当前位置:网站首页>Moco V2 literature research [self supervised learning]
Moco V2 literature research [self supervised learning]
2022-07-05 02:30:00 【A classmate Wang】
Personal profile :
Nanjing University of Posts and telecommunications , Computer science and technology , Undergraduate
● A foreword :《MoCo v1 Literature research [ Self supervised learning ]》
● A foreword :《SimCLR v1 Literature research [ Self supervised learning ]》
List of articles

Ⅰ. Abstract
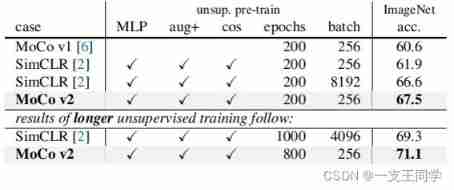
● Theoretical contribution :MoCo v2 Integrated MoCo v1 and SimCLR v1 Algorithm , It is the epitome of the two , And comprehensively surpass SimCLR. It absorbs SimCLR Two important improvements of :
① Use one MLP Projection head [using an MLP projection head]
② More data enhancements [more data augmentation]
● Additional explanation : No need for image SimCLR Use oversized 『 Batch size (batch size)』, Ordinary 8 Zhang gpu Ready to train .
● experimental result :MoCo v2 With 『 iteration (epochs)』 and 『 Batch size (batch size)』 All ratio SimCLR Small , But the accuracy is higher than it .
Ⅱ. Introduction
● Introduction( Preface ) yes Abstract( Abstract ) An extension of . Here slightly .
Ⅲ. Background
● Here is a simple restatement in the paper MoCo v1.
Ⅳ. Experiments
4.1 Parameter setting [Settings]
● Data sets : 1.28 M 1.28M 1.28M ImageNet
● Follow two common evaluation protocols :
① ImageNet Linear classification : Freeze feature , Training supervised linear classifiers . And record the single cutting (224×224) after ,Top-1 The accuracy of .
②『 transfer (Transferring)』 To VOC Object detection : Use COCO『 Measurement Suite (suite of metrics)』 Yes VOC 07 The test set is evaluated .
● They use with MoCo The same super parameter ( Unless otherwise noted ) And the code base . All results are in standard size ResNet-50.
4.2 “MLP Projection head ”[MLP head]
● They will MoCo Medium f c fc fc Replace the header with 2 layer M L P MLP MLP head ( Hidden layer is 2048-d, Use ReLU). Be careful , This only affects the unsupervised training stage . Linear classification or 『 transfer (Transferring)』 Phase does not use this M L P MLP MLP head .
● They first look for one about the following I n f o N C E InfoNCE InfoNCE『 Compare the loss function (contrastive loss function)』 The best “ Temperature parameters τ τ τ”: L q , k + , { k − } = − l o g e x p ( q ⋅ k + / τ ) e x p ( q ⋅ k + / τ ) + ∑ k − e x p ( q ⋅ k − / τ ) \mathcal{L}_{q,k^+,\{k^-\}}=-log\dfrac{exp(q·k^+/τ)}{exