当前位置:网站首页>[CV-Learning] Linear Classifier (SVM Basics)
[CV-Learning] Linear Classifier (SVM Basics)
2022-08-04 06:14:00 【Xiao Liang has to work hard】
数据集介绍(本文所用)
CIFAR10数据集
包含5w张训练样本、1w张测试样本,分为飞机、汽车、鸟、猫、鹿、狗、蛙、马、船、Ten categories of trucks,Images are color images,其大小为32*32.
图像类型(像素表示)
二进制(0/1)
灰度图像
A pixel consists of a bit(Byte)表示,取值为0-255.
degree of color:黑(0)---->----->---->白(255)彩色图像
One image has red、绿、Three depths of blue,即三个通道.One pixel per channel is made up of one bit(Byte)表示,取值为0-255.The three depth images are combined to represent a color image.比如:The pixels of the image are 500500,则需要500500*3can be represented by a matrix.
degree of color:黑(0)---->----->---->红(255)Ps:Most classification algorithms require an input vector,Convert an image matrix to a vector.

Therefore, each image of the dataset used in this article is converted into a vector3072(32323)维列向量.
线性分类器
定义:线性分类器是一种线性映射,Map the input image features as 类别分数.
特点:形式简单,易于理解
拓展:通过层级结构(神经网络)或者高维映射(支撑向量机)可以形成功能强大的非线性模型.in the case of small samples,Commonly used support vector machines;in the case of large samples,常用神经网络.
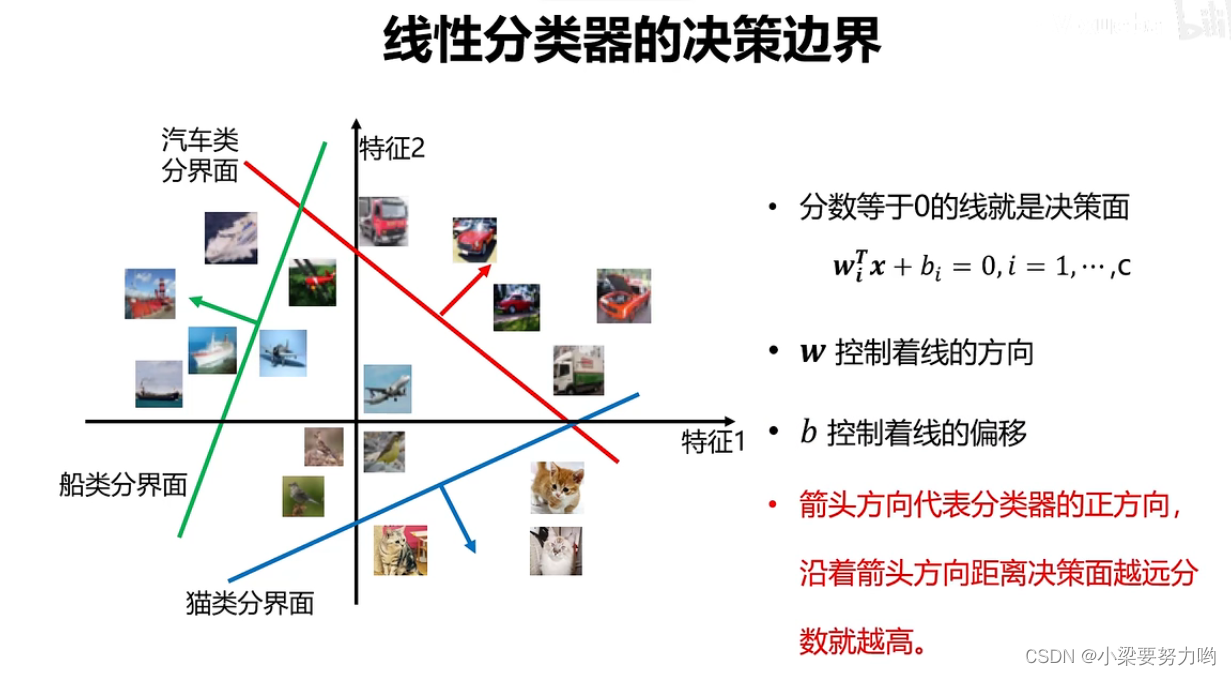
Decisions of Linear Classifiers
决策规则:
决策步骤:
- Images are represented as vectors
- 计算当前图片每个类别的分数
- Determine the current image by category score
Matrix representation of the classifier:
Weight vector for the linear classifier

Decision boundary for a linear classifier
损失函数
To find the optimal classification model,Also need the help of loss function and optimization algorithm.The loss function builds the model performance and model parameters(W,b)之间的桥梁,指导模型参数优化.
