当前位置:网站首页>Reptile exercises (I)
Reptile exercises (I)
2022-07-04 13:00:00 【InfoQ】
import requests
word = input(" Please enter the search content ")
start = int(input(" Please enter the start page "))
end = int(input(" Please enter the end page "))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word} Of the {n} page .html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))

https://www.sogou.com/web?query=python&page=2&ie=utf8url = f'https://www.sogou.com/web?query={word}&page={n}'
https://www.sogou.com/web?query=Python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=12736&sst0=1650428312860&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428312860
https://www.sogou.com/web?query=java&_ast=1650428313&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=10734&sst0=1650428363389&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428363389
https://www.sogou.com/web?query=C%E8%AF%AD%E8%A8%80&_ast=1650428364&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=11662&sst0=1650428406805&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428406805
https://www.sogou.com/web?
https://www.sogou.com/web?query=Python&
https://www.sogou.com/web?query=Python&page=2&ie=utf8
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
'cookie' = "IPLOC=CN3600; SUID=191166B6364A910A00000000625F8708; SUV=1650427656976942; browerV=3; osV=1; ABTEST=0|1650428297|v17; SNUID=636A1DCD7B7EA775332A80CB7B347D43; sst0=663; [email protected]@@@@@@@@@; LSTMV=229,37; LCLKINT=1424"
'URl' = "https://www.sogou.com/web?query=Python&_ast=1650429998&_asf=www.sogou.com&w=01029901&cid=&s_from=result_up&sut=5547&sst0=1650430005573&lkt=0,0,0&sugsuv=1650427656976942&sugtime=1650430005573"
url="https://www.sogou.com/web?query={}&page={}:
" ":" ",
# Build the format of the dictionary ,',' Never forget
# headers It's a keyword. You can't write it wrong , If you make a mistake, you will have the following error reports
import requests
url = "https://www.bxwxorg.com/"
hearders = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, hearders=hearders)
print(response.content.decode("UTF-8"))
Traceback (most recent call last):
File "D:/pythonproject/ The second assignment .py", line 141, in <module>
response = requests.get(url, hearders=hearders)
File "D:\python37\lib\site-packages\requests\api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "D:\python37\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
TypeError: request() got an unexpected keyword argument 'hearders'
# reason : Three hearders Write consistently , however headers Is the key word , So the report type is wrong
# But it's written heades There will be another form of error reporting
import requests
word = input(" Please enter the search content ")
start = int(input(" Please enter the start page "))
end = int(input(" Please enter the end page "))
heades = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word} Of the {n} page .html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))
Traceback (most recent call last):
File "D:/pythonproject/ The second assignment .py", line 117, in <module>
response = requests.get(url, headers=headers)
NameError: name 'headers' is not defined
# reason : Three hearders Inconsistent writing , So the registration is wrong
# The correct way of writing is , You'd better not make a mistake !
import requests
url = "https://www.bxwxorg.com/"
headers = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, headers=headers)
print(response.content.decode("UTF-8"))
for n in range(start, end + 1):
边栏推荐
- 诸神黄昏时代的对比学习
- [leetcode] 96 and 95 (how to calculate all legal BST)
- 17. Memory partition and paging
- 从0到1建设智能灰度数据体系:以vivo游戏中心为例
- Runc hang causes the kubernetes node notready
- 敏捷开发/敏捷测试感受
- Master the use of auto analyze in data warehouse
- Transformer principle and code elaboration (pytorch)
- mysql三级分销代理关系存储
- Is there an elegant way to remove nulls while transforming a Collection using Guava?
猜你喜欢
C语言数组

《预训练周刊》第52期:屏蔽视觉预训练、目标导向对话

Read the BGP agreement in 6 minutes.

