当前位置:网站首页>Redis summary
Redis summary
2022-07-07 08:37:00 【Silent flowers bloom】
Objective record
What is? Redis
Redis(Remote Dictionary Server) It's a use C language-written , Open source (BSD The license ) High performance non relational (NoSQL) Key value to database .
Redis You can store mappings between keys and five different types of values . The key type can only be string , Value supports five data types : character string 、 list 、 aggregate 、 Hash table 、 Ordered set .
redis Can handle over per second 10 Ten thousand read and write operations , Is the fastest known Key-Value DB. in addition redis It is also commonly used as a distributed lock .
Redis Why fast ?
- Completely based on memory , Most requests are purely memory operations , Very fast .
At the same time, the data is stored in memory , Be similar to HashMap,HashMap The advantage is the time complexity of both the lookup and the operation O(1); - The data structure is simple , It's also easy to manipulate data ,Redis The data structure in is specially designed ;
- Using single thread .
Unnecessary context switches and race conditions are avoided , There is no switching consumption caused by multiple processes or multiple threads CPU, You don't have to worry about locks , There is no lock release operation , There is no performance penalty due to possible deadlocks ; - Using multiple channels I/O Reuse model , Non blocking IO;
- Using the underlying model is different .
The underlying implementation and application protocols for communicating with clients are different between them ,Redis Build it yourself VM Mechanism , Because the normal system calls system functions , It's a waste of time moving and requesting ;
Redis What are the common data types ?
Redis There are mainly 5 Type of data , Include String,List,Set,Zset,Hash
String ( character string 、 Integer or floating point ): Do a simple key value pair cache
List list : Store some list data structures
set unordered set : intersection 、 Combine 、 Operation of difference set
hash Unordered hash table with key value pairs : Structured data , Like an object
zset Ordered set : De duplication but sorting
Redis RDB and AOF The difference between persistence , How to choose ?
What is? Redis Persistence ?
Persistence is to write data in memory to disk , Prevent memory data loss due to service outage .
Redis What is the persistence mechanism of ?
Redis There are two persistence mechanisms RDB( Default ) and AOF Mechanism :
RDB:Redis DataBase, Generate a snapshot of the current data and save it on the hard disk .
RDB yes Redis Default persistence method . Save the memory data to the hard disk in the form of snapshot according to a certain time , The corresponding generated data file is dump.rdb. Through... In the configuration file save Parameter to define the period .AOF:Append Only File Persistence , Record every data operation on the hard disk .
take Redis Each write command executed is recorded in a separate log file , When restarting Redis It will recover the data from the persistent log again .
RDB and AOF Advantages and disadvantages
- AOF File than RDB High update frequency , priority of use AOF Restore data .
- AOF Than RDB Safer and bigger
- RDB Performance ratio AOF good
- If both have priority loading AOF
How to choose
1、 Generally speaking , If you want to achieve enough PostgreSQL Data security of , Two persistence functions should be used at the same time . under these circumstances , When Redis It will be loaded prior to restart AOF File to restore the original data , Because in general AOF The data set saved by the file is better than RDB The data set of the file should be complete .
2、 If it can withstand data loss within a few minutes , Then you can only use RDB Persistence .
3、 Use only AOF Persistence , But it is not recommended . Because of timing generation RDB snapshot (snapshot) Very convenient for database backup , also RDB Data set recovery is also faster than AOF Fast recovery , besides , Use RDB You can also avoid AOF programmatic bug.
4、 If you only want the data to exist when the server is running , You can do it without any persistence .
How to solve cache breakdown 、 Cache penetration 、 Avalanche problem ?
Cache breakdown
Cache breakdown refers to data not in the cache but in the database ( Generally, the cache time expires ), At this time, there are many concurrent users , At the same time, the read cache does not read the data , At the same time go to the database to get data , Causes the database pressure to increase instantaneously , Cause too much pressure .
Unlike the cache avalanche , Cache breakdown refers to concurrent query of the same data , The cache avalanche is that different data has expired , A lot of data can't be found to look up the database .
Solution
- Set hotspot data never to expire .
- Add mutex lock
Cache penetration
Make a request for some data that must not exist , The request will penetrate the cache and reach the database .
Cache penetration refers to data that does not exist in cache or database , Causes all requests to fall to the database , Cause the database to bear a large number of requests in a short time and crash .
Solution
- Cache an empty data for these nonexistent data ;
- Filtering such requests .
Cache avalanche
Because the data is not loaded into the cache , Or cache data fails in a large area at the same time ( Be overdue ), Or the cache server is down , This results in a large number of requests reaching the database .
