当前位置:网站首页>In depth understanding of the se module of the attention mechanism in CV
In depth understanding of the se module of the attention mechanism in CV
2022-07-08 02:18:00 【Strawberry sauce toast】
CV Medium Attention Mechanism summary ( One ):SE modular
Squeeze-and-Excitation Networks
Thesis link :Squeeze-and-Excitation Networks
1. Abstract
In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation”(SE) block,that adaptively recalibrates( Recalibrate )channel-wise feature responses by explicitly modelling interdependencies between channels.
SE The module belongs to the channel attention mechanism , It can adaptively learn the dependencies between different channels .
2. SE Detailed understanding of the module
Given in the original SE The module legend is as follows :
Combined with article 3 The contents of this section provide a detailed understanding of the following two issues :
- SE How modules learn about dependencies between different channels ?
- SE How does the module use the channel information to guide the model to carry out differentiated weighted learning of features ?
2.1 Multiple input and multiple output channels
chart 1 in ① Part describes the convolution layer of multiple input and multiple output channels .
Multiple input channels : Each channel of the input characteristic graph corresponds to a two-dimensional convolution kernel , The sum of convolution results of all input channels is the final convolution result , As shown in the figure below ( For simplicity , The deviation is omitted ):
In style , C C C It means the first one C C C Output channels , S S S It means the first one S S S Input channels .
Each input channel corresponds to a two-dimensional convolution kernel , therefore : Number of channels of three-dimensional convolution kernel = Enter the number of channels of the characteristic graph .
2.2 Multiple output channels
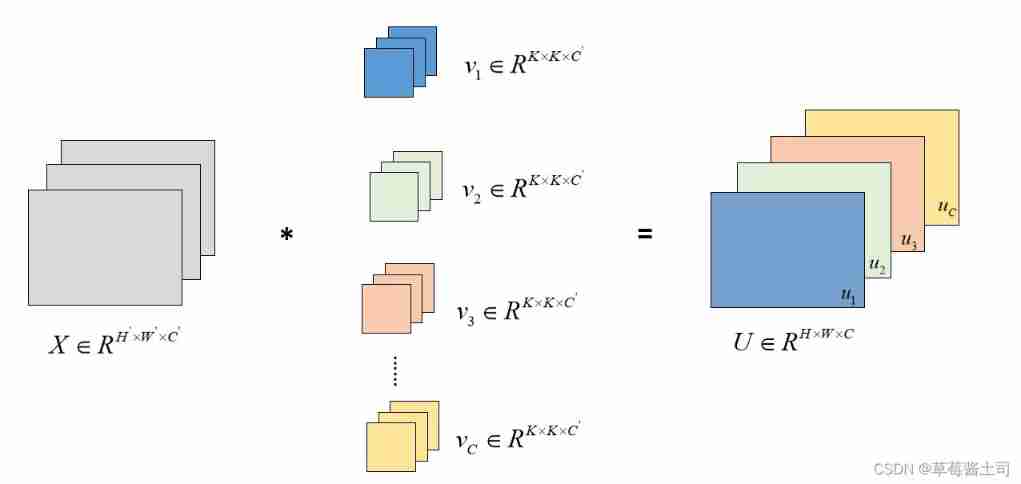
Each output channel corresponds to an independent three-dimensional convolution kernel , therefore , The number of channels to output the characteristic graph = Number of three-dimensional convolution kernels . Usually , The number of output channels is a super parameter .
According to the principle of multiple input and multiple output channels , It is not difficult for us to understand that in conventional convolution calculation , The correlation between different input channels is hidden in each output channel , And only “ Add up ” This simple way , Different output channels correspond to independent three-dimensional convolution kernels , therefore , The correlation between input channels is not reasonably utilized .
Therefore, the author of the paper proposes SE Module to explicitly utilize information between different input channels .
2.3 Squeeze-and-Excitation Block
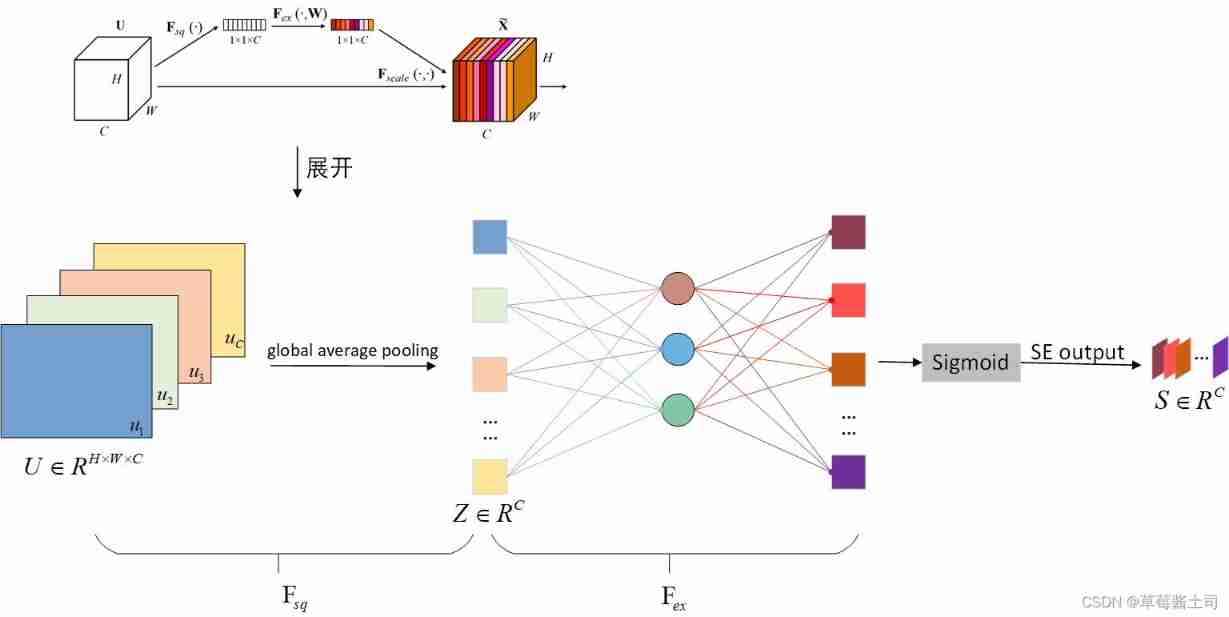
2.3.1 Squeeze: Global Information Embedding
The author adopts global average convergence (Global Average Pooling) Get the information of each channel .
z c = F s q ( u c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_c=\bold F_{sq}(\bold u_c)=\frac{1}{H\times W}\sum_{i=1}^{H} \sum_{j=1}^{W}u_c(i,j) zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
Why do you do this ? The original text explains :
Each of the learned filters operates with a local receptive field and consequently each unit of the transformation output U U U is unable to exploit contextual information outside of this region.
On a sheet of H × W H\times W H×W In the characteristic diagram of , Each element only corresponds to a local area in the input characteristic graph ( It's the receptive field ), Therefore, each element in the output feature graph contains only local information rather than global information .
To mitigate this problem, we propose to squeeze global spatial information into a channel descriptor. This is achieved by using global average pooling to generated chanel-wise statistics.
The author uses the global average convergence to get the overall situation features , The purpose is to fuse local information to get global information , The reason for adopting global average convergence is that it is simple to implement , Other more delicate but complex operations can also be used .
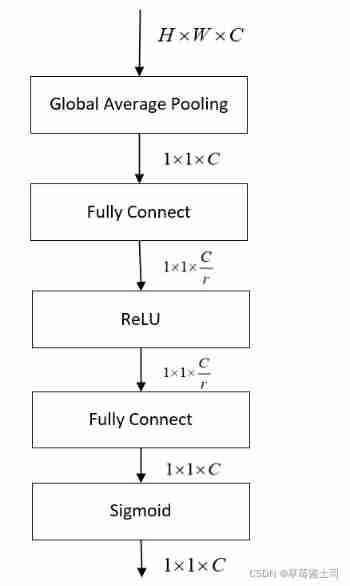
2.3.2 Excitation: Adaptive Recaloibration
Excitation( incentive ) The module is to better get the dependencies between various channels , Two requirements need to be met :
- It can learn the nonlinear relationship between various channels ;
- It can ensure that each channel has a corresponding output , obtain soft-label, instead of one-hot Type vector .
therefore , The author uses two full connection layers to learn nonlinear relations , Finally using sigmoid Activation function .
And in order to reduce model parameters and complexity , Adopted “bottleneck” Thought design full connection layer , Then a super parameter is generated : r r r, Wen Zhongling r = 16 r=16 r=16.
Turn off On by What Well send use s i g m o i d Letter Count Of thinking Examination ? \color{red}{ On why to use sigmoid Thinking about functions ?} Turn off On by What Well send use sigmoid Letter Count Of thinking Examination ?
sigmoid Is one of the common activation functions ,SE The final output of the module is equivalent to the weight of each channel learned , First of all, ensure that the weight cannot be 0, by 0 Instead, it will lose a lot of information , So it can't be used ReLU; in addition , The range you want here is [ 0 , 1 ] [0,1] [0,1] The weight of , Not to highlight a certain channel , Different from “ Multi category classification ” problem , More like “ Multi label classification ” problem , So I'm going to use softmax Function is not appropriate .
Excitation The module formula represents :
s = F e x ( x , W ) = σ ( g ( z , W ) ) = σ ( W 2 δ ( W 1 z ) ) s=\bold F_{ex}(\bold x, \bold W)=\sigma(g(\bold z,\bold W))=\sigma(\bold W_2\delta(W_1 \bold z)) s=Fex(x,W)=σ(g(z,W))=σ(W2δ(W1z))
In style , δ ( ∙ ) \delta(\bullet) δ(∙) Express ReLU Activation function , σ ( ∙ ) \sigma(\bullet) σ(∙) Express sigmoid Activation function .
2.3.3 weighting
The final will be SE The output of the module acts on the output of the convolution layer , Get the output characteristic diagram of channel attention weighting .
Use what you get channel-wise vector , Each element of the characteristic graph of each channel is weighted ( Understand the formula (4) Then there is the product of scalar and matrix ).
3. SE Use of modules

3、 ... and 、PyTorch Realization SE modular
3.1 Use the full connection layer to realize Excitation
class SE(nn.Module):
def __init__(self, channels, reduction=16): # I think so 16, If the number of feature map channels is small , It can be adjusted properly
super(SE, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.excitation = nn.Sequential(
nn.Linear(channels, channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels, bias=False),
nn.Sigmoid())
def forward(self, x):
b, c, _, _ = x.size()
y = self.squeeze(x).view(b, c)
y = self.excitation(y).view(b, c, 1, 1)
return x * y.expand_as(x)
3.2 Use 1 × 1 1\times 1 1×1 Convolution realization Excitation
Use 1 × 1 1\times 1 1×1 Convolution instead of full connection layer , Avoid dimensional transformations between matrices and vectors
class SE(nn.Module):
def __init__(self, channels, reduction=2):
super(SE, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.excitation = nn.Sequential(
nn.Conv2d(channels, channels // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channels // reduction, channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.Sigmoid())
def forward(self, x):
b, c, _, _ = x.size()
y = self.squeeze(x)
print(y.shape)
y = self.excitation(y)
print(y.shape)
return x * y
边栏推荐
- Towards an endless language learning framework
- LeetCode精选200道--链表篇
- If time is a river
- Popular science | what is soul binding token SBT? What is the value?
- 常见的磁盘格式以及它们之间的区别
- Clickhouse principle analysis and application practice "reading notes (8)
- The way fish and shrimp go
- JVM memory and garbage collection-3-direct memory
- 直接加比较合适
- 谈谈 SAP iRPA Studio 创建的本地项目的云端部署问题
猜你喜欢

leetcode 865. Smallest Subtree with all the Deepest Nodes | 865.具有所有最深节点的最小子树(树的BFS,parent反向索引map)
![[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview](/img/45/5f14454267318bb404732c2df5e03c.jpg)
[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview
JVM memory and garbage collection-3-direct memory

leetcode 869. Reordered Power of 2 | 869. Reorder to a power of 2 (state compression)
adb工具介绍

Little knowledge about TXE and TC flag bits

JVM memory and garbage collection-3-runtime data area / method area

XXL job of distributed timed tasks
关于TXE和TC标志位的小知识

"Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.2 data preprocessing_ Learning thinking and exercise answers
随机推荐
喜欢测特曼的阿洛
leetcode 873. Length of Longest Fibonacci Subsequence | 873. 最长的斐波那契子序列的长度
Key points of data link layer and network layer protocol
The bank needs to build the middle office capability of the intelligent customer service module to drive the upgrade of the whole scene intelligent customer service
Semantic segmentation | learning record (3) FCN
力争做到国内赛事应办尽办,国家体育总局明确安全有序恢复线下体育赛事
牛熊周期与加密的未来如何演变?看看红杉资本怎么说
力扣4_412. Fizz Buzz
文盘Rust -- 给程序加个日志
Cross modal semantic association alignment retrieval - image text matching
#797div3 A---C
阿锅鱼的大度
Random walk reasoning and learning in large-scale knowledge base
《通信软件开发与应用》课程结业报告
Many friends don't know the underlying principle of ORM framework very well. No, glacier will take you 10 minutes to hand roll a minimalist ORM framework (collect it quickly)
C language -cmake cmakelists Txt tutorial
Neural network and deep learning-5-perceptron-pytorch
实现前缀树
Coreldraw2022 download and install computer system requirements technical specifications
Semantic segmentation | learning record (5) FCN network structure officially implemented by pytoch