当前位置:网站首页>Mysql database interview questions
Mysql database interview questions
2022-07-06 11:55:00 【Ride the wind to break the bug】
List of articles
- Database Basics
- data type
- engine
- Indexes
- What is index ?
- What are the advantages and disadvantages of index
- Index usage scenarios ( a key )
- What are the types of indexes ?
- The data structure of the index (b Trees ,hash)
- The fundamentals of indexing
- What are the indexing algorithms ?
- The principles of index design ?
- The principle of index creation ( A top priority )
- Three ways to create indexes , Delete index
- What to pay attention to when creating indexes ?
- Can index query definitely improve query performance ? Why?
- How to delete data of millions or above
- Prefix index
- What is the leftmost prefix principle ? What is the most left common matching principle
- B Trees and B+ The difference between trees
- Use B The benefits of trees
- Use B+ The benefits of trees
- Hash Index and B+ What are the differences or advantages and disadvantages of indexes
- Why do databases use B+ Trees, not B Trees
- B+ Tree does not need to return table to query data when it satisfies clustering index and covering index
- What is a clustered index ? When to use clustered index and non clustered index
- Will non clustered index return to table query
- What is a federated index ? Why should we pay attention to the order in the union index ?
- Business
- lock
- Yes MySQL Do you understand ?
- The relationship between isolation level and lock
- According to the granularity of the lock, which database locks have ? Lock mechanism and InnoDB Lock algorithm
- According to the type of lock MySQL What locks are there ? Is locking like the above a bit of a hindrance to concurrency efficiency
- MySQL in InnoDB How to realize the row lock of engine ?
- InnoDB There are three algorithms for storing engine locks
- What is a deadlock ? How to solve ?
- What are optimistic locks and pessimistic locks of database ? How to achieve ?
- View
- Stored procedures and functions
- trigger
- common SQL sentence
- SQL What are the main types of sentences
- Super key 、 Candidate key 、 Primary key 、 What are the foreign keys ?
- SQL What are the constraints ?
- Six associations
- The table connects interview questions
- What is subquery
- Three kinds of sub queries
- mysql in in and exists difference
- varchar And char The difference between
- varchar(50) in 50 Meaning of
- int(20) in 20 Meaning of
- mysql Why is it designed this way?
- mysql in int(10) and char(10) as well as varchar(10) The difference between
- FLOAT and DOUBLE What's the difference ?
- drop,delete And truncate The difference between
- UNION And UNION ALL The difference between ?
- SQL Optimize
- How to locate and optimize SQL Statement performance problems ? Is the index created used in ? Or how can we know why this statement runs slowly ?
- SQL Life cycle of
- Large table data query , How to optimize the
- How to deal with large paging ?
- mysql Pagination
- Slow query log
- I care about the business system sql Is it time consuming ? Is the statistics too slow ? How to optimize slow queries ?
- Why try to set a primary key ?
- The primary key uses auto increment ID still UUID?
- Why do fields need to be defined as not null?
- If you want to store a user's password hash , What fields should be used for storage ?
- Optimize data access during query
- Optimize long and difficult query statements
- Optimize specific types of query statements
- Optimize associated queries
- Optimize subqueries
- Optimize LIMIT Pagination
- Optimize UNION Inquire about
- Optimize WHERE Clause
- Database optimization
- Why optimize
- Database structure optimization
- MySQL database cpu Soar to 500% What can he do with it ?
- How to optimize the big watch ? Some table has nearly ten million data ,CRUD It's slow , How to optimize ? How to do sub database and sub table ? What's wrong with the sub table and sub database ? Is it useful to middleware ? Do you know how they work ?
- Problems faced after separating the tables
- MySQL The principle and process of replication
- The master-slave copy has the function
- Mysql The problem of master-slave copying the ending
- Mysql How master-slave replication works
- Basic principle flow ,3 Threads and their associations
- What are the solutions to read-write separation ?
- Backup plan ,mysqldump as well as xtranbackup Implementation principle of
- What are the ways to repair data table corruption ?
Database Basics
Why use a database ?
- Data saved in memory
advantage : Fast access
shortcoming : Data can't be stored permanently - Data is stored in files
advantage : Data is permanently stored
shortcoming :1) Slower than memory operation , Frequent IO operation .2) It's not convenient to query data - The data is stored in the database
1) Data is permanently stored
2) Use SQL sentence , Query is convenient and efficient .
3) Easy to manage data
What is? SQL?
Structured query language (Structured Query Language) abbreviation SQL, Is a database query language .
effect : For accessing data 、 Inquire about 、 Update and manage relational database system .
What is? MySQL?
MySQL Is a relational database management system , The Swedish MySQL AB Companies to develop , Belong to Oracle Its products .MySQL Is one of the most popular relational database management systems , stay WEB Application aspect ,MySQL It's the best RDBMS (Relational Database Management System, Relational database management system ) One of the application software . stay Java Very common in enterprise development , because MySQL It's open source and free , And it's easy to expand .
What are the three paradigms of database ?
First normal form : Each column cannot be split
Second normal form : On the basis of the first paradigm , Non primary key columns are completely dependent on the primary key , Instead of relying on a part of the primary key
Third normal form : On the basis of the second paradigm , Non primary key columns only depend on the primary key , Not dependent on other non primary keys
When designing the database structure , Try to follow the three paradigms , If not , There must be a good reason . For example, performance and other reasons .
mysql What are the tables about permissions ?
MySQL The server controls the user's access to the database through the permission table , The authority list is stored in mysql In the database , from mysql_install_db Script initialization . These authority tables are user,db,table_priv,columns_priv and host. Here are the structure and contents of these tables :
- user Permissions on the table : Record the user account information allowed to connect to the server , The permissions in it are global .
- db Permissions on the table : Record the operation authority of each account on each database .
- table_priv Permissions on the table : Record data table level operation authority .
- columns_priv Permissions on the table : Record the operation authority of data column level .
- host Permissions on the table : coordination db Permission table controls database level operation permission of given host more carefully . This permission table is not subject to GRANT and REVOKE Statement impact .
MySQL Of binlog There are several entry formats ? What's the difference between them ?
There are three formats ,statement,row and mixed.
- statement In mode , Each one will modify the data sql It will be recorded in binlog in . You don't need to record every line change , Less binlog Log volume , Economize IO, Improved performance . because sql The execution of is contextual , So when you save it, you need to save the relevant information , At the same time, some statements that use functions and so on cannot be copied by records .
- row Below grade , Don't record sql Statement context information , Save only which record was modified , Record unit changes for each line , Basically, it can be written down completely, but due to many operations , Will result in a lot of line changes ( such as alter table), So there's so much information in this pattern of files , Too many logs .
- mixed, A compromise scheme , Common operation use statement Record , When can't use statement When you use row.
TIP: New version of the Mysql Chinese vs row Level has been optimized , When the table structure changes , Will record statements rather than line by line .
data type
mysql What are the data types
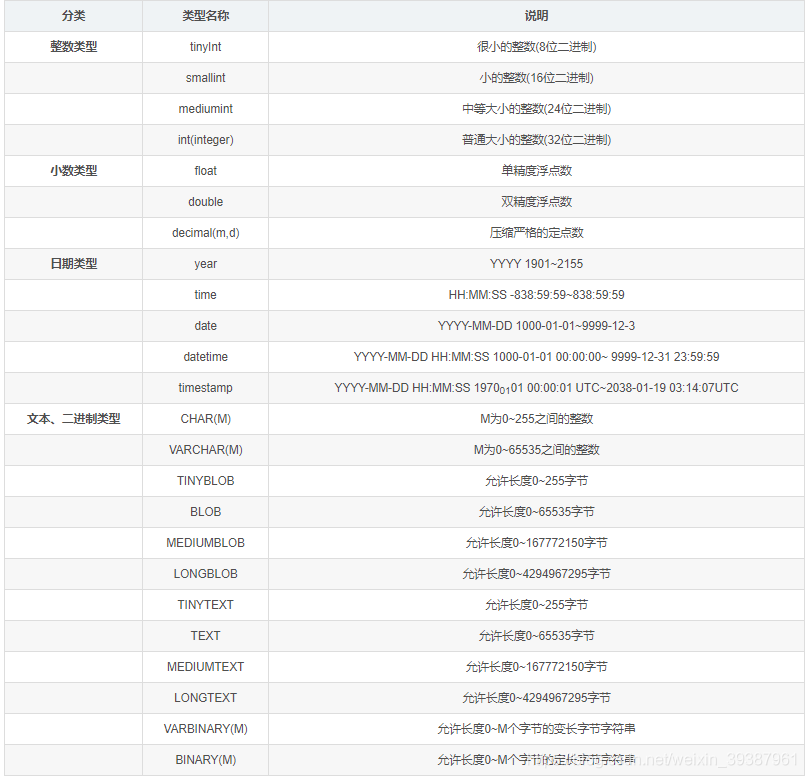
- Integer types , Include TINTINT,SMALLINT,MEDIUMINT,INT,BIGINT, respectively 1 byte ,2 byte ,3 byte ,4 byte ,8 byte . You can add... To any integer type UNSIGNED attribute , Indicates that the data is unsigned , It's a nonnegative integer .
length : Integer type can be specified length , for example :INT(11) The length is 11 Of INT type , Length doesn't make sense in most scenes , It doesn't limit the legal range of values , It will only affect the number of displayed characters , And need and UNSIGNED ZEROFLL Properties are used together to make sense .
Example : Suppose the type is set to INT(5), The attribute is UNSIGNED ZEROFLL, If the data inserted by the user is 12 If you have to , So the actual data stored in the database is 00012. - Real number type , Include FLOAT,DOUBLE,DECIMAL.
DECIMAL Can be used for storage ratio BIGNIT It's a whole number , Can eat and store accurate decimals .
and FLOAT and DOUBLE There is a value range , And support the use of standard floating-point approximation .
When calculating FLOAT and DOUBLE comparison DECIMAL More efficient ,DECIMAL You can understand it as a string processing . - String type , Include VARCHAR,CHAR,TEXT,BLOB
VARCHAR Used to store variable length strings , It saves more space than the fixed length class .
VARCHAR Use extra 1 or 2 Byte storage string length . Column length is less than 255 when , Use 1 The byte represents , Otherwise use 2 The byte represents .
VARCHAR When the stored content exceeds the set length , Memory will be truncated .
CHAR It must be long , Allocate enough space according to the defined string length
CHAR It will be filled with spaces as needed for easy comparison
CHAR Suitable for storing very short strings , Or all values are close to the same length
CHAR When the stored memory exceeds the set length , The content will also be truncated .
Use policy :
- For frequently changing data ,CHAR Than VARCHAR Better , because CHAR It's not easy to produce fragments .
- For very short columns ,CHAR Than VARCHAR More efficient in storage space
- Pay attention to the space required for address allocation when using , A longer column sort consumes more memory
- Avoid using TEXT/BLOB type , Temporary tables will be used when querying , Cause serious performance overhead
- Enumeration type (ENUM) Store non repetitive data as a predefined set .
Sometimes you can use ENUM Instead of the usual string type
ENUM Storage is very compact , Will compress the list value to one or two bytes .
ENUM When storing in memory , In fact, there are integers .
Try to avoid using numbers as ENUM Enumerated constant , Because it's easy to get confused
Sorting is based on internal stored integers - Date and time type , Use as much as possible timestamp, Space efficiency is higher than datetime
It's usually not convenient to save timestamps with integers
If you need to store subtle , have access to bigint Storage
engine
MySQL Storage engine MyISAM And InnoDB difference
Storage engine Storage engine:MySQL Data in , How indexes and other objects are stored , Is a set of file system implementation .
Common storage engines include the following :
- Innodb engine :Innodb The engine provides the database ACID Transaction support , It also provides row level lock and foreign key constraints , The goal of his design is to deal with the database system with large data capacity .
- MyIASM engine ( Original Mysql The default engine for ): No transaction support , Row level locks and foreign keys are also not supported .
- MEMORY engine : All the data is in memory , Data processing speed is fast , But the security is not high .
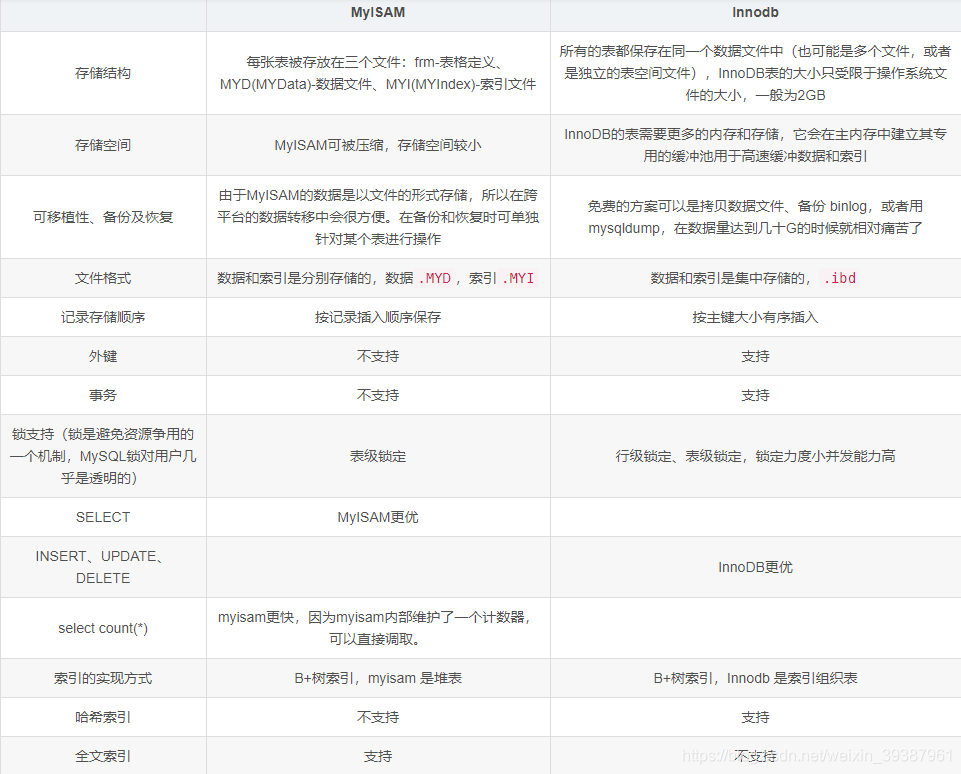
MyISAM Index and InnoDB The difference between indexes ?
