当前位置:网站首页>[CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
[CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
2022-07-06 11:31:00 【kiraraLou】
Preface
Record CDH colony yarn Service task centralized allocation configuration does not take effect .
environmental information
- CDH 5.16
- Hadoop 2.6.0
- yarn Fair scheduling mode
The course of the problem
In recent days, , The system operation and maintenance feedback said that our big data cluster has a node (nodemanager) Memory usage exceeds the alarm threshold , Trigger alarm .
After troubleshooting, it is found that the computing node (nodemanager) And nodes (nodemanager) The load gap is large , I immediately thought of it because Yarn Batch allocation is enabled .
In addition, because our tasks are all flow computing tasks , Required for a single task container Not many . So it will aggravate this phenomenon . Some nodes have been used 175G Memory , Some nodes only 40G.
Solution steps
1. Refer to online solutions
here , We have located it Yarn Batch allocation is enabled , And our task type will aggravate this phenomenon . Let's solve this problem OK 了 .
Most of the online solutions are as follows :
Method 1 :
take yarn.scheduler.fair.assignmultiple Set to false.
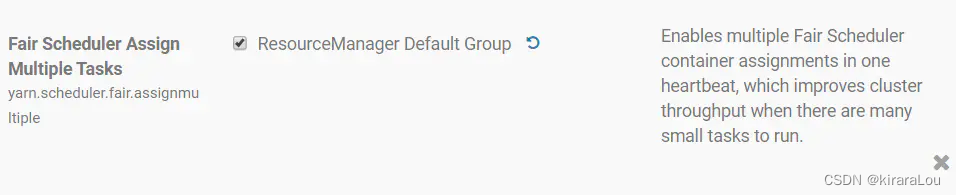
Method 2 :
- take
yarn.scheduler.fair.assignmultipleSet totrue.
- take
yarn.scheduler.fair.max.assignSet to A smaller value ( Such as 3 - 5).
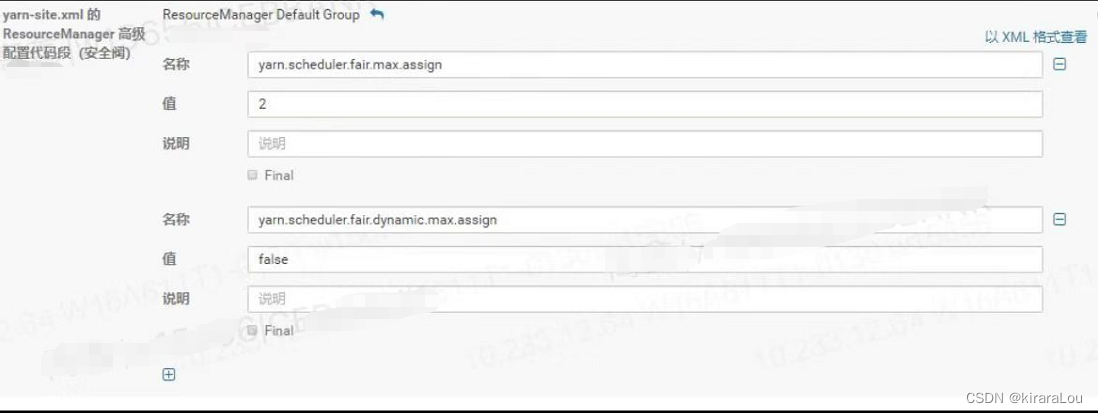
notes : This value depends on the number of its own computing nodes and the number of containers launched by the task , It is not a so-called fixed value .
2. Configuration does not work
Here we refer to method 2 , And then yarn.scheduler.fair.max.assign Set up in order to 2. It's restarted resource manager After service , Reschedule tasks , It was found that the configuration did not take effect , All of a single task container Are centrally scheduled to a node . Explain this batch allocation yarn.scheduler.fair.max.assign The configuration did not take effect .
So the test will yarn.scheduler.fair.assignmultiple Set to false. Then repeat the above operation , It was found that the function of batch allocation was indeed turned off , Under a task container Are divided into different nodes .
Here comes the problem , Also set up yarn.scheduler.fair.assignmultiple by true and yarn.scheduler.fair.max.assign by 2, Will not take effect at the same time .
3. Why ignore ?
After all kinds of searches , Finally found
from CDH 5.9 Start , For new clusters ( I.e. not from CDH 5.8 Upgrade to a higher version of CDH The cluster of ), No matter what is running in the cluster NodeManager How many , Continuous scheduling is disabled by default , namely yarn.scheduler.fair.continuous-scheduling -enabled Set to false,yarn.scheduler.fair.assignmultiple Set to true also yarn.scheduler.fair.dynamic.max.assign The default is also set to true.
