当前位置:网站首页>Adapter-a technology of adaptive pre training continuous learning
Adapter-a technology of adaptive pre training continuous learning
2022-07-06 02:06:00 【weixin_ forty-two million one thousand and eighty-nine】
Preface
Long term pre training partner , You can pay attention to this technical point, that is adapter, Recently, there are quite a lot of work in this field , It is such a background : Without forgetting the knowledge learned before , How to continuously inject knowledge into the large model .
Today I will bring you two latest related works , Open up your mind ~, Interested partners can check more related paper.
Of course, the idea is not particularly new , There have been many similar ideas before , So when you look at it, on the one hand, you should learn its design ideas , On the other hand, it is more important to learn what problems it wants to solve and the general direction of thinking , In short, don't let the current adapter Research is bound , As the author also gives some discussions at the end of the article , In fact, the title of this article at the beginning is not intended to write “Adapter- A technique that adapts pre training to continuous learning ”, But I want to write the general direction of continuous learning , But this direction is big , And this article introduces paper All are adapter thought ( One of the solutions ), So write in lowercase , I'll write another article later when I have time “ Model continuous learning ”, And the author believes that this is the starting point for the study of the most essential problems in the future , Even the current multimodal model of the fire is just an attempt , It cannot solve the essential problem ( See the end of the article for the reasons , To represent only one's point of view )
To be exact, after reading this article, I hope you have not learned a specific model design , But gain : I understand that there is another direction that can be studied, that is, continuous knowledge learning of pre training model . If you can inspire a good idea, That is the greatest significance of this article .
problem
Before we begin, let's take a look at the main problems in this demand context ? Before, it was basically through multi task learning to inject new knowledge into the model or curriculum learning ( Multi-stage learning ), For example, dialogue model PLATO-2 Multi-stage learning is adopted in , But here are some obvious shortcomings :
(1) Unable to continuously inject knowledge , For example, we have a trained model before , So what if a new knowledge needs to be injected ? If you only train on the data set of this new knowledge , That is bound to make the model fit the current data set infinitely , Then it leads to forgetting the knowledge learned before , Usually to solve this problem , We mix the previous data set with the current data set , Retraining the whole model , That's ok , for example ERNIE-2 That's what it does , But the disadvantages are also obvious , That is, the cost is too high , Every new knowledge , You need to bring all the previous knowledge to update the whole model .
(2) The model indicates that the coupling is serious , This means that multiple knowledge representations are coupled together, and it is difficult to study the impact of various knowledge , I believe you have also seen the trend of model unification , In a narrow sense, from the perspective of single-mode model : Integrate various tasks , such as NLP Field will ner、 Data sets of various tasks such as emotion classification and even tables are collected , Train a unified model ; In a broad sense, from the multi-modal model, we can see the unification : The picture 、 Text and even voice data are collected to train a unified model . In short, no matter three, seven, twenty-one , Is to collect the data that can be collected , Train a big model , That is, rely on big data and big models to build an intelligent model that accommodates all kinds of knowledge . Far away , Far away , Interested partners , You can see an article previously written by the blogger as follows . Back to the topic of this article , In this trend , It is more important to study the relationship between various knowledge , Instead, study relationships , The first step is to find a way to decouple each knowledge representation .
 https://zhuanlan.zhihu.com/p/435697429
https://zhuanlan.zhihu.com/p/435697429After generally understanding the requirements, let's take a look through two papers adapter The solution .
If you have to sum it up in a big white sentence , I think it is : Press and hold the big head , Train the little head .
K-adapter
Thesis link :https://arxiv.org/pdf/2002.01808.pdf

Don't forget the previous knowledge, but don't want to retrain with the previous data , To achieve this effect, the easiest thing to think of is not to change the good weight that has been trained , If you don't change the weight, the knowledge is still !!!
Based on this logic , We can think of fixing the previous weight , Then the new knowledge only trains itself to add a corresponding part of the model weight . That is what I started to say “ Press and hold the big head , Train the little head ”.
Speaking of this , Did some friends laugh , This is similar pretrain+fintune Do you ? Yes that's right , Hold down “ Previous weights ” This big head does not change , Only train your own part of the weight , And the weight of this part is usually not too large , This part of the model is called adapter, Each task has its own adapter To fit .
We can also see from the above figure that (a) It represents multi task learning , I will learn all the data together ,(b) Is the method mentioned in this article , You can see that there is Adapter1,Adapter2 Multiple adaptation mechanisms .
In fact, it can end here , We have learned the core idea , But the following is about adapter How it was designed , The paper gives a train of thought , You don't even need to design your own models .

Specifically, you can see N individual transformer layer ,2 A mapping layer and 1 A residual connection combination structure , Every adapter It actually includes K A combination like this , This is also the title of the thesis K-adapter The origin of . About experiments and more details , You can read the original paper .
Adapter-Bot
Thesis link :https://arxiv.org/pdf/2008.12579.pdf

This paper will adapter Apply ideas to the dialogue model . His background is like this : There are many kinds of dialog data sets , For example, knowledge-based dialogue skills , Emotional dialogue skills and so on , Every kind of data can be understood as a kind of knowledge , What this paper wants to solve is how to train a dialogue model that integrates multiple knowledge , If you are interested in the dialogue model, you can see an article written by the author before :
The big idea remains the same , Press and hold the big head , Train the little head .
The specific big head is one frozen backbone Dialogue model ; The small head is a group of trainable independent residuals residual adapters And a trainable dialog manager dialogue manager.
If analogy K-adapter Words ,residual adapters Namely K-adapter, But the design here adopts residual .
The so-called dialog manager here is actually a classification task , It is used to classify which conversation skill data set the current conversation belongs to , The function is to supervise residual adapters We better fit their data distribution .
summary
(1) Hold down the big head , Only update small adapter This idea can certainly solve the problem of not forgetting , But this is not 100% Can solve , The reason why the big head can become the capital of the big head lies in its sufficient authority , In other words, when training the first version of big head, it already contains a lot of knowledge , Suppose your big head is not very good at the beginning , Now a new knowledge , This knowledge is very big , It's very hard to learn , In fact, the previous boss is not qualified to be a boss , Still need to learn again . So it is very important whether the big head on your hand is strong enough .
(2) Pay attention to the problems discussed here and multi task learning ( Including multimodal learning and so on ) There are differences and connections , One of the reasons given by researchers of multitasking learning is : Multiple tasks can influence each other, that is, improve their performance through the influence of other related tasks , So we should study together , Interact with each other , We seem to keep the weight of other tasks unchanged . There's actually nothing tangled here , There are two things , You can take care of it .
(3) Talk a little more : I don't know if you feel the above mentioned adapter In fact, it is not necessarily the best way , Take us as human beings , A birth is a blank sheet , Then learn and accumulate knowledge little by little the day after tomorrow , Finally, it becomes stronger and stronger . So should we not be based on a big model , Small stack on top , But jump out of this thinking , Look at this problem again , That's us ( Small at the beginning ) Now there are many models of various abilities , So how to integrate these models , Or how to make the system continuously learn these models , Pay attention to what is mentioned here and above adapter Ideas are fundamentally different ,adapter The premise is to assume that small knowledge is pushed above the big , In fact, there should be no size discrimination , The designed model should have the ability to continuously integrate the knowledge of large models , So this piece of imagination space is very large , We can even draw lessons from distillation ideas and so on ,adapter The concept of is by no means narrow , Knowledge fusion is a valuable topic , Now the multi model is essentially a start. Soha is to prepare all kinds of knowledge data as much as possible at the beginning , But the author believes that this is ultimately a palliative , Because there will be an endless stream of knowledge data every day , In this age of information explosion , It is never possible to enumerate by preparing in advance , It is necessary to have the ability of continuous learning , Therefore, it is very valuable to study model sustainable learning , I sincerely hope to see more achievements in this field in the future .
Focus on
Welcome to your attention , See you next time ~
Welcome to WeChat official account :

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
You know :
边栏推荐
- C web page open WinForm exe
- [flask] official tutorial -part1: project layout, application settings, definition and database access
- MCU lightweight system core
- Paddle框架:PaddleNLP概述【飞桨自然语言处理开发库】
- Leetcode sum of two numbers
- 安装php-zbarcode扩展时报错,不知道有没有哪位大神帮我解决一下呀 php 环境用的7.3
- National intangible cultural heritage inheritor HD Wang's shadow digital collection of "Four Beauties" made an amazing debut!
- Unreal browser plug-in
- 【网络攻防实训习题】
- 通过PHP 获取身份证相关信息 获取生肖,获取星座,获取年龄,获取性别
猜你喜欢
Computer graduation design PHP college student human resources job recruitment network
SQL statement
![[ssrf-01] principle and utilization examples of server-side Request Forgery vulnerability](/img/43/a8f302eb69beff4037aadda808f886.png)
[ssrf-01] principle and utilization examples of server-side Request Forgery vulnerability
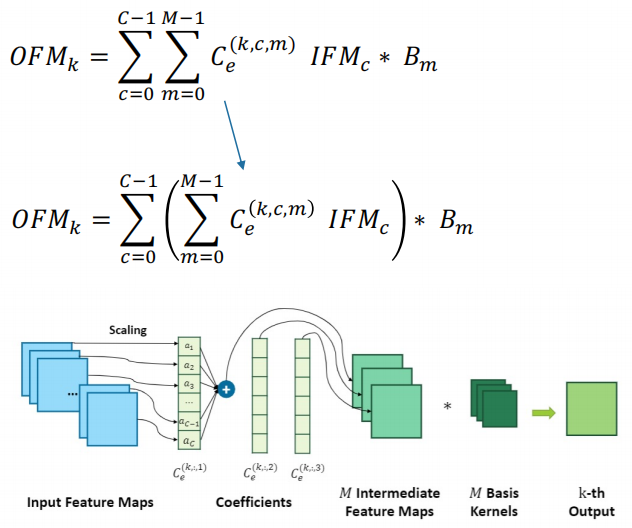
干货!通过软硬件协同设计加速稀疏神经网络

Numpy array index slice
Concept of storage engine

Leetcode skimming questions_ Invert vowels in a string
C web page open WinForm exe
Folio. Ink is a free, fast and easy-to-use image sharing tool

500 lines of code to understand the principle of mecached cache client driver

随机推荐
论文笔记: 图神经网络 GAT
干货!通过软硬件协同设计加速稀疏神经网络
[flask] response, session and message flashing
Executing two identical SQL statements in the same sqlsession will result in different total numbers
Flutter Doctor:Xcode 安装不完整
【网络攻防实训习题】
National intangible cultural heritage inheritor HD Wang's shadow digital collection of "Four Beauties" made an amazing debut!
[ssrf-01] principle and utilization examples of server-side Request Forgery vulnerability
MCU lightweight system core
[depth first search notes] Abstract DFS
Computer graduation design PHP animation information website
Cookie concept, basic use, principle, details and Chinese transmission
Unity learning notes -- 2D one-way platform production method
Leetcode3, implémenter strstr ()
ClickOnce does not support request execution level 'requireAdministrator'
[flask] official tutorial -part2: Blueprint - view, template, static file
Exness: Mercedes Benz's profits exceed expectations, and it is predicted that there will be a supply chain shortage in 2022
Shutter doctor: Xcode installation is incomplete
genius-storage使用文档,一个浏览器缓存工具
Redis-字符串类型