- InnoDB An index is a clustered index ,MyISAM Index is a non clustered index
- InnoDB The leaf node of the primary key index stores row data , So the primary key index is very efficient
- MyISAM The row data address stored in the leaf node of the index , It needs to be addressed again to get data
- InnoDB The leaf node of the non primary key index stores the primary key and other indexed column data , Therefore, it is very efficient to overwrite the index when querying .
InnoDB Engine 4 Big characteristic
- Insert buffer (insert buffer)
- The two time to write (double write)
- adaptive hash index (ahi)
- read-ahead (read ahead)
Storage engine selection
If there is no special need , Use default InnoDB that will do
MyISAM: Application based on read-write insertion , Like the blog system , News portal
InnoDB: to update ( Delete ) The operation frequency is good , Or to ensure the integrity of the data ; High concurrency , Support transactions and foreign keys . such as OA Automatic office system .
Indexes
What is index ?
Index is a special kind of file (InnoDB An index on a data table is an integral part of a table space ), They contain reference pointers to all records in the data table
An index is a data structure , Database index , It is a sort data structure in database management system , To assist in quick query , Update data in data table . The implementation of index usually uses B Trees and their varieties B+ Trees .
In the vernacular , An index is a directory , For the convenience of searching the contents of the book , A directory formed by indexing content . Index is a file , It's going to occupy physical space .
What are the advantages and disadvantages of index
The advantages of indexing
- Can greatly speed up the retrieval of data , This is also the main reason for creating an index
- By using index , During the process of query , Using the optimize hide tool , Improve system performance
Disadvantages of indexes - In terms of time : Creating and maintaining indexes takes time , Concrete , When adding data in the table , When deleting and modifying , Index also needs dynamic maintenance , It will reduce the execution efficiency of adding, deleting and modifying queries .
- In space : Index needs to occupy physical space .
Index usage scenarios ( a key )
- where
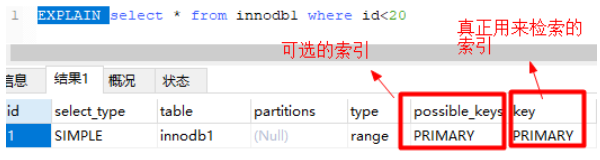
Above picture , according to id Query log , because id Field has only primary key index , So this SQL Execute optional index only primary key index , If there are more than one , Finally, a better one will be selected as the basis for retrieval .
-- Add a field without index
alter table innodb1 add sex char(1);
-- Press sex The optional index for retrieval is null
EXPLAIN SELECT * from innodb1 where sex=' male ';
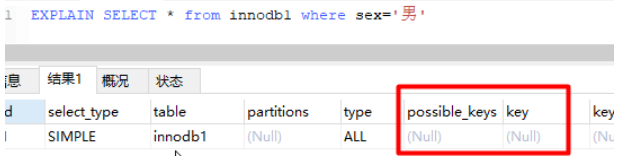 You can try when a field is not indexed , Query efficiency based on this field , Then index the field (alter table Table name add index( Field name )), alike SQL Efficiency of execution , You will find that the query efficiency will be significantly improved ( The larger the amount of data, the more obvious ).
You can try when a field is not indexed , Query efficiency based on this field , Then index the field (alter table Table name add index( Field name )), alike SQL Efficiency of execution , You will find that the query efficiency will be significantly improved ( The larger the amount of data, the more obvious ).
- order by
When we use order by When sorting query results by a field , If the field is not indexed , Then the execution plan will use external sorting for all the data queried ( Read data from hard disk to memory and use internal sorting , Finally, merge the query results ), This operation will greatly affect the performance , Because you need to read all the data involved in the query from disk to memory ( If a single piece of data is too large or too much data, efficiency will be reduced ), No matter the sort after reading the memory .
But if we index this field alter table Table name add index( Field name ), So because the index itself is ordered , Therefore, the data can be extracted one by one according to the index order and mapping relationship , And if it's paged , Then only take out the data corresponding to the index within a certain range of the index table , Instead of taking out all the data for sorting and then returning the data within a certain range like the appeal ( Fetching data from disk is the most performance critical .) - join
Yes join Statement matching relationship (on) The designed field indexing can improve efficiency
Index overlay
If all the fields to be queried have been indexed , The engine will query directly in the index table without accessing the original data ( Otherwise, as long as one field is not indexed, a full table scan will be done ), This is index coverage . So we need to try our best to select Write only the necessary query fields after , To increase the probability of index coverage
It's worth noting here that you don't want to index every field , Because the advantage of using index first is its small size .
What are the types of indexes ?
- primary key : Duplicate columns are not allowed , It is not allowed to be NULL, A table can only have one primary key
- unique index : Duplicate columns are not allowed , Allow for NULL, A table allows multiple columns to create unique indexes .
- Can pass ALTER TABLE table_name ADD UNIQUE (column); Create unique index
- Can pass ALERT TABLE table_name ADD UNIQUE(column1,column2); Create a unique composite index
- General index : Basic index types , There is no limit to uniqueness , Allow for NULL value
- Can pass ALERT TABLE table_name ADD INDEX index_name (column); Create a normal index
- Can pass ALERT TABLE table_name ADD INDEX index_name(column1,column2,column3); Create a composite index
- Full-text index : Is the current search engine use of a key technology
- Can pass ALERT TABLE table_name ADD FULLTEXT (column); Create full text index
The data structure of the index (b Trees ,hash)
The data structure of the index is related to the implementation of the specific storage engine , stay Mysql The indexes used more often in are Hash Indexes ,B+ Tree index, etc , And we often use InnoDB The default index implementation of the storage engine is :B+ Tree index . For a hash index , The underlying data structure is the hash table , So when most of the requirements are single record queries , You can choose hash index , The fastest query performance , Most of the rest , Suggested choice BTree Indexes .
- B Tree index
mysql Get data through storage , basic 90% That's what they use InnoDB 了 , According to the realization ,InnoDB There are currently only two types of indexes for :BTREE(B Trees ) Index and HASH Indexes .B The tree index is mysql The most frequently used index type in the database , Basically all storage engines support BTree Indexes . Usually we say that the index is not unexpected (B Trees ) Indexes ( It's actually using B+ Trees achieve , Because when looking at the index ,mysql Print on BTREE, So it's called B Tree index )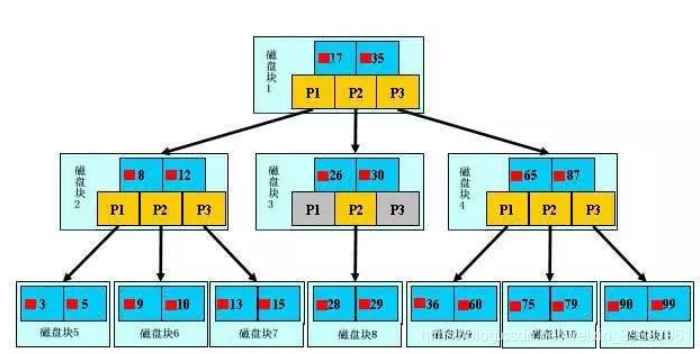
A query :
Primary key index area :Pi( The address of the data when the association is saved ) Query by primary key
General index area :si( The associated id Address , Then get to the address above ). So query by primary key , The fastest
B+Tree nature :
- n Height tree The node of contains n Key words , Not to save the data, but to save the index of the data
- All leaf nodes contain the information of all keywords , And point to the records containing these keywords , And the leaf nodes themselves are linked from small to large according to the size of keywords
- All non terminal nodes can be regarded as index parts , A node contains only the largest of its subtrees ( Or the smallest ) keyword .
- B+ In the tree , Data objects are inserted and deleted only on leaf nodes .
- B+ The tree has 2 Head pointer , One is the root node of the tree , One is the leaf node of the minimum key
- Hash index
Briefly , Similar to the simple implementation in data structure HASH surface ( Hash table ) equally , When we're in mysql When using hash index in , Mainly through Hash Algorithm ( common Hash The algorithm has direct address method , Square with the middle method , Folding method , Division and remainder , Random number method ), Convert database field data to fixed length Hash value , Store with the row pointer of this data Hash The corresponding position of the table ; In case of Hash Collision ( Two different keywords Hash Same value ), In the corresponding Hash The key is stored as a linked list , Of course, this is just a simple simulation diagram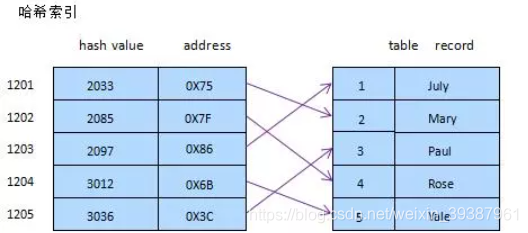
The fundamentals of indexing
The index is used to quickly find which records have specific values , If there is no index , Generally speaking, the whole table is traversed when the query is executed .
The principle of indexing is simple , It's about turning unordered data into ordered queries
- Sort the contents of the columns that are indexed
- Produce reverse order table for sorting results
- Spell the data address chain on the contents of the inverted list
- At query time , First get the contents of the inverted list , Then take out the data address chain , So we can get the specific data
What are the indexing algorithms ?
Index algorithms include BTree Algorithm and Hash Algorithm
- BTree Algorithm
BTree Algorithm is the most commonly used mysql Database index algorithm , It's also mysql Default algorithm , Because it can not only be used in =,>=,<=,<,> On these operators , And it can also be used in like The operator , As long as its query condition is a variable that does not start with a wildcard , for example
-- As long as its query condition is a constant that does not start with a wildcard
select * from user where name like 'jack%';
-- If it starts with a wildcard , Or not using constants , Index will not be used , for example :
select * from user where name like '%jack';
- Hash Algorithm
Hash Indexes can only be used for peer-to-peer comparisons , for example =,<=>( amount to =) The operator , Because it's a location data , Unlike BTree The index needs to go from the root node to the child node , Finally, you can access the leaf node so many times IO visit , So the retrieval efficiency is much higher than BTree Indexes .
The principles of index design ?
- Classes suitable for indexing appear in where Column in clause , Or the column specified in the join clause
- Columns with smaller cardinality , Poor indexing , There is no need to index the secondary column
- Use short index , If you index a long string , You should specify a prefix length , This can save a lot of index space
- Don't over index , Index requires extra disk space , And reduce the performance of write operations . When modifying the contents of the table , The index will be updated or even refactored , More indexes , The longer it will be , So just keeping the index you need is good for querying .
The principle of index creation ( A top priority )
The index is good , But it's not unlimited use , It is best to comply with the following principles
- Leftmost prefix matching principle , The very important principle of composite indexing ,mysql It will keep matching to the right until it encounters a range query (>,<,beetween,like) Just stop matching , such as a=1 and b=2 and c>3 and d=4 If set up (a.b.c.d) Index of order ,d Is an index that you can't use , If set up (a,b,d,c) The index of can be used ,a,b,d The order of can be adjusted at will .
- The fields used as query criteria are often used to create indexes
- Frequently updated fields are not suitable for creating indexes
- If the columns that cannot distinguish data effectively are not suitable for index columns ( Such as gender , Male and female positions , There are three kinds at most , The discrimination is too low )
- Expand the index as much as possible , Don't create a new index , Let's say it's already in the table a The index of , Now want to add (a,b) The index of , All you need to do is change the original index
- The data column with foreign key must be indexed
- For which columns are rarely involved in queries , Do not index columns with more duplicates
- For the definition of text,image and bit Do not index columns of data type
Three ways to create indexes , Delete index
- In execution CREATE TABLE Create index
CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
- Use ALTER TABLE Command to add index
ALTER TABLE table_name ADD INDEX index_name (column_list);
ALTER TABLE To create a normal index ,UNIQUE Index or PRIMARY KEY Indexes
among table_name Is the name of the table to be indexed ,column_list Indicate which columns are indexed , Multiple columns are separated by commas
Index name index_name You can name it yourself , By default ,Mysql A name will be assigned to the first index column . in addition ,ALTER TABLE Allow multiple tables to be changed in a single statement , So you can create multiple indexes at the same time .
- Use CREATE INDEX Command to create
CREATE INDEX index_name ON table_name (column_list);
CREATE INDEX You can add a normal index or UNIQUE Indexes .( But you can't create PRIMARY KEY Indexes )
Delete index
Delete normal index based on index name , unique index , Full-text index :alter table Table name drop KEY Index name
alter table user_index drop KEY name;
alter table user_index drop KEY id_card;
alter table user_index drop KEY information;
Delete primary key index :
alter table Table name drop primary key( Because there is only one primary key ). Here's what's interesting , If the primary key grows by itself , This operation cannot be performed directly ( Self growth depends on primary key index )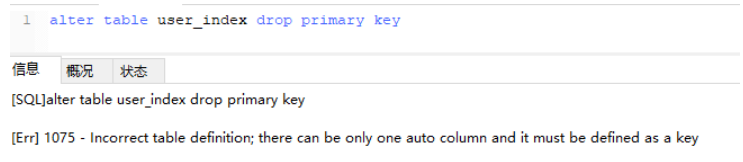
Need to cancel self growth and delete again :
alter table user_index
-- Redefining fields
MODIFY id int,
drop PRIMARY KEY
But the primary key is not usually deleted , Because the design of primary key must have nothing to do with business logic .
What to pay attention to when creating indexes ?
- Non empty field : Column should be specified as NOT NULL, Unless you want to store NULL. stay mysql in , Query optimization is difficult for columns with null values , Because they make indexes , Indexing statistics and comparison operations are more complex . You should use 0, A special value or an empty string replaces the null value
- The discrete value is much larger than the field :( The difference between the values of variables ) You have to put the column in front of the joint index , Can pass count() Function to view the difference value of the field , The larger the returned value is, the more unique the field is, the higher the discrete scale of the field is
- The smaller the index field, the better : The data storage of the database is in pages. The more data a page stores IO The larger the data obtained by the operation, the higher the efficiency ;
Can index query definitely improve query performance ? Why?
Usually , Querying data by index is faster than scanning the whole table . But we must also pay attention to its cost
- Indexes need space to store , It also needs regular maintenance , Whenever a record is added or deleted in the table or the index is modified , The index itself will also be modified . This means that each record will have to be added, deleted, modified and checked more 4,5 Secondary disk I/O, Therefore, indexing requires additional storage space and processing , Those unnecessary indexes will slow down the response time of queries . Using index queries does not necessarily improve query performance , Index range query (INDEX RANGE SCAN) Suitable for two situations :
-》 Search based on a range , Generally, the returned result set of a query is less than the number of records in the table 30%
-》 Search based on non unique index
How to delete data of millions or above
About index : Because the index requires additional maintenance costs , Because the index file is a separate file , So when we add, delete, modify and check the data, we will have additional operations on the index file , These operations require additional IO, It will reduce the execution efficiency of adding, deleting, modifying and checking . therefore , When we delete a million level database , Inquire about MYSQL According to the official policy, the speed of deleting data is directly proportional to the number of indexes created .
- So when we want to delete millions of data, we can delete the index first ( It will take about three minutes )
- Then delete the useless data ( This process takes less than two minutes )
- Recreate index after deletion ( There's less data at this point ) Indexing is also very fast , About ten minutes
- It's definitely much faster to delete directly , Let alone in case the terminal is deleted , All deletions will be rolled back , That's even worse
Prefix index
grammar :index(field(10)), Use field values before 10 Characters to index , The default is to use all the contents of the field to build the index
Premise : High prefix identification , For example, passwords are prefixed with indexes , Because passwords are almost different
Difficulty of practical operation : Depends on the length of prefix truncation
We can use select count(*)/count(distinct left(password,prefixLen));, By adjusting from prefixLen Value ( from 1 Self increasing ) View an average match of different prefix lengths , near 1 When it's time ( Before a password prefixLen Characters can almost determine the only record )
What is the leftmost prefix principle ? What is the most left common matching principle
- seeing the name of a thing one thinks of its function , It's the top left priority , When creating a multi-column index , According to business needs ,where The most frequently used column of clauses is placed on the far left .
- Leftmost prefix matching principle , Very important principle ,mysql It will keep matching to the right until it encounters a range query (>,<,between,like) Just stop matching , such as a=1 and b=1 and c>3 and a=4 If set up (a,b,c,d) Index of order ,d There is no index , If set up (a,b,d,c) Indexes can be used ,a,b,d The order of can be adjusted at will
- = and in You can order , such as a=1 and b=2 and c=3 establish (a,b,c) Indexes can be in any order ,mysql The query optimizer will help you optimize it into a form that the index can recognize
B Trees and B+ The difference between trees
- B In the tree , You can store keys and values in internal nodes and leaf nodes , But in B+ In the tree , Internal nodes are all keys , No value , Leaf nodes store keys and values at the same time
- B+ The leaf nodes of the tree are linked by a chain , and B Each child of the leaf node of the tree is independent .
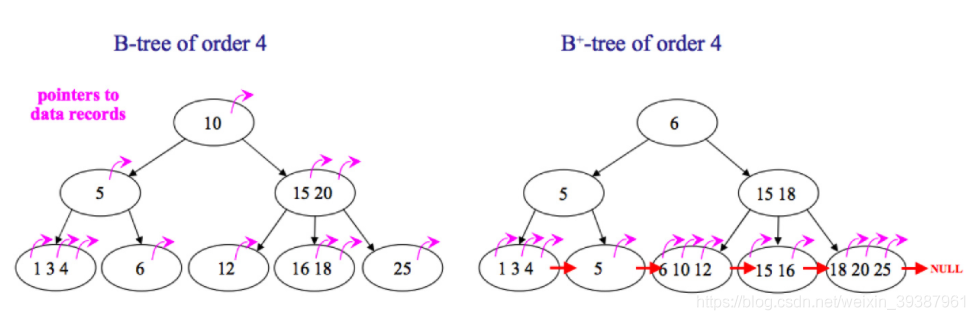
Use B The benefits of trees
B Trees can store keys and values at the same time in internal nodes , therefore , Putting frequently accessed data close to the root node will greatly improve the query efficiency of hot data . This characteristic makes B Trees are more efficient in a scenario where specific data is repeatedly queried .
Use B+ The benefits of trees
because B+ The internal nodes of the tree only store keys , No storage value , therefore , Read once , You can get more keys in the memory page , It helps to narrow the search scope faster .B+ The leaf nodes of the tree are connected by a chain , therefore , When you need a full data traversal ,B+ Trees only need to use O(logN) Time to find the smallest node , And then through the chain O(N) The order of traversal can be . and B Trees need to traverse every layer of the tree , This will require more memory replacements , So it takes more time .
Hash Index and B+ What are the differences or advantages and disadvantages of indexes
The first thing to know is Hash Index and B+ The underlying implementation principle of tree index :
hash The bottom layer of the index is hash surface , When making a query , Call once hash Function to get the corresponding key value , After that, the actual data can be obtained through the back table query .B+ At the bottom of the tree is a multi-channel balanced search tree , Every query starts from the root node , Find the leaf node to get the key value , Then, according to the query, judge whether to return the table to query the data
From the description of the appeal, we can see that they have the following differences :
- hash It's faster for index to do equivalent query ( In general ), But we can't do range query .
Because in Hash In the index hash After the function is indexed , The order of indexes cannot be consistent with the original order , Range query... Is not supported . and B+ All nodes of the tree follow ( The left node is smaller than the parent node , The right node is larger than the parent node , A forked tree is similar , Range of natural support ) - hash Index does not support sorting with index , The principle of same
- hash Fuzzy query and leftmost prefix matching of multi column index are not supported , The principle is also because hash The unpredictability of a function .AAAA and AAAAB The index of is not relevant .
- hash Index can't avoid returning table to query data at any time . and B+ Trees are meeting certain conditions ( Cluster index , Overwrite index, etc ) You can only query by index
- hash Although the index is faster in equivalent queries , But it's not stable , Performance is unpredictable , When a value has a lot of repetition , happen hash Collision , At this point, the efficiency may be extremely poor . and B+ The query efficiency of the tree is relatively stable , For all queries, from the root node to the leaf node , And the height of the tree is lower .
therefore , in the majority of cases , Direct selection B+ Tree index can achieve stable and better query speed , Instead of using hash Indexes
Why do databases use B+ Trees, not B Trees
- B Trees are only suitable for random Retrieval , and B+ The tree supports both random and sequential retrieval
- B+ Tree space utilization is higher , Can reduce I/O frequency , Disk read and write costs less , Generally speaking , The index itself is big , It's impossible to store everything in memory , So indexes are often stored on disk as index files . In this case , Disk will be generated during index search I/O Consume .B+ The internal node of the tree does not point to the specific information of the keyword , Just use as index , Its internal structure ratio B Small tree , There are more keywords in the nodes that the disk can hold , The more keywords you can look up in memory at one time , Relative ,I/O The number of reading and writing is also reduced , and I/O The number of reads and writes is the biggest factor affecting the efficiency of retrieval ;
- B+ Tree query efficiency is more stable .B Tree search may end at non leaf nodes , The closer to the root node, the shorter the record query time , Just find the keyword to confirm the existence of the record , Its performance is equivalent to a binary search in the keyword set . And in the B+ In the tree , Sequential retrieval is obvious , Random search , Any keyword search must take a path from the root node to the leaf node , All keywords have the same search path length , The query efficiency of each keyword is equivalent
- B The tree is raising the disk I/O Performance does not solve the inefficient element traversal of Veneta ,B+ The trees are themselves, but they are connected together in sequence by using pointers , As long as you traverse the leaf node, you can traverse the whole tree . And range based queries are very frequent in databases , and B Tree does not support this operation .
- Add or delete documents ( node ) when , More efficient , because B+ The leaf node of the tree contains all the keywords , And stored in an orderly linked list structure , This can improve the efficiency of addition and deletion
B+ Tree does not need to return table to query data when it satisfies clustering index and covering index
stay B+ In the index of the tree , The leaf node may store the current key value , It may also store the current key Values and the entire row of data , This is the clustered index and the nonclustered index .
stay InnoDB in , Only the primary key is a clustered index , If there is no primary key , Then select a unique key to build the clustering index , If there's no one key , Then an implicit key is generated to build the clustering index .
When a query uses a clustered index , In the corresponding leaf node , You can get the whole row of data , Therefore, there is no need to query the table again .
What is a clustered index ? When to use clustered index and non clustered index
- Cluster index : Put the data and index together , Find the index and find the data
- Nonclustered index : Separate data and index structures , The leaf node of the index structure points to the corresponding row of the data ,MyISAM adopt key_buffer Cache the index into memory first , When you need to access data ( Access data by index ), Search the index directly in memory , Then find the corresponding disk through the index , This is why the index is no longer key)buffer Hit, , The reason for the slow speed
- Clarify a concept :InnoDB in , An index created on top of a clustered index is called a secondary index , Secondary index access data always needs secondary search , Non clustered indexes are secondary indexes , Like a composite index , Prefix index , unique index , The secondary index leaf node no longer stores the physical location of the row , It's the primary key value
When to use clustered and non clustered indexes
Will non clustered index return to table query
not always , This involves whether all the fields required by the query statement hit the index , If all hits the index , Then you don't have to query the return table
for instance : Suppose we build an index in the employee table , So when it comes to select age from employee where age <=20; When it comes to , On the leaf node of the index , Already included age Information , It will not query back to the table again
What is a federated index ? Why should we pay attention to the order in the union index ?
MySQL You can use multiple fields to build an index at the same time , It's called Union index , In the union index , If you want to hit the index , It needs to be used one by one according to the field order when building the index , Otherwise, the index cannot be hit .
The specific reason :
Mysql Use indexes in an orderly way , Let's say that now we have “name,age,school” Joint index of , So the order of the index is : First according to name Sort , If name identical , According to age Sort , If age The value of is the same , According to school Sort .
When making a query , At this time, the index is only based on name Be strict and orderly , So you have to use name Field for equivalent query , Then for the matched Columns , According to age Fields are strictly ordered , You can use age Fields are used for index lookup , One analogy . So we should pay attention to the order of index columns when building a union index , In general , Put the columns with frequent query requirements or high field selectivity in front , Besides , It can be adjusted separately according to the query or table structure of special cases .
Business
What is a database transaction ?
A transaction is an inseparable sequence of database operations , That is, the basic unit of database concurrency control , The result of its execution must change the database from one consistency state to another . A transaction is a logical set of operations , Or both , Either not .
The classic example of a transaction is a transfer :
If Xiaoming wants to transfer money to Xiaohong 1000 element , There are two key operations involved in this transfer : Reduce Xiao Ming's balance 1000 element , Increase the balance of Xiaohong 1000 element . In case of a sudden error between these two operations, such as the collapse of the banking system , As a result, Xiaoming's balance decreased while Xiaohong's balance did not increase , That's not right . Transaction is to ensure the success of both critical operations , Or they all have to fail .
The four characteristics of things (ACID) Introduce to you ?
Relational databases need to follow ACID The rules , The details are as follows :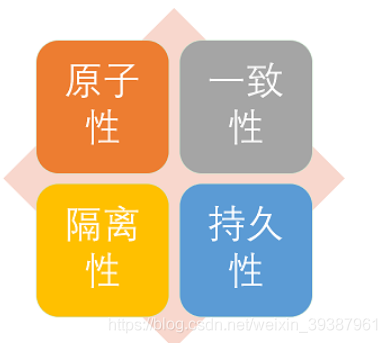
- Atomicity : Transactions are the smallest unit of execution , Division is not allowed , The atomicity of the transaction ensures that the action is either complete , Or it doesn't work at all ;
- Uniformity : Before and after the execution of the transaction , Data consistency , Multiple transactions read the same data with the same result ;
- Isolation, : When accessing the database concurrently , One user's transaction is not interfered by other transactions , The database between concurrent transactions is independent ;
- persistence : After a transaction is committed , Its changes to the data in the database are persistent , Even if the database fails, it should not have any impact .
What is dirty reading ? Fantasy reading ? It can't be read repeatedly ?
- Dirty reading (Drity Read): A transaction has updated a data , Another transaction reads the same data at this time , For some reason , Previous RollBack The operation , Then the data read by the latter transaction will be incorrect .
- It can't be read repeatedly (Non-repeatable read): Data inconsistency in two queries of a transaction , This may be that a transaction update of the original data is inserted between the two queries .
- Fantasy reading (Phantom Read): The number of data transactions in two queries of a transaction is inconsistent , For example, a transaction queries several columns (Row) data , Another transaction inserts new columns of data at this time , The previous transaction is in the next query , You will find that there are fierce data that it did not have first .
What is the isolation level of a transaction ?MySQL What is the default isolation sector ?
In order to achieve the four characteristics of transactions , The database defines 4 Different levels of transaction isolation , From low to high Read uncommitted,Read Committed,Repeatable read,Serializable, These four levels can solve dirty reading one by one , It can't be read repeatedly , These questions of unreal reading .
