当前位置:网站首页>超标量处理器设计 姚永斌 第10章 指令提交 摘录
超标量处理器设计 姚永斌 第10章 指令提交 摘录
2022-07-07 09:51:00 【岐岇】
10.1 概述
在超标量处理器中,指令在处理器内部执行的时候,是不会按照这种严格的串行方式执行的。但是处理器想要正确地执行程序,就必须按照程序中串行顺序,则一般在超标量流水线中增加最后一级阶段,称为提交commit。
当一条指令到达提交阶段后,会将这条指令在重排序缓存中标记为已完成的状态,需要注意的是,这个状态只表示这条指令已经计算完毕,并不表示它可以离开流水线。
只有在重排序缓存中最旧的那条指令变为已完成的状态时,这条指令才允许离开流水线,并使用它的结果对处理器的状态进行更新,此时称这条指令退休retire了。从这个过程可以看出,一条指令可能需要在流水线的提交等待一段时间,才可以从流水线中退休,而重排序缓存是完成这个功能的关键部件,因此它也是流水线的提交阶段最重要的一个部件。
由于分支预测失败和异常等原因,到达提交阶段的指令并不一定代表这条一定是正确的。
只有这条指令之前进入到流水线中的所有指令退休了,并且这条指令已经处于已完成的状态时候,它才可以退休而离开流水线。
在一条指令没有退休之前,它的状态都是推测的,只有这条指令真正退休而离开流水线的时候,才可以将它的结果更新到处理器的状态中国,这样即使有分支预测失败或者异常,也不会将错误状态暴露给程序员。
流水线的分发阶段是处理器从顺序执行到乱序执行的分界点,那么,流水线的提交阶段又将处理器从乱序状态拉回到顺序执行的状态了。不管超标量处理器内部发生了怎样的事情,从处理器外部看来,它总是按照程序中指定的顺序执行的,任何预测技术所产生的错误,在处理器内部都会解决掉,不会将这些错误的状态表现出来。
维持程序执行的串行性,也是精确异常所要求的,精确异常的定义是当一条指令发现异常时,这条指令前面的所有指令都已经完成,而这条指令及其后面的所有指令都不应该改变处理器的状态。
对于一个N-way的超标量处理器来说,流水线的提交阶段每周期至少需要将N条指令退休,这样才能保证流水线不会被堵塞。
10.2 重排序缓存
10.2.1 一般结构
ROB本质是一个FIFO,它当中存储了一条指令的相关信息,例如这条指令的类型,结果,目的寄存器和异常的类型。
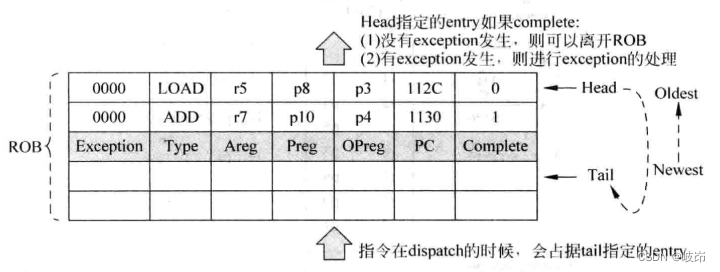
ROB的容量决定了流水线最多同时执行的指令个数,表项的内容包括
(a)Complete:表示一条指令是否已经执行完毕;
(b)Areg:指令在原始程序中指定的目的寄存器,它以逻辑寄存器的形式给出;
(c)Preg:指令的Areg经过寄存器重命名之后,对应的物理寄存器编号;
(d)OPreg:指令的Areg被重命名新的Preg之前,对应的旧的Preg,当指令发生异常而进行状态恢复时,会使用到这个值;
(e)PC:指令对应的PC值,当一条指令发生中断或者异常时,需要保存这条指令的PC值,以便能够重新执行程序;
(f)Exception:如果指令发生了异常,会将这个异常的类型写到这里,当指令要退休时候,会对这个异常进行处理;
(g)Type:指令的类型会被记录在此,当指令要退休时候,不同类型的指令会有不同的动作,例如store指令要写D-Cache,分支指令要释放Checkpoint。
指令一旦在流水线分发阶段占据了ROB中的一个表项,这个表项的编号会一直随着这条指令在流水线中流动,这样指令在之后的任何时刻,都可以知道如何在ROB中找到自己。