【云原生 | Kubernetes篇】深入了解Ingress(十二)
golang 设置goproxy代理的小细节,适用于go module下载超时,阿里云镜像go module下载超时
Detailed explanation of mt4api documentary and foreign exchange API documentary interfaces
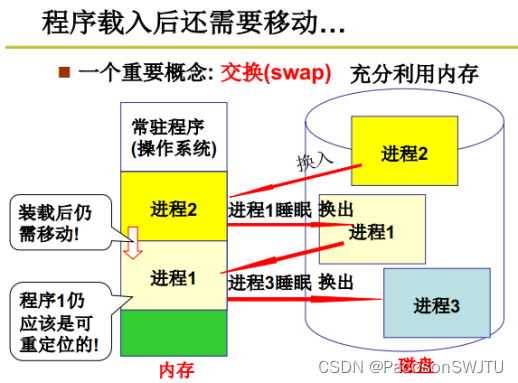
16. Memory usage and segmentation
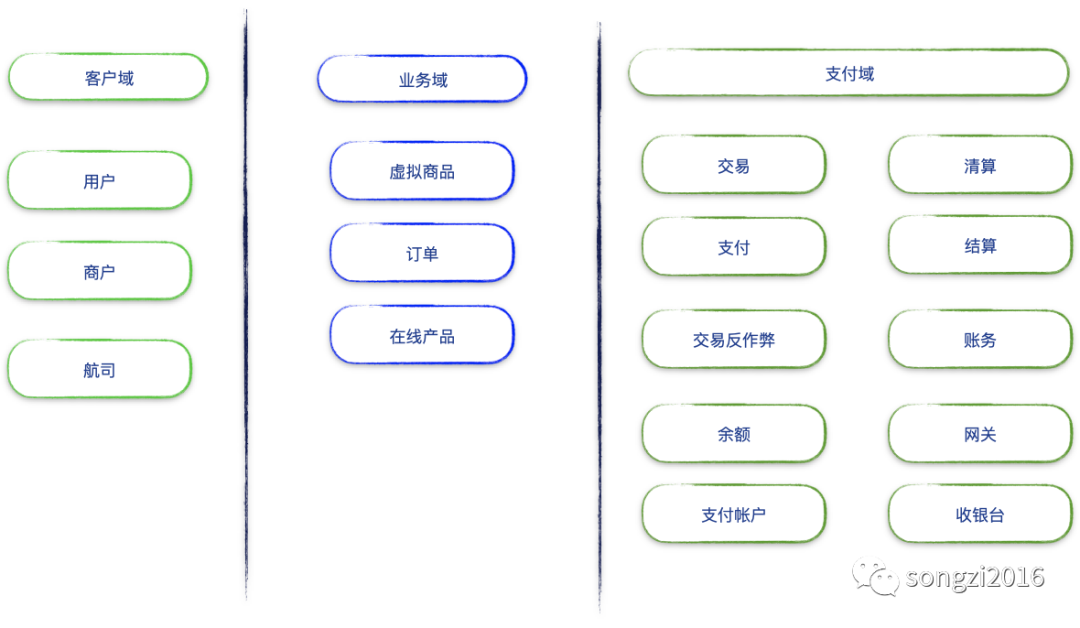
一个数据人对领域模型理解与深入
6 分钟看完 BGP 协议。
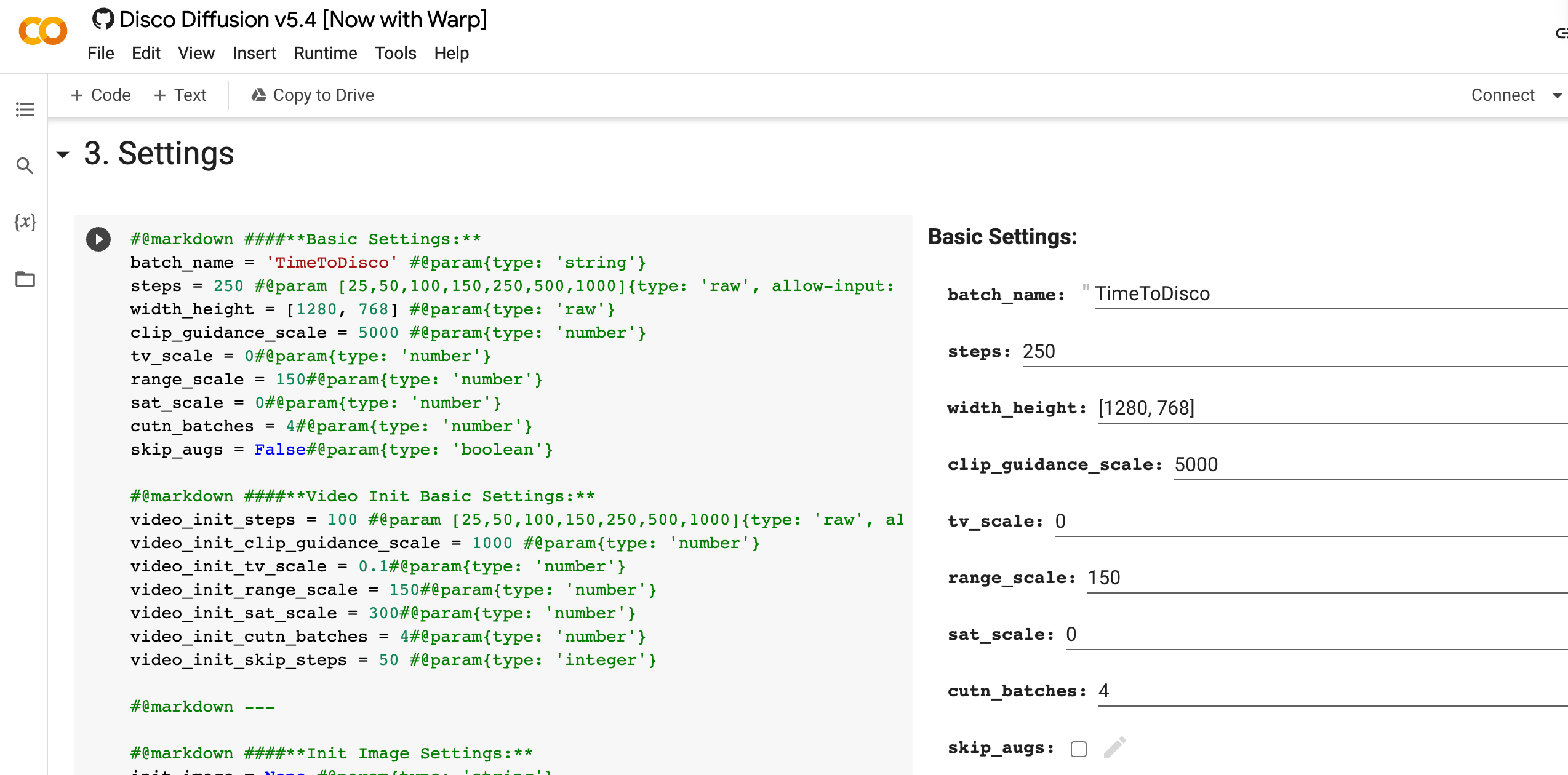
AI painting minimalist tutorial
随机推荐
再说rsync+inotify实现数据的实时备份
面试官:Redis 过期删除策略和内存淘汰策略有什么区别?
分布式事务相关概念与理论
求解:在oracle中如何用一条语句用delete删除两个表中jack的信息
游戏启动后提示安装HMS Core,点击取消,未再次提示安装HMS Core(初始化失败返回907135003)
Zhongang Mining: in order to ensure sufficient supply of fluorite, it is imperative to open source and save flow
【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
WPF双滑块控件以及强制捕获鼠标事件焦点
C language function
【Android Kotlin】lambda的返回语句和匿名函数
eclipse链接数据库中测试SQL语句删除出现SQL语句语法错误
实战:fabric 用户证书吊销操作流程
Full arrangement (medium difficulty)
[Android kotlin] lambda return statement and anonymous function
Valentine's Day confession code
「小技巧」给Seurat对象瘦瘦身
Vit (vision transformer) principle and code elaboration
6 分钟看完 BGP 协议。
DGraph: 大规模动态图数据集
Peak detection of measured signal