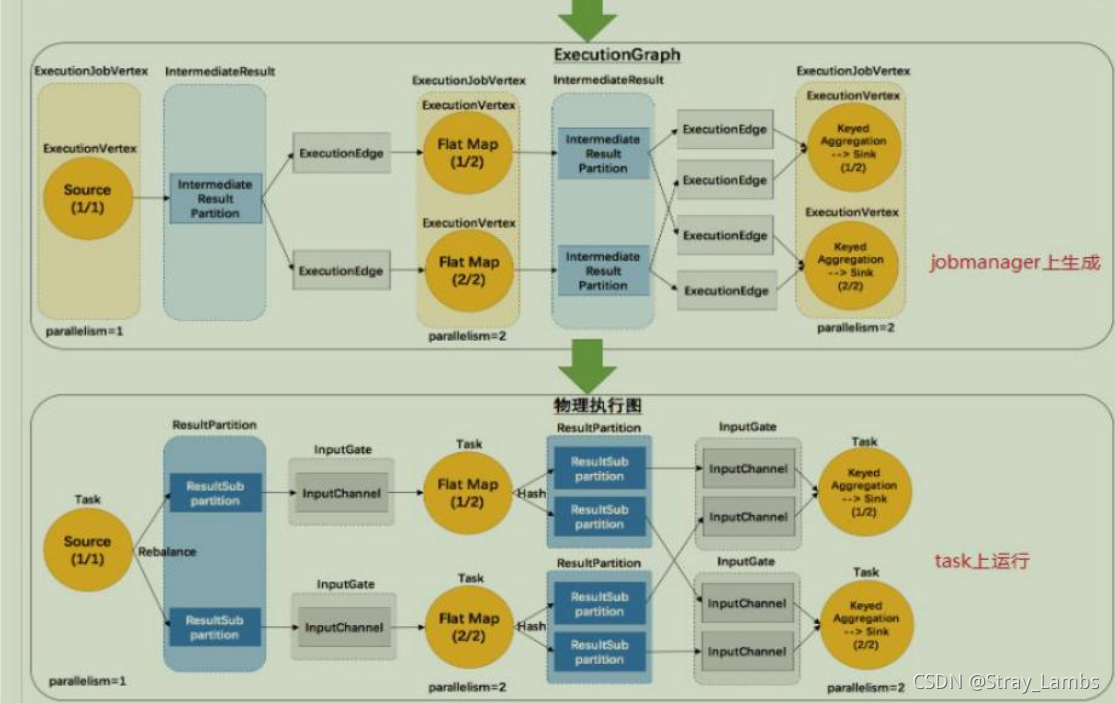
- ExecutionGraph:JobManager根据JobGraph生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。在JobManager中生成。
- 物理执行图:JobManager根据ExecutionGraph对Job进行调度后,在各个TaskManager上部署Task后形成的图,并不是一个具体的数据结构。
PS:后来发现如果加上每一个图的源码解读篇幅过长,我就打算分开放在接下来的博客里面...
跟Spark一样,Flink也是懒执行,用户逻辑代码会在Flink封装并执行完所有流程图后才开始运行。
每一个operator(类似于Spark当中的rdd算子)会生成对应的Transformation(比如Map对应的OneInputTransformation),最终直到运行到StreamExecutionEnvironment.execute(),类似于执行到了Spark当中action算子,才真正的执行代码,进行划分DAG以及各个阶段和任务,Flink也是如此开始划分Flink的执行图以及各种任务链。
数据传输形式
与Spark相类似的是,Flink的不同的算子也是具有宽窄的传输形式,只不过Flink称之为One-to-one和Redistributing。
- One-to-one(不涉及shuffle过程):有点类似与独生的感觉,上游数据只有一个下游接收数据。stream维护着分区以及元素的顺序(比如source和map之间)。这意味着map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap等算子都是one-to-one的对应关系。
- Redistributing(涉及shuffle过程):有点类似于多生的感觉,上游数据有多个下游接收数据。stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy 基于 hashCode 重分区、而 broadcast 和 rebalance 会随机重新分区,这些算子都会引起redistribute过程,而 redistribute 过程就类似于 Spark 中的 shuffle 过程。
任务链(Operator Chains)
Flink采用了一种称为任务链的优化技术,由于无论是跨NodeManager传输数据还是跨Task传数据,都可能造成通信的开销,所以Flink在特定的条件下减少本地通信的开销。若满足条件,则可以将两个甚至多个算子通过本地转发的方式进行连接。
- 相同并行度的one-to-one操作(并且需要相同组内),这样的算子可以进行链接在一起形成一个task,原来的算子成为了里面的一个subtask(立个flag,有机会写一篇任务链接的源码解读…)
以后源码解读和原理理解将分为两个模块,不然篇幅过大…
参考
边栏推荐
- 汇编语言寻址方式
- Activiti目录(五)驳回、重新发起、取消流程
- Some instructions on whether to call destructor when QT window closes and application stops
- Restful style interface design
- Description of project structure configuration of idea
- The difference between URI and URL
- 一个数10年工作经验的微服务架构老师的简历
- 吴军三部曲见识(七) 商业的本质
- Monomer application concept
- Fdog series (V): use QT to imitate QQ to realize login interface to main interface, function chapter.
猜你喜欢
High performance mysql (Third Edition) notes
MySQL date function
MySQL string function
Shell_ 02_ Text three swordsman
Activit fragmented deadly pit
MySQL digital function

The daemon thread starts redis and modifies the configuration file
Mongodb learning notes
Notes on how the network is connected
Activit零零碎碎要人命的坑
随机推荐
DS18B20数字温度计系统设计
吴军三部曲见识(四) 大家智慧
After idea installs the plug-in, restart the plug-in and disappear
Logical operation instruction
Fdog series (III): use Tencent cloud SMS interface to send SMS, write database, deploy to server, web finale.
我走過最迷的路,是字節跳動程序員的腦回路
IDEA断点调试技巧,多张动图包教包会。
Design of DS18B20 digital thermometer system
Shell_ 03_ environment variable
was unable to send heartbeat
Mongodb在node中的使用
MySQL日期函数
汇编语言段定义
Resume of a microservice architecture teacher with 10 years of work experience
8086 CPU 内部结构
Shell_ 05_ operator
The "advertising maniacs" in this group of programmers turned Tiktok advertisements into ar games
Koa Middleware
redux使用说明
README. txt