一条指令一旦变为ROB中最旧的指令,使用head pointer来指示最旧的指令,并且它的complete状态位也为1,就表示这条指令已经具备退休的条件了。
一般而言,在流水线的分发阶段,每周期最多可以进入ROB的指令个数会等于ROB每周期最多可以退休的指令个数,这样可以保证流水线的畅通。
10.2.2 端口要求
处理器在执行过程中,从ROB中最旧的一些指令中(由head pointer指定),选择那些已经变味complete状态,使其从流水线中退休。
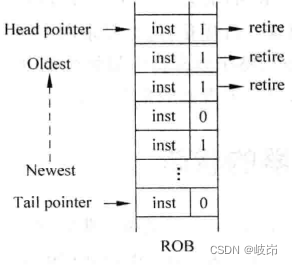
需要对ROB中最旧的指令开始连续的四个complete信号进行判断,如果某个complete信号为0,那么它后面的所有指令都不允许在本周期退休。
对于一个4-way的超标量处理器来说,ROB至少需要支持4个读端口,但是这远远不是ROB真正需要的端口个数,流水线的其他阶段还对ROB有着端口需求,它和处理器所采用的架构有关系,如果处理器采用ROB进行寄存器重命名的方式,此时对ROB的端口需求是最多的,这些端口包括:
(a)在流水线的寄存器重命名阶段,需要从ROB中读取4条指令的源操作数,因此需要ROB至少支持8个读端口。
(b)在流水线的分发阶段,需要向ROB写入四条指令,因此需要ROB支持4个写端口。
(c)在流水线的写回阶段,需要向ROB写入最少4条指令,之所以使用最少的这个词,是因为很多处理器的issue width要大于machine width,处理器会放置更多的FU来提高运算的并行度,这样导致每周期运算得到的结果要打4个。
ROB需要支持12个读端口和最少8个写端口,这种多端口的FIFO在面积和延迟方面很难进行优化,这也是采用ROB进行寄存器重命名的架构所面临的最大问题之一;ROB会成为处理器中最繁忙的部件。
10.3 管理处理器的状态
在超标量处理器内部有两个状态,一个是指令集定义的状态,例如通用寄存器的值,PC值以及存储器的值,将这个状态称为Architecture state;还有一个状态时超标量处理器内部的状态,例如重命名使用的物理寄存器、重排序缓存、发射队列和store buffer等部件的值,这些状态是处理器在运行过程中产生的,由于乱序执行的原因,它总是超前于指令集定义的状态。将处理器内部的状态称为speculative state。一条指令只有在退休的时候才会更新处理器中指定集定义的状态,就好像处理器使按照串行的顺序执行程序一样。
只有一条指令满足退休条件,变为ROB中最旧的指令,已经处于complete状态,并且没有异常发生,这才能够将这条指令对应的处理器内部状态更新到指令集定义的状态中。
逻辑寄存器之外的其他寄存器都属于处理器内部状态,都不应该从处理器外部看到。除了指令集定义的资源,例如PC寄存器、存储器或者通用寄存器等部件来说,其他的资源都属于处理器内部的状态。
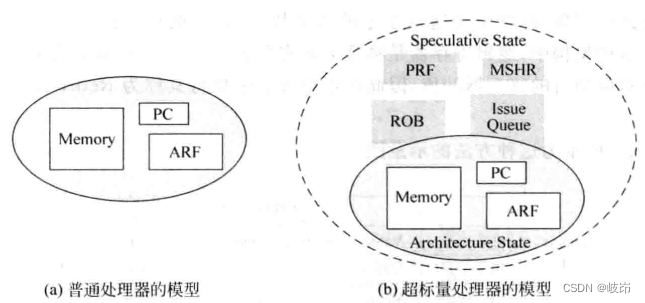
对于指令集中定义的绝大部分指令,都会更改处理器的状态,例如普通的运算指令改变通用寄存器的值,访问存储器的指令改变存储器和通用寄存器的值,分支指令改变PC寄存器的值。
例如对于采用将通用寄存器扩展为寄存器重命名的架构,需要将目的寄存器的值从物理寄存器搬移到通用寄存器;对于采用统一的物理寄存器进行重命名的架构需要将目的寄存器在物理寄存器堆中标记为外界可见的状态;store指令需要将Store buffer中对应的值写到D-Cache中;分支指令预测失败进行状态恢复,并且抛弃掉流水线中错误的指令,重新从正确的地址开始取指令,将它所占用的checkpoint资源进行释放;异常指令则会使处理器抛弃流水线当中所有指令,跳转到相应的异常处理程序的入口。