In a system with a cache , The system relies heavily on caching , The cache shares a large portion of the data requests . When a cache avalanche occurs , The database can't handle such a large request , Cause database crash .
Solution :
- In order to prevent cache avalanche caused by cache expiration in a large area at the same time , By observing user behavior , Set the cache expiration time reasonably
( The expiration time of cache data is set randomly , Prevent a large number of data expiration at the same time .) - In general, concurrency is not particularly large , The most commonly used solution is lock queuing
- Add the corresponding cache mark to each cache data , Whether the record cache is invalid , If the cache token fails , Then update the data cache .
- In order to prevent cache avalanche caused by cache server downtime , You can use distributed caching , In the distributed cache, each node only caches part of the data , When a node goes down, it can ensure that the cache of other nodes is still available .
- You can also warm up the cache , Avoid the cache avalanche caused by not caching a large amount of data soon after the system starts .
边栏推荐
- 基本数据类型和string类型互相转化
- IELTS review progress and method use [daily revision]
- [kuangbin] topic 15 digit DP
- 接口作为参数(接口回调)
- Thirteen forms of lambda in kotlin
- Go语言中,函数是一种类型
- Using helm to install rainbow in various kubernetes
- Opencv learning note 3 - image smoothing / denoising
- uniapp 微信小程序监测网络
- Data type - floating point (C language)
猜你喜欢

Interpreting the practical application of maker thinking and mathematics curriculum
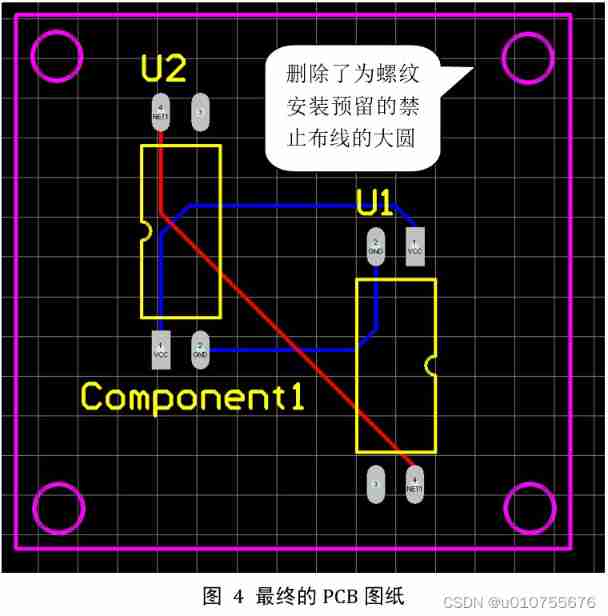
23 Chengdu instrument customization undertaking_ Discussion on automatic wiring method of PCB in Protel DXP

Merge sort and non comparison sort

联想混合云Lenovo xCloud:4大产品线+IT服务门户
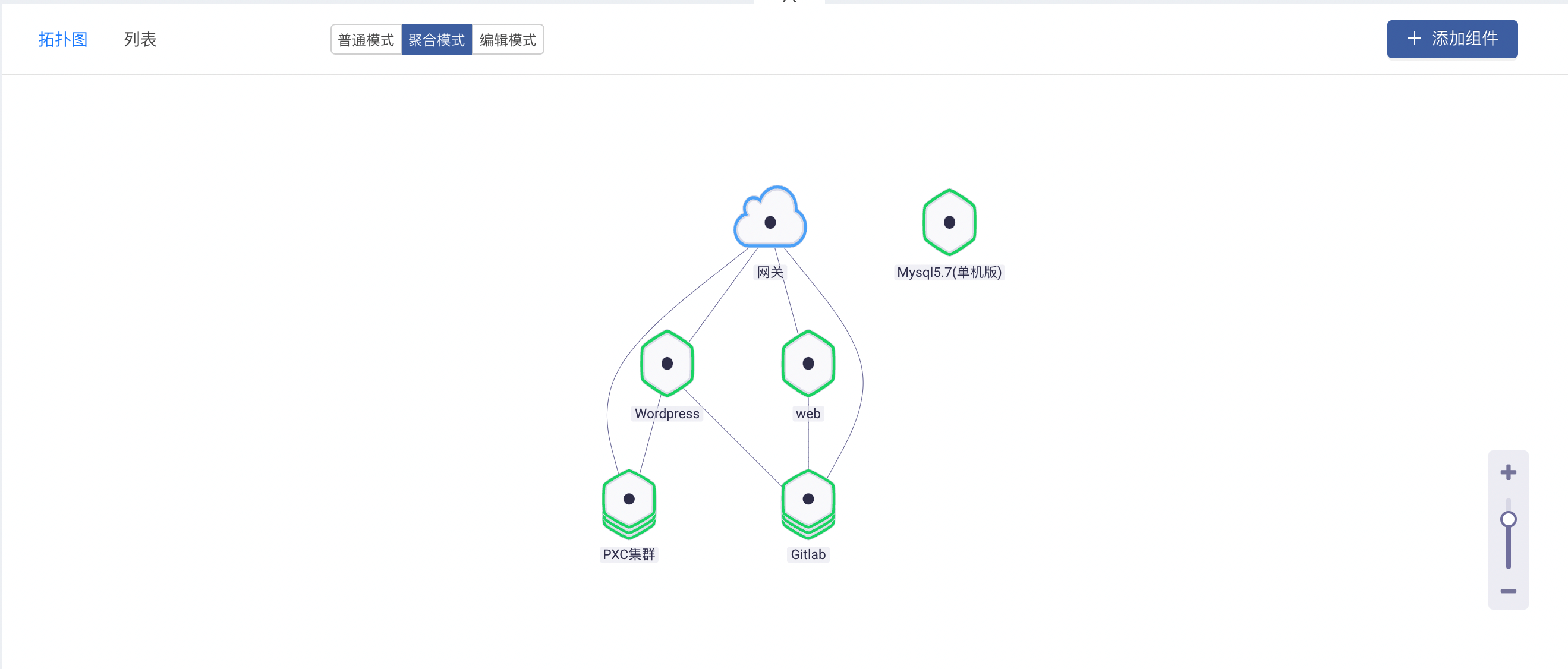
Rainbow version 5.6 was released, adding a variety of installation methods and optimizing the topology operation experience
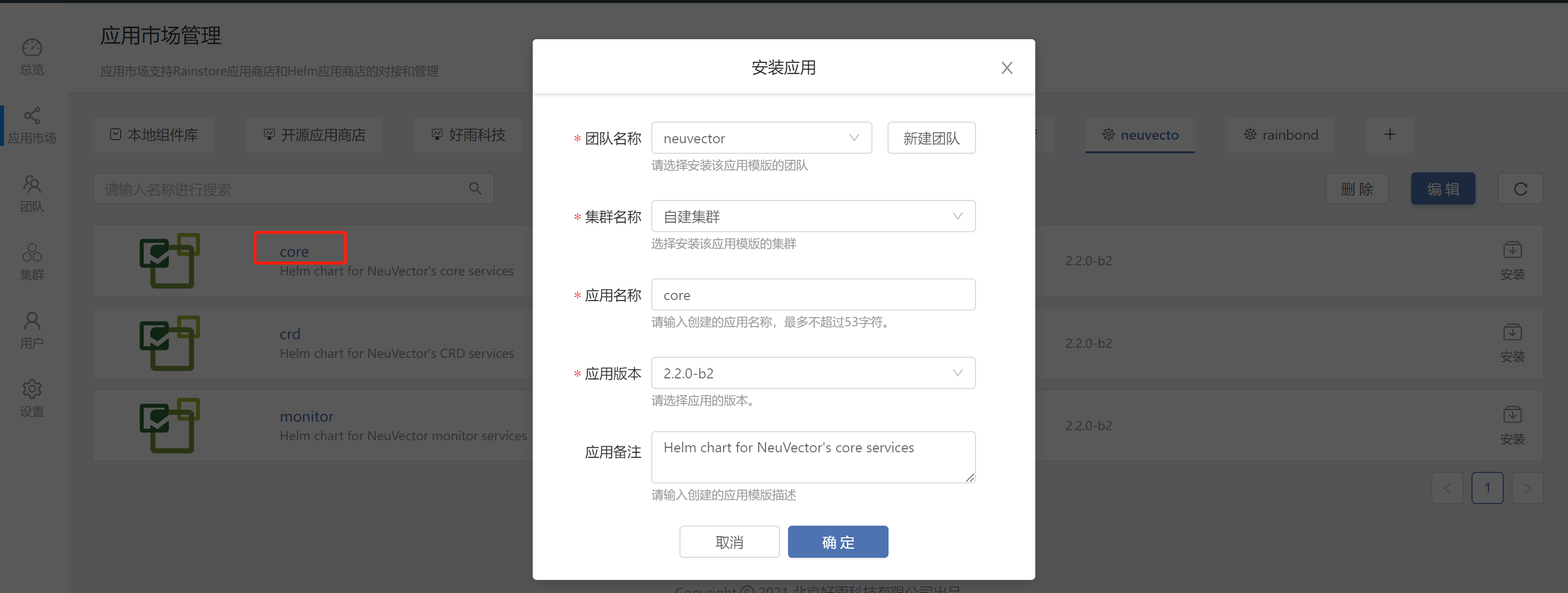
Rainbow combines neuvector to practice container safety management
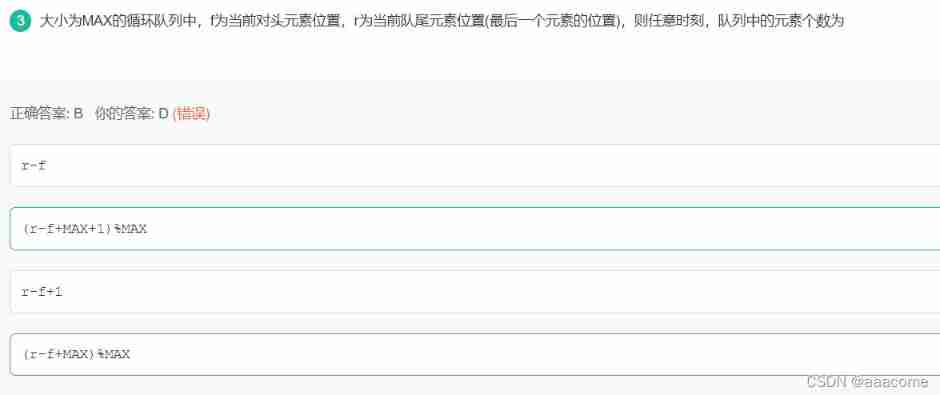
Exercise arrangement 2.10, 11

Analyzing the influence of robot science and technology development concept on Social Research
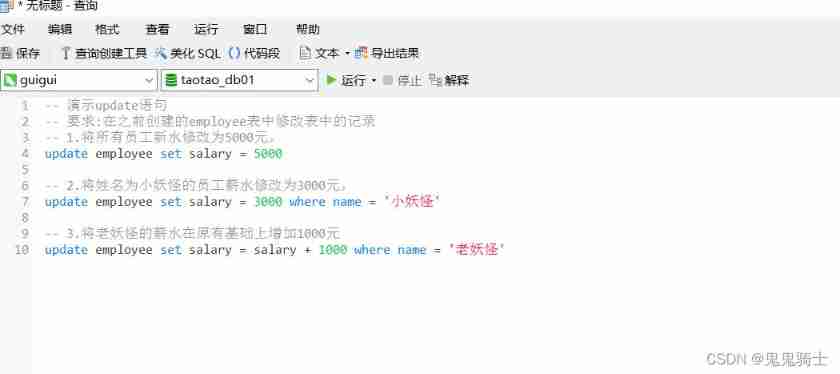
MySQL introduction - crud Foundation (establishment of the prototype of the idea of adding, deleting, changing and searching)
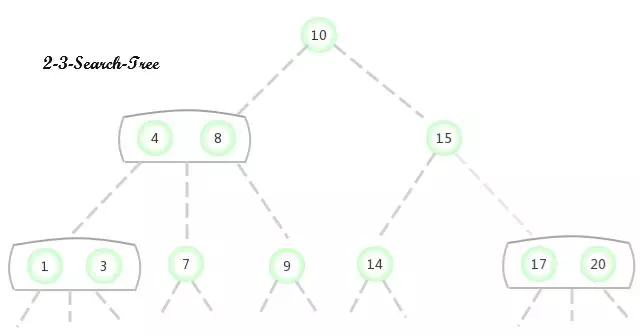
2-3查找樹
随机推荐
mysql分区讲解及操作语句
路由信息协议——RIP
基本数据类型和string类型互相转化
JEditableTable的使用技巧
MES system is a necessary choice for enterprise production
Implementation method of data platform landing
快速集成认证服务-HarmonyOS平台
How to understand distributed architecture and micro service architecture
Ebpf cilium practice (2) - underlying network observability
【无标题】
[IELTS speaking] Anna's oral learning records Part3
Golan idea IntelliJ cannot input Chinese characters
Train your dataset with swinunet
单场带货涨粉10万,农村主播竟将男装卖爆单?
[paper reading] icml2020: can autonomous vehicles identify, recover from, and adapt to distribution shifts?
grpc、oauth2、openssl、双向认证、单向认证等专栏文章目录
MES系統,是企業生產的必要選擇
Practice of implementing cloud native Devops based on rainbow library app
GFS distributed file system
Virtual address space