当前位置:网站首页>Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
2022-07-02 06:26:00 【chenf0】
loading annotations into memory...
Done (t=18.25s)
creating index...
index created!
number of images used for training: 31235
2022-06-05 03:17:10,191 maskrcnn_benchmark.trainer INFO: Start training
/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/structures/segmentation_mask.py:422: UserWarning: This overload of nonzero is deprecated:
nonzero()
Consider using one of the following signatures instead:
nonzero(*, bool as_tuple) (Triggered internally at /pytorch/torch/csrc/utils/python_arg_parser.cpp:766.)
item = item.nonzero()
/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [15,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [17,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "tools/train_first_step.py", line 232, in <module>
main()
File "tools/train_first_step.py", line 224, in main
model = train(cfg, args.local_rank, args.distributed)
File "tools/train_first_step.py", line 103, in train
arguments,
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/engine/trainer.py", line 70, in do_train
loss_dict,_,_,_,_ = model(images, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/apex-0.1-py3.7-linux-x86_64.egg/apex/amp/_initialize.py", line 197, in new_fwd
**applier(kwargs, input_caster))
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/detector/generalized_rcnn.py", line 67, in forward
x, result, detector_losses = self.roi_heads(features, proposals, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/roi_heads.py", line 27, in forward
x, detections, loss_box = self.box(features, proposals, targets)
File "/home/earhian/anaconda3/envs/maskrcnn/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/box_head/box_head.py", line 55, in forward
loss_classifier, loss_box_reg = self.loss_evaluator([class_logits], [box_regression])
File "/data3/cf/papercpde/maskrcnn-benchmark/maskrcnn_benchmark/modeling/roi_heads/box_head/loss.py", line 151, in __call__
sampled_pos_inds_subset = torch.nonzero(labels > 0).squeeze(1)
RuntimeError: copy_if failed to synchronize: cudaErrorAssert: device-side assert triggered

原因是我训练的数据集是70,coco一共80类
coco.py中写的很清楚,之前没看哈哈,当训练基础类别为70时,first 70 categories对应1 ~ 79。将num_classes改成81即可成功运行
# first 40 categories: 1 ~ 44; first 70 categories: 1 ~ 79; first 75 categories: 1 ~ 85
# second 40 categories: 45 ~ 91; second 10 categories: 80 ~ 91; second 5 categories: 86 ~ 91
# totally 80 categories
边栏推荐
- Open failed: enoent (no such file or directory) / (operation not permitted)
- 第一个快应用(quickapp)demo
- [introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table
- view的绘制机制(三)
- 华为机试题-20190417
- view的绘制机制(二)
- 读《敏捷整洁之道:回归本源》后感
- 解决万恶的open failed: ENOENT (No such file or directory)/(Operation not permitted)
- allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
- Play online games with mame32k
猜你喜欢
Cognitive science popularization of middle-aged people
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
Using MATLAB to realize: Jacobi, Gauss Seidel iteration

DNS attack details
PointNet理解(PointNet实现第4步)

Principle analysis of spark

SSM学生成绩信息管理系统

如何高效开发一款微信小程序

ORACLE EBS中消息队列fnd_msg_pub、fnd_message在PL/SQL中的应用
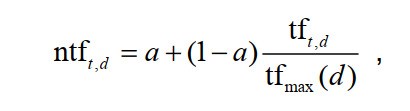
【信息检索导论】第六章 词项权重及向量空间模型
随机推荐
Explanation of suffix of Oracle EBS standard table
ssm人事管理系统
如何高效开发一款微信小程序
Three principles of architecture design
Yaml file of ingress controller 0.47.0
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
Point cloud data understanding (step 3 of pointnet Implementation)
SSM supermarket order management system
Jordan decomposition example of matrix
CSRF attack
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
Drawing mechanism of view (3)
MySQL has no collation factor of order by
第一个快应用(quickapp)demo
SSM garbage classification management system
Open failed: enoent (no such file or directory) / (operation not permitted)
【信息检索导论】第七章搜索系统中的评分计算
SSM laboratory equipment management
Error in running test pyspark in idea2020
SSM实验室设备管理