SQL The standard defines four isolation levels
- READ-UNCOMMITTED( Read uncommitted ): Lowest isolation level , Allow read of uncommitted data changes , May lead to dirty reading , Phantom or unrepeatable reading .
- READ-COMMITTED( Read committed ): Allow to read data submitted by concurrent transactions , Can prevent dirty reading , But phantom or unrepeatable reads can still occur .
- REPEATABLE-READ( Repeatable ): The results of multiple reads of the same field are consistent , Unless the data is modified by the transaction itself , Can prevent dirty and unrepeatable read , But phantom reading can still happen .
- SERIALIZABLE( Serializable ): Highest isolation level , Completely obey ACID Isolation level , All transactions are executed one by one , In this way, there is no interference between transactions , in other words , This level prevents dirty reads , Unrepeatable reading and phantom reading .
Here we need to pay attention to :Mysql By default PEPEATABLE_READ Isolation level ,Oracle Default adopted READ_COMMITTED Isolation level
The implementation of transaction isolation mechanism is based on lock mechanism and concurrent scheduling . Concurrent scheduling uses MVVC( Multi version concurrency control ), By saving the modified old version information to support concurrent consistent read and rollback features .
Because the lower the isolation level , The fewer locks the transaction requests , So the isolation level of most database systems is READ-COMMITTED( Read submissions ), But what you need to know is InnoDB By default, the storage engine uses REPEATABLE-READ() Repeatable There will be no loss of performance .
InnoDB In the case of distributed transactions, the storage engine will generally use SERIALIZABLE( Serializable ) Isolation level .
lock
Yes MySQL Do you understand ?
When there are concurrent transactions in the database , There may be data inconsistencies , At this time, we need some mechanisms to ensure the order of access , Lock mechanism is such a mechanism .
It's like a hotel room , If you go in and out at will , There will be multiple people robbing the same room , And put a lock on the room , People who apply for the key can stay and lock the room , Others can only use it again after it is used .
The relationship between isolation level and lock
- stay Read Uncommitted Below grade , Reading data does not require a shared lock , This will not conflict with the exclusive lock on the modified data
- stay Read Committed Next , Read operations require shared locks , But release the shared lock after the statement is executed
- stay Repeatable Read Below grade , Read operations require shared locks , But the shared lock is not released before the transaction is committed , In other words, the shared lock must be released after the transaction is completed .
- SERIALIZABLE It's the most restrictive level of isolation , Because this level locks the entire range of keys , And hold the lock all the time , Until the transaction is complete .
According to the granularity of the lock, which database locks have ? Lock mechanism and InnoDB Lock algorithm
In a relational database , Database locks can be divided into row level locks according to the granularity of locks (INNODB engine ) And watch level locks (MYISAM engine ) And page level locks (BDB engine )
MyISAM and InnoDB Locks used by the storage engine :
- MyISAM Use watch level lock (table-level locking)
- InnoDB Row level locking is supported (row-level locking) And watch level locks , The default is row level lock
Row-level locks , Table level lock and page level lock contrast - Row-level locks : The line lock is Mysql The lock with the finest granularity , Indicates that only the row of the current operation is locked . Row level lock can greatly reduce the conflict of database operation , The lock granularity is the smallest , But locking costs the most , Row level lock is divided into shared lock and exclusive lock .
characteristic : Spending big , Lock the slow , A deadlock occurs ; Locking granularity minimum , The probability of lock collision is very low , The degree of concurrency is also high . - Table lock : The watch lock is Mysql The lock with the largest granularity , It means locking the whole table level of the current operation , It's easy to implement , Less resource consumption , By most Mysql Engine support , Most commonly used Myisam and InnoDB Table level locking is supported , Table level locks are divided into table shared read locks ( Shared lock )/ Table Write Lock ( Exclusive lock )
characteristic : Low overhead , Locked fast ; A deadlock will not occur ; Large locking size , The highest probability of lock conflict is , The highest degree of concurrency - Page level lock : Page level lock is Mysql A lock whose granularity is between row level lock and table level lock . The watch lock is fast , But there are many conflicts , Row level lock conflicts are less , But the speed is slow. , So I took a compromise page level , Lock a group of adjacent records in turn .
characteristic : The cost and locking time are between table lock and row lock ; A deadlock occurs ; Lock granularity is between table lock and row lock , The concurrency is average .
According to the type of lock MySQL What locks are there ? Is locking like the above a bit of a hindrance to concurrency efficiency
In terms of lock categories , There are shared locks and exclusive locks .
- Shared lock : It's also called read lock , When the user wants to read the data , Add a shared lock to the data , A shared lock can have more than one
- Exclusive lock : Also called write lock , When the user wants to write data , Add an exclusive lock to the data , Only one lock can be added , He's locked up with the others , Shared locks are mutually exclusive
In the above example, there are two kinds of user behavior , One is coming to see the house , It is acceptable for multiple users to watch the house together . One is a real one night stay , in the meantime , No matter what you want to check in or what you want to see .
The granularity of the lock depends on the specific storage engine ,InnoDB Implemented row level lock , Page level lock , Table lock .
Their locking overhead ranges from large to small , Concurrency is also from large to small .
MySQL in InnoDB How to realize the row lock of engine ?
answer :InnoDB It is based on the index to complete row locking
example : select * from tab_with_index where id = 1 for update;
for update The row lock can be locked according to the conditions , also id It's a column with an index key , If id Not the index key InnoDB Table lock will be completed , Concurrency will be impossible
InnoDB There are three algorithms for storing engine locks
- Record lock : Locks on a single line record
- Gap lock: Clearance lock , Lock a range , Not including the record itself
- Next-key lock:record+gap Lock a range , Include the record itself
Related knowledge
- innodb Use... For row queries next-key lock
- Next-locking keying In order to solve Phantom Problem The problem of unreal reading
- When the index of the query contains unique properties , take next-key lock Downgrade to record key
- Gap The purpose of lock design is to prevent multiple transactions from inserting transactions into the same scope , This will lead to the problem of unreal reading
- There are two ways to show off gap lock :( In addition to foreign key constraints and uniqueness checks , In other cases, only use record lock)
1) Set the transaction isolation level to RC
2) The parameter innodb_locks_unsafe_for_binlog Set to 1
What is a deadlock ? How to solve ?
Deadlock means that two or more transactions occupy each other on the same resource , And ask to lock the other party's resources , Which leads to a vicious circle .
Common solutions to deadlock
- If different programs will access multiple tables concurrently , Try to agree to access tables in the same order , Can greatly reduce the chance of deadlock .
- In the same transaction , Try to lock all required resources at once , Reduce the probability of deadlock ;
- For business parts that are very prone to deadlock , You can try using upgrade lock granularity , Table level locking is used to reduce the probability of deadlock ;
If business processing is not good, you can use distributed transaction lock or optimistic lock
What are optimistic locks and pessimistic locks of database ? How to achieve ?
The task of concurrency control in the database is to ensure that when multiple transactions access the same data in the database at the same time, the isolation and unity of transactions and the unity of the database are not destroyed . Optimistic concurrency control ( Optimism lock ) And pessimistic concurrency control ( Pessimistic locking ) Is the main technical means of concurrency control .
- Pessimistic locking : Concurrent conflicts are assumed , Block all operations that may violate data integrity . Lock up the transaction after querying the data , Until the transaction is committed . Realization way : Using the lock mechanism in the database .
- Optimism lock : Assume no concurrency conflicts , Check for data integrity violations only when submitting operations . Lock up transactions when modifying data , adopt version To lock in the same way . Realization way : Optimistic locks generally use version number mechanism or CAS Algorithm implementation
- Two kinds of lock use scenarios
The introduction of two kinds of locks from above , We know that the two locks have their own advantages and disadvantages , Don't think one is better than the other , Like optimistic lock, it is suitable for less writing ( Read more scenes ), That is, conflict is really rare , This can save the cost of locking , Increase the whole throughput of the system .
But if you write too much , Conflicts often occur , This will lead to the continuous application of the upper layer retry, This, in turn, reduces performance , So it's more suitable to use pessimistic lock in general scenario .
View
Why use views ? What is a view ?
To improve complexity SQL The reusability of statements and the security of table operations ,Mysql Database management system provides view features . So called view , It's essentially a virtual table , It doesn't exist in Physics , Its content and are physically nonexistent , The content is similar to a real table , Contains a series of named column and row data . however , Views do not exist in the database as stored data values . Row and column data to customize the basic table used by the view query , And dynamically generated when the view is referenced .
Views allow developers to focus only on specific data of interest and specific tasks they are responsible for , You can only see the data defined in the view , Instead of the data in the table referenced by the view , So as to improve the security of data in the database .
What are the features of views ?
- The columns of a view can come from different tables , It's the abstraction of the table and the new relationship established in the logical sense .
- The view is made up of basic tables ( Real table ) The resulting table ( Virtual table )
- The creation and deletion of views does not affect the base table
- Update view content ( add to , Delete and modify ) Directly affect the basic table
- When views come from multiple base tables , Adding and deleting data is not allowed
The operations of a view include creating a view , View view , Delete views and modify views
What are the usage scenarios of views ?
The fundamental use of views : simplify sql Inquire about , Improve development efficiency , If there is another use, it is compatible with the old table structure
Common usage scenarios of view :
- reusing SQL sentence ;
- Simplify complex SQL operation , After writing the query , It can be easily reused without knowing its basic query details
- Use parts of the table instead of the entire table ;
- Protection data , Users can be granted access to specific parts of the table instead of the entire table ;
- Change data format and presentation , Views can return data that is different from the representation and format of the underlying table
Benefits of views
- Query simplification , The view can simplify the operation of users
- Data security . Views allow users to view the same data from multiple perspectives , It can provide security protection for confidential data
- Logical data independence , Views provide a certain degree of logical independence for refactoring databases
The disadvantages of view
- performance , The database must convert the query of the view into the query of the basic table , If this view is defined by a complex winning query , that , Even a simple query of views , Databases also turn it into a complex combination , It takes a certain amount of time .
- Modify restrictions , When the user changes some rows of the view , The database must convert it into changes to some rows of the basic table , in fact , When inserting or deleting from a view , So it is . For a simple view , It's very convenient , however , For more complex views , It may be immutable
These views have the following characteristics :
- Yes UNIQUE The view of the set operator
- Yes Group By View of clause
- There are things like AVG/SUM/MAX View of the equal aggregate function
- Use DISTINCT Keyword view
- Connect the view of the table ( There are some exceptions )
What is a cursor ?
Cursor is a data buffer opened by the system for users , Deposit SQL Statement execution result , Each cursor area has a name , Users can get records one by one through cursors and assign them to the primary variable , Leave it to the main language for further processing .
Stored procedures and functions
What is stored procedure ? What are the advantages and disadvantages
Stored procedure is a precompiled SQL sentence , The advantage is to allow modular design , That is to say, you only need to create , Later, it can be called many times in this program , If an operation needs to be performed more than once SQL, Using stored procedures is better than just SQL Statement execution should be fast
advantage
- Stored procedures are precompiled , High execution efficiency
- Store overly long code directly in the database , Call directly through the name of the stored procedure , Reduce network communication
- High safety , Users who need certain permissions to execute stored procedures
- Stored procedures can be reused , Reduce the workload of database developers
shortcoming - Modal trouble , But with PL/SQL Dexeloper The mode is very convenient
- Transplant problem , Database side code, of course, is database related , But if it's an engineering project , There is basically no migration problem
- Recompile problem , Because the back-end code is compiled before running , If an object with a reference relationship changes , Affected stored procedures 、 The package will need to be recompiled ( However, it can also be set to compile automatically at run time ).
- If a large number of stored procedures are used in a program system , When the program is delivered and used, the data structure will change with the increase of user requirements , And then there's the system , Finally, if users want to maintain the system, it's very difficult 、 And the cost is unprecedented , It's more difficult to maintain .
trigger
What is trigger ? What are the usage scenarios of triggers ?
Trigger is a kind of special time driven stored procedure defined by user on relational table . A trigger is a piece of code , When a certain time is triggered , Automatically execute the code
Use scenarios
- Cascading changes can be achieved through correlation in the database
- In order to monitor the change of a field in a table in real time, we need to deal with it
- For example, you can generate the number of some services
- Be careful not to abuse , Otherwise, it will cause difficulties in the maintenance of databases and Applications
- Focus on understanding data types CHAR and VARCHAR The difference of , Table storage engine InnoDB and MyISAL The difference between
Mysql What triggers are in ?
stay Mysql There are six triggers in the database :
- Before Insert
- After Insert
- Before Update
- After Update
- Before Delete
- After Delete
common SQL sentence
SQL What are the main types of sentences
- Data definition language DDL(Data Ddefinition Language)CREATE,DROP,ALTER Mainly for the above operations That is to say, it has operation on logical structure , This includes table structure , Views and indexes .
- Data query language DQL(Data Query Language)SELECT
This is easier to understand That is, query operation , With select keyword . Various simple queries , Connect queries, etc All belong to DQL. - Data manipulation language DML(Data Manipulation Language)INSERT,UPDATE,DELETE Mainly for the above operations That is, to operate on data , Corresponding to the above query operation DQL And DML The common operations of adding, deleting, modifying and checking are constructed by the author . And query is a special kind of Be divided into DQL in .
- Data control function DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK
Mainly for the above operations That is to the database security integrity and other operations , It can be simply understood as permission control, etc .
Super key 、 Candidate key 、 Primary key 、 What are the foreign keys ?
