Reptile battle ( 8、 ... and ): Crawl for the expression bag
One 、 Website analysis
1、 Demand analysis
stay QQ In the bucket diagram , Why do some people always have endless plans , today , Here is the doutu applet , Finally, I can say goodbye to the pain of fighting without winning .
here , We need to be right about Send expression website Crawl the data of the whole station , Let you have many expression packs
2、 Page analysis
Through packet capturing analysis , We found that , Page link data is in the page , Not loaded data , so , We can request the website directly , To crawl data

3、 Link analysis
here , We are right. https://fabiaoqing.com/bqb/lists/type/hot.html Analyze links ,
Thermogram
https://fabiaoqing.com/bqb/lists/type/hot/page/1.html first page
https://fabiaoqing.com/bqb/lists/type/hot/page/2.html The second page
https://fabiaoqing.com/bqb/lists/type/hot/page/n.html The first n page
Lovers map
https://fabiaoqing.com/bqb/lists/type/liaomei/page/1.html
https://fabiaoqing.com/bqb/lists/type/liaomei/page/2.html
https://fabiaoqing.com/bqb/lists/type/liaomei/page/n.html
At the same time, for other types of expression package links , It's all similar
4、 Details page analysis
Through packet capturing analysis , We found that , The link of the image is also saved on the page source code , meanwhile , it is to be noted that , To achieve lazy loading , The website didn't put pictures in src Attribute above , It's in data-original Inside ; however , When we download the image data , Will find , The picture is a little small , that , How should we solve it ?

Click on another picture , Go to the details page of each picture , You can find a big picture in it , Should we visit the details page to get the download link of the image ? Can it not be so troublesome ?
Let's first compare the links of the two figures , It is found that there is a word difference between the two links , Then we can use replace Replace to get the big picture directly , Instead of visiting the details page
http://tva3.sinaimg.cn/bmiddle/e16fc503gy1h3q1s3nl8tg20ge0geqv5.gif
http://tva3.sinaimg.cn/large/e16fc503gy1h3q1s3nl8tg20ge0geqv5.gif
5、 Process analysis
- Use for Loop through each link
- Get links to each kind of expression package
- Analyze each expression package in each type of expression package
Two 、 Write code
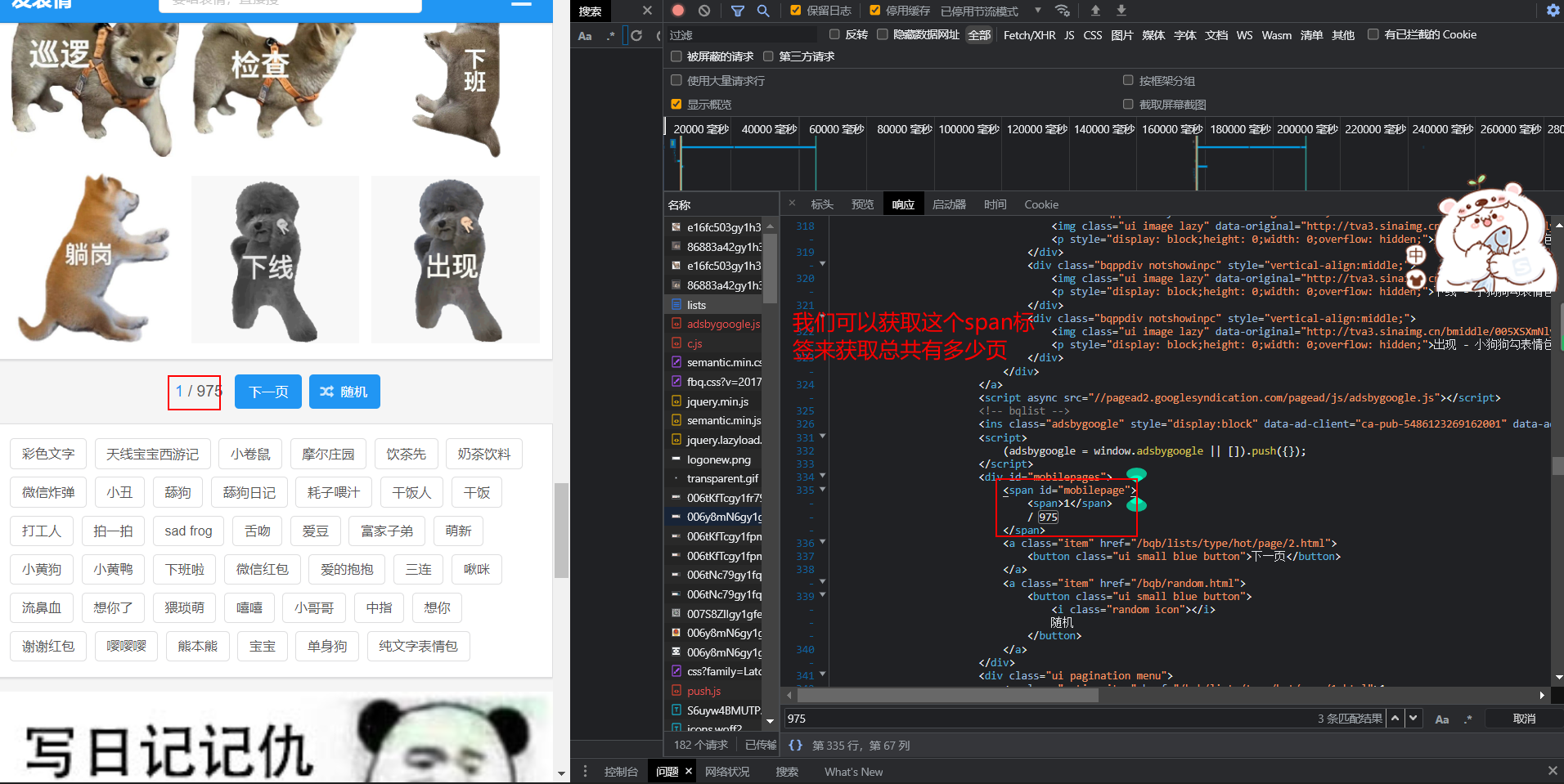
1、 Number of pages parsed
import requests, os, re # Guide pack
from lxml import etree # This use xpath Parsing data
from fake_useragent import UserAgent # Random request header
if not os.path.exists("./ emoticon "):
os.mkdir("./ emoticon ")
add_url = "https://fabiaoqing.com" # Used to splice expression packs url
# Let's prepare a basic url list , Of course, this can also be obtained by using crawlers
base_urls = [
"https://fabiaoqing.com/bqb/lists/type/hot/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/liaomei/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/qunliao/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/doutu/page/%d.html"
"https://fabiaoqing.com/bqb/lists/type/duiren/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/emoji/page/%d.html"
]
headers = {
"user-agent": UserAgent().random,
}
def get_num(url):
""" Analyze how many pages there are in each major expression package """
resp = requests.get(url, headers=headers)
resp.encoding = resp.apparent_encoding
html = etree.HTML(resp.text)
temp = html.xpath('//*[@id="mobilepage"]/text()')[0] # Locate where the number of pages is stored
num = int(re.search("\d+", temp).group()) # Regular matching numbers
return num # Return results
page = get_num(base_urls[0] % 1)
2、 Get a kind of expression package
def get_eve_express(page_url):
resp = requests.get(page_url, headers=headers)
resp.encoding = resp.apparent_encoding
html = etree.HTML(resp.text)
