当前位置:网站首页>分布式事务的实现方案
分布式事务的实现方案
2022-07-06 09:15:00 【乘风破BUG】
CAP定理
要看分布式事务先要了解CAP定理
CAP定理在分布式系统中就是:一致性,可用性,分区容忍性
- 一致性:分布式环境下多个节点得数据是否强一致
- 可用性:分布式服务能一致保证可用状态,当用户发出一个请求后,服务能在有限时间内返回结果
- 分区容忍性:特指对网络分区得容忍性
对于共享数据系统,最多只能同时拥有CAP其中得两个,没法三者兼顾
- 任两者得组合都有其适用场景
- 真实系统应当是ACID和BASE得混合体
- 不同类型得业务可以也应当区别对待
其中!分区容忍性是不可或缺得!!!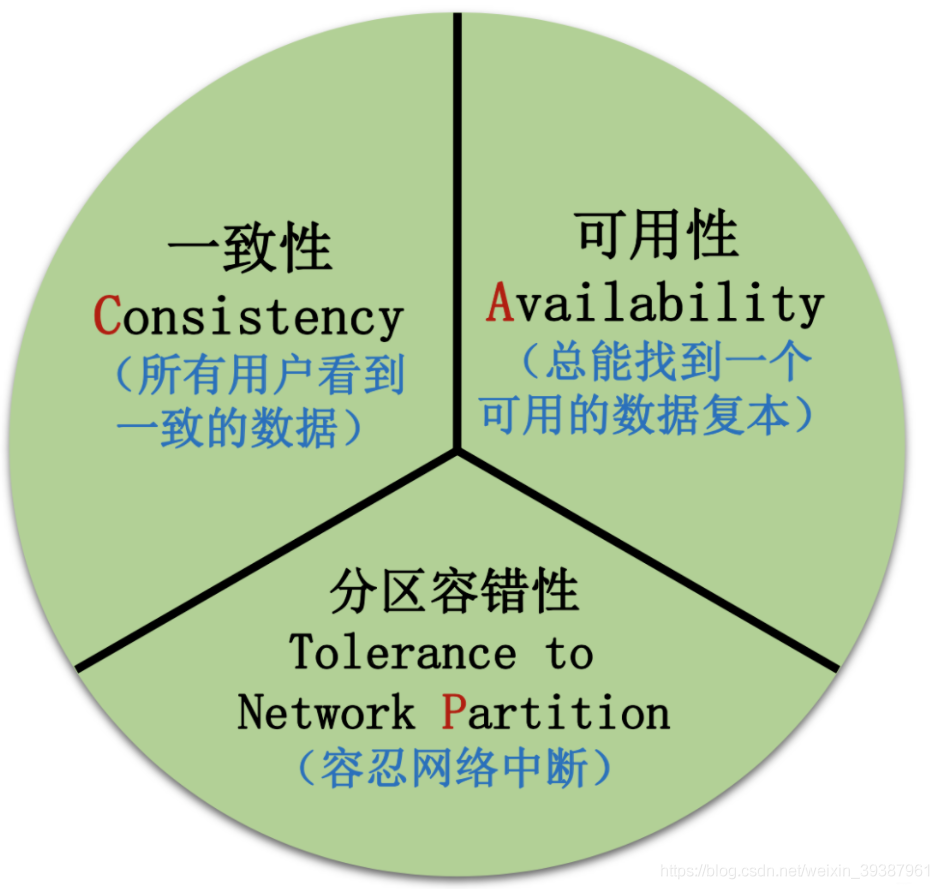
BASE理论
核心思想
- 基本可用(BasicallyAvailable)
分布式系统在出现故障时,允许损失部分得可用性来保证核心可用 - 软状态(SoftState)
允许分布式系统存在中间状态,该中间状态不会影响到系统的整体可用性 - 最终一致性(EventualConsistency)
分布式系统种的所有副本数据经过一定时间后,最终能够达到一致的状态
一致性模型数据的一致性模式可以分成以下3类:
- 弱一致性
数据更新成功后,任意时刻所有副本中的数据都是一致的,一般采用同步方式实现 - 最终一致性
弱一致性的一种形式,数据更新成功后,系统不承诺立即可以返回最新写入的值,但是保证最终会返回上一次更新操作的值
分布式系统数据的强一致性,弱一致性和最终一致性可以通过Quorum NRW算法分析
分布式的实现方案
主要有以下五种方案:
XA方案,TCC方案,本地消息表,可靠消息最终一致性方案,最大努力通知方案
XA方案(两阶段提交方案)
所谓XA方案也被称为两阶段提交,其中有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先询问各个数据库是否准备好了,如果每个数据库都回复OK,那么就正式提交事务,在各个数据库上执行操作,如果有任何其中一个数据回答不OK,那么就回滚事务
这种分布式事务方案,比较适合单块应用中,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景,如果要玩,那么基于Sprign+JTA就可以搞定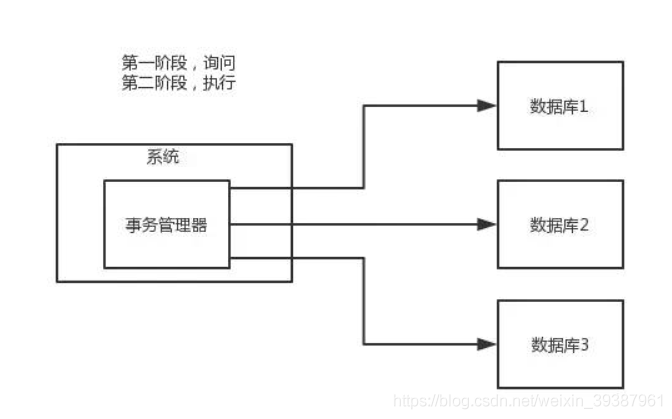
TCC方案
TCC全称是:Try ,Confirm,Cancel
