当前位置:网站首页>Convolutional Neural Network (CNN) mnist Digit Recognition - Tensorflow
Convolutional Neural Network (CNN) mnist Digit Recognition - Tensorflow
2022-08-01 20:07:00 【Jane Says Python】
大家好,我是老表~最近参与了 K同学啊 举行的 深度学习训练营,第一周任务:卷积神经网络(CNN)mnist数字识别,Here I share my own learning and implementation process,and summarizing reflections on the part of your doubts,希望对大家有所帮助.
使用环境:
- K80显卡
- Tensorflow 2.8
- opencv 4.6
I knew very little about deep learning before,So the goal I set for myself is:
- 跑通代码
- understand the code as much as possible
- Can use the trained model to predict their written words
导入相关包
# 导入包
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
设置GPU
# 设置 gpu
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
加载数据
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# can also be loaded locally
# (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data(path='/mnt/mnist.npz')
# 查看数据规模
train_images.shape, test_images.shape, train_labels.shape, test_labels.shape
输出:
((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
- 查看数据:
# To see the data
train_images[0][10]
输出:
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 14, 1, 154, 253,
90, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=uint8)
数据归一化
看了个b站upMaster's Video Introduction,It feels very clear,What I understand is that data normalization avoids a single feature having a big impact on the final result.
There are two ways to normalize:线性函数归一化(maximization)和零均值归一化(标准化).

线性函数归一化(maximization)It is suitable for the situation with obvious edge,For example, the pixel in this case(0-255),人的身高等.
零均值归一化(标准化)Suitable for data with outliers and more noise.
# 数据归一化
# What is data normalization?作用?
# Normalize the value of the pixel to0到1的区间内
train_images, test_images = train_images / 255.0, test_images / 255.0
# max:255 min:0
# 归一化公式 (x-min)/(max-min)
- View normalized data
# View normalized data
train_images[0][10]
输出:
array([0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.05490196,
0.00392157, 0.60392157, 0.99215686, 0.35294118, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. ])
查看训练集数据
plt.figure(figsize=(20,10))
for i in range(20):
plt.subplot(5,10,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# cmap 参数作用?Set the image gradient
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(train_labels[i])
plt.show()

调整数据 shape
# Adjust the data to the format we need
# Why adjust data?
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
输出:
((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
- To check the adjusted data
# To check the adjusted data
train_images[0][10]
输出:
array([[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0.05490196],
[0.00392157],
[0.60392157],
[0.99215686],
[0.35294118],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0. ]])
构建CNN网络
# 构建CNN网络模型
# every step?什么是cnn?
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
model.summary()

