当前位置:网站首页>4. Install and deploy spark (spark on Yan mode)
4. Install and deploy spark (spark on Yan mode)
2022-07-06 11:30:00 【@Little snail】
Catalog
- 4.1 Use the following command , decompression Spark Install package to user root directory :
- 4.2 To configure Hadoop environment variable
- 4.3 verification Spark install
- 4.4 restart hadoop colony ( Make configuration effective )
- 4.5 Get into Spark Install home directory
- 4.6 Installation and deployment Spark-SQL
- 4.6.1 take hadoop Install under directory hdfs-site.xml File copy to spark Install under directory conf Under the table of contents
- 4.6.2 take Hive The installation directory conf Under subdirectories hive-site.xml file , copy to spark Configuration subdirectory of
- 4.6.3 modify spark Configure... In the directory hive-site.xml file
- 4.6.4 take mysql Copy the connected driver package to spark The directory jars subdirectories
- 4.6.5 restart Hadoop Cluster and verify spark-sql; The figure below , Get into spark shell client , explain spark sql Configuration is successful
- 4.6.6 Press ctrl+d Composite key , sign out spark shell
- 4.6.7 if hadoop The cluster is no longer used , Please shut down the cluster
4.1 Use the following command , decompression Spark Install package to user root directory :
[[email protected] ~]$ cd /home/zkpk/tgz/spark/
[[email protected] spark]$ tar -xzvf spark-2.1.1-bin-hadoop2.7.tgz -C /home/zkpk/
[[email protected] spark]$ cd
[[email protected] ~]$ cd spark-2.1.1-bin-hadoop2.7/
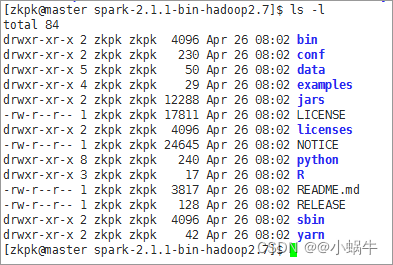
[[email protected] spark-2.1.1-bin-hadoop2.7]$ ls -l
perform ls -l The command will see the content shown in the following picture , These are Spark Included files :
4.2 To configure Hadoop environment variable
4.2.1 stay Yarn Up operation Spark Need configuration HADOOP_CONF_DIR、YARN_CONF_DIR and HDFS_CONF_DIR environment variable
4.2.1.1 command :
[[email protected] ~]$ cd
[[email protected] ~]$ gedit ~/.bash_profile
4.2.1.2 Add the following at the end of the file ; preservation 、 sign out
#SPARK ON YARN
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
4.2.1.3 Recompile file , Enable environment variables
[[email protected] ~]$ source ~/.bash_profile
4.3 verification Spark install
4.3.1 modify ${HADOOP_HOME}/etc/Hadoop/yarn-site.xml;