- Super key : The set of attributes that uniquely identify tuples in a relationship is called the superkey of the relationship pattern , An attribute can be used as a super key , Multiple attributes can also be combined as a superkey . Superkeys contain candidate keys and primary keys
- Candidate key : Is the smallest super bond , Hyperkeys without redundant elements
- Primary key : In the database table, unique and complete data columns and attribute combinations are given to the stored data objects , A data column can only have one primary key , And the value of the primary key cannot be confirmed , Cannot be null (Null)
- Foreign keys : The primary key of another table existing in one table is called the foreign key of this table .
SQL What are the constraints ?
- NOT NULL: The content of the control field must not be empty (NULL)
- UNIQUE: Control field content cannot be repeated , A table allows more than one Unique constraint
- PRIMARY KEY: It is also used to control the field content can not be repeated , But it allows only one... In a table
- FOREIGN KEY: The action used to prevent the connection between tables from being broken , It also prevents illegal data from being inserted into foreign key columns , Because it has to be one of the values in the table it points to .
- CHECK: Used to control the value range of a field .
Six associations
- Cross connect (CROSS JOIN)
- Internal connection (INNER JOIN)
- External connection (LEFT JOIN/RIGHT JOIN)
- The joint query (UNION And UNION ALL)
- Full connection (FULL JOIN)
- Cross connect (CROSS JOIN)
SELECT * FROM A,B(,C) perhaps SELECT * FROM A CROSS JOIN B (CROSS JOIN C)# There is no correlation condition , The result is Cartesian product , It turned out that the rally was big , It makes no sense , Rarely use internal connections (INNER JOIN)SELECT * FROM A,B WHERE A.id=B.id perhaps SELECT * FROM A INNER JOIN B ON A.id=B.id A collection of data records in multiple tables that meet certain conditions at the same time ,INNER JOIN Can be abbreviated to JOIN
- There are three types of internal connections
- Equivalent connection :ON A.id=B.id
- Unequal value connection :ON A.id > B.id
- Self join :SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
- External connection (LEFT JOIN/RIGHT JOIN)
- The left outer join :LEFT OUTER JOIN, Mainly in the left table , Find the left table first , according to ON After the association conditions match the right table , What is not matched is used NULL fill , It can be abbreviated as LEFT JOIN
- Right connection :RIGHT OUTER JOIN, Mainly in the right table , Look up the right table first , according to ON After the association conditions match the left table , What is not matched is used NULL fill , It can be abbreviated as RIGHT JOIN
- The joint query (UNION And UNION ALL)
SELECT * FROM A UNION SELECT * FROM B UNION ...
It's just putting multiple result sets together ,UNION Based on the previous results , It should be noted that the number of columns in the union query should be equal , The same record lines will merge , If you use UNION ALL, Efficiency of not merging duplicate record lines UNION higher than UNION ALL
4. Full connection (FULL JOIN)
MySQL Full connection is not supported , have access to LEFT JOIN and UNION and RIGHT JOIN A combination of
SELECT * FROM A LEFT JOIN B ON A.id=B.id UNIONSELECT * FROM A RIGHT JOIN B ON A.id=B.id
The table connects interview questions
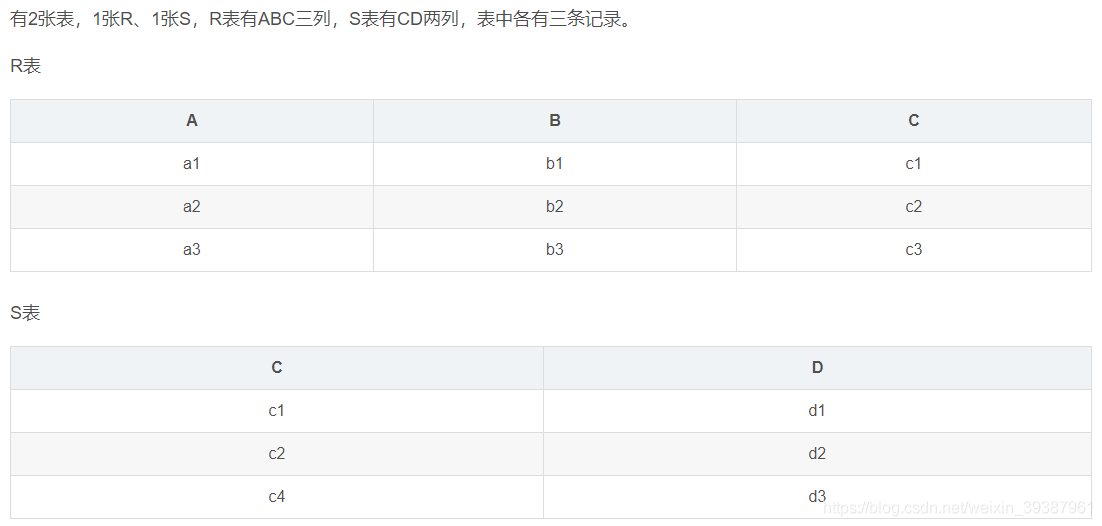
- Cross connect ( The cartesian product )
select r.*,s.* from r,s
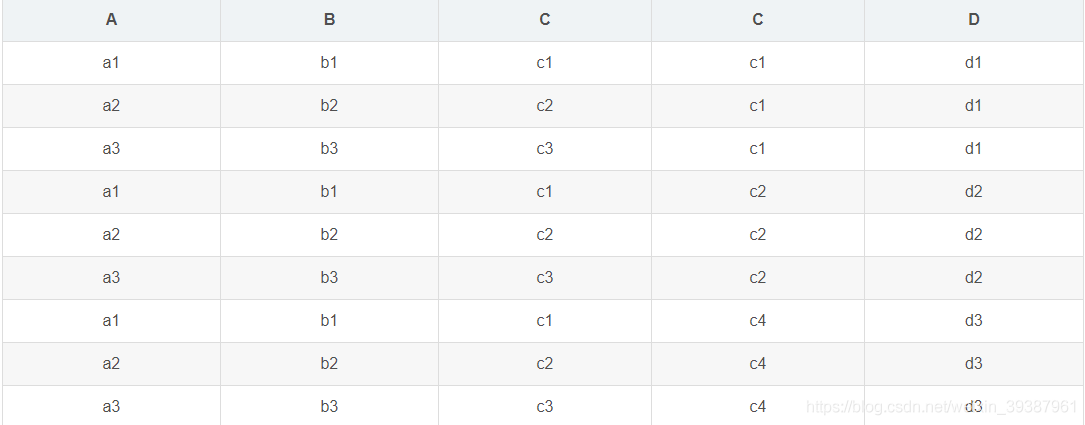
2. Internal connection result
select r.*,s.* from r inner join s on r.c=s.c

3. Left connection result
select r.*,s.* from r left join s on r.c=s.c

4. Right connection result
select r.*,s.* from r right join s on r.c=s.c

5. The result of the full table connection (MySql I won't support it ,Oracle Support )
select r.*,s.* from r full join s on r.c=s.c

What is subquery
- Conditions : One SQL The query result of a statement is taken as the condition or result of another query statement
- nesting : multiple SQL Statement nesting uses , Inside SQL A query statement is called a subquery
Three kinds of sub queries
- Subquery is the case of single row and single column : The result set is a value , Parent query uses :=、 <、 > Equal operator
-- Find out who the highest paid employees are ?
select * from employee where salary=(select max(salary) from employee);
- Subquery is the case of multiple rows and single columns : The result set is similar to an array , Parent query uses :in Operator
-- Find out who the highest paid employees are ?
select * from employee where salary in (select salary from employee);
- Subquery is the case of multiple rows and columns : The result set is similar to a virtual table , Cannot be used for where Conditions , be used for select Clause as a child table
-- 1) Query out 2011 Information of employees who have been employed since
-- 2) Look up all the Department Information , Compare with the information in the virtual table above , Find all the departments ID Equal employees .
select * from dept d, (select * from employee where join_date > '2011-1-1') e where e.dept_id = d.id;
-- Connect with the table :
select d.*, e.* from dept d inner join employee e on d.id = e.dept_id where e.join_date > '2011-1-1'
mysql in in and exists difference
mysql Medium in The statement makes the appearance and the inner table hash Connect , and exits A statement is an external statement loop loop , Every time loop Loop and query the inner table . Many people have always believed that exits Than in The efficiency of sentences should be high , This statement is not all right , This should be distinguished from the environment
- If the size of the two tables queried is the same , Then use in and exits Not much difference .
- If one of the two tables is smaller , One is a big watch , Then the sub query table is very useful exits, Small use of subquery table in
- not in and not exists: If the query statement uses not in, Then both internal and external tables should be scanned , No index is used ; and not existst The sub query can still use the index on the table , So no matter which watch is big , use not exists All ratio not in Be quick .
varchar And char The difference between
char Characteristics
- char Represents a fixed length string , The length is fixed
- If the length of the inserted data is less than char When the length is fixed , Fill with spaces ;
- Because the length is fixed , So access speed is higher than varchar Much faster , Even fast 50%, But because of its fixed length , So it will occupy extra space , It's space for time ;
- about char Come on , The maximum number of characters that can be stored 255, It's not about coding
varchar Characteristics - varhcar Represents a variable long string , The length is variable ;
- How long is the inserted data , Just how long it is stored ;
- varchar In terms of access to and from char contrary , It has slow access , Because the length is not fixed , But because of the schedule , Don't take up extra space , It's time for space ;
- about varchar Come on , The maximum number of characters that can be stored 65532
All in all , Combine performance angles (char faster ) And saving disk space (varchar smaller ), It is safe to design the database according to the specific situation .
varchar(50) in 50 Meaning of
At most 50 Characters ,varchar(50) and varchar(200) Storage hell Same space , But the latter consumes more memory when sorting , because order by col use fixed)length Calculation col length (memory So is the engine ). In the early Msql In the version ,50 Represents the number of bytes , Now it stands for the number of characters .
int(20) in 20 Meaning of
Refers to the length of the display character ,20 Indicates the maximum display width bit 20, But still occupy 4 Byte storage , Storage range unchanged ;
Does not affect internal storage , It's just the impact zone zerofill Defined int when , How many in front 0, Easy to report .
mysql Why is it designed this way?
It doesn't make sense for most applications , It just specifies the number of characters that some tools use to display ;int(1) and int(20) Storage and computing are the same ;
mysql in int(10) and char(10) as well as varchar(10) The difference between
- int(10) Of 10 Indicates the length of the displayed data , It's not the size of the stored data ;char(10) and varchar(10) Of 10 Represents the size of the stored data , That is, how many characters are stored :
int(10) 10 Bit data length 9999999999, Occupy 32 Bytes ,int type 4 position
char(10) 10 Bit fixed string , Not enough space most 10 Characters
varchar(10) 10 Bit variable string , Not enough space most 10 Characters - char(10) Denotes a fixed storage length 10 Characters , Insufficient 10 Fill in with space , Take up more storage space
- varchar(10) Indicates storage 10 A variable length character , Store as many as you can , Spaces are also stored as one character , This is with char(10) The spaces are different ,char(10) The space for space occupying does not count as a character
FLOAT and DOUBLE What's the difference ?
- FLOAT Type data can be stored up to 8 A decimal number , And in memory 4 byte
- DOUBLE Type data can be stored up to 18 A decimal number , And in memory 8 byte
drop,delete And truncate The difference between
All three mean delete , But there are some differences :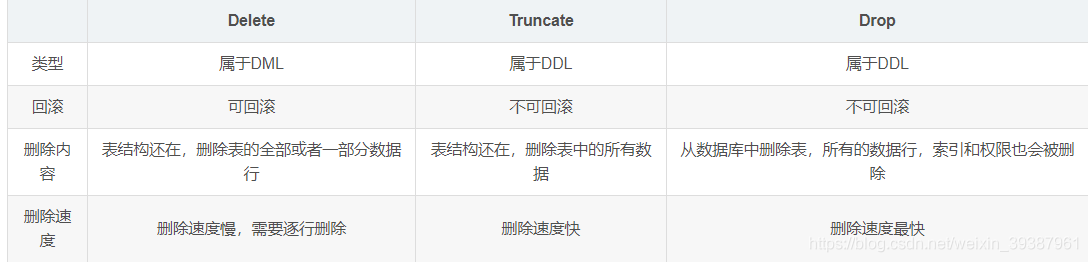
therefore , When you no longer need a watch , use drop; When you want to delete some data lines , use delete; To delete all data while retaining the table truncate.
UNION And UNION ALL The difference between ?
- If you use UNION ALL , Duplicate record lines will not be merged
- efficiency UNION higher than UNION ALL
SQL Optimize
How to locate and optimize SQL Statement performance problems ? Is the index created used in ? Or how can we know why this statement runs slowly ?
For low performance SQL The location of statements , The most important and effective way is to use execution plan ,MySQL Provides explain Command to view the execution plan of the statement . We know , No matter what kind of database , Or what kind of database engine , On the right SQL During the execution of statements, many related optimizations will be done , For query statements , The most important way to optimize is to use indexes . Instead of implementing the plan , Is to show the database engine for SQL Details of the execution of the statement , It includes whether to use index or not , What index to use , Information about the index used, etc .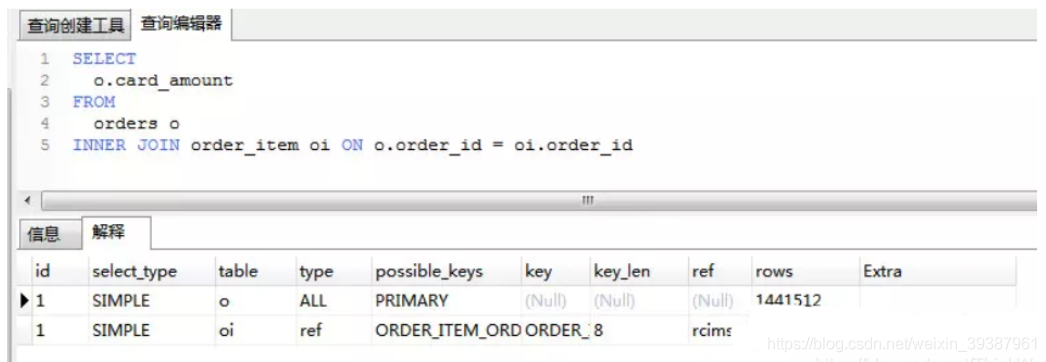
Information contained in the implementation plan id There is a set of numbers , Represents the execution order of each subquery in a query ;
- id The same execution sequence is from top to bottom
- id Different ,id The higher the value, the higher the priority , The first to be executed .