编译模型
# 编译模型
# optimizer loss metrics 含义和作用?
model.compile(optimizer ='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
训练模型
# 训练模型
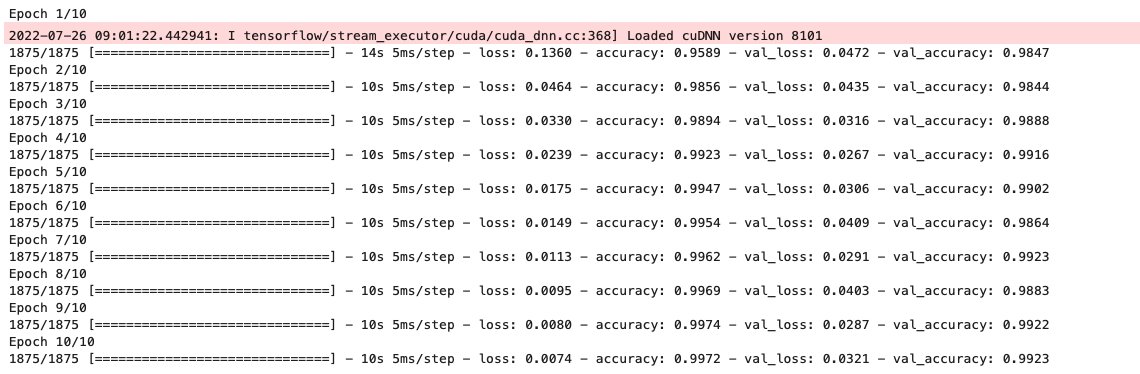
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
预测
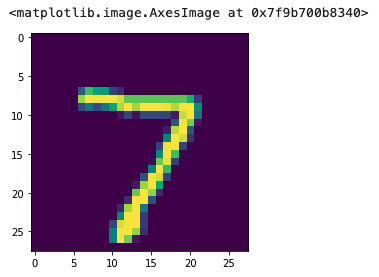
# Read a random image from the test set,并显示
plt.imshow(test_images[0])
- 预测测试集数据
# 使用训练好的 model 进行预测
pre = model.predict(test_images)
# 查看预测结果
pre[0]
输出:
array([-16.13687 , -1.1026648, -3.5199716, -4.108456 , -2.1431744,
-11.160188 , -12.815703 , 17.407137 , -13.253326 , -1.5100265],
dtype=float32)
这里返回的是一个 array 数组,The value of each element corresponds to the number on the predicted picture is0-9的“概率”(and the element subscript exactly corresponds to the upper),如上 数组最大值是17.407137,The corresponding subscript of the element is7,So according to the prediction result, the maximum number on the picture is predicted to be7.
- Write a function to convert predictions to numbers
# Write a function to convert predictions to numbers
import numpy as np
def get_pre_data(pre_array):
return np.argmax(pre_array, axis=0)
调用函数:
get_pre_data(pre[0])
# 输出:7
- Encapsulate the prediction function Predict a single image in the test set
通过前面,我们不难看出,model.predict(test_images)is to predict all the test set images at once,In reality, we definitely want to predict one by one.,If violence changes the parameter totest_images[0]You will encounter the following error.
ValueError: Exception encountered when calling layer "conv2d" (type Conv2D).
Negative dimension size caused by subtracting 3 from 1 for '{
{node sequential/conv2d/Conv2D}} = Conv2D[T=DT_FLOAT, data_format="NHWC", dilations=[1, 1, 1, 1], explicit_paddings=[], padding="VALID", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true](sequential/ExpandDims, sequential/conv2d/Conv2D/ReadVariableOp)' with input shapes: [?,28,1,1], [3,3,1,32].
Call arguments received:
• inputs=tf.Tensor(shape=(None, 28, 1, 1), dtype=float32)
大概意思是在conv2d中图像 shape 出现了问题,The reason is because the data passed into the modelshape应该为x, 28, 28, 1,而test_images[0]的 shape 是 28, 28, 1,知道原因,改起来就简单了,具体代码如下.
# Encapsulate the prediction function Predict a single image in the test set
def pre_image(image):
# 传入 image shape 是 (28, 28, 1) needs to be transformed into (1, 28, 28, 1)
image = image.reshape((1, 28, 28, 1))
# 使用训练好的 model 进行预测 returns a two-digit
pre_array = model.predict(image)[0]
# 获取预测结果
return get_pre_data(pre_array)
调用函数:
pre_image(test_images[0])
# 输出:7
- Predict the words we write ourselves
First you need to save the model.
# 模型保存
model.save('/mnt/tf_data/mnist_model.h5')
Then write a number by yourself(Write a number on toilet paper2):
Then write a model prediction function,大概步骤就是:加载模型-读取图片-图片处理-预测.
Here we should pay special attention to the following two points:
- We do before the training data normalization,Then the predicted data must also be normalized accordingly.
