当前位置:网站首页>Spark accumulator and broadcast variables and beginners of sparksql
Spark accumulator and broadcast variables and beginners of sparksql
2022-07-06 17:40:00 【Bald Second Senior brother】
accumulator :
Catalog
Why use accumulators : stay spark If you do not define an accumulator in, when using the accumulation calculation method , because task Cannot change the original variable , After using the accumulator, the global variables can be rewritten , So accumulator is also called global writable variable
The illustration
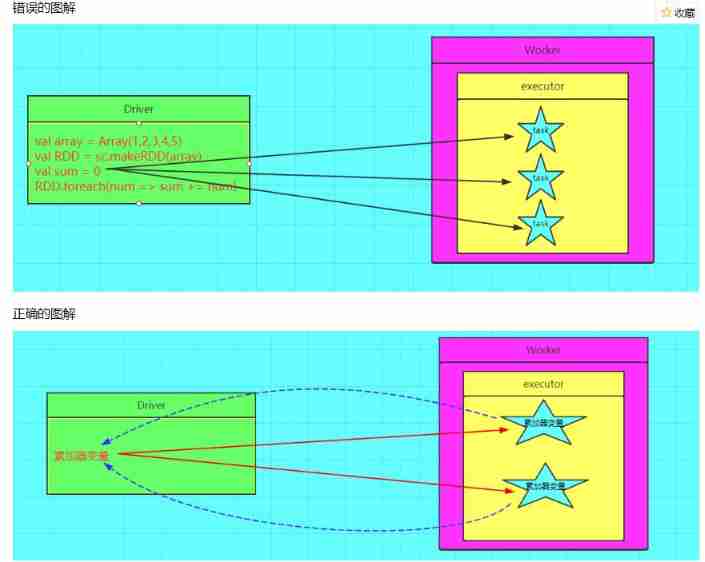
Usage mode :
object Spark_leijia {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("word")
val sc = new SparkContext(conf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4), 2)
// Accumulator shared variable
// Create accumulator object
val accumulator = sc.longAccumulator
var sum=0;
dataRDD.foreach{
case i =>{
// Execute the accumulation function
accumulator.add(i)
}
}
println("sum="+accumulator.value)
}
}Be careful : Although accumulator is also called global write only variable , But he is also readable , It is only the operation of writing that is used at most
Broadcast variables
Why use broadcast variables : because spark There is an independent copy of the variable of , Then when sending Driver For each task Distribute a copy , stay task Too much time will consume a lot of system resources , So there are broadcast variables , Broadcast variables are also called global readable variables
The illustration
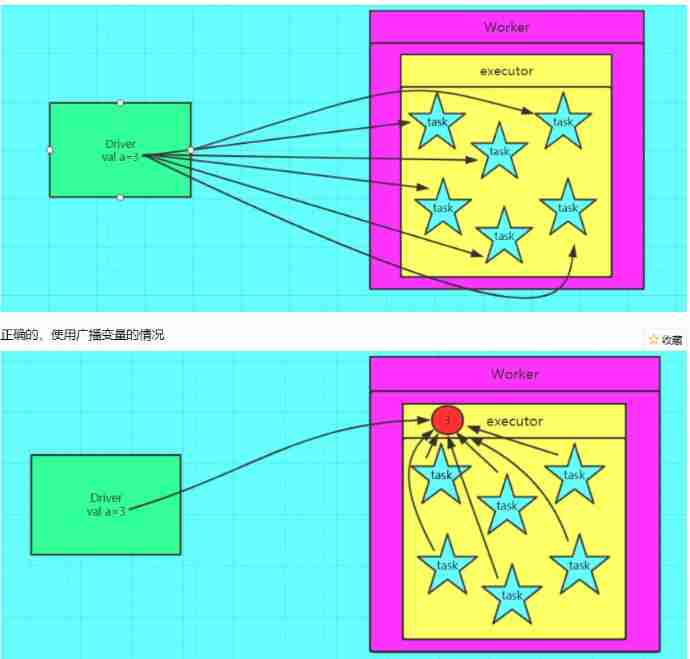
The use of broadcast variables
// Define broadcast variables val a = 3 val broadcast = sc.broadcast(a) // Restore val c = broadcast.value
Be careful : The broadcast variable is the same as its other name. Once defined, it can only be read and cannot be overwritten
SparkSQL
What is? SpqrkSQL:Spark Is a similar to HIve A kind of SQL It's all to replace MapReduce The birth of the , It provides 2 Programming abstractions :DataFrame and DataSet, And as distributed SQL The function of query engine
advantage : Easy integration , Unified data access , compatible Hive, Standard data connection
DataFrame
dataFrame It's a use RDD Distributed data containers written for the bottom , Compare with RDD For example, he added the structure of data , Similar to two-dimensional tables and hive similar .
dataFrame Use :
df At build time , Need to be right RDD The data from map To add data structures , Or directly read files with data structures, such as :json file
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Sql1")
val session = new SparkSession.Builder().config(conf).getOrCreate()
// Read data and build dataFrame
val frame = session.read.json("D:\\spark-class\\in\\user.json")
// use sql Syntax to access data
// take dataFram Convert to a table
frame.createOrReplaceTempView("xxx");
session.sql("select * from xxx").show
//frame.show()
session.stop()DataSet
DataSet And Df Very similar, but ,DS stay DF Data types are added on the basis of , In this way, data can be queried as an object .
DS Use DS The use of DF similar , However, you need to specify the type of data when creating , You can create it through a sample class
RDD,DF,DS Direct conversion
The conversion of these three is to add or remove data types through specific functions , Data structure for conversion
object Spark_SQL2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Sql1")
val session = new SparkSession.Builder().config(conf).getOrCreate()
// Implicit conversion rules need to be introduced before replacement
// take RDD Convert to DF
val listRDD = session.sparkContext.makeRDD(List((1, "zhangsan", 21), (2, "lisi", 24)))
import session.implicits._
val dataFrame = listRDD.toDF("id", "name", "age")
//DF Convert to DS
val dataSet = dataFrame.as[User]
//DS Convert to DF
val dataFrame1 = dataSet.toDF()
//DF Convert to RDD
val rdd = dataFrame1.rdd
rdd.foreach(row =>{
println(row.getString(1))
})
}
/**
* Sample class
*/
case class User(id:Int ,name:String,age:Int)
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("word")
val session = new SparkSession.Builder().config(conf).getOrCreate()
import session.implicits._
// establish RDD
val listRDD = session.sparkContext.makeRDD(List((1, "zhangsan", 21), (2, "lisi", 24)))
//RDD Convert to DS
val userRDD = listRDD.map {
case (id,name,age) => {
User(id, name, age)
}
}
userRDD.toDS().show()
}
/**
* Sample class
*/
case class User(id:Int ,name:String,age:Int)Custom aggregate functions
Weak type : No data type is specified
object Spark_SQL4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("word")
val session = new SparkSession.Builder().config(conf).getOrCreate()
import session.implicits._
// establish RDD
val listRDD = session.sparkContext.makeRDD(List((1, "zhangsan", 21), (2, "lisi", 24)))
val udaf=new MyAgeAvg
// Register aggregate function
session.udf.register("avgAGE",udaf)
// Use
val rdd = listRDD.map {
case (id, name, age) => {
User(id, name, age)
}
}
val ds = rdd.toDS().createOrReplaceTempView("user")
session.sql("select avgAGE(age) from user ").show()
}
/**
* Sample class
*/
case class User(id:Int ,name:String,age:Int)
/**
* Custom weak type aggregate function
* 1. Inherit UserDefinedAggregateFunction
* 2. Implementation method
*/
class MyAgeAvg extends UserDefinedAggregateFunction{
// Function input data structure
override def inputSchema: StructType = {
new StructType().add("age",LongType)
}
// Data structure during calculation
override def bufferSchema: StructType = {
new StructType().add("sum",LongType).add("count",LongType)
}
// The data type returned by the function
override def dataType: DataType =DoubleType
// Whether the function is stable
override def deterministic: Boolean = true
// Buffer initialization before calculation
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0L
buffer(1)=0L
}
// Update data
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0)=buffer.getLong(0)+input.getLong(0)
buffer(1)=buffer.getLong(1)+1
}
// Combine multiple node buffers
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
// Calculation
override def evaluate(buffer: Row): Any ={
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
}
Strong type : Specify the data type
