当前位置:网站首页>8.优化器
8.优化器
2022-07-07 23:11:00 【booze-J】
文章
一、优化器
常见的一些优化器有:SGD、Adagrad、Adadelta、RMSprop、Adam、Adamax、Nadam、TFOptimizer等等。
1.SGD(Stochastic gradient descent)
标准梯度下降法:
标准梯度下降法计算所有样本汇总误差,然后根据总误差来更新权值。
随机梯度下降法:
随机梯度下降法随机抽取一个样本来计算误差,然后更新权值。
批量梯度下降法:
批量梯度下降算是一种折中的方案,从总样本中选取一个批次(比如一共有10000个样本,随机选取100个样本作为一个batch),然后计算这个batch的总误差,根据总误差来更新权值。
标准梯度下降法:速度慢,效果好
随机梯度下降法:速度快,效果差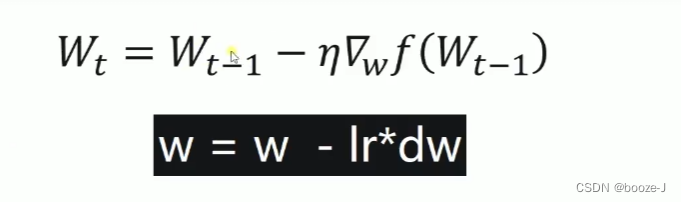
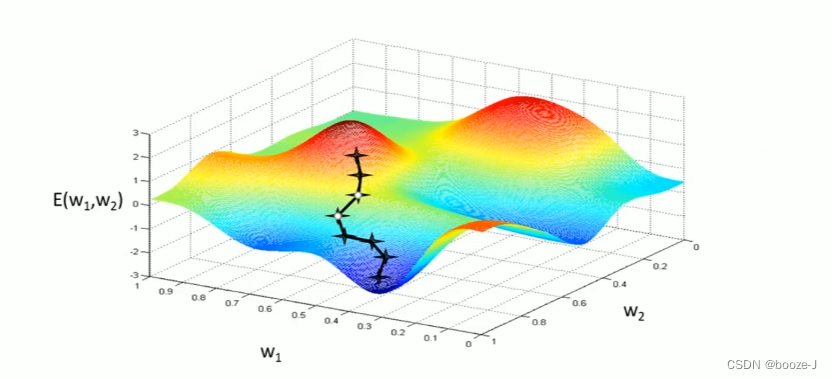
2.Momentum
γ \gamma γ动力,通常设置为0.9。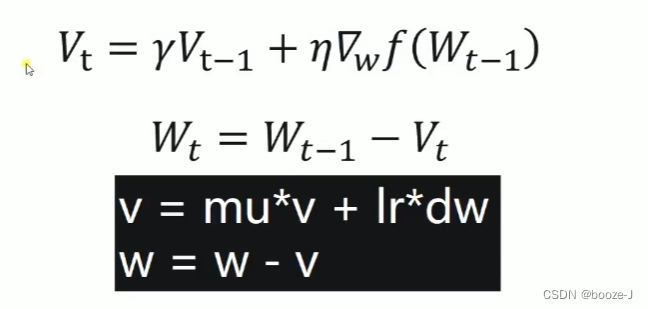
当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球的向下的速度。
3.NAG(Nesterov accelerated gradient)
γ \gamma γ动力,通常设置为0.9。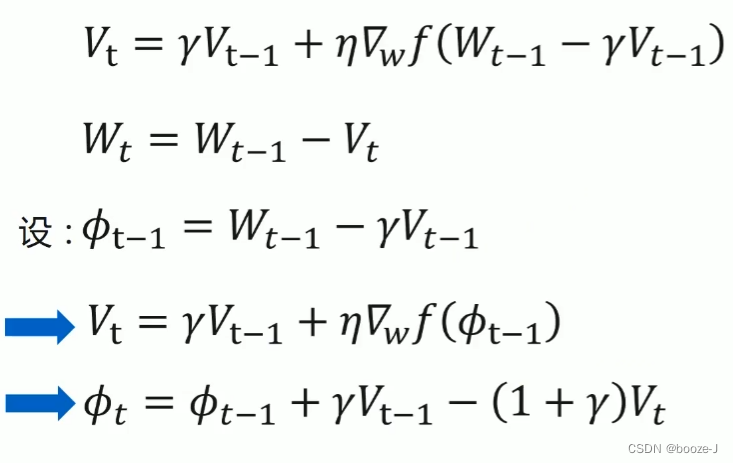


4.Adagrad
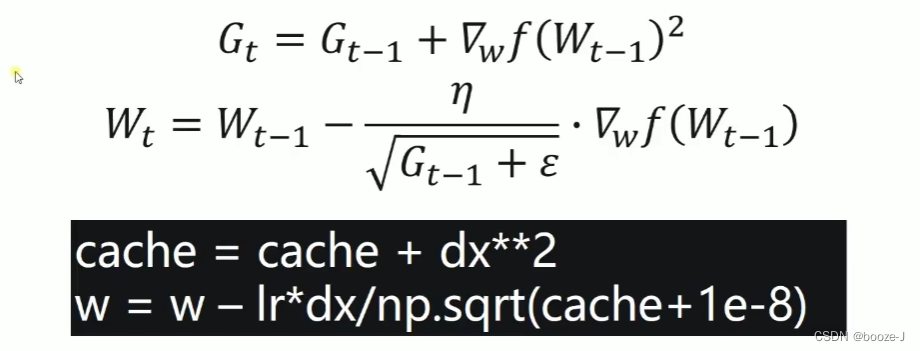
ε:避免分母为0,取值一般是1e-8。
Adagrad主要的优势在于不需要人为的调节学习率,它可以自动调节。它的缺点在于,随着迭代次数的增多,学习率也会越来越低,最终会趋向于0。
5.RMSprop

γ \gamma γ动力,通常设置为0.9。
RMSprop是Adagrad的改进,RMSprop不会出现学习率越来越低的问题,而且也能自己调节学习率,可以得到一个比较好的效果。
6.Adadelta
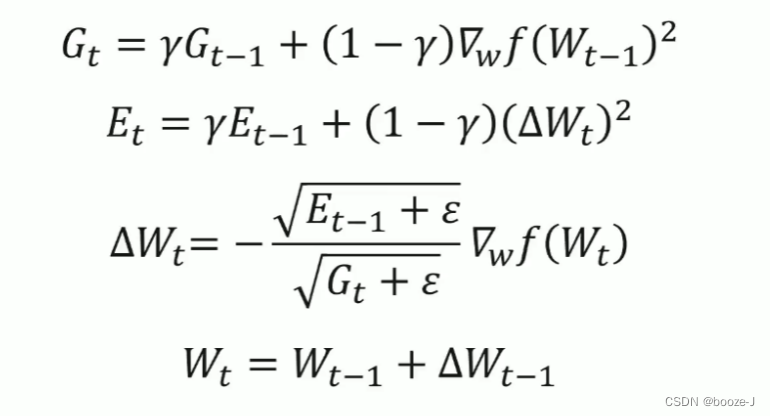
γ \gamma γ动力,通常设置为0.9。
Adadelta也是Adagrad的改进,Adadelta不需要使用学习率也可以达到一个很好的效果。
7.Adam
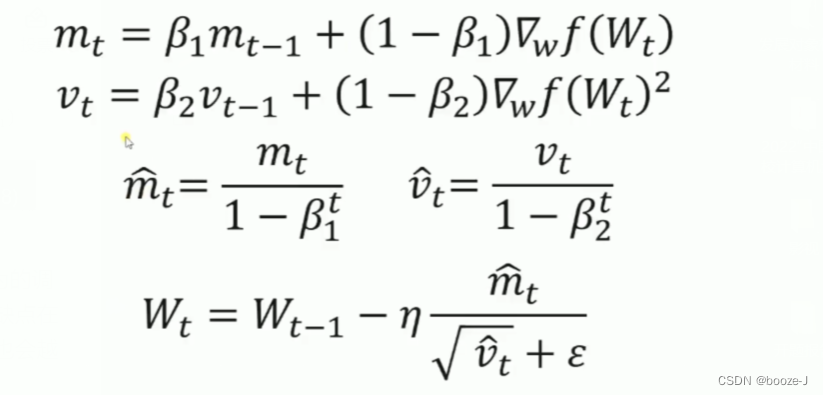