- try阶段:这个阶段说的是对各个服务的资源做检查以及对资源进行锁定或者预留
- Confirm阶段:这个阶段说是在各个服务中执行实际的操作
- Cancel阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作(把那些执行成功的回滚)
这种方案目前很少人使用,但也有使用的场景,比如说一般跟钱相关,跟钱打交道的支付,交易相关的场景,就会用TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,保证在资金上不会出现问题。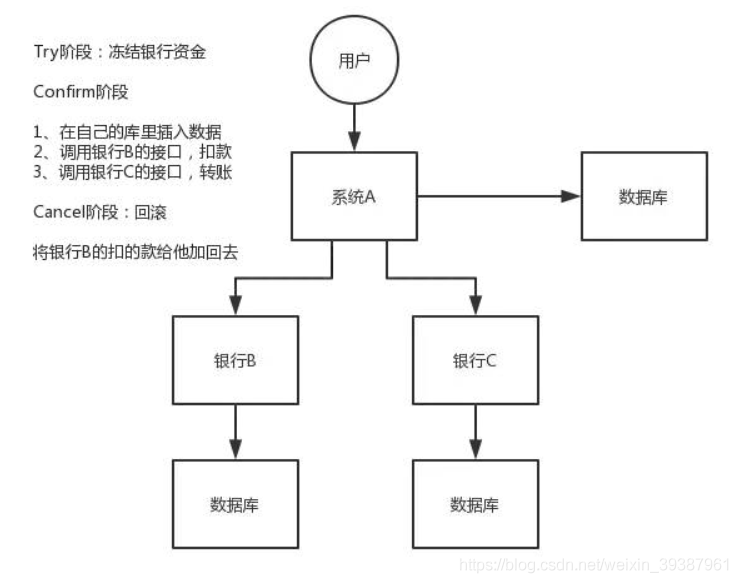
本地消息表
大概意思看下面:
- A系统在自己本地一个事务里操作的同时,插入一条数据到消息表
- 接着A系统将这个消息发送到MQ中去
- B系统接收到消息后,在一个事务里,往自己本地消息表里插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了,那么此时这个事务回滚,这样保证不会重复处理消息
- B系统执行成功之后,就会更新自己本地消息表的状态以及A系统消息表的状态
- 如果B系统处理失败了,那么就不会更新消息表状态,那么此时A系统会定时扫描自己的消息表,如果有未处理的消息,会再次发送到MQ中去,让B再次处理
- 这个方案保证了最终一致性,哪怕B事务失败了,但是A会不断重发消息,直到B那边成功为止
这方案存在的最大问题就在于严重欧冠依赖于数据库的消息表来管理事务,如果是高并场景咋办?很难进行扩展,所以一般较少使用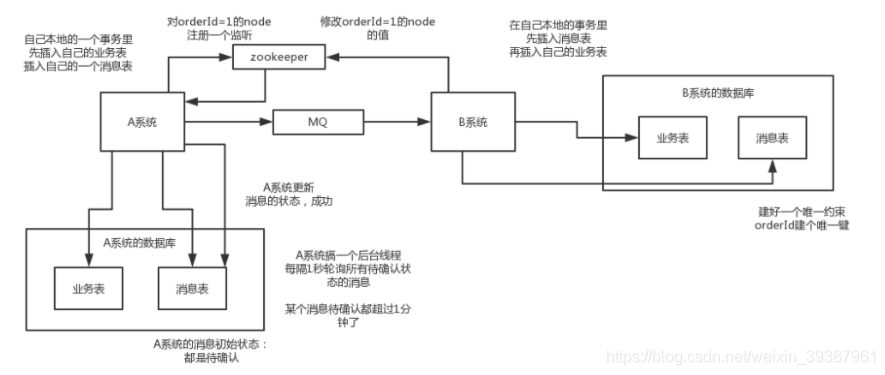
可靠消息最终一致性方案
这个方案就是不用消息表,直接基于MQ来实现事务,比如阿里的RocketMQ就支持消息事务
大概意思如下:
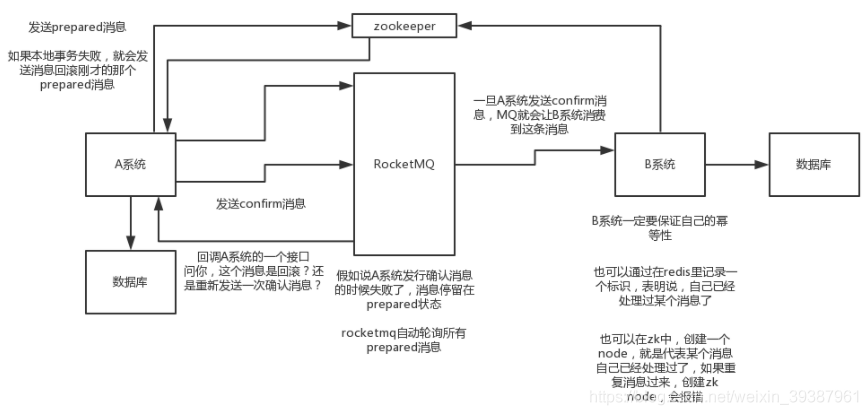
- A系统先发送一个prepared消息到MQ,如果这个prepared消息发送失败那么就直接取消操作别执行了
- 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉mq发送确认消息,如果失败就告诉mq回滚消息
- 如果发送了确认消息,那么此时系统B会接收到确认消息,然后执行本地的事务