object Spark_SQL5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("word")
val session = new SparkSession.Builder().config(conf).getOrCreate()
import session.implicits._
// establish RDD
val listRDD = session.sparkContext.makeRDD(List((1, "zhangsan", 21), (2, "lisi", 24)))
val udaf = new MyAgeAvgClass
// Convert the aggregate function to the column of the query
val avg = udaf.toColumn.name("avgAge")
// Use
val rdd = listRDD.map {
case (id, name, age) => {
User(id, name, age)
}
}
val ds = rdd.toDS()
ds.select(avg).show
}
/**
* Sample class
*/
case class User(id: Int, name: String, age: Int)
/**
* Define data types
*/
case class AvgBuff(var sum:Int,var count:Int)
/**
* Custom strongly typed aggregate functions
* 1.Aggregator, Set generics
* 2. Implementation method
*/
class MyAgeAvgClass extends Aggregator[User,AvgBuff,Double] {
// Buffer initialization
override def zero: AvgBuff = {AvgBuff(0,0)}
// Aggregate data
override def reduce(b: AvgBuff, a: User): AvgBuff = {
b.sum=b.sum+a.age
b.count=b.count+1
b
}
// Merge operation of buffer
override def merge(b1: AvgBuff, b2: AvgBuff): AvgBuff = {
b1.sum=b1.sum+b2.sum
b1.count=b1.count+b2.count
b1
}
// Calculation
override def finish(reduction: AvgBuff): Double = {
reduction.sum.toDouble/reduction.count
}
override def bufferEncoder: Encoder[AvgBuff] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
}SparkSession:
SparkSession It provides a unified entry point for users , He is used to replace SparkContext For convenience ,SparkSession Because Spark The operation of RDD For different API Need different Context use SparkSession To integrate them .
advantage :
Provide users with a unified entry point to use Spark Functions
Allow users to call DataFrame and Dataset relevant API To write a program
It reduces some concepts that users need to understand , It's easy to communicate with Spark Interact
And Spark You don't need to create a display when you interact SparkConf, SparkContext as well as SQlContext, These objects have been enclosed in SparkSession in
边栏推荐
猜你喜欢
List set data removal (list.sublist.clear)
The NTFS format converter (convert.exe) is missing from the current system
Flink parsing (IV): recovery mechanism
Final review of information and network security (based on the key points given by the teacher)
Final review of information and network security (full version)
![[getting started with MySQL] fourth, explore operators in MySQL with Kiko](/img/11/66b4908ed8f253d599942f35bde96a.png)
[getting started with MySQL] fourth, explore operators in MySQL with Kiko
BearPi-HM_ Nano development board "flower protector" case
Application service configurator (regular, database backup, file backup, remote backup)
【逆向】脱壳后修复IAT并关闭ASLR
C version selenium operation chrome full screen mode display (F11)
随机推荐
Xin'an Second Edition: Chapter 25 mobile application security requirements analysis and security protection engineering learning notes
【ASM】字节码操作 ClassWriter 类介绍与使用
The art of Engineering (3): do not rely on each other between functions of code robustness
[elastic] elastic lacks xpack and cannot create template unknown setting index lifecycle. name index. lifecycle. rollover_ alias
04 products and promotion developed by individuals - data push tool
Connect to LAN MySQL
分布式(一致性协议)之领导人选举( DotNext.Net.Cluster 实现Raft 选举 )
[VNCTF 2022]ezmath wp
Debug and run the first xv6 program
MySQL报错解决
网络分层概念及基本知识
Flink analysis (I): basic concept analysis
CTF逆向入门题——掷骰子
Interpretation of Flink source code (I): Interpretation of streamgraph source code
Wordcloud colormap color set and custom colors
The NTFS format converter (convert.exe) is missing from the current system
05 personal R & D products and promotion - data synchronization tool
TCP连接不止用TCP协议沟通
C version selenium operation chrome full screen mode display (F11)
mysql高級(索引,視圖,存儲過程,函數,修改密碼)