- id by null Time represents a result set , You don't need to use it to query , It often appears in containing union Wait for the query statement .
select_type The query type of each subquery , Some common query types .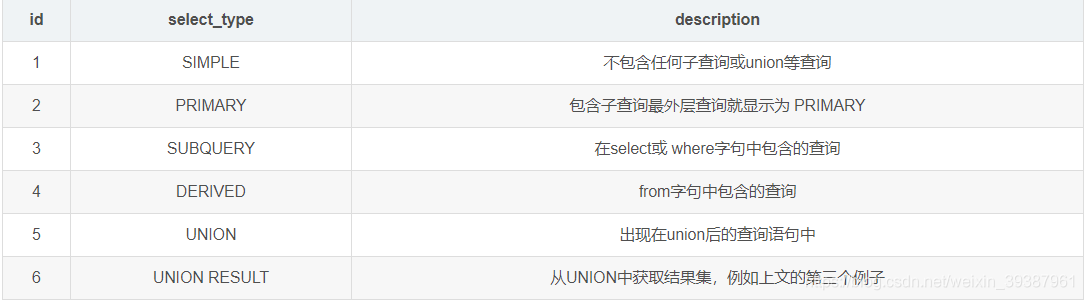
table Query data table , When looking up data from a derived table, it will show x Represents the corresponding execution plan id partitions Table partitioning 、 When creating a table, you can specify which column to partition the table .
for example :
create table tmp (
id int unsigned not null AUTO_INCREMENT,
name varchar(255),
PRIMARY KEY (id)
) engine = innodb
partition by key (id) partitions 5;
type( It's very important , You can see if there's an index ) Access type
1)ALL Scan the full table data
2)index Traverse index
3)range Index range lookup
4)index_subquery Use... In subqueries ref
5)unique_subquery Use... In subqueries eq_ref
6)ref_or_null Yes Null To optimize the index ref
7)fulltext Use full text indexing
8)ref Find data using a non unique index
9)eq_ref stay join Use in query PRIMARY KEYorUNIQUE NOT NULL Index Association .
possible_keys
Possible indexes , Note that you don't have to use . If there is an index on the field involved in the query , Then the index will be listed . When this column is NULL Consider the current SQL Whether it needs to be optimized .
key
Show MySQL The index actually used in the query , If you don't use an index , Is shown as NULL.
TIPS: If an overlay index is used in the query ( Overlay index : The index data covers all the data to be queried ), The index appears only in key In the list
key_length
Index length
ref
Indicates the join matching condition of the above table , That is, which columns or constants are used to find values on index columns
rows
Returns the estimated number of result sets , It's not an exact value .
extra It's very informative
Common are :
- Using index Use overlay index
- Using where Used where Clause to filter the result set
- Using filesort Use file sorting , When sorting with non indexed columns , Very performance intensive , Try to optimize .
- Using temporary Using a temporary table sql The optimization target can refer to Alibaba development manual
【 recommend 】SQL Objectives of performance optimization : At the very least range Level , The requirement is ref Level , If it could be consts best .
explain :
1) consts There is at most one matching row in a single table ( Primary key or unique index ), Data can be read in the optimization phase .
2) ref It refers to the use of ordinary indexes (normal index).
3) range Scope index .
Counter example :explain Table results ,type=index, Index physical file full scan , Very slow , This index Level comparison range Still low , With a full scan is a wizard .
SQL Life cycle of
- The application server establishes a connection with the database server
- The database process gets the request sql
- Parse and generate execution plan , perform
- Read data into memory and do logical processing
- Through step 1 connection , Send results to client
- Close the connection , Release resources
Large table data query , How to optimize the
- Optimize shema,sql sentence + Indexes ;
- Second, add cache ,memcached,redis;
- Master slave copy , Read / write separation
- Split Vertically , According to the coupling degree of your module , Divide a large system into smaller ones , It's a distributed system ;
- Horizontal split , For tables with large data , This asynchrony is the most troublesome , The most capable of testing technical level , Choose a reasonable sharding key, In order to have good query efficiency , The table structure also needs to be changed , Do some redundancy , The application should be changed ,sql Try to bring sharding key, Locate the data in the limit table and check , Instead of scanning all the tables ;
How to deal with large paging ?
Large paging is usually solved in two directions :
- Database used to main, This is also what we focus on ( Although the effect is not so great ) Be similar to select * from table where age > 20 limit 1000000 ,10 This kind of query can also be optimized , This statement requires load 1000000 The data is then basically discarded , Take only 10 Of course it's slow , We can change it to select * from table where id in (select id from table where age > 20 limit 100000,10), Although this is also Load A million data , But because of index coverage , All fields to be queried are in the index , So it's going to be fast , At the same time, if ID Continuous Hao , We can still select * from table where id > 1000000 limit 10, Efficiency is also good , There are many possibilities for optimization , But the core idea is the same , Is to reduce load The data of .
- Reduce this request from a requirements perspective .. The main thing is not to do similar needs ( Jump directly to a specific page after millions of pages , Only page by page viewing or following a given route is allowed , This can predict , Can be replaced by ) To prevent ID Leakage and continuous malicious attack
Solve large paging , In fact, it's mainly cache , Predictable content found in advance , Cache to redis etc. k-V In the database , Just go back .
In Alibaba 《Java Development Manual 》 in , The solution to large paging is similar to the first one mentioned above :
【 recommend 】 Use delay association or subquery to optimize the super multi page scenario .
explain :MySQL It's not about skipping offset That's ok , It's about taking offset+N That's ok , And then back before giving up offset That's ok , return N That's ok , That's right offset When I was very old , It's very inefficient , Or control the total number of pages returned , Or for the number of pages over a specific threshold SQL rewrite .
Example : First, quickly locate what needs to be acquired id paragraph , And then relate :
SELECT a.* FROM surface 1 a, (select id from surface 1 where Conditions LIMIT 100000,20 ) b where a.id=b.id
mysql Pagination
limit Clauses can be used to enforce select Statement returns the specified number of records .limit Receive one or two digital parameters . Argument must be an integer constant . If two parameters are given , The first parameter is only the offset of the first return record line , The second parameter specifies the maximum number of rows to return records , The offset of the initial record line is 0( instead of 1)
select * from table limit 5,10; // retrieval 6-15 That's ok
To retrieve all record lines from an offset to the end of the recordset , The second parameter can be specified as -1;
select * from table limit 95,-1; // Retrieve record lines 96 - last
If only one parameter is given , It means to return the maximum number of record lines ;
select * from table limit 5; // Retrieve the first five record lines
let me put it another way ,limit n Equivalent to Limit 0,n;
Slow query log
Used to record execution times that exceed a threshold SQL journal , For fast location and slow query , For our optimization
- Open slow query log
Configuration item :slow_query_log
have access to show variables like 'slov_query_log’ Check to see if it's on , If the status value is OFF, have access to set GLOBAL slow_query_log = on To open , It will be datadir Next generation xxx-slow.log The file of - Set critical time
Configuration item :long_query_time
see :show VARIABLES like ‘long_query_time’, Unit second
Set up :set long_query_time=0.5
The actual operation time should be set from a long time to a short time , About the slowest SQL Optimize out
Check the log , once SQL Beyond the critical time we set, it will be recorded xx-slow.log in
I care about the business system sql Is it time consuming ? Is the statistics too slow ? How to optimize slow queries ?
First of all, we need to understand the reasons for slow query optimization ? Is that the query criteria did not hit the index ? yes load Unnecessary data columns ? Or too much data ?
So optimization is also aimed at these three directions :
- First, analyze the statement , See if load Extra data , It may be that the redundant rows are queried and discarded , Probably loaded a lot of columns that are not needed in the results , Analyze and rewrite statements .
- Analysis statement execution plan , Then get its usage index , Then change the statement or index , Make the statement hit the index as much as possible .
- If the optimization of the statement is no longer possible , Consider whether the amount of data in the table is too large , If so, it can be divided horizontally or vertically .
Why try to set a primary key ?
The primary key is the guarantee for the database to ensure the uniqueness of data rows in the whole table , Even if the business production table has no primary key , Page also suggests adding a self growing column as the primary key , After setting the primary key , The time of subsequent deletion and modification may be faster and ensure the safety of the operating data range .
The primary key uses auto increment ID still UUID?
Self increasing is recommended ID, Do not use UUID.
Because in InnoDB In the storage engine , The primary key index exists as a clustered index , in other words , Primary key index B+ The tree leaf node stores the primary key index and all the data ( In order ), If the primary key index is self increasing ID, So just keep going backwards , If it is UUID, Because of the coming ID Not sure with the original size , Will cause a lot of data insertion , Data mobility , Then it causes a lot of memory fragmentation , This leads to a decrease in insertion performance .
All in all , In the case of a larger amount of data , It will be better to use auto increment primary key .
About primary key is clustered index , If there is no primary key ,InnoDB A unique key will be selected as the clustering index , If there's no one key , An implicit primary key will be generated .
Why do fields need to be defined as not null?
null Values take up more bytes , And will cause a lot of unexpected situations in the program
If you want to store a user's password hash , What fields should be used for storage ?
Password hash , salt , Fixed length strings such as user ID number should use char instead of varchar To store , This can save space and improve retrieval efficiency .
Optimize data access during query
- Too much data access results in query performance degradation
- Determine if the application is retrieving more data than it needs , It could be too many rows or columns
- confirm MySQL Whether the server is analyzing a large number of unnecessary rows of data
- Avoid the following SQL sentence in wrong
– Query unnecessary data . terms of settlement : Use limit solve
– Multiple table Association returns all columns . terms of settlement : Specifies the column name
– Always return all columns . terms of settlement : Avoid using SELECT *
– Repeatedly query the same data . terms of settlement : Can cache data , Next time read cache directly
– Are additional records being scanned . terms of settlement :
Use explain Analyze , If you find that a query needs to scan a large amount of data , But only a few lines are returned , The following techniques can be used to optimize :
1) Use index overlay scan , Put all the columns in the index , In this way, the storage engine can return the result without returning to the table to get the corresponding row .
2) Changing the structure of databases and tables , Modify the data table paradigm
3) rewrite SQL sentence , Let the optimizer execute the query in a better way .
Optimize long and difficult query statements
- A complex query or multiple simple queries
- MySQL It can scan millions of rows of data in memory every second , by comparison , Response data to the client is much slower
- It's good to use the smallest possible query , But sometimes it is necessary to decompose a large query into multiple small queries .
- Syncopation query
- Divide a large query into multiple small identical queries
- Delete at one time 1000 Ten thousand data is more than one deletion 1 ten thousand , The scheme of pause for a while will cost more server overhead .
- Decompose associated query , Make caching more efficient .
- Performing a single query reduces lock contention .
- In the application layer, it is easier to split the database .
- Query efficiency will be greatly improved .
- Queries with fewer redundant records .
Optimize specific types of query statements
- count(*) All columns will be ignored , Count all columns directly , Do not use count( Name )
- MyISAM in , There is no where Conditions of the count(*) Very fast .
- When there is where When the conditions ,MyISAM Of count Statistics don't have to be faster than other engines .
- have access to explain Look up the approximation , Substitute an approximate value for count(*)
- Add summary
- Use the cache
Optimize associated queries
- determine ON perhaps USING Whether there is an index in the clause .
- Make sure GROUP BY and ORDER BY There is only one column in the table , such MySQL It's possible to use indexes .
Optimize subqueries
- Replace... With an associated query
- Optimize GROUP BY and DISTINCT
- These two types of query data can be optimized using indexes , Is the most effective optimization method
- Association query , It's more efficient to group using identity Columns
- If you don't need to ORDER BY, Conduct GROUP BY Time plus ORDER BY NULL,MySQL No more file sorting .
- WITH ROLLUP Super aggregation , It can be moved to the application
Optimize LIMIT Pagination
- LIMIT When the offset is large , Query efficiency is low
- You can record the maximum of the last query ID, The next query is based on the ID To query
Optimize UNION Inquire about
- UNION ALL Is more efficient than UNION
Optimize WHERE Clause
How to solve the problem :
For such questions , First, explain how to locate inefficiency SQL sentence , And then according to SQL Check the reasons why statements may be inefficient , Start with the index , If the index is OK , Consider the above aspects , Data access issues , The problem of long and difficult queries is still some specific type optimization problems , Answer one by one .
SQL Some methods of sentence optimization ?
- Optimize the query , Try to avoid full scan , The first thing to consider is where And order by Index the columns involved .
- Should try to avoid in where Field in the clause null Value judgement , Failing to do so will cause the engine to abandon the index for a full table scan , Such as :
select id from t where num is null
-- Can be in num Set the default value on 0, Make sure the table num No column null value , And then query like this :
select id from t where num=
- Should try to avoid in where Used in clauses != or <> The operator , Otherwise, the engine will discard the index and scan the whole table .
- Should try to avoid in where Used in clauses or To join the conditions , Failing to do so will cause the engine to abandon the index for a full table scan , Such as :
select id from t where num=10 or num=20
-- You can query like this :
select id from t where num=10 union all select id from t where num=20
- in and not in Be careful with , Otherwise, it will result in a full table scan , Such as :
select id from t where num in(1,2,3)
-- For continuous values , It works between Don't use in 了 :
select id from t where num between 1 and 3
- The following query will also result in a full table scan :select id from t where name like ‘% Li %’ To improve efficiency , Consider full-text search .