β1:通常取0.9,β2:通常取0.999。
Adam是常用的一种优化器。Adam会存储之前衰减的平方梯度,同时它也会保存之前衰减的梯度。经过一些处理之后再用来更新权值W。
效果对比:


二、优化器的简单使用
以使用Adam优化器为例:
修改4.交叉熵中的
# 定义优化器
sgd = SGD(lr=0.2)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
变化为
# 定义优化器
sgd = SGD(lr=0.2)
adam = Adam(lr=0.001)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=adam,
loss="categorical_crossentropy",
metrics=['accuracy']
)
使用前需要先导入from tensorflow.keras.optimizers import SGD,Adam。
运行结果: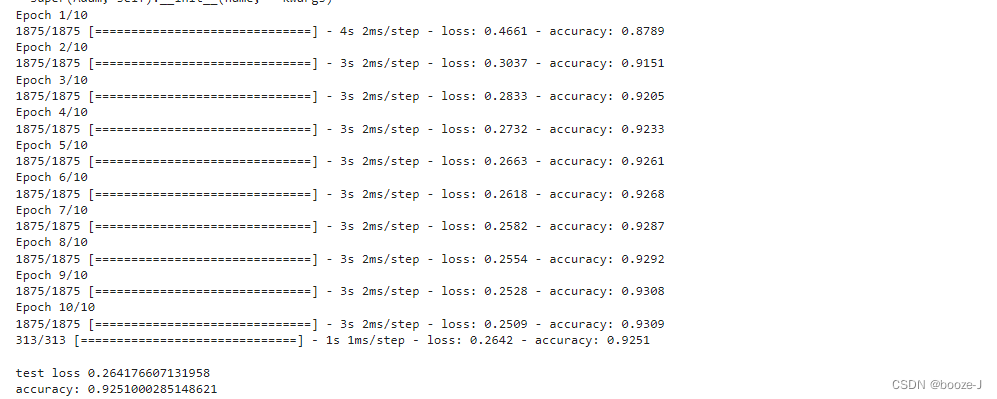
完整代码
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import SGD,Adam
2.加载数据及数据预处理
# 载入数据
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) 还未进行one-hot编码 需要后面自己操作
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape()中参数填入-1的话可以自动计算出参数结果 除以255.0是为了归一化
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 换one hot格式
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3.训练模型
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是10 输入是784,设置偏置为1,添加softmax激活函数
Dense(units=10,input_dim=784,bias_initializer='one',activation="softmax"),
])
# 定义优化器
sgd = SGD(lr=0.2)