损失函数定义
损失函数是一个函数,用于度量给定分类器的预测值与真实值的不一致程度,其输出通常是一个非负实值.
其输出的非负实值可以作为反馈信号来对分类器参数进行调整,以降低当前示例对应的损失值,提升分类器的分类效果.
The loss value is a description of the model's performance.
多类支撑向量机损失
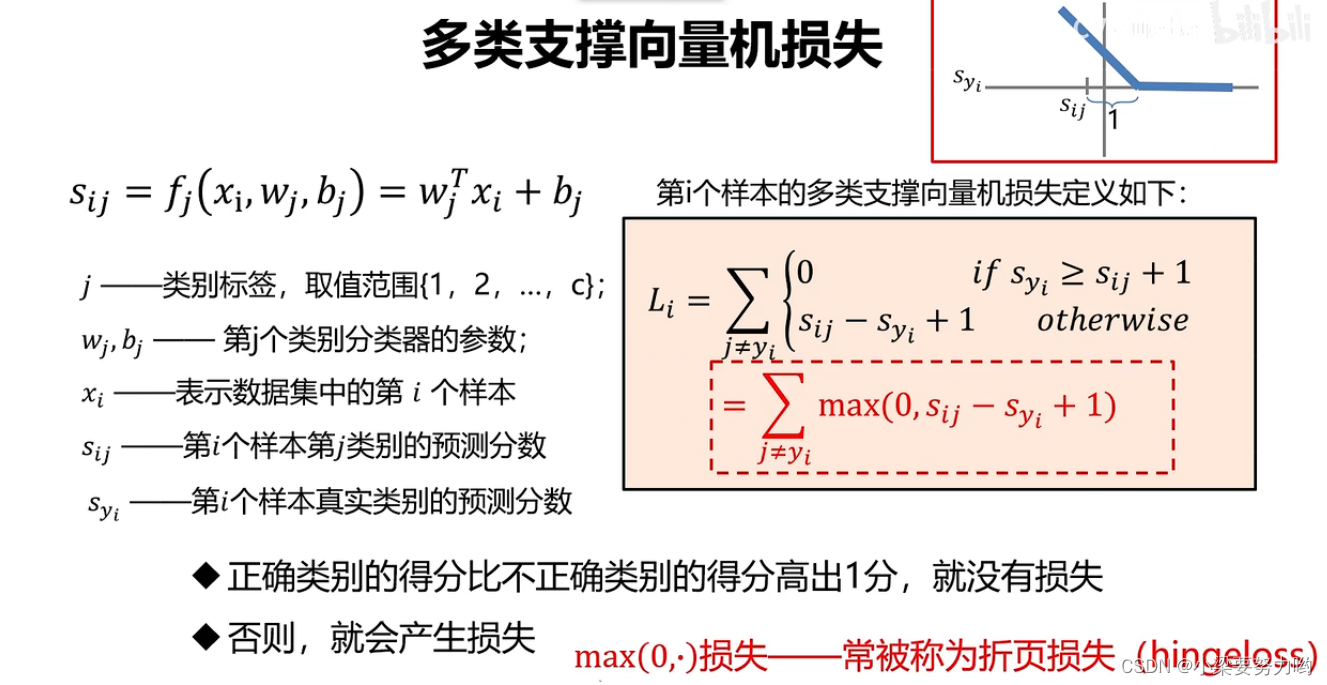

Ps:限制条件中**+1**It is to reduce the influence of noise near the boundary
L函数举例说明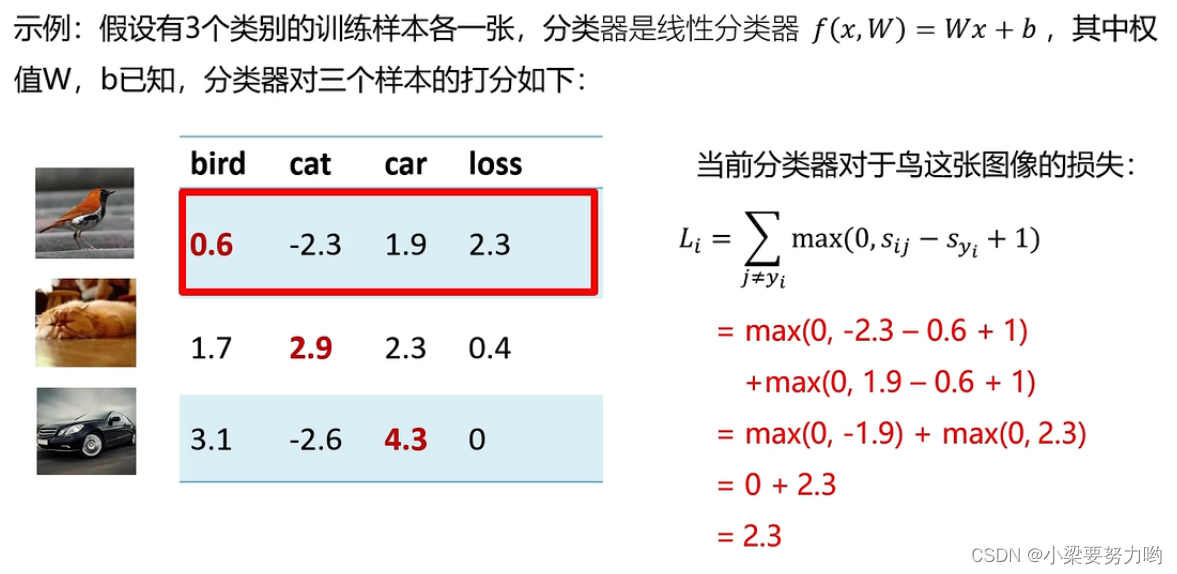
计算出多个LThen ask for an average value!
问题解答
- 多类支撑向量机损失Li的最大/What will be the minimum value?
答:The maximum value is infinite,最小值为0 - 如果初始化时w和b很小,损失L是多少?
答:此时,Sij和Syiare small andSij-Syi约为0.Li和Lequal to the sample size minus one.This situation can be used to check the correctness of the algorithm. - Consider all categories(包括j=yi), 损失L,Whether it affects the selection of optimal parameters?
答:无影响. - in total lossL计算时,If the sum is used instead of the average,Whether it affects the selection of optimal parameters?
答:无影响. - 假设存在一个W使损失函数L=0,这个W是唯一的吗?
答:不唯一.
正则项与超参数
What is regular term loss
Prevent the model from learning too well on the training set(过拟合),可以在Lplus a regularization loss,The regular term gives the model a preference,Can be used in multiple loss functions0The optimal model parameters are selected from the model parameters,所以损失函数L可以唯一.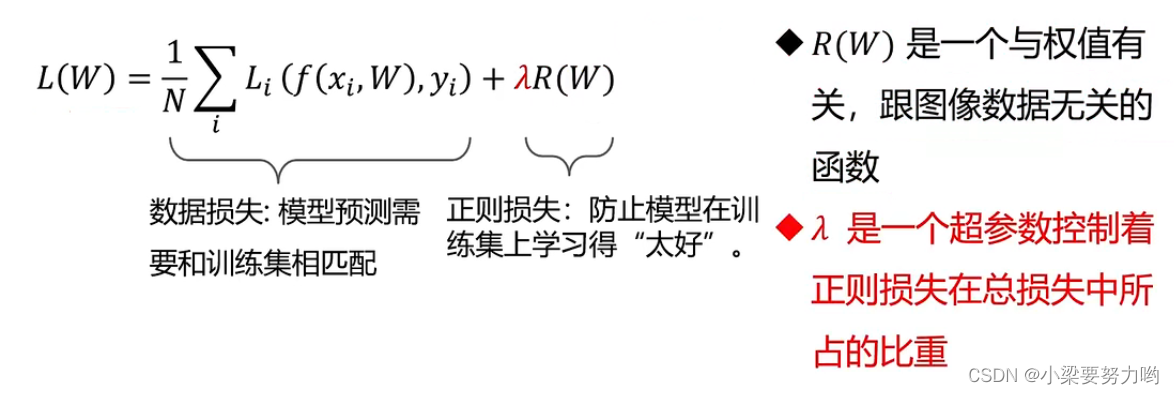
L2正则项

什么是超参数
在before starting the learning process设置值的参数,rather than learning.