We know from the above , about CDH 5.9 - Hadoop 2.6.0 For later versions ,yarn.scheduler.fair.dynamic.max.assign This configuration has been added to the service configuration by default , And for true , But for the open source version Hadoop Come on ,hadoop 2.6.0 No such configuration , But in hadoop 2.8.0 Later, this configuration was added .
Here, our previous reference configurations are the corresponding version configurations of the referenced open source version , So ignore yarn.scheduler.fair.dynamic.max.assign This configuration , As a result, the configuration did not take effect .
This also makes me understand ,CDH Version and The real difference between open source versions , Before, I just thought CDH Only the package is better , The code changes are not very big , Now it seems that there is some deviation in understanding .
Be careful : from C6.1.0 Start , Set up
yarn.scheduler.fair.dynamic.max.assignandyarn.scheduler.fair.max.assignstay Cloudera Manager China open , Therefore, no safety valve is required .
4. Final solution
in other words , For in C5.x Run in CDH 5.8 And higher ( Or from CDH 5.8 Upgrade to a higher version ) The cluster of :
- Attribute
yarn.scheduler.fair.assignmultipleSet totrue. - Optional : Attribute
yarn.scheduler.fair.dynamic.max.assignSet totrue. This requires the use of safety valves - ResourceManager Advanced Configuration Snippet (Safety Valve) for yarn-site.xml. - If you set
yarn.scheduler.fair.dynamic.max.assign, Even if the attribute is setyarn.scheduler.fair.max.assignIt's also ignored .
principle
Question why
FairScheduler Continuous scheduling takes too long on large clusters with many applications submitted or running . This may lead to ResourceManager There is no response , Because the time spent in continuous scheduling dominates ResourceManager The usability of .
As the number of applications increases and / Or the increase in the number of nodes in the cluster , Iterating over nodes can take a long time . Due to continuous scheduling, lock is obtained , This reduces ResourceManager In other functions ( Including regular container distribution ) The proportion of time spent on .
YARN The reason for the performance degradation
NodeManager -> ResourceManager heartbeat
stay YARN In the cluster , Every NodeManager(NM) Will regularly report to ResourceManager(RM) Send a heartbeat . These are based on yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
Property occurs periodically during this heartbeat , Every NM tell RM How much unused capacity , also FairScheduler One or more containers will be allocated in this NM Up operation . By default , The interval between heartbeats is 1 second ( The second 1 Heart rate ).
Heartbeat and container allocation
The number of containers allocated will depend on fair-scheduler.xml Set up . The flow chart is as follows :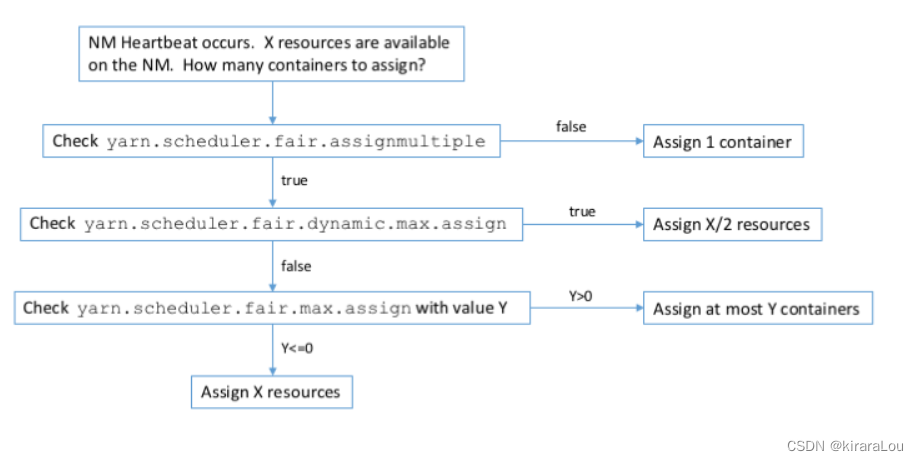
attribute yarn.scheduler.fair.dynamic.max.assign Is in CDH 5.9( and YARN-5035) Introduced in .
Continuously scheduled container allocation
Except for the routine ( Heartbeat based ) Outside the container distribution ,FairScheduler It also supports continuous scheduling . This can be done by attributes yarn.scheduler.fair.continuous-scheduling-enabled Turn on . When this property is set to true when , Will be in FairScheduler Start continuous scheduling .
For continuous scheduling , There is a separate thread that performs container allocation , And then according to the properties yarn.scheduler.fair.continuous-scheduling-sleep-ms Sleep for milliseconds .
stay CDH in , This value is set as the default 5 millisecond . During this period, non scheduling RM function .
Continuous scheduling is introduced , Reduce the scheduling delay to much lower than the default value of node heartbeat 1s. The continuous scheduling thread will perform scheduling by iterating over the submitted and running applications , At the same time, find free resources on the nodes in the cluster . This applies to small clusters . The scheduler can very quickly ( In a few milliseconds ) Traverse all nodes .
As the number of applications increases and / Or the increase in the number of nodes in the cluster , Iterating over nodes can take a long time . Because continuous scheduling will acquire locks , This reduces RM In other functions ( Including regular container distribution ) The proportion of time spent on .
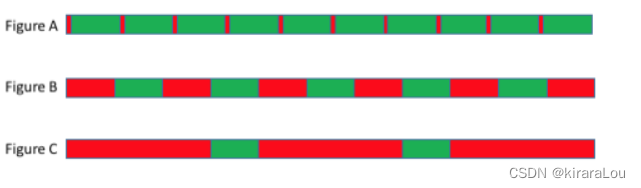
In the three figures above , We show the running time of continuously scheduled threads in red , The remaining RM Usability . On small and lightly loaded clusters ,RM Availability will be as shown in Figure A Shown . On larger and more heavily loaded clusters ,RM Availability will be more like figure B. This has shown RM Available only half the time . In the figure C On the heavily loaded cluster ,RM It may seem unresponsive , Because all the time can be spent on continuous scheduling . This may cause other clients ( for example :Cloudera Manager、Oozie etc. ) There is also no response .
summary :
- Continuous distribution is
yarnAn optimization of , It can speed up the container allocation and scheduling of tasks . - Continuous allocation can easily lead to unbalanced cluster load .
- It needs to be reasonably configured according to its own cluster size and computing task size , Don't let this optimization become " stumbling block ".
- attribute yarn.scheduler.fair.dynamic.max.assign Is in
CDH 5.9 - Hadoop2.6.0andOpen source Hadoop-2.8.0Introduced in .
Reference resources :
1. https://my.cloudera.com/knowledge/FairScheduler-Tuning-With-assignmultiple-and-Continuous?id=76442
2. https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
3. https://blog.csdn.net/nazeniwaresakini/article/details/105137788
边栏推荐
- Software testing and quality learning notes 3 -- white box testing
- 【flink】flink学习
- 搞笑漫画:程序员的逻辑
- Are you monitored by the company for sending resumes and logging in to job search websites? Deeply convinced that the product of "behavior awareness system ba" has not been retrieved on the official w
- wangeditor富文本组件-复制可用
- Attention apply personal understanding to images
- Solution of deleting path variable by mistake
- Error reporting solution - io UnsupportedOperation: can‘t do nonzero end-relative seeks
- Introduction and use of automatic machine learning framework (flaml, H2O)
- 基于apache-jena的知识问答
猜你喜欢
Django running error: error loading mysqldb module solution

Solve the problem of installing failed building wheel for pilot
【flink】flink学习
软件测试与质量学习笔记3--白盒测试
Install mongdb tutorial and redis tutorial under Windows
C语言读取BMP文件
AcWing 1298.曹冲养猪 题解

Kept VRRP script, preemptive delay, VIP unicast details
Dotnet replaces asp Net core's underlying communication is the IPC Library of named pipes
QT creator support platform
随机推荐
AcWing 179. Factorial decomposition problem solution
{one week summary} take you into the ocean of JS knowledge
[NPUCTF2020]ReadlezPHP
Number game
PHP - whether the setting error displays -php xxx When PHP executes, there is no code exception prompt
保姆级出题教程
vs2019 第一个MFC应用程序
QT creator uses Valgrind code analysis tool
Niuke novice monthly race 40
yarn安装与使用
QT creator specifies dependencies
01 project demand analysis (ordering system)
天梯赛练习集题解LV1(all)
[Bluebridge cup 2020 preliminary] horizontal segmentation
Codeforces Round #771 (Div. 2)
Vs2019 first MFC Application
What does BSP mean
基于apache-jena的知识问答
AcWing 242. A simple integer problem (tree array + difference)
Codeforces Round #771 (Div. 2)