- If in where Use parameters in Clause , It can also lead to a full table scan . because SQL Local variables are resolved only at runtime , But the optimizer can't delay the choice of access plan to run time ; It has to be selected at compile time . however and , If an access plan is established at compile time , The value of the variable is still unknown , Therefore, it cannot be selected as an input item of index . As the following statement will scan the whole table :
select id from t where [email protected]
-- You can force queries to use indexes instead :
select id from t with(index( Index name )) where [email protected]
- Should try to avoid in where The clause performs an expression operation on the field , This causes the engine to abandon the use of indexes for a full table scan . Such as :
select id from t where num/2=100
-- Should be changed to :
select id from t where num=100*2
- Should try to avoid in where Clause to function fields , This causes the engine to abandon the use of indexes for a full table scan . Such as :
select id from t where substring(name,1,3)=’abc’
-- name With abc At the beginning id Should be changed to :
select id from t where name like ‘abc%’
- Not in where In Clause “=” On the left is the function 、 Arithmetic operations or other expression operations , Otherwise, the system may not be able to use the index correctly .
Database optimization
Why optimize
- The throughput bottleneck of the system often appears in the access speed of the database
- As the application runs , There will be more and more data in the database , Processing time will slow down accordingly
- Data is stored on disk , The speed of reading and writing cannot be compared with that of memory
Optimization principle : Reduce system bottlenecks , Reduce resource use , Increase the reaction speed of the system .
Database structure optimization
A good database design scheme for the performance of the database will often play a multiplier effect .
Data redundancy needs to be considered 、 Speed of query and update 、 Whether the data type of the field is reasonable and so on .
- Decompose a table with many fields into multiple tables
For tables with more fields , If some fields are used very infrequently , You can separate these fields to form a new table .
Because when a table has a large amount of data , It will slow down due to the existence of low frequency fields . - Add middle table
For tables that need frequent union queries , Intermediate tables can be created to improve query efficiency .
By creating a middle table , Insert the data that needs to be queried through union into the intermediate table , Then change the original union query to the query of the intermediate table . - Add redundant fields
The design of data table should follow the rules of normal form theory , Reduce redundant fields as much as possible , Make the database design look elegant 、 grace . however , Reasonable addition of redundant fields can improve the query speed .
The more normalized the table is , The more relationships between tables , The more you need to join queries , The worse the performance .
Be careful :
The value of the redundant field was modified in a table , We have to find a way to update in other tables , Otherwise, it will lead to data inconsistency .
MySQL database cpu Soar to 500% What can he do with it ?
When cpu Soar to 500% when , Use the operating system command first top Command to observe if mysqld Occupation causes , If not , Find out which processes are taking up the most , And deal with it .
If it is mysqld Caused by the , show processlist, Look at what's running inside session situation , Is there a consumption of resources sql Running . Find out what's consuming sql, See if the execution plan is accurate , index Missing , Or the amount of data is too large .
Generally speaking , Definitely kill Drop these threads ( Observe at the same time cpu Is the usage rate down ), And so on ( For example, index 、 Change sql、 Change memory parameters ) after , Run these again SQL.
It's also possible that it's every sql It doesn't cost much , But all of a sudden , A large number of session The connection leads to cpu soaring , In this case, we need to work with the application to analyze why the number of connections will surge , Then make the corresponding adjustment , For example, limit the number of connections .
How to optimize the big watch ? Some table has nearly ten million data ,CRUD It's slow , How to optimize ? How to do sub database and sub table ? What's wrong with the sub table and sub database ? Is it useful to middleware ? Do you know how they work ?
When Mysql When the number of single table records is too large , Database CRUD Performance will be significantly reduced , Some common optimization measures are as follows :
- Limit the range of data : Be sure to prohibit query statements without any restrictions on data range conditions . such as : When users are querying the order history , We can control it within a month ;
- read / Write separation : Classic database splitting scheme , The main warehouse is responsible for , Read from the library ;
- cache : Use Mysql The cache of , And for heavyweights , For less updated data, consider using application level caching ;
There is also through the way of sub database sub table optimization , There are mainly vertical sub table and horizontal sub table
- Vertical zones
Split according to the correlation of data tables in the database . for example : The user table contains both the login information and the basic information of the user , You can split the user table into two separate tables , Even put it into a separate library as a sub Library
In short, vertical splitting refers to the splitting of database table columns , Split a table with more columns into multiple tables , As shown in the figure below :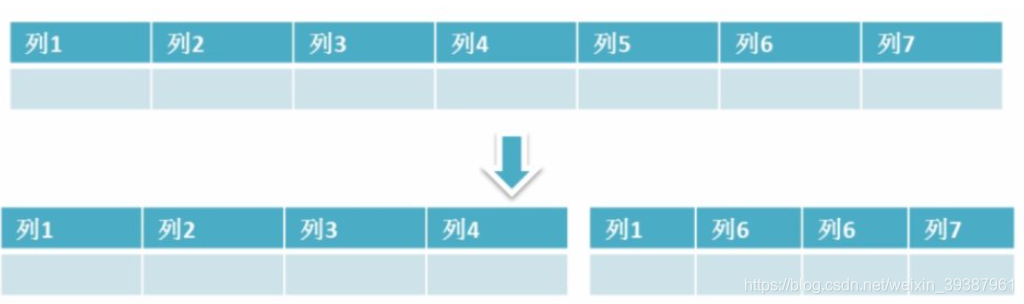
Advantages of vertical splitting : Can make row data smaller , Reduce the number of reads in the query Block Count , Reduce I/O frequency . Besides , Vertical partitioning simplifies the structure of tables , Easy to maintain
Disadvantages of vertical splitting : There will be redundancy in the primary key , Need to manage redundant columns , And will cause join operation , It can be done in the application layer join To solve , Besides , Vertical partitioning makes transactions more complex ;
- Vertical sub table
Put the primary key and some columns in a table , Then put the primary key and other columns in another table .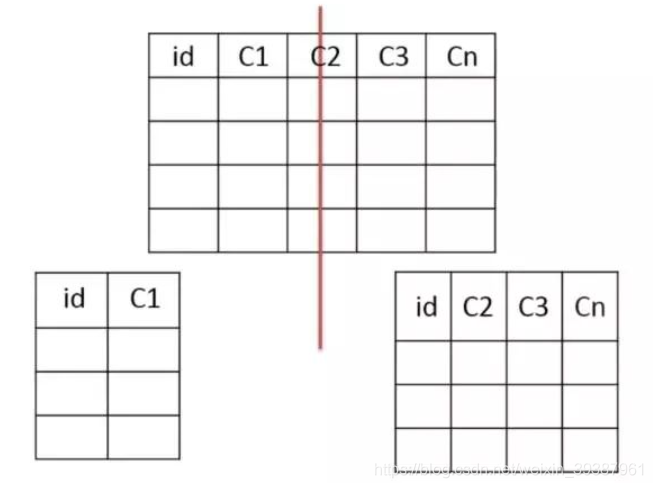
- Applicable scenario
1) If some columns in the table are commonly used , Some of the other columns are not commonly used
2) It can make the data smaller , A data page can store more data , Reduce the number of queries I/O frequency - shortcoming
1) Some table splitting strategies are based on application level logic algorithms , Once the logic algorithm changes , The whole table logic will change , Poor scalability
2) For the application layer , Logic algorithms increase development costs
3) Managing redundant columns , To query all data, you need join operation
- Horizontal zoning :
Keep the data table structure unchanged , Store data shards through some strategy , In this way, each piece of data is scattered into different tables or databases , For distributed purposes , Horizontal splitting can support a very large amount of data
Horizontal splitting refers to the splitting of data table rows , The number of rows in the table exceeds 200 Wanxingshi , It's going to slow down , At this time, you can split the data of a table into multiple tables to store . for instance : We can split user information into multiple user information tables , In this way, we can avoid the impact of too much data on the performance of a single table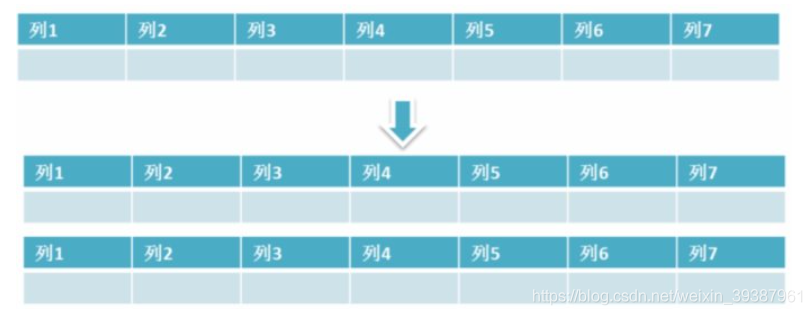
Horizontal splitting can support a very large amount of data , One thing to note is that : Sub table only solves the problem of too large data in a single table , But because the data of the table is still on the same machine , In fact, for promotion sql Concurrency doesn't make sense , Therefore, it's best to divide the horizontal split into different libraries .
Horizontal splitting can support a very large amount of data storage , There is also less transformation of application end , But fragmentation is hard to solve , Crossover point join Poor performance , Complex logic
TIP: Try not to fragment the data , Because splitting brings logic , Deploy , The complexity of operation and maintenance , It is not a big problem for a general data table to support a data volume of less than 10 million under the condition of proper optimization , If you really want to slice , Try to choose client fragmentation Architecture , This can reduce the network of primary and middleware I/O
- Horizontal sub table :
The watch is big , After segmentation, it can reduce the number of pages of data and index that need to be read during query , At the same time, pages reduce the number of levels of index , Increase the number of queries
- Applicable scenario
1) The data in the table itself is independent , For example, the sub table in the table records the data of various regions or different periods , In particular, some data are commonly used , Some data are not commonly used
2) Data needs to be stored on multiple media - The disadvantage of horizontal split
1) Add complexity to the application , Usually, multiple table names are required when querying , Querying all data requires UNION operation
2) In many database applications , This complexity will outweigh the benefits it brings , Query will increase the number of times to read an index layer disk
Here are two common solutions for database fragmentation :
- Client agent : Sharding logic at the application end , Packaged in jar In bag , By modifying or banning JDBC Layer to achieve . Dangdang. Com Sharding-JDBC, Ali's TDDL Are two common implementations
- Middleware agent : Add a proxy layer between application and data , Fragment logic is maintained in middleware services . What we are talking about now Mycat,360 Of Atlas, Netease's DDB And so on are the implementation of this architecture .
Problems faced after separating the tables
- Transaction support :
After the sub-library sub-table , It becomes a distributed transaction , If you rely on the distributed transaction management function of the database itself to execute transactions , It will cost a lot of performance , If the application helps control , To form a logical transaction , It will also cause the burden of transformation . - Cross Library JOIN
As long as it's segmentation , Cross node join The problem is inevitable , But good design and segmentation can reduce this kind of situation . The common way to solve this problem is to implement it in two queries , Find the associated data in the result set of the first query id, According to these id Initiate a second request to get the associated data . - Cross node count,order by,group by And aggregate function problems
These are questions , Because they all need to calculate based on all data sets , Most agents don't automatically handle the merge . Solution : And solve cross-border points join The problem is similar , After getting the results on each node, merge them on the application side . and join The difference is that each node query can be executed in parallel , Because many times its speed is much faster than a single big watch , But if the result set is large , Memory consumption for applications is a problem - Data migration , Capacity planning , Expansion, etc
These problems come from the external team of Taobao integrated business , It uses right 2 Multiple redundancy of has the feature of forward compatibility ( If yes 4 Take the rest 1 Get the number right 2 Taking the rest is also 1) To allocate data , Avoid row level data migration , But it still needs to be marked and not migrated , At the same time, there are restrictions on the scale of expansion and the number of sub tables , in general , These plans are not very ideal , There are problems , It reflects from the side Sharding The expansion is difficult . - ID problem
Once the database is partitioned to multiple physical nodes , We can no longer rely on the database's own primary key generation mechanism , One side , A partition database is automatically generated ID There is no guarantee that it is the only one in the overall situation ; On the other hand , Applications need to get... Before inserting data ID In order to carry out sql route , Some common primary key generation strategies :
UUID Use UUID Primary key is the simplest solution , But the disadvantages are also very obvious . because UUID Very long , In addition to taking up a lot of storage space , The main problem is the index , There are performance problems in both indexing and index based queries . Twitter Distributed self increasing ID Algorithm Snowflake In distributed systems , Need to generate a global UID There are many occasions ,twitter Of snowflake Solved this demand , The implementation is also very simple , Remove configuration information , The core code is millisecond time 41 position machine ID 10 position Sequence in milliseconds 12 position .
