当前位置:网站首页>Flink analysis (I): basic concept analysis
Flink analysis (I): basic concept analysis
2022-07-06 17:27:00 【Stray_ Lambs】
Catalog
1、 Independent clusters (Standalone)
Flink Basic concepts
Currently in the real-time framework ,Flink It can be said to have a place .Flink It's a distributed system , Computing resources need to be effectively allocated and managed to execute streaming applications . It integrates all common cluster resource managers , for example Hadoop YARN、Apache Mesos and Kubernetes, But you can also set up to run as a separate cluster or even a library . also Flink It is a computing framework for flow batch integration , It can calculate finite data flow and infinite data flow with state or without state ( That is, it can be flow computing or batch computing ).
Flink As Flow batch integration Framework , Stream processing uses DataStream, Batch processing uses DataSet. It consists of the following core components .

Flink Runtime (runtime) It consists of two types of processes : One JobManager And one or more TaskManager. First, put a structure diagram of the official website , Get to know .
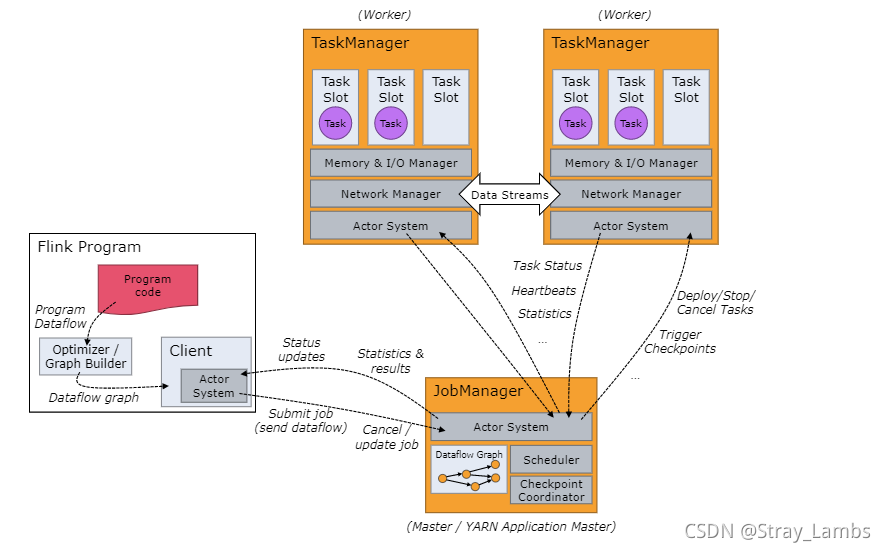
Here is a brief overview of the overall process :
When Flink Once the cluster is started , First, a JobManager And one or more TaskManager. By the client Client Submit a task to JobManager,JobManager Then schedule tasks to each TaskManager To carry out , then TaskManager Report heartbeat and statistics to JobManager.TaskManager Data transmission in the form of stream . These are independent JVM process .
- Client Submit for Job The client of , It can run on any machine , As long as it's with JobManager The environment is connected . Submit Job after ,Client You can end the process or wait for the result to return .
- JobManager Mainly responsible for Client Received Job and Jar After the package and other resources , An optimized execution plan will be generated , And Task The unit is scheduled to each TaskManager To carry out .
- TaskManager It is set at startup slot Slot number , Every slot Can start a Task, And Task For threads , This is the same as Spark Of fork Threads are similar . from JobManager Receive what needs to be deployed Task after , Establish with upstream Netty Connect , Receive data and process it .
- Flink The communication between roles in the architecture uses Akka, such as JobManager And Client Communication between , The transmission between data uses Netty.
1、Job Manager
JobManager Is the job manager , Is a main process . Mainly responsible for : Coordinate Distributed Computing ; Responsible for scheduling tasks ; Coordinate checkpoint; Coordinate fault recovery . It consists of the following three components :
- ResourceManager
ResourceManager be responsible for Flink Resource application in the cluster 、 Release 、 Distribute , stay HA in ,RM Also responsible for selection leader Job Manager. It manages task slots, This is a Flink The unit of resource scheduling in the cluster ( Please refer to TaskManagers).Flink For different environmental and resource providers ( for example YARN、Mesos、Kubernetes and standalone Deploy ) The corresponding ResourceManager. stay standalone Setting up ,ResourceManager Only available... Can be assigned TaskManager Of slots, Instead of starting a new TaskManager.
- Dispatcher
The dispenser ( Not necessary ).Dispatcher Provides a REST Interface (GET/PUT/DELETE/POST), To submit Flink Application execution , And start a new job for each submitted job JobMaster. It also runs Flink WebUI (localhost:8081) be used for ⽅ Conveniently display and monitor work execution ⾏ Information about .Dispatcher It may not be necessary in the architecture , It depends on ⽤ Delivery ⾏ Of ⽅ type .
- JobMaster
JobMaster Responsible for managing individual JobGraph Implementation . Be responsible for receiving tasks , be responsible for JobManagerRunner( Encapsulates the JobMaster) Start of .Flink Multiple jobs can run simultaneously in a cluster , Each assignment has its own JobMaster.
2、Task Manager
Task Manager( hereinafter referred to as TM) yes Flink Medium ⼯ Working process ( Task manager ). Usually in Flink There will be more than one TM shipment ⾏, Every time ⼀ individual Task Manager It's all about ⼀ A certain number of slots (slots). The number of slots limits TM Be able to hold ⾏ Number of tasks . Each of them TM It's a JVM process , And every one slot It's a thread .
When a TM when ,TM Will send to Resource Manager Reverse register its slot; In the subsequent task scheduling , received RM Instructions will be provided after slot to JobManager.Job Manager You can go to slot Assign tasks to perform . In execution dataflow Medium task when ,TM Will cache and exchange data ( such as shuffle).
Task submission process
1、 Independent clusters (Standalone)

2、Yarn colony

Yarn Cluster mode ,Client Need to put jar Upload packages and related configurations to HDFS in , And to RM With Session Submit by session Job( namely jar package ). After submission , from RM In idle NodeManager Go to start ApplicationMaster As the application master node , It's a bit like Spark Medium Driver. Among them NodeManager Contains JobManger, then JobManager towards HDFS Loaded, packaged and uploaded jar Package and related configuration , Go where you need to go RM Apply to start TaskManager. When the startup completes the corresponding TaskManager after ,TM Will RM Reverse registration slot.
Programs and data streams
Flink The program consists of three parts :Source、Transformation and Sink. among Source Responsible for reading data source ,Transformation Processing with various operators ,Sink Responsible for output .

During operation ,Flink The program that runs on will be mapped to “ Logical data flow ”(dataflows), Every dataflow With one or more source Start with one or more sinks end . every last dataflow Is similar to DAG Directed acyclic graph .
Execution diagram
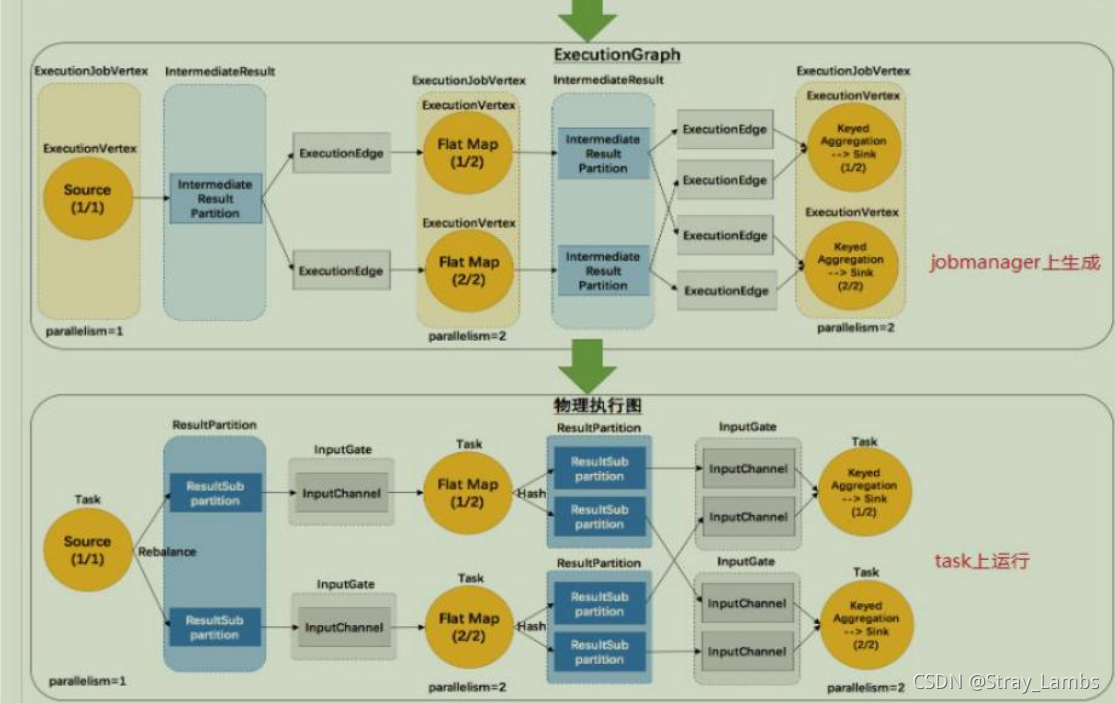
Flink The execution diagram can be divided into four layers :
StreamGraph->JobGraph->ExecutionGraph-> Physical execution diagram
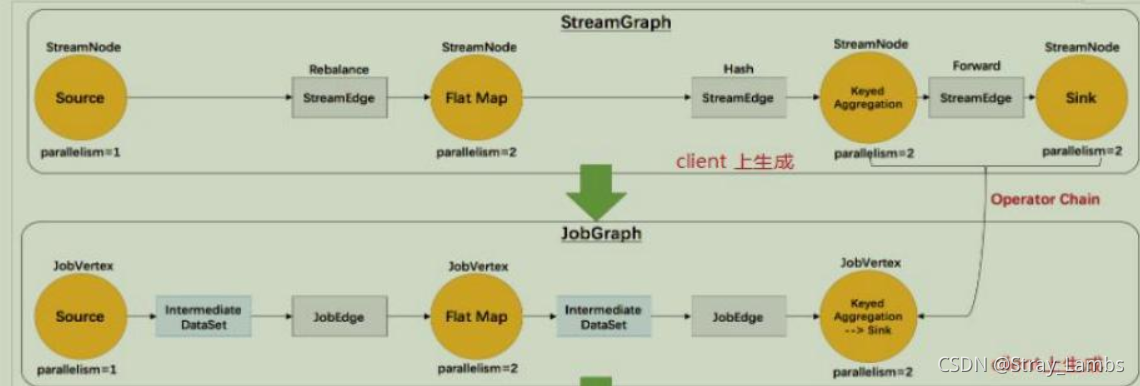
- StreamGraph: According to the user through Stream API The original diagram generated by the written code . Used to represent the topology of a program . stay Client In the middle of .
- JobGraph:StreamGraph After optimization, it generates JobGraph, Submitted to JobManager Data structure of . The main optimization is , Multiple nodes that meet the conditions chain Together as a node . stay Client In the middle of .
- ExecutionGraph:JobManager according to JobGraph Generate ExecutionGraph.ExecutionGraph yes JobGraph Parallel version of , It is the core data structure of scheduling layer . stay JobManager In the middle of .
- Physical execution diagram :JobManager according to ExecutionGraph Yes Job After scheduling , In all TaskManager Upper Department Task The diagram formed after , It's not a specific data structure .
PS: Later, I found that if you add the source code interpretation of each figure, the length is too long , I plan to put it separately in the next blog ...
Follow Spark equally ,Flink Also lazy execution , The user logic code will be in Flink After encapsulating and executing all the flow charts, start running .
every last operator( Be similar to Spark In the middle of rdd operator ) I'm going to generate the corresponding Transformation( such as Map Corresponding OneInputTransformation), Finally, it runs until StreamExecutionEnvironment.execute(), Similar to the implementation of Spark among action operator , To really execute the code , division DAG And all stages and tasks ,Flink So it starts to divide Flink Execution diagram and various task chains .
Data transmission form
And Spark Similarly ,Flink The different operators of also have a wide and narrow transmission form , It's just Flink be called One-to-one and Redistributing.
- One-to-one( Don't involve shuffle The process ): It's a little similar to the feeling of being an only child , Upstream data has only one downstream receiving data .stream Maintaining the order of partitions and elements ( such as source and map Between ). It means map The number and order of elements seen by the subtask of the operator follow source The number of elements produced by the subtask of the operator 、 Same order .map、fliter、flatMap And so on one-to-one Correspondence of .
- Redistributing( involve shuffle The process ): A little similar to the feeling of multiple birth , Upstream data has multiple downstream received data .stream The partition of will change . The subtasks of each operator depend on the selected transformation Send data to different target tasks . for example ,keyBy be based on hashCode Repartition 、 and broadcast and rebalance It's going to be randomly repartitioned , These operators all cause redistribute The process , and redistribute The process is similar to Spark Medium shuffle The process .
Task chain (Operator Chains)
Flink An optimization technology called task chain is adopted , Because whether it's across NodeManager Data transmission is still cross Task The data transfer , May cause communication overhead , therefore Flink Reduce the cost of local communication under specific conditions . If the conditions are met , Then two or more operators can be connected by local forwarding .
- Of the same degree of parallelism one-to-one operation ( And it needs to be in the same group ), Such operators can be linked together to form a task, The original operator becomes one of them subtask( Put a flag, Have the opportunity to write a task link source code interpretation …)
In the future, source code interpretation and principle understanding will be divided into two modules , Otherwise, the space is too large …
Reference resources
0006-Flink principle (Flink Data flow & Execution diagram ) - Programmer base
边栏推荐
- 手把手带你做强化学习实验--敲级详细
- Basic knowledge of assembly language
- mysql 基本增删改查SQL语句
- Only learning C can live up to expectations top3 demo exercise
- 吴军三部曲见识(四) 大家智慧
- Only learning C can live up to expectations TOP4 S1E6: data type
- Activiti directory (I) highlights
- Case: check the empty field [annotation + reflection + custom exception]
- On the clever use of stream and map
- Flink源码解读(三):ExecutionGraph源码解读
猜你喜欢
手把手带你做强化学习实验--敲级详细
Akamai anti confusion
Logical operation instruction
信息与网络安全期末复习(完整版)
Models used in data warehouse modeling and layered introduction

Activiti directory (V) reject, restart and cancel process

吴军三部曲见识(四) 大家智慧
06 products and promotion developed by individuals - code statistical tools
Activit fragmented deadly pit

Wu Jun's trilogy experience (VII) the essence of Commerce
随机推荐
Activiti directory (I) highlights
PostgreSQL 14.2, 13.6, 12.10, 11.15 and 10.20 releases
CTF reverse entry question - dice
JVM 垃圾回收器之Serial SerialOld ParNew
CTF逆向入门题——掷骰子
Development and practice of lightweight planning service tools
Deploy flask project based on LNMP
Flink 解析(四):恢复机制
Akamai anti confusion
自动答题 之 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
【逆向初级】独树一帜
Interview collection library
基于Infragistics.Document.Excel导出表格的类
Flink 解析(一):基础概念解析
8086 segmentation technology
当前系统缺少NTFS格式转换器(convert.exe)
05个人研发的产品及推广-数据同步工具
Only learning C can live up to expectations top3 demo exercise
华为认证云计算HICA
02个人研发的产品及推广-短信平台