- When reading data, you need to specify cv2.IMREAD_GRAYSCALE,Otherwise, the default reading is three channels(Data processing is troublesome)
代码如下:
# To predict their written words
import tensorflow as tf
import cv2
def pre_image(image_path, model):
# 读取本地图片
# Reading pictures in grayscale,默认是三通道(Data processing is troublesome)
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# print('图片大小', img.shape)
# 转变成 28,28
img = cv2.resize(img,(28,28))
# print('图片大小', img.shape)
# 显示图片
plt.imshow(img)
# 数据归一化 (How to normalize the model before, how to normalize now)
img = img/255
# 将图片 shape 改成 (1,28,28,1) Also data type last and training set/测试集一样
img = img.reshape((1,28,28,1)).astype('float64')
# 使用训练好的 model 进行预测 returns a two-digit
pre_array = model.predict(img)[0]
# 获取预测结果
return get_pre_data(pre_array)
# 加载模型
model = tf.keras.models.load_model('/mnt/tf_data/mnist_model.h5')
image_path = '/mnt/tf_data/2.jpeg'
# 预测
print('预测结果:', pre_image(image_path, model))

总结
The project ran smoothly,And solved some of my doubts by consulting the information,Finally, I also use the model I trained myself,Predicted the value written by yourself,感觉很棒.