在超标量处理器中,根据架构的不同,会对应着不同的方法来管理指令集定义的状态,主要两种方法:
(a)使用ROB管理指令集定义的状态;
(b)使用物理寄存器管理指令集定义的状态
10.3.1 使用ROB管理指令集定义的状态
对于采用ROB进行寄存器重命名的架构,一条指令在没有退休之前,都会使用ROB来保存指令的结果,当指令退休的时候,这条指令的结果可以对指令集定义的状态进行更新,此时会将这条指令的结果从ROB中搬移到指令集定义的逻辑寄存器中。在这种架构中,逻辑寄存器是物理上真实存在的,由于在逻辑寄存器中存储了所有退休的指令对应的目的寄存器的值,因此这种方法也被称为Retire Register File,简称RRF。
ROB包括了两个主要部分,即指令信息和指令结果。在指令信息中记录了指令的类型、指令执行的状态以及指令的目的寄存器等内容,在指令结果中记录了指令产生的结果。
这种设计本质上利用ROB作为物理寄存器,可以直接将4条指令在ROB的地址作为它们经过寄存器重命名之后的物理寄存器,因此使用ROB来管理指令集定义的状态,可以简化寄存器重命名的过程。
在一般情况下,使用ROB来管理指令集定义的状态,都会对应着使用数据捕捉的结构来发射,因为在这种方法中,当一条指令退休的时候,需要将这条指令的结果从ROB中搬移到通用寄存器中,以后的指令如果想要使用这条指令的结果,就需要从通用寄存器中进行读取。这样,一个寄存器在它的生命周期内会存在两个地方,如果使用数据捕捉的方法,当一条指令的结果在流水线的执行阶段被计算出来之后,会将这个结果送到旁路网络中,这样payload RAM就可以捕捉到这个结果,也就是说,在发射队列中,所有使用这个结果作为操作数的指令都会得到这个值,这些指令被仲裁电路选中的时候,直接从payload RAM就可以得到所有源寄存器数了,而不需要关心这个寄存器此时是在ROB中还是通用寄存器中。因此,payload RAM是采用数据捕捉结构的必要部件,当指令被进行重命名的时候,会访问重命名映射表,如果发现源寄存器的值已经被计算出来,那么直接可以从ROB或者通用寄存器中读取这个值,然后写到payload RAM中,等待从旁路网络中捕捉这个值。如果这个寄存器的值还没有被计算出来,就将这个寄存器在ROB中的地址写到payload RAM中,等待从旁路网络捕捉这个值。
使用ROB进行寄存器重命名,并管理指令集定义的状态,是和数据捕捉的发射方式正好匹配的。
10.3.2 使用物理寄存器管理指令集定义的状态
这种方式使用一个统一的物理寄存器堆,指令集中定义的所有逻辑寄存器都混在这个寄存器堆中。当然,未来进行寄存器重命名,在它当中包含了更多的寄存器,当一条指令被寄存器重命名之后,它的目的寄存器就和一个物理寄存器产生了对应关系,优点在于:
(a)当指令从ROB中退休的时候,不需要将指令的结果进行搬移,它仍旧会存在于物理寄存器中,也就是说,一旦指令的源操作数被确定存在那个地方,以后就不会再变化了,这样便于处理器实现低功耗设计。
(b)在基于ROB进行状态管理的方式中,需要从ROB中开辟空间来存放指令的结果,但是在程序中,有相当一部分的指令并没有目的寄存器,例如store指令,比较指令和分支指令,因此ROB中会有一部分空间是浪费的。使用物理寄存器进行状态管理则避免了这样的问题。这种方式只对目的寄存器的指令分配空间,其他不存在的目的寄存器的指令,不会对应任何物理寄存器。因此使用这种方式,占用的物理寄存器个数小于此时ROB中指令的个数。