- Sort paging across tiles
In general , When paging, you need to sort according to the specified fields . When the sorting field is a fragment field , We can easily locate the specified fragment through the fragment rule , And when sorting fields that are not fragment fields , The situation will become more complicated . For the accuracy of the final result , We need to sort the data in different sharding nodes and return , The result sets returned by different segments are summarized and re sorted , And finally back to the user . As shown in the figure below :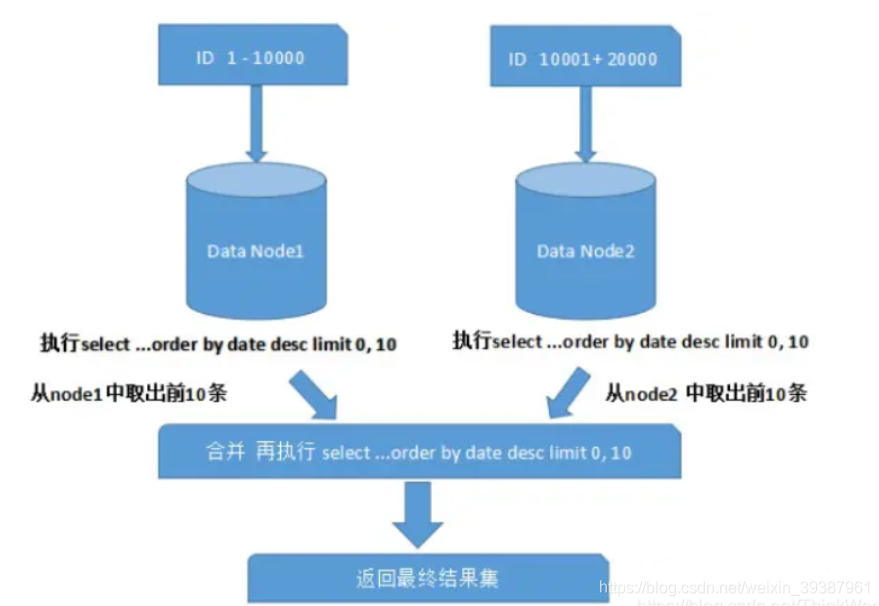
MySQL The principle and process of replication
Master slave copy : In the main database DDL and DML Operation through binary log (BINLOG) Transfer to the slave database , Then re execute these logs ( redo ); So that the data from the slave database is consistent with the master database .
The master-slave copy has the function
- There's a problem with the main database , You can switch to and from the database
- You can perform read-write separation at the database level
- Daily backup can be carried out on the slave database
Mysql The problem of master-slave copying the ending
- The data distribution : Start or stop copying at will , And distribute data in different geographical locations for backup
- Load balancing : Reduce the pressure on a single server
- High availability and fail over : Help applications avoid single point of failure
- Upgrade test : You can use a higher version Mysql As a slave Library
Mysql How master-slave replication works
- Copy and record the data on the main database to the binary log
- Copy the logs of the master database from the slave database to its own relay log
- Read relay log events from the library , Put it back in the slave library data
Basic principle flow ,3 Threads and their associations
- Lord :binlog Threads —— Record all statements that change database data , In the master Upper binlog in ;
- from :io Threads —— In the use of start slave after , In charge of from master Pull up binlog Content , Put it in your own relay log in ;
- from :sql Execute thread —— perform relay log The statement in ;
The copying process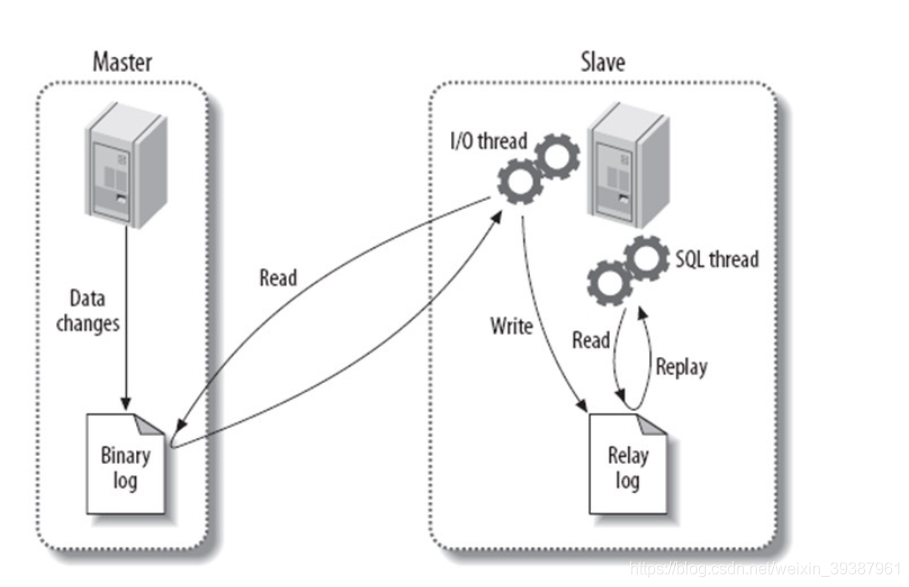
- Binary log: Binary log of main database
- Relay log: Relay logs from server
First step :master Before each transaction updates the data , Write the operation record serially to binlog In file .
The second step :salve To start a I/O Thread, The thread is in master Open a normal connection , The main job is binlog dump process. If the progress of the reading has kept up with master, Go to sleep and wait master Create new events .I/O The ultimate goal of the thread is to write these events to the relay log .
The third step :SQL Thread Will read the relay log , And execute... In the log in sequence SQL event , This is consistent with the data in the main database .
What are the solutions to read-write separation ?
Read write separation depends on master-slave replication , And master-slave replication serves for read-write separation . Because of master-slave replication requirements slave Can't write, can only read ( If the slave Perform write operations , that show slave status Will appear Slave_SQL_Running=NO, At this point, you need to synchronize manually as mentioned earlier slave).
Scheme 1
Use mysql-proxy agent
advantage : Direct implementation of read-write separation and load balancing , No need to change the code ,master and slave Use the same account number ,mysql Officials do not recommend the use of
shortcoming : Reduce performance , Unsupported transactionOption two
Use AbstractRoutingDataSource+aop+annotation stay dao The layer determines the data source .
If... Is used mybatis, You can separate reading and writing in ORM layer , such as mybatis Can pass mybatis plugin Intercept sql sentence , be-all insert/update/delete All visit master library , be-all select All visit salve library , So for dao The layers are transparent . plugin When implementing, you can select the master-slave database by annotation or analysis statement is read-write method . But there is still a problem , That is, transactions are not supported , So we need to rewrite it DataSourceTransactionManager, take read-only The transaction of is thrown into the read Library , The rest, read and write, are thrown into the writing library .Option three
Use AbstractRoutingDataSource+aop+annotation stay service The layer determines the data source , Can support transactions .
shortcoming : Class internal methods are passed through this.xx() When the methods are called to each other ,aop No interception , Special treatment is required .
Backup plan ,mysqldump as well as xtranbackup Implementation principle of
(1) Backup plan
It depends on the size of the library , Generally speaking 100G Library in , Consider using mysqldump To do it , because mysqldump More light and flexible , The backup time should be in the low peak period of the business , Full backup can be done every day (mysqldump The backup file is relatively small , Smaller after compression ).
100G The above Library , Consider using xtranbackup To do it , Backup speed is significantly faster than mysqldump Be quick . Generally, one full-time one week , The rest are backed up incrementally every day , The backup time is the low peak period of the business .
(2) Backup recovery time
Fast physical backup recovery , Slow recovery of logical backup
Here with the machine , Especially the speed of the hard disk has something to do with , The following list is for reference only
20G Of 2 minute (mysqldump)
80G Of 30 minute (mysqldump)
111G Of 30 minute (mysqldump)
288G Of 3 Hours (xtra)
3T Of 4 Hours (xtra)
The logic import time is generally the backup time 5 More than times
(3) How to deal with backup recovery failure
First of all, we should do enough preparations before recovery , Avoid errors in recovery . For example, check the validity after backup 、 Permission check 、 Space inspection, etc . In case of a wrong report , And then according to the error prompt to make the corresponding adjustment .
(4)mysqldump and xtrabackup Realization principle
mysqldump
mysqldump It's a logical backup . Join in –single-transaction Option to make a consistent backup . The background process will first set session Transaction isolation level of RR(SET SESSION TRANSACTION ISOLATION LEVELREPEATABLE READ), Then open a transaction explicitly (START TRANSACTION /*!40100 WITH CONSISTENTSNAPSHOT */), This ensures that the data read in the transaction is the snapshot of the transaction . Then read out the data of the table . If you add –master-data=1 Words , At the beginning, a database read lock will be added (FLUSH TABLES WITH READ LOCK), After opening the transaction , Record the database again at this time binlog The location of (showmaster status), Now unlock , Read the data of the table again . Wait until all the data has been exported , You can end the transaction
Xtrabackup:
xtrabackup It's a physical backup , Copy tablespace files directly , At the same time, continuous scanning produces redo Log it and save it . Finally completed innodb After the backup of , Will make a flush engine logs The operation of ( The old version is in the presence of bug, stay 5.6 If you do not do this operation, you will lose data ), Ensure that all redo log It's all down ( It involves two-phase commit of transaction
Concept , because xtrabackup Not copy binlog, So we have to make sure that all redo log All set , Otherwise, the data of the last set of committed transactions may be lost ). This time is innodb Time to complete backup , Data files are not consistent , But there was a time when redo You can make data files consistent ( What to do in recovery
love ). And then it needs flush tables with read lock, hold myisam Wait for other engine tables to be backed up , Unlock after backup . In this way, the perfect hot preparation .
What are the ways to repair data table corruption ?
Use myisamchk To repair , Specific steps :
1) Before repairing mysql Service stopped .
2) Open command line mode , And then into mysql Of /bin Catalog .
3) perform myisamchk –recover Database path /*.MYI
Use repair table perhaps OPTIMIZE table Order to fix ,REPAIR TABLE table_name Repair table OPTIMIZE TABLE table_name Optimization table REPAIR TABLE Used to repair damaged tables . OPTIMIZE TABLE Used to reclaim idle database space , When rows of data on a table are deleted , The occupied disk space is not immediately reclaimed , Used OPTIMIZE TABLE After the command, the space will be reclaimed , And rearrange the data rows on the disk ( Be careful : It's on disk , Not databases )
边栏推荐
- Kaggle竞赛-Two Sigma Connect: Rental Listing Inquiries
- Using LinkedHashMap to realize the caching of an LRU algorithm
- R & D thinking 01 ----- classic of embedded intelligent product development process
- MySQL realizes read-write separation
- Principle and implementation of MySQL master-slave replication
- Raspberry pie tap switch button to use
- E-commerce data analysis -- User Behavior Analysis
- Connexion sans mot de passe du noeud distribué
- Implementation scheme of distributed transaction
- Redis interview questions
猜你喜欢
MySQL数据库面试题
Basic use of pytest

Vert. x: A simple login access demo (simple use of router)
Togglebutton realizes the effect of switching lights
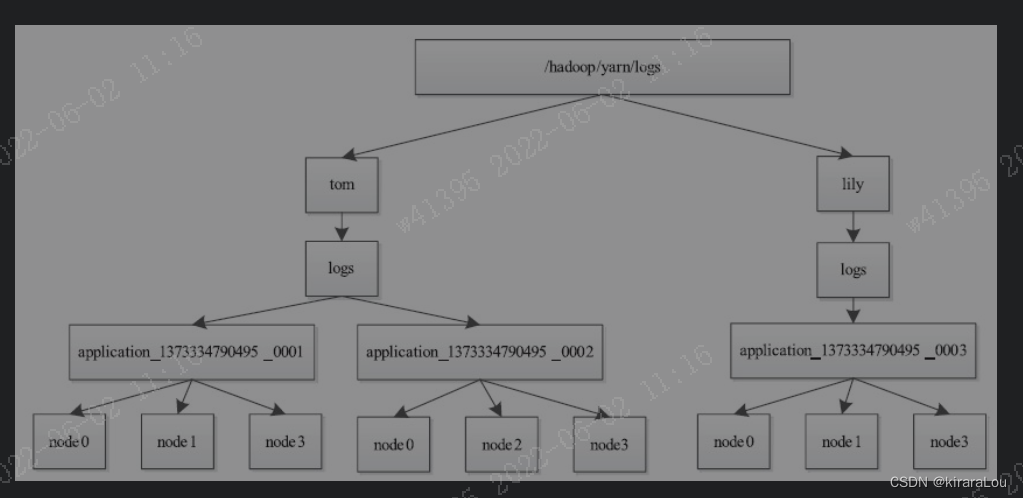
【yarn】Yarn container 日志清理

快来走进JVM吧
RT-Thread的main线程“卡死”的一种可能原因及解决方案
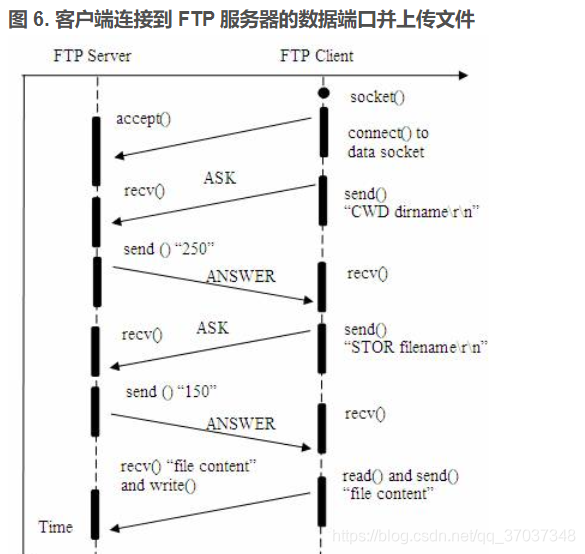
FTP file upload file implementation, regularly scan folders to upload files in the specified format to the server, C language to realize FTP file upload details and code case implementation

Apprentissage automatique - - régression linéaire (sklearn)
E-commerce data analysis -- User Behavior Analysis
随机推荐
XML file explanation: what is XML, XML configuration file, XML data file, XML file parsing tutorial
冒泡排序【C语言】
RT-Thread的main线程“卡死”的一种可能原因及解决方案
Mall project -- day09 -- order module
Correspondence between STM32 model and contex M
[BSidesCF_2020]Had_ a_ bad_ day
Niuke novice monthly race 40
Linux yum安装MySQL
DICOM: Overview
nodejs 详解
XML文件详解:XML是什么、XML配置文件、XML数据文件、XML文件解析教程
Distribute wxWidgets application
Software I2C based on Hal Library
【yarn】CDP集群 Yarn配置capacity调度器批量分配
TypeScript
ES6 promise object
Pytorch实现简单线性回归Demo
Solution to the practice set of ladder race LV1 (all)
FreeRTOS 任务函数里面的死循环
分布式事务的实现方案