adam = Adam(lr=0.001)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=adam,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# 训练模型
model.fit(x_train,y_train,batch_size=32,epochs=10)
# 评估模型
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("accuracy:",accuracy)
边栏推荐
- How to insert highlighted code blocks in WPS and word
- 搭建ADG过程中复制报错 RMAN-03009 ORA-03113
- 1293_FreeRTOS中xTaskResumeAll()接口的实现分析
- Summary of weidongshan phase II course content
- 3 years of experience, can't you get 20K for the interview and test post? Such a hole?
- jemter分布式
- Operating system principle --- summary of interview knowledge points
- Su embedded training - day4
- 牛客基础语法必刷100题之基本类型
- NVIDIA Jetson test installation yolox process record
猜你喜欢
My best game based on wechat applet development
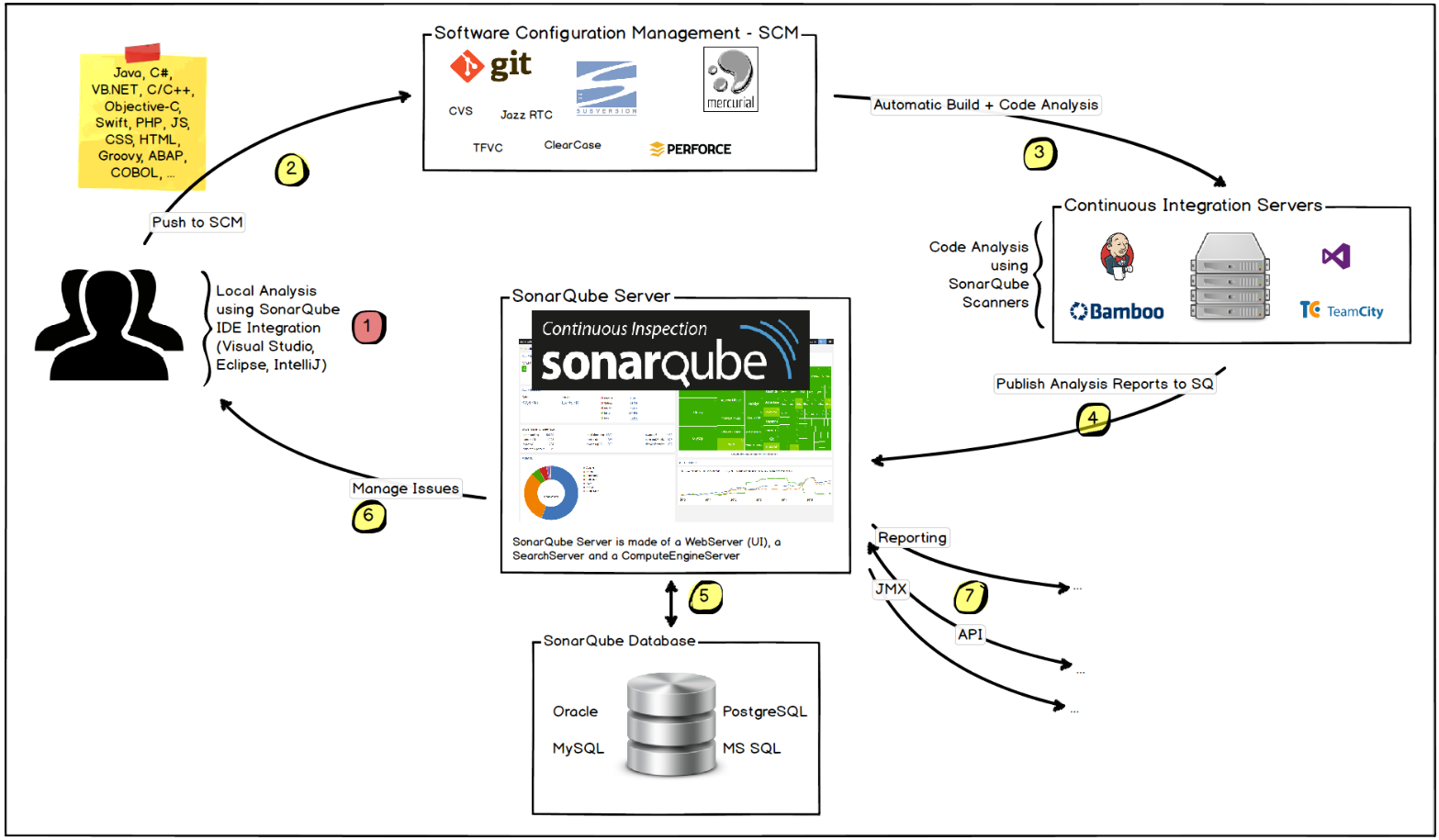
玩转Sonar
![[necessary for R & D personnel] how to make your own dataset and display it.](/img/50/3d826186b563069fd8d433e8feefc4.png)
[necessary for R & D personnel] how to make your own dataset and display it.
Installation and configuration of sublime Text3
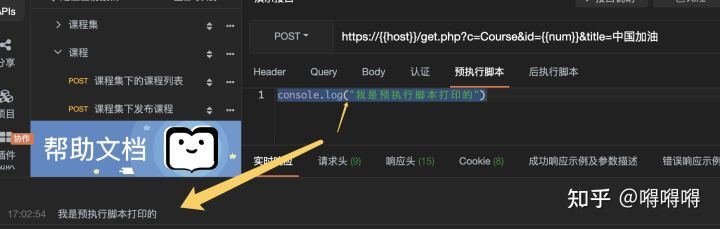
接口测试进阶接口脚本使用—apipost(预/后执行脚本)
Kubernetes static pod (static POD)
AI遮天传 ML-初识决策树
Thinkphp内核工单系统源码商业开源版 多用户+多客服+短信+邮件通知
Where is the big data open source project, one-stop fully automated full life cycle operation and maintenance steward Chengying (background)?

华为交换机S5735S-L24T4S-QA2无法telnet远程访问
随机推荐
大二级分类产品页权重低,不收录怎么办?
牛客基础语法必刷100题之基本类型
Operating system principle --- summary of interview knowledge points
How can CSDN indent the first line of a paragraph by 2 characters?
Prompt configure: error: required tool not found: libtool solution when configuring and installing crosstool ng tool
Malware detection method based on convolutional neural network
How to add automatic sorting titles in typora software?
基于微信小程序开发的我最在行的小游戏
新库上线 | CnOpenData中华老字号企业名录
ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification
Basic mode of service mesh
The method of server defense against DDoS, Hangzhou advanced anti DDoS IP section 103.219.39 x
【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
Jemter distributed
Su embedded training - Day3
串口接收一包数据
AI遮天传 ML-初识决策树
Reentrantlock fair lock source code Chapter 0
Class head up rate detection based on face recognition
C# 泛型及性能比较