a = html.xpath('//*[@id="bqblist"]/a') # Get the pictures of each type a Tag Links
# Traverse a label
for i in a:
href = i.xpath("./@href")[0]
href = add_url + href # url Splicing
title = i.xpath("./@title")[0]
dic = {
"href": href,
"title": title
}
# Here, call the function to parse and download the expression package , below , Let's take a random dictionary to test
print(dic)
get_eve_express(base_urls[0] % 1)
3、 Save the expression pack
test_dic = {'href': 'https://fabiaoqing.com/bqb/detail/id/54885.html', 'title': ' Guard dog expression bag \u200b_ Doutu expression pack (8 A look )'}
def get_down_url(dic):
""" Download and store emoticons """
if not os.path.exists(f"./ emoticon /{dic['title']}"):
os.mkdir(f"./ emoticon /{dic['title']}")
resp = requests.get(dic['href'], headers=headers)
info = re.findall('<img class="bqbppdetail lazy" data-original="(?P<href>.*?)" src', resp.text)
for i in info:
# Replace the picture with a larger one
i = i.replace("bmiddle", "large")
resp = requests.get(i)
name = i.split("/")[-1]
with open(f"./ emoticon /{dic['title']}/{name}", "wb") as f:
f.write(resp.content)
print(f"{dic['title']} The series expression package is saved !")
get_down_url(test_dic)
3、 ... and 、 Master code
import requests, os, re # Guide pack
from lxml import etree # This use xpath Parsing data
from fake_useragent import UserAgent # Random request header
if not os.path.exists("./ emoticon "):
os.mkdir("./ emoticon ")
add_url = "https://fabiaoqing.com" # Used to splice expression packs url
# Let's prepare a basic url list , Of course, this can also be obtained by using crawlers
base_urls = [
"https://fabiaoqing.com/bqb/lists/type/hot/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/liaomei/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/qunliao/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/doutu/page/%d.html"
"https://fabiaoqing.com/bqb/lists/type/duiren/page/%d.html",
"https://fabiaoqing.com/bqb/lists/type/emoji/page/%d.html"
]
headers = {
"user-agent": UserAgent().random,
}
def get_num(url):
""" Analyze how many pages there are in each major expression package """
resp = requests.get(url, headers=headers)
resp.encoding = resp.apparent_encoding
html = etree.HTML(resp.text)
temp = html.xpath('//*[@id="mobilepage"]/text()')[0] # Locate where the number of pages is stored
num = int(re.search("\d+", temp).group()) # Regular matching numbers
return num # Return results
def get_down_url(dic):
""" Download and store emoticons """
if not os.path.exists(f"./ emoticon /{dic['title']}"):
os.mkdir(f"./ emoticon /{dic['title']}")
resp = requests.get(dic['href'], headers=headers)
info = re.findall('<img class="bqbppdetail lazy" data-original="(?P<href>.*?)" src', resp.text)
for i in info:
# Replace the picture with a larger one
i = i.replace("bmiddle", "large")
resp = requests.get(i)
name = i.split("/")[-1]
with open(f"./ emoticon /{dic['title']}/{name}", "wb") as f:
f.write(resp.content)
print(f"{dic['title']} The series expression package is saved !")
def get_eve_express(page_url):
resp = requests.get(page_url, headers=headers)
resp.encoding = resp.apparent_encoding
html = etree.HTML(resp.text)
a = html.xpath('//*[@id="bqblist"]/a') # Get the pictures of each type a Tag Links
# Traverse a label
for i in a:
href = i.xpath("./@href")[0]
href = add_url + href # url Splicing
title = i.xpath("./@title")[0]
dic = {
"href": href,
"title": title
}
# Here, call the function to parse and download the expression package , below , Let's take a random dictionary to test
# Download emoticon pack
get_down_url(dic)
def main():
for i in base_urls:
num = get_num(i % 1) # Get the number of pages , Once again for Loop traversal
for j in range(1, num + 1):
get_eve_express(i % j) # Download the pictures
if __name__ == "__main__":
main()