explain : stay master and slave01、slave02 Nodes should modify this file in this way
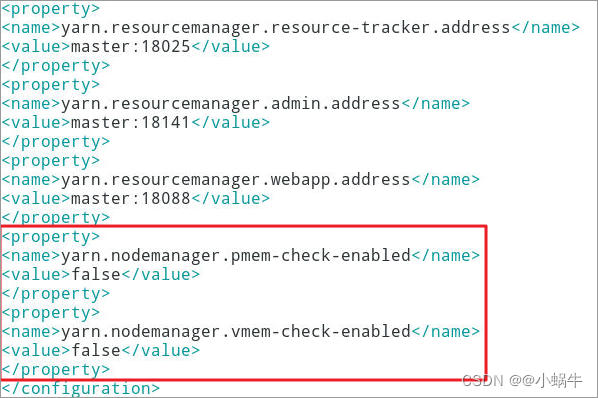
4.3.2 Add two property
[[email protected] ~]$ vim ~/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.4 restart hadoop colony ( Make configuration effective )
[[email protected] ~]$ stop-all.sh
[[email protected] ~]$ start-all.sh
4.5 Get into Spark Install home directory
[[email protected] ~]$ cd ~/spark-2.1.1-bin-hadoop2.7
4.5.1 Execute the following command ( Notice this is 1 Line code ):
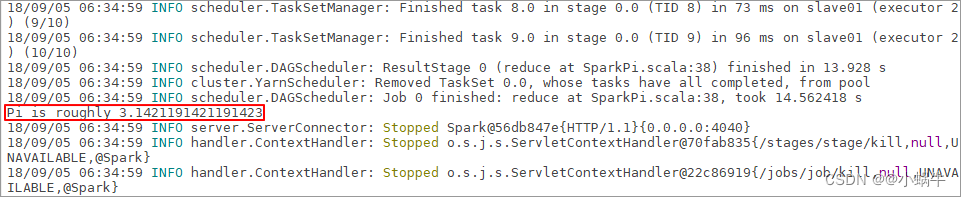
[[email protected] spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
4.5.2 After executing the command, the following interface will appear :
4.5.3Web UI verification
4.5.3.1 Get into spark-shell Interactive terminal , The order is as follows :
[[email protected] spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-shell
4.5.3.2 Open the browser , Enter the following address , View the operation interface ( Address :http://master:4040/)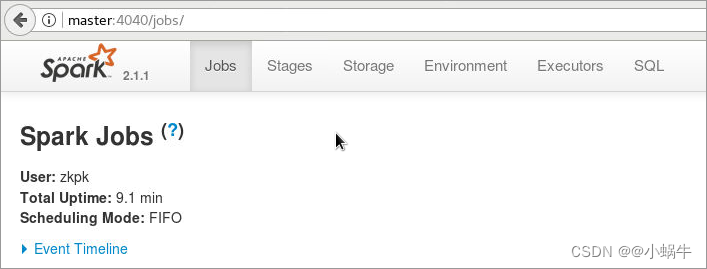
4.5.3.3 Exit interactive terminal , Press ctrl+d Composite key
scala> :quit
4.6 Installation and deployment Spark-SQL
4.6.1 take hadoop Install under directory hdfs-site.xml File copy to spark Install under directory conf Under the table of contents
[[email protected] spark-2.1.1-bin-hadoop2.7]$ cd
[[email protected] ~]$ cd hadoop-2.7.3/etc/hadoop/
[[email protected] hadoop]$ cp hdfs-site.xml /home/zkpk/spark-2.1.1-bin-hadoop2.7/conf
4.6.2 take Hive The installation directory conf Under subdirectories hive-site.xml file , copy to spark Configuration subdirectory of
[[email protected] hadoop]$ cd
[[email protected] ~]$ cd apache-hive-2.1.1-bin/conf/
[[email protected] conf]$ cp hive-site.xml /home/zkpk/spark-2.1.1-bin-hadoop2.7/conf/
4.6.3 modify spark Configure... In the directory hive-site.xml file
[[email protected] conf]$ cd
[[email protected] ~]$ cd spark-2.1.1-bin-hadoop2.7/conf/
[[email protected] conf]$ vim hive-site.xml
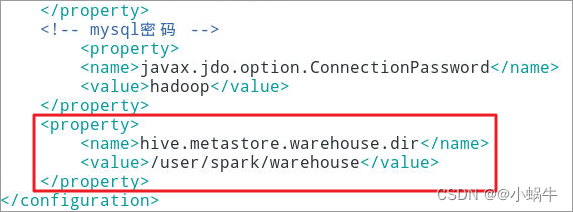
4.6.3.1 Add the following properties
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/spark/warehouse</value>
</property>
4.6.4 take mysql Copy the connected driver package to spark The directory jars subdirectories
[[email protected] conf]$ cd
[[email protected] ~]$ cd apache-hive-2.1.1-bin/lib/