(c)ROB是一个集中管理的方式,所有指令都需要从中读取操作数,同时所有的指令也需要将结果写到其中,再加上ROB空间的占用和回收都需要读写端口的支持,因此这需要大量的读写端口,会使得ROB变得非常臃肿,严重拖累处理器的速度。
缺点是:造成寄存器重命名的过程比较复杂,在使用ROB进行状态管理的时候,只需要将一条指令写入到ROB就可以完成重命名的过程,当这条指令顺利地离开流水线的时候,就自然释放了这个映射关系,而使用物理寄存器进行状态管理的方式中,需要一个额外的表格来存放那些物理寄存器是空闲的,并且重命名映射的关系建立和释放过程都是比较复杂的。
10.4 特殊情况的处理
由于现代超标量处理器采用了很多预测方法来执行指令,并不是流水线中所有的指令都可以退休,例如分支预测失败和异常。在流水线的提交阶段需要重点关注的指令还有store指令,由于它只有在退休的时候才可以真正地改变处理器的状态。
10.4.1 分支预测失败的处理
发现分支预测失败后,处理器的状态恢复的过程可以分为两个独立的任务,前端的状态恢复和后端的状态恢复,它们是以流水线的寄存器重命名阶段为分界的。前端的状态恢复是比较简单的,只需要将流水线中重命名阶段之前的所有指令都抹掉,将分支预测推测其中历史状态表进行恢复,并使用正确的地址来取指令即可;后端恢复复杂一点,需要将处理器的所有内部组件,例如issue queue、store buffer,和ROB等错误的指令都抹掉,还需要将重命名映射表RAT进行恢复,以便将那些错误的指令对RAT的修改进行修正,同时被错误的指令所占据的物理寄存器和 ROB的空间也需要被释放。
当发现分支预测失败时,大部分的恢复任务都是对寄存器重命名的相关部件进行的,因为大部分错误错误路径上的指令都经过了这一步。重命名方式的修复如下:
(1)在基于ROB进行重命名的架构中进行状态修复
在基于ROB进行寄存器重命名的架构中,存在一个真正的寄存器堆,它和指令集中定义的所有寄存器是一一对应的,它成为ARF。
一条退休的指令将目的寄存器的值从ROB搬移到ARF中,并不一定表示以后的指令就需要从ARF中读取这个寄存器的值。
在ROB中的每条指令都会检查自身是否是最新的映射关系,只有当一条指令从ROB中退休的时候,发现自身也是最新的映射关系,这样才能将RAT中对应的内容改为ARF状态。
从ROB中退休的一条指令如何才能检查自身是不是最新的映射关系呢?可以在这条指令退休的时候,使用它的目的寄存器来读取RAT,读出这个逻辑寄存器此时对应的ROB pointer。
在流水线中发现分支预测失败时,此时流水线中有一部分指令时分支指令之前进入流水线的,它们可以继续被执行,因此但发现分支指令预测失败时,并不马上进行状态修复,而是停止取新的指令,让流水线继续执行,这个过程称为将流水线抽干drain out。
这种基于ROB进行寄存器重命名的方法,不仅重命名过程本身易于实现,当分支预测失败时进行的状态恢复也是比较简单的,硬件小高也比较少。
(2)在基于统一的PRF进行重命名的架构中进行状态修复
在这种架构中,流水线中存在两个重命名映射表,一个在流水线的寄存器重命名阶段使用,它的状态时推测的,称作前段RAT;另一个是在流水线提交阶段使用的,所有从流水线中退休的指令,如果它存在目的寄存器,都会更新这个表格,因此它永远都是正确的,称它为后端RAT。
等到分支指令之前的进入到流水线的指令(包括分支指令本身)都顺利地离开流水线的时候,此时在流水线中所有的指令都是处在错误的路径上,可将流水线中所有指令全部抹掉,然后将后端RAT全部复制到寄存器重命名阶段使用的RAT,这就完成了RAT状态恢复,此时就可以从正确的地址开始取地址执行。
也会遇到当分支指令之前存在D-Cache miss指令,分支指令等待时间过长而导致分支预测失败的惩罚过大的情况。
