当前位置:网站首页>Semi supervised mixpatch
Semi supervised mixpatch
2022-07-02 07:40:00 【Xiao Chen who wants money】
Self consistent regularization : There was too little tag data before , When the generalization ability of supervised learning is poor , People generally expand training data , For example, random translation of images , The zoom , rotate , Distortion , shear , Change the brightness , saturation , Add noise, etc . Data augmentation can produce countless modified new images , Expand the training data set . The idea of self consistent regularization is , Data augmentation of unlabeled data , The new data generated is input into the classifier , The prediction results should be self consistent . That is, the sample generated by the same data expansion , The prediction results of the model should be consistent . This rule is added to the loss function , There are the following forms ,
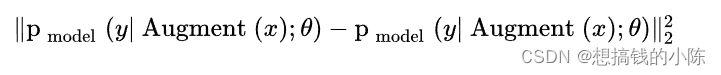
among x Is unmarked data ,Augment(x) Said to x Do random augmentation to generate new data , θ Is the model parameter ,y Is the result of the model prediction . Note that data augmentation is a random operation , Two Augment(x) The output is different . This L2 Loss item , Constrained machine learning model , All new images obtained by enlarging the same image , Make self consistent predictions .MixMatch Integrated self consistent regularization . Data augmentation uses random left-right flipping and clipping of images (Crop).
The second scheme is called Minimize entropy (Entropy Minimization)【5】. Many semi supervised learning methods are based on a consensus , That is, the classification boundary of the classifier should not pass through the high-density region of marginal distribution . The specific method is to force the classifier to make low entropy prediction for unlabeled data . The implementation method is to simply add a term to the loss function , To minimize the ![]() Corresponding entropy .
Corresponding entropy .
MixMatch Use "sharpening" function , Minimize the entropy of unlabeled data . This part will be introduced later .
The third scheme is called traditional regularization (Traditional Regularization). In order to make the generalization ability of the model better , The general practice is to do L2 Regularization ,SGD Next L2 Regularization is equivalent to Weight Decay.MixMaxtch Used Adam Optimizer , And an article found that Adam and L2 There will be problems when regularization is used at the same time , therefore MixMatch Use a separate Weight decay.
A recently invented data augmentation method is called Mixup 【6】, Randomly sample two samples from the training data , Construct mixed samples and mixed labels , As new augmented data ,
among lambda It's a 0 To 1 A positive number between , Represents the mixing ratio of two samples .MixMatch take Mixup It is used in both marked data and unlabeled data .
mixmatch Specific steps :
- Use MixMatch Algorithm , To a Batch Tag data for x And a Batch Unlabeled data for u Data expansion , Get one... Respectively Batch Augmented data x' and K individual Batch Of u'.
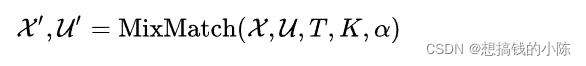
among T, K, It's a super parameter. , Later on .MixMatch The data augmentation algorithm is as follows ,

Algorithm description :for Loop to a Batch The marked pictures and unlabeled pictures of are expanded . To mark pictures , Only one augmentation , The label remains unchanged , Write it down as p . For unmarked data , do K Sub random augmentation ( Superparameters in the article K=2), Input classifier , Get the average classification probability , Application temperature Sharpen Algorithm (T It's a temperature parameter , This algorithm will be introduced later ), Get unlabeled data “ guess ” label . At this time, the expanded tag data There is one Batch, Expanded unlabeled data Yes K individual Batch. take and Mix it up , Randomly rearrange the data set . Final MixMatch The output of the augmentation algorithm , Yes, it will And Did MixUp() One of the Batch Tag data for , as well as And Did MixUp() Of K individual Batch Unmarked augmented data .
. For the expanded tag data x , And unmarked augmented data u Calculate the loss items separately ,




边栏推荐
- Get the uppercase initials of Chinese Pinyin in PHP
- 自然辩证辨析题整理
- Proof and understanding of pointnet principle
- 【信息检索导论】第一章 布尔检索
- 【信息检索导论】第七章搜索系统中的评分计算
- A slide with two tables will help you quickly understand the target detection
- ABM thesis translation
- 华为机试题-20190417
- 離線數倉和bi開發的實踐和思考
- ModuleNotFoundError: No module named ‘pytest‘
猜你喜欢

SSM garbage classification management system
Play online games with mame32k

How do vision transformer work?【论文解读】
使用百度网盘上传数据到服务器上
Mmdetection installation problem
【论文介绍】R-Drop: Regularized Dropout for Neural Networks

The first quickapp demo
![[introduction to information retrieval] Chapter 1 Boolean retrieval](/img/78/df4bcefd3307d7cdd25a9ee345f244.png)
[introduction to information retrieval] Chapter 1 Boolean retrieval
使用Matlab实现:Jacobi、Gauss-Seidel迭代

Deep learning classification Optimization Practice
随机推荐
PPT的技巧
Conda 创建,复制,分享虚拟环境
常见CNN网络创新点
SSM supermarket order management system
Win10+vs2017+denseflow compilation
iOD及Detectron2搭建过程问题记录
Sparksql data skew
allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
Record of problems in the construction process of IOD and detectron2
win10解决IE浏览器安装不上的问题
The difference and understanding between generative model and discriminant model
Transform the tree structure into array in PHP (flatten the tree structure and keep the sorting of upper and lower levels)
SSM garbage classification management system
程序的执行
【深度学习系列(八)】:Transoform原理及实战之原理篇
腾讯机试题
SSM laboratory equipment management
一份Slide两张表格带你快速了解目标检测
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
基于pytorch的YOLOv5单张图片检测实现