- mq会自动定时轮询所有prepared消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所以没发送确认得消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚把,这个就是避免可能本地事务执行成功了,而确认消息却发送失败了
- 这个方案里,要是系统B得事务失败了呢?重试洛,自动不断重试直到成功,如果实在不行,要么就针对重要得资金类业务进行回滚,比如B系统本地回滚后,想办法通知系统A也回滚,或者是发送报警由人工来手工回滚和补偿
- 这个方案还是比较适合得,要不就直接使用RocketMq支持得,要么就自己基于ActiveMQ或者RabbitMQ自己封装一套这样得逻辑
最大努力通知方案
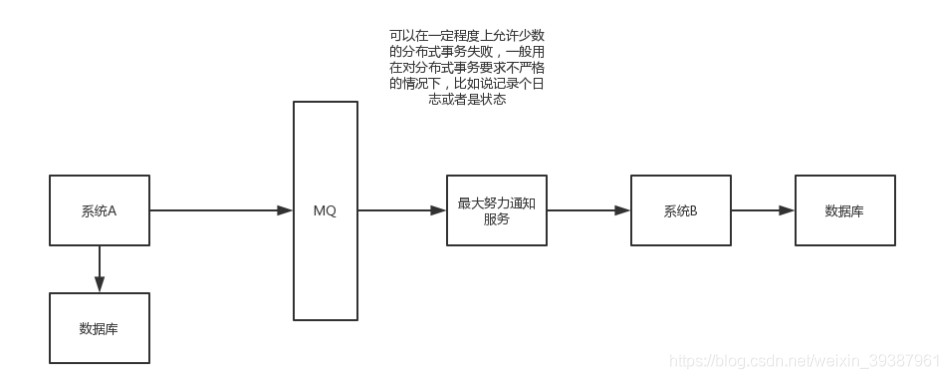
这个方案得大概意思如下
- 系统A本地事务执行完之后,发送个消息到MQ
- 这里会有个专门消费MQ得最大努力通知服务,这个服务会消费MQ然后写入数据库中记录下来,或者放入个内存队列也可以,接着调用系统B得接口
- 要是系统B执行成功就OK了,要是系统B执行失败了,那么最大努力通知服务就定时尝试重新调用系统B,反复N次,最后还是不行就放弃
边栏推荐
- [蓝桥杯2021初赛] 砝码称重
- Codeforces Round #771 (Div. 2)
- MongoDB
- 【yarn】Yarn container 日志清理
- 使用lambda在循环中传参时,参数总为同一个值
- 【CDH】CDH/CDP 环境修改 cloudera manager默认端口7180
- [Bluebridge cup 2021 preliminary] weight weighing
- Wangeditor rich text reference and table usage
- Integration test practice (1) theoretical basis
- UDS learning notes on fault codes (0x19 and 0x14 services)
猜你喜欢

保姆级出题教程

Stage 4 MySQL database

Password free login of distributed nodes
![[yarn] CDP cluster yarn configuration capacity scheduler batch allocation](/img/85/0121478f8fc427d1200c5f060d5255.png)
[yarn] CDP cluster yarn configuration capacity scheduler batch allocation
Django running error: error loading mysqldb module solution
Integration test practice (1) theoretical basis

Learn winpwn (3) -- sEH from scratch

One click extraction of tables in PDF

Rhcsa certification exam exercise (configured on the first host)
Picture coloring project - deoldify
随机推荐
Machine learning -- census data analysis
Kept VRRP script, preemptive delay, VIP unicast details
Database advanced learning notes -- SQL statement
AcWing 1294.樱花 题解
解决安装Failed building wheel for pillow
Antlr4 uses keywords as identifiers
天梯赛练习集题解LV1(all)
MySQL and C language connection (vs2019 version)
Julia 1.6 1.7 common problem solving
小L的试卷
Nanny level problem setting tutorial
2019腾讯暑期实习生正式笔试
數據庫高級學習筆記--SQL語句
Word排版(小计)
Mtcnn face detection
Project practice - background employee information management (add, delete, modify, check, login and exit)
error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_s instead
AcWing 1298. Solution to Cao Chong's pig raising problem
人脸识别 face_recognition
DICOM: Overview