However, there are still many problems unresolved,比如:Understand the specific role of normalization?How to affect the convergence efficiency of gradient descent when solving?Why should the data be transformed into(60000, 28, 28, 1)?CNNHow the network model works?what does the compiled model do?等.
I will find time to continue my study later,Looking forward to learning more with you.
参考
卷积神经网络(CNN)mnistNumber Recognition Tutorial https://mtyjkh.blog.csdn.net/article/details/116920825
Why do you need to normalize numeric features?? https://b23.tv/RnN2VoQ
Why do we need to normalize data in machine learning?? https://cloud.tencent.com/developer/article/1456997
边栏推荐
- "No title"
- 给定中序遍历和另外一种遍历方法确定一棵二叉树
- 【kali-信息收集】(1.6)服务的指纹识别:Nmap、Amap
- Creo5.0草绘如何绘制正六边形
- Application of Acrel-5010 online monitoring system for key energy consumption unit energy consumption in Hunan Sanli Group
- WhatsApp群发实战分享——WhatsApp Business API账号
- 油猴hook小脚本
- 智能硬件开发怎么做?机智云全套自助式开发工具助力高效开发
- 模板特例化和常用用法
- 使用Huggingface在矩池云快速加载预训练模型和数据集
猜你喜欢
【torch】张量乘法:matmul,einsum

Pytorch模型训练实用教程学习笔记:三、损失函数汇总
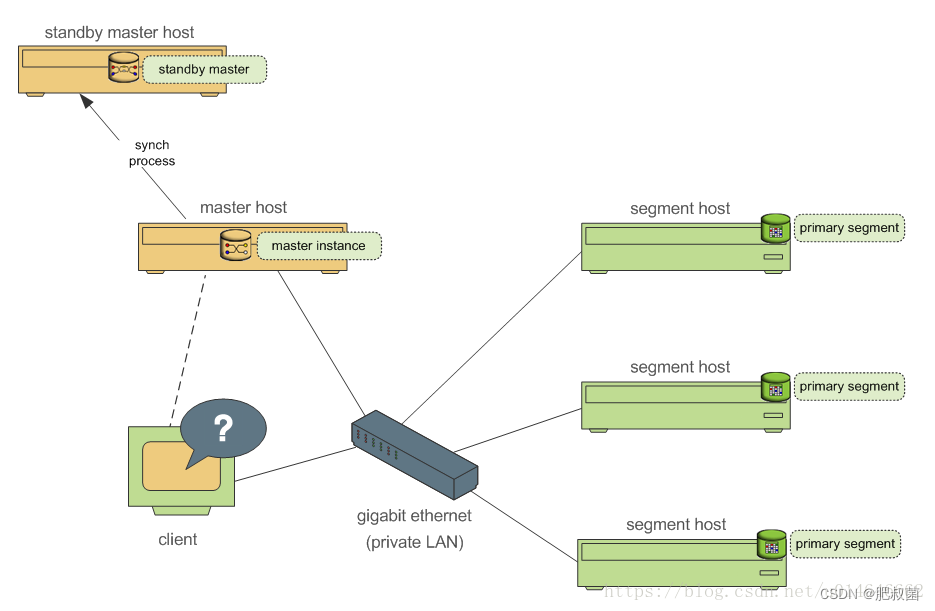
Greenplum数据库源码分析——Standby Master操作工具分析
![[Multi-task optimization] DWA, DTP, Gradnorm (CVPR 2019, ECCV 2018, ICML 2018)](/img/a1/ec038eeb6c98c871eb31d92569533d.png)