Hyperparameters generally have a significant impact on model performance.
Commonly used regular term losses

优化算法
利用The output value of the loss functionAs a feedback signal to adjust the classifier parameters,以提升分类器对训练样本的预测性能.The optimization goal is to find the loss function that makes it soL达到最优的那组参数W.
梯度下降算法
A simple and efficient iterative optimization algorithm.
- 数值法
计算量大,得到近似值,不准确.
- 解析法
精确值,速度快,But derivative derivation is error-prone.
问:What does a numerical gradient do?
求梯度时一般使用解析梯度,而数值梯度主要用于解析梯度的正确性校验(梯度检查).
计算效率
- 梯度下降

当N很大时,Each calculation of the weight gradient is very computationally expensive,耗时长,效率低下. - 随机梯度下降

单个样本的训练可能会带来很多噪声,Although not every iteration is in the direction of the overall optimum,However, a large number of iterations to reflect the law will make the whole go in the optimal direction. - 小批量梯度下降
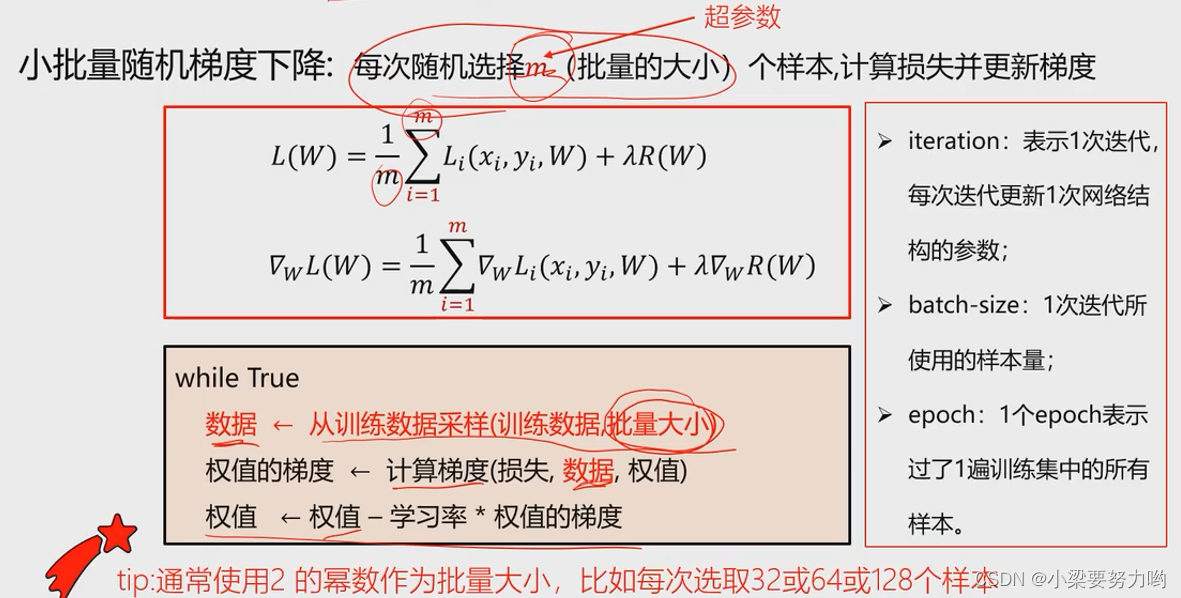
在论文中,一般用epochDescribe the iterative sample situation.
1个epoch需要N/m次迭代,N是样本总数,m是批量大小.
训练过程
数据集划分
数据集=训练集+验证集+测试集
训练集:The learning of the classifier parameters when used for the given hyperparameters.
验证集:Used to select hyperparameters.
测试集:评估泛化能力.
问:when data is scarce,Then the possible validation set contains very few samples,Thus, the data cannot be represented in a statistical sense.At this point we can come up with a method that uses cross-validation.