如果在流水线中发现分支预测失败时,可以马上进行状态恢复,而不需要等待分支指令从流水线中退休,这样就加快速度,从而减少惩罚。
使用checkpoint的方法可以快速进行状态恢复,这种方法会在每条分支指令改变处理器的状态之前,将处理器的状态保存起来,例如在分支指令以后后面的指令对重命名映射表更改之前,将这个表格的内容保存起来,这样在以后的时间发现分支预测失败的分支指令时,可以使用这条分支指令的编号到流水线中错误路径上的指令都抹掉,同时使用checkpoint资源将处理器的状态进行恢复,然后就可以从正确路径上取指令执行了。
分支指令个数很可能增加,但是checkpoint个数很难随之增加。解决方法是对那些分支进行checkpoint也进行预测,因为很多分支指令的预测正确率很高,为它分配checkpoint资源,绝大部分时间都是浪费的。
当一条分支指令没有分配checkpoint资源,但是最后发现这条分支预测失败时,如何对处理器进行状态恢复,当然可以等待这条分支指令退休的时候。利用ROB将重命名映射表进行恢复了,较之使用checkpoint方法,这种方法肯定慢很多,但是它对硬件的消耗比较少,可以作为一种补充方法。
10.4.2 异常的处理
需要一种方法来记录所有指令的异常,然后按照指令在程序中原始顺序对所有异常进行处理,能够胜任这个任务的,就是重排序缓存。
为了能够按照正确的顺序处理异常,一条指令的异常要被处理,必须保证在它之前的所有资料的异常都已经被处理完成了,最容易实现这个任务的时间点就是在一条指令将要退休的时候,此时这条指令之前的所有指令都已经顺利地离开流水线。
对精确异常处理完后,可以精确地返回,返回的地方可能有两种情况,可以返回到发生异常的指令本身,重新执行这条指令,也可以不重新执行这条发生异常的指令,而是返回到它的下一条指令开始执行。
在跳转到相应的异常处理程序之前,需要将流水线中这条产生异常的指令后面的所有指令都抹去,并将它们对处理器状态的修改进行恢复,就好像这些指令从来没有发生过一样。
当一条指令要从ROB中退休之前,如果发现它在之前记录过异常的发射,此时ROB中所有其实都不允许退休而改变处理器的状态。
Recovery at Retire的异常处理方法还有一个好处,那就是很多指令的异常并非真的需要被处理,如果这些指令处于分支预测失败的路径上,它们都会从流水线中被抹掉,因此它们的异常其实都是无效的。
另一种修复过程是基于重排序缓存来进行的,从ROB中最新写入的指令开始,逐个将每条指令对应旧的映射关系写到重命名映射表中,这样就可以将这个表格进行状态恢复了,这个方法就是前文提到的WALK。
在使用统一的PRF进行寄存器重命名的方式中,和RAT相关的内容还有两个表格,一个表格用来存储那些物理寄存器是空闲状态的,称为Free Register Pool;另一个表格用来存储每个物理寄存器的值是否已经被计算出来,称为Busy Table。当异常发生时,这两个部件也需要进行恢复。
对于异常发生时的处理器来说,如果采用ROB进行重命名架构,使用Recovery at Retire方式是合适的,而对于采用统一的PRF进行重命名的架构,则需要使用WALK方法。
相比于分支预测失败,异常发生的频率会更低。
10.4.3 中断的处理
在MIPS处理器中,异常是由处理器内部执行指令产生的,因此异常总是和某条指令时同步的; 而中断指的是处理器外部产生的,它和处理器内部执行的指令没有必然的对应关系,因此称中断是异步的。一般有两种处理方式:
(1)马上处理。当中断发射时,将此时流水线中所有指令都抹掉,对处理器的状态进行恢复,并将流水线中最旧的那条指令的PC值保存起来,然后跳转到对应的中断处理程序,当从其中返回时,会使用中断发生时所保存的PC值来重新读取指令。优点在于响应最快,效率较低。
(2)延迟处理。当中断发生时,流水线停止取指令,但是等到流水线中所有指令退休之后才对这个中断进行处理。需要考虑的问题:
(a)如果在流水线中的这些指令发生了D-Cache缺失,那么需要很长的耗时间才能够解决,导致过长的中断响应时间。
(b)如果在流水线中发现分支预测失败指令,那么首先需要对这个情况进行处理,将处理器状态进行恢复,这也需要消耗一定时间,也造成中断响应时间的增大。
(c)如果在流水线中发现异常,那么先对异常进行处理,还是先对中断进行处理?一般来说,应该先对中断进行处理,因为很多类型的异常处理需要很长的时间。
10.4.4 store指令的处理
store指令即使计算完毕,也会将结果暂存在store buffer,直到store指令退休的时候,才会将store buffer中对应的内容写到Cache中。
一旦store指令在写D-Cache发射miss,则需要等待很长时间才能够使它离开ROB,这样就造成了ROB的阻塞,即使store指令有很多指令已经执行完毕,处于complete状态,但是由于store指令挡在前面而不能退休,造成处理器性能的降低。
解决上述问题最简单的方法就是在store buffer中增加一个状态位,用来标记一条store指令是否已经具备退休的条件,这样一条store指令在缓存中就有3个状态,即没有被执行完毕,已经被执行完毕和顺利离开流水线。
当一条store指令在流水线分发阶段,按照程序中指定的顺序占据store buffer空间,并被标记未完成。
当store指令成为流水线已经得到地址和数据,但是还没有变成流水线中最旧的指令,就处于complete状态。
当store指令成为流水线中最旧的指令并退休的时候,即顺利离开流水线状态。
store指令都是按照程序中指定的顺序来执行,当然更需要按照这个顺序对处理器的状态进行更新,所以store buffer是按照FIFO方式进行管理的。
一旦store buffer再也找不到可用的空间进行写入,此时就不能够接收新的store指令,分发阶段之前的流水线就需要暂停。造成store实际可用容量减少。限制处理器性能的提高。
如果不想造成store buffer实际可用容量的降低,可以将那些已经退休的store指令存储在一个不同于store buffer的地方,这个地方可以称为write back buffer,硬件会自动将wirte back buffer的store的指令写到D-Cache中。
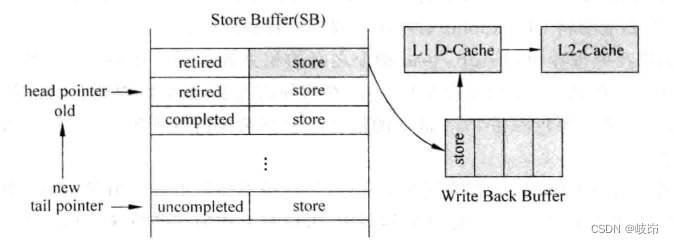
每条store指令一旦退休,就将其从store buffer写到write back buffer中,也就是说,此时这条store指令可以离开ROB和store buffer两个部件。在这个方法中,write back buffer已经成为了处理器状态的一部分。laod指令需要在store buffer和write back buffer两个缓存中进行查找,这样增加了设计复杂度。
在进入的同时需要在其中查找有没有写到相同的store指令,如果存在,那么就需要将其置为无效,这样才能够保证后面的load指令查找write back buffer,使用最新的结果。
10.4.5 指令离开流水线的限制
如果ROB中最旧的4条指令都已经处于complete状态,其中没有发现预测失败的分支指令,也没有指令产生异常,那么这4条指令就可以在一个周期内离开流水线?