[Multi-task optimization] DWA, DTP, Gradnorm (CVPR 2019, ECCV 2018, ICML 2018)

Intranet penetration lanproxy deployment

【kali-信息收集】(1.3)探测网络范围:DMitry(域名查询工具)、Scapy(跟踪路由工具)
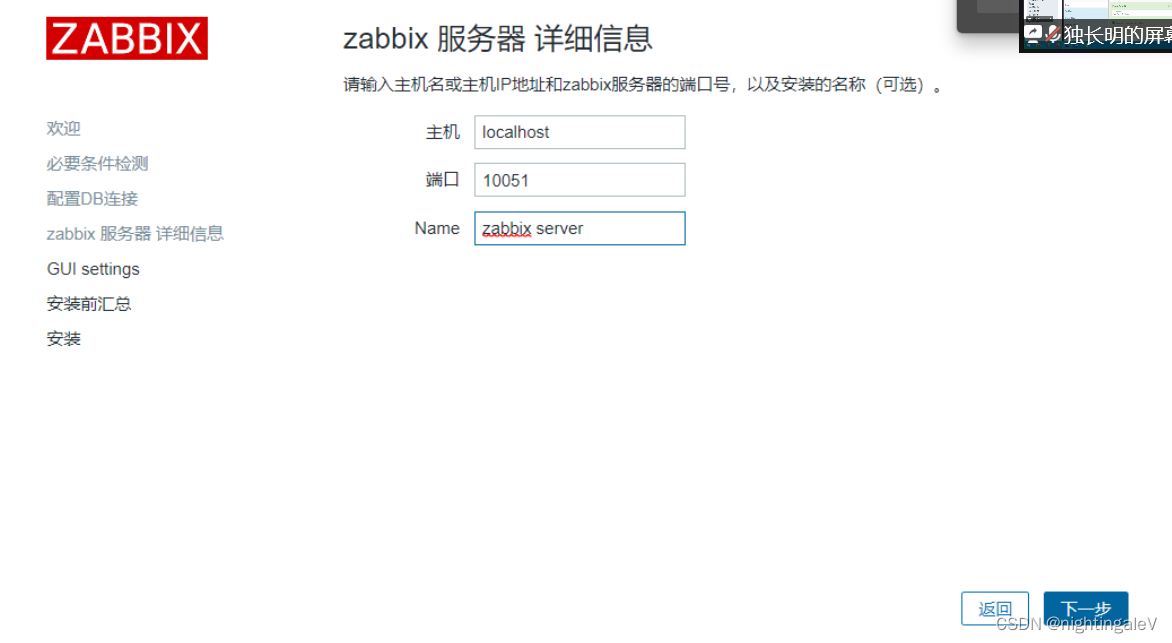
deploy zabbix

研究生新同学,牛人看英文文献的经验,值得你收藏
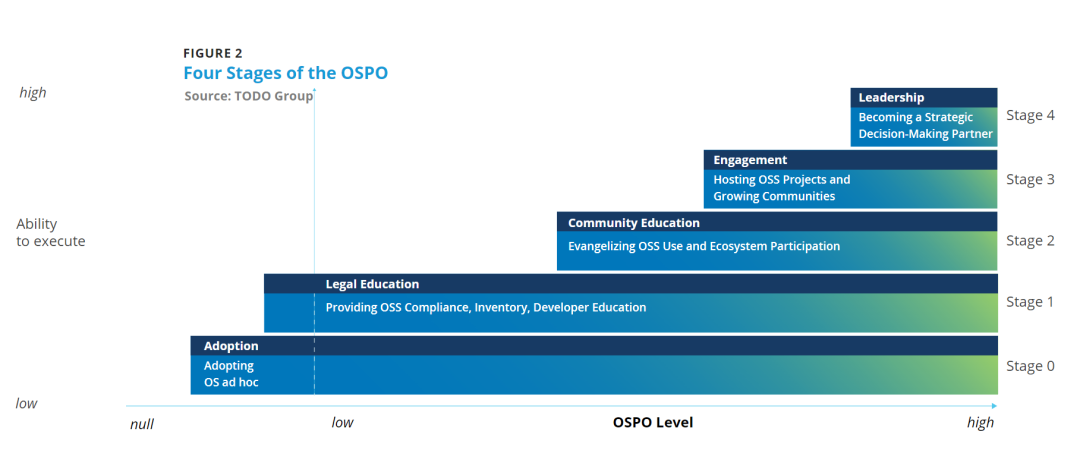
OSPO 五阶段成熟度模型解析
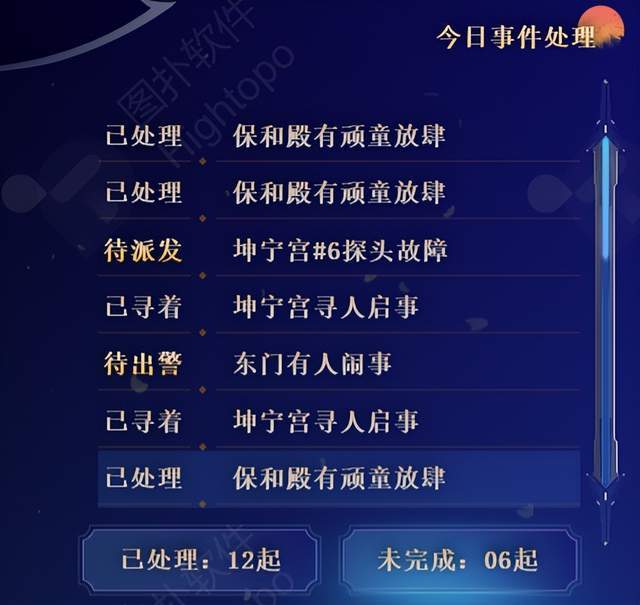
数字孪生北京故宫,元宇宙推进旅游业进程
随机推荐
Arthas 常用命令
【节能学院】安科瑞餐饮油烟监测云平台助力大气污染攻坚战
Creo5.0 rough hexagon is how to draw
Determine a binary tree given inorder traversal and another traversal method
瀚高数据导入
我的驾照考试笔记(3)
第58章 结构、纪录与类
数字孪生北京故宫,元宇宙推进旅游业进程
30天刷题计划(五)
第57章 业务逻辑之业务实体与数据库表的映射规则定义
使用微信公众号给指定微信用户发送信息
锐捷交换机基础配置
解除360对默认浏览器的检测与修改
【社媒营销】如何知道自己的WhatsApp是否被屏蔽了?
myid file is missing
Addition, Subtraction, Multiplication of Large Integers, Multiplication and Division of Large Integers and Ordinary Integers
【kali-信息收集】(1.2)SNMP枚举:Snmpwalk、Snmpcheck;SMTP枚举:smtp-user-enum
】 【 nn. The Parameter () to generate and why do you want to initialize
【nn.Parameter()】生成和为什么要初始化
58: Chapter 5: Develop admin management services: 11: Develop [admin face login, interface]; (not measured) (using Ali AI face recognition) (demonstrated, using RestTemplate to implement interface cal