K折交叉验证
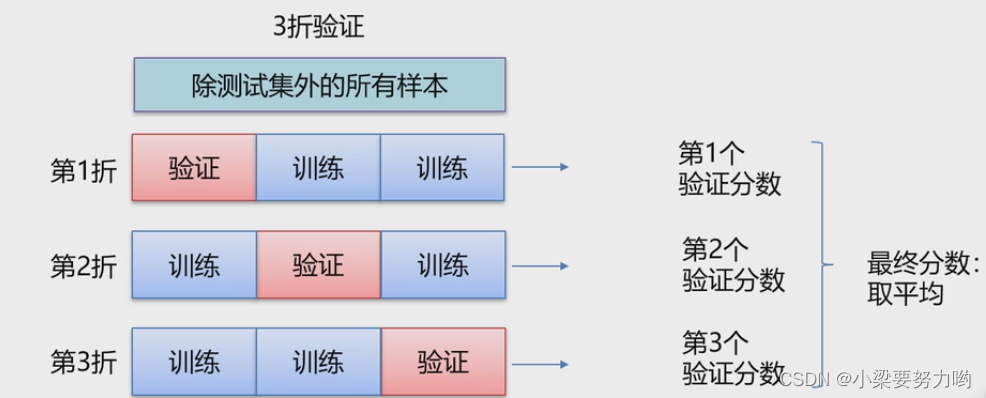
To make randomness better,We can shuffle the data at each split,This results in a better final average score,这种方法叫做带有打乱数据的重复K折验证.
数据预处理
- 去均值
x=x-均值;The floating range of the data can be reduced,Highlight relative differences. - 归一化
x=(x-均值)/方差;去除量纲的影响.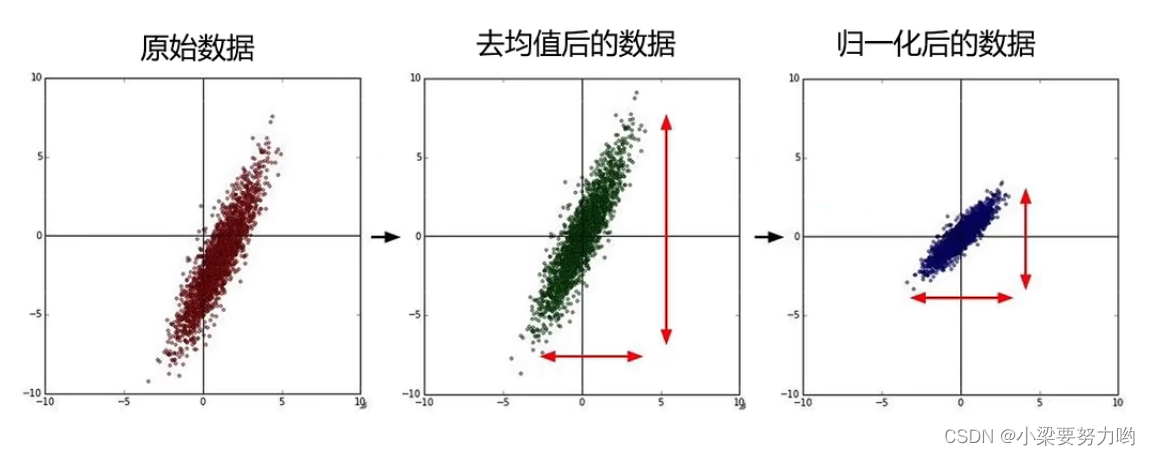
- 去相关性
Sometimes it's just a separate discussionxOr just discuss it separatelyy,就需要去掉x,y的相关性,x变化,y不会随着变化;Make the data independent,达到降维的效果. - 白化
The normalization operation is performed on the basis of decorrelation.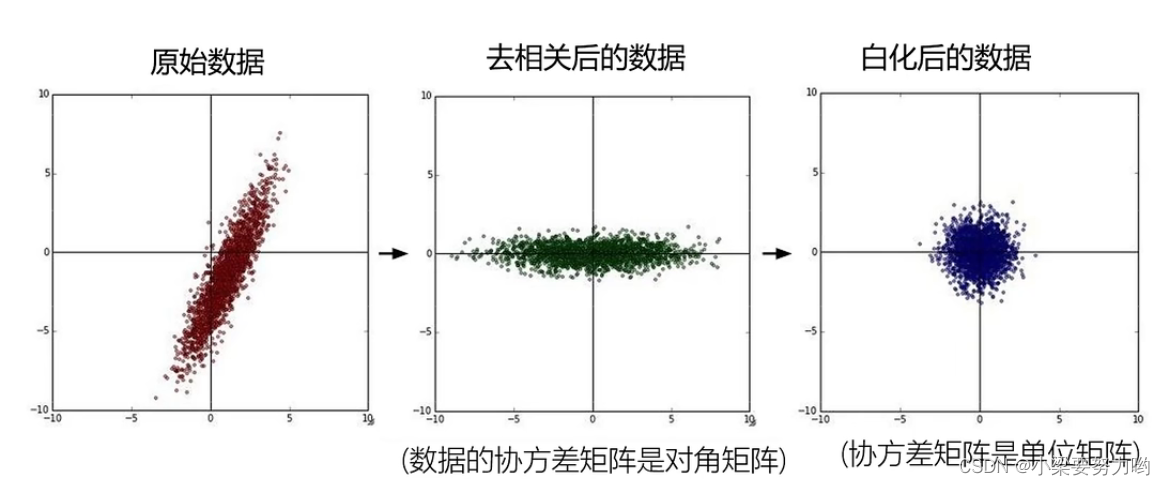
北京邮电大学–鲁鹏–计算机视觉与深度学习
边栏推荐
- 【CV-Learning】卷积神经网络
- Matplotlib中的fill_between;np.argsort()函数
- 【go语言入门笔记】12、指针
- 计算某像素点法线
- [CV-Learning] Convolutional Neural Network Preliminary Knowledge
- Usage of RecyclerView
- 安装dlib踩坑记录,报错:WARNING: pip is configured with locations that require TLS/SSL
- 【论文阅读】Exploring Spatial Significance via Hybrid Pyramidal Graph Network for Vehicle Re-identificatio
- thymeleaf中 th:href使用笔记
- 字典特征提取,文本特征提取。
猜你喜欢
![[Go language entry notes] 13. Structure (struct)](/img/0e/44601d02a1c47726d26f0ae5085cc9.png)
[Go language entry notes] 13. Structure (struct)
![[Deep Learning 21 Days Learning Challenge] Memo: What does our neural network model look like? - detailed explanation of model.summary()](/img/99/819ccbfed599ffd52307235309cdc9.png)