从理论上说,这4条指令确实可以在一个周期内都退休而离开流水线,但是,这对处理器许多其他的部件提出了更多写端口的要求 :
(1)每周期有4条store指令,意味着D-Cache后者write back huffer需要支持4个写端口。
(2)每周期4条分支指令退休路,意味着每周期需要将4条分支指令的信息写回到分支预测器章中,这需要分支预测器中所有部件都需要支持4个写端口,同时还需要能够将checkpoint资源在每周期释放4个。
为这些不经常出现的情况而增加硬件设计的复杂度是得不偿失的,因此在超标量处理器中,可以对上述这些特殊的指令进行限制。例如,每周期退休的指令中最多只能有一条分支指令。
在流水线的提交阶段需要对指令的异常进行处理,由于需要跳转到对应的异常处理程序中,所以每周期只能处理一条指令的异常,因此找到第一个产生异常的异常,并将这条指令后面的所有指令都屏蔽,不允许它们在本周期退休。
边栏推荐
- 【最短路】ACwing 1127. 香甜的黄油(堆优化的dijsktra或spfa)
- Use metersphere to keep your testing work efficient
- 相机标定(2): 单目相机标定总结
- Electron adding SQLite database
- 技术分享 | 抓包分析 TCP 协议
- 《论文阅读》Neural Approaches to Conversational AI(1)
- R language Visual facet chart, hypothesis test, multivariable grouping t-test, visual multivariable grouping faceting boxplot, and add significance levels and jitter points
- Drive HC based on de2115 development board_ SR04 ultrasonic ranging module [source code attached]
- The annual salary of general test is 15W, and the annual salary of test and development is 30w+. What is the difference between the two?
- Talk about SOC startup (11) kernel initialization
猜你喜欢

聊聊SOC启动(十一) 内核初始化

Zhou Yajin, a top safety scholar of Zhejiang University, is a curiosity driven activist
How much do you know about excel formula?
.NET MAUI 性能提升
正在运行的Kubernetes集群想要调整Pod的网段地址

Flet教程之 19 VerticalDivider 分隔符组件 基础入门(教程含源码)
In my limited software testing experience, a full-time summary of automation testing experience
Le Cluster kubernets en cours d'exécution veut ajuster l'adresse du segment réseau du pod
分布式数据库主从配置(MySQL)

【最短路】Acwing1128信使:floyd最短路
随机推荐
通过环境变量将 Pod 信息呈现给容器
Various uses of vim are very practical. I learned and summarized them in my work
Have you ever met flick Oracle CDC, read a table without update operation, and read it repeatedly every ten seconds
In depth learning autumn recruitment interview questions collection (1)
网络协议 概念
关于SIoU《SIoU Loss: More Powerful Learning for Bounding Box Regression Zhora Gevorgyan 》的一些看法及代码实现
The running kubernetes cluster wants to adjust the network segment address of pod
QT implements the delete method of the container
禁锢自己的因素,原来有这么多
Common SQL statement collation: MySQL
Table replication in PostgreSQL
In SQL, I want to set foreign keys. Why is this problem
LeetCode - 面试题17.24 最大子矩阵
聊聊SOC启动(七) uboot启动流程三
In my limited software testing experience, a full-time summary of automation testing experience
正在运行的Kubernetes集群想要调整Pod的网段地址
聊聊SOC启动(十一) 内核初始化
Flet教程之 16 Tabs 选项卡控件 基础入门(教程含源码)
学习笔记|数据小白使用DataEase制作数据大屏
深度学习秋招面试题集锦(一)