[[email protected] lib]$ cp mysql-connector-java-5.1.28.jar /home/zkpk/spark-2.1.1-bin-hadoop2.7/jars/
4.6.5 restart Hadoop Cluster and verify spark-sql; The figure below , Get into spark shell client , explain spark sql Configuration is successful
[[email protected] lib]$ cd
[[email protected] ~]$ stop-all.sh
[[email protected] ~]$ start-all.sh
[[email protected] ~]$ cd ~/spark-2.1.1-bin-hadoop2.7
[[email protected] spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-sql --master yarn

4.6.6 Press ctrl+d Composite key , sign out spark shell
4.6.7 if hadoop The cluster is no longer used , Please shut down the cluster
[[email protected] spark-2.1.1-bin-hadoop2.7]$ cd
[[email protected] ~]$ stop-all.sh
边栏推荐
- 01 project demand analysis (ordering system)
- Codeforces Round #753 (Div. 3)
- L2-004 这是二叉搜索树吗? (25 分)
- [蓝桥杯2017初赛]包子凑数
- When you open the browser, you will also open mango TV, Tiktok and other websites outside the home page
- ES6 let 和 const 命令
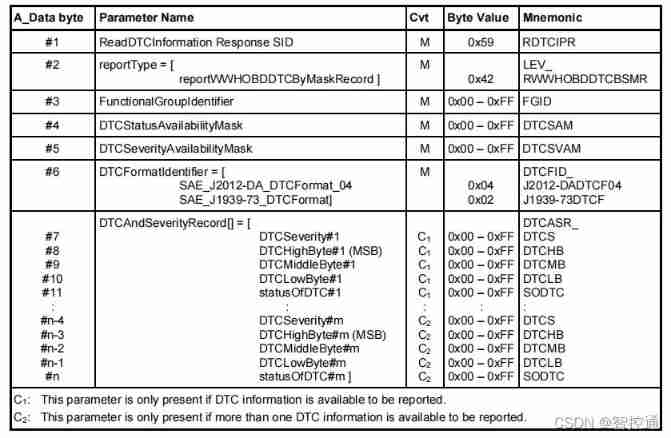
- UDS learning notes on fault codes (0x19 and 0x14 services)
- Punctual atom stm32f103zet6 download serial port pin
- L2-004 is this a binary search tree? (25 points)
- 引入了junit为什么还是用不了@Test注解
猜你喜欢

Classes in C #
vs2019 桌面程序快速入门
QT creator specify editor settings
图片上色项目 —— Deoldify
UDS learning notes on fault codes (0x19 and 0x14 services)
学习问题1:127.0.0.1拒绝了我们的访问
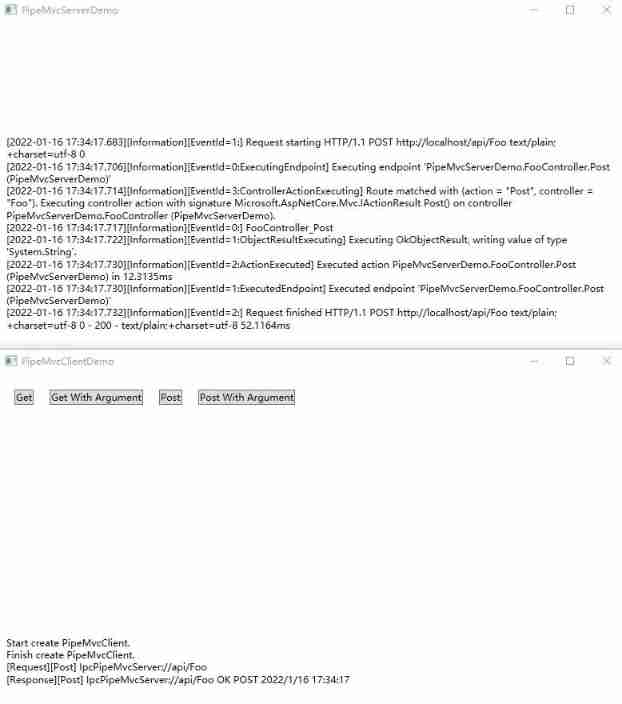
Dotnet replaces asp Net core's underlying communication is the IPC Library of named pipes
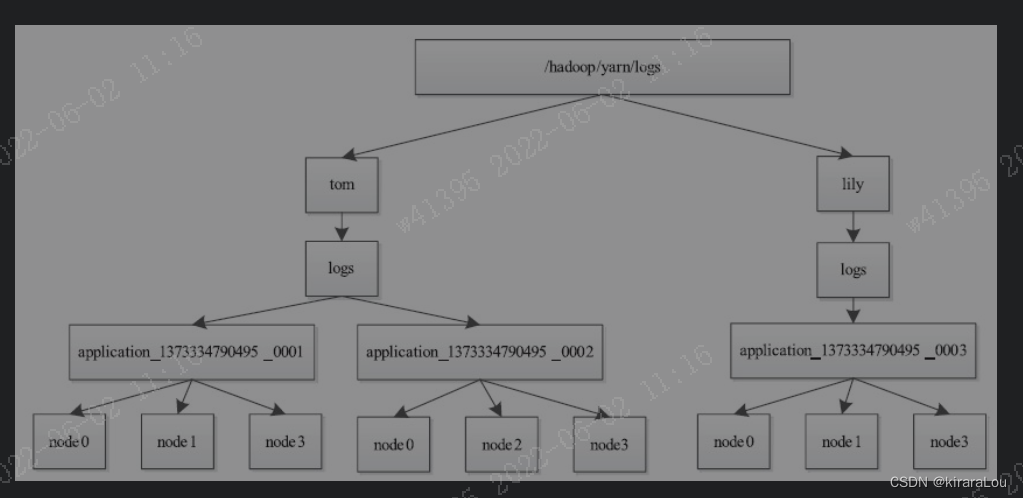
【yarn】Yarn container 日志清理

Learn winpwn (3) -- sEH from scratch

Nanny level problem setting tutorial
随机推荐
Knowledge Q & A based on Apache Jena
AcWing 1298. Solution to Cao Chong's pig raising problem
Machine learning notes week02 convolutional neural network
Introduction to the easy copy module
基于apache-jena的知识问答
数数字游戏
Codeforces Round #753 (Div. 3)
Reading BMP file with C language
QT creator test
[NPUCTF2020]ReadlezPHP
Antlr4 uses keywords as identifiers
Solve the problem of installing failed building wheel for pilot
库函数--(持续更新)
express框架详解
Machine learning -- census data analysis
引入了junit为什么还是用不了@Test注解
In the era of DFI dividends, can TGP become a new benchmark for future DFI?
L2-007 家庭房产 (25 分)
ES6 promise object
Vs2019 desktop app quick start