[Deep Learning 21 Days Learning Challenge] Memo: What does our neural network model look like? - detailed explanation of model.summary()
语音驱动嘴型与面部动画生成的现状和趋势
线性回归02---波士顿房价预测

【论文阅读】Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
PyTorch
剪映专业版字幕导出随笔
fuser 使用—— YOLOV5内存溢出——kill nvidai-smi 无pid 的 GPU 进程

target has libraries with conflicting names: libcrypto.a and libssl.a.

tensorRT5.15 使用中的注意点
随机推荐
Lee‘s way of Deep Learning 深度学习笔记
中国联通、欧莱雅和钉钉都在争相打造的秘密武器?虚拟IP未来还有怎样的可能
2020-10-29
读研碎碎念
Endnote编辑参考文献
动手学深度学习_线性回归
动手学深度学习_softmax回归
ValueError: Expected 96 from C header, got 88 from PyObject
thymeleaf中 th:href使用笔记
【论文阅读】Further Non-local and Channel Attention Networks for Vehicle Re-identification
【深度学习21天学习挑战赛】备忘篇:我们的神经网模型到底长啥样?——model.summary()详解
Copy攻城狮的年度之“战”|回顾2020
【CV-Learning】Image Classification
Qt日常学习
【论文阅读】Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
Dictionary feature extraction, text feature extraction.
Android foundation [Super detailed android storage method analysis (SharedPreferences, SQLite database storage)]
PCL1.12 解决memory.h中EIGEN处中断问题
TensorFlow2 study notes: 5. Common activation functions
度量学习(Metric learning)—— 基于分类损失函数(softmax、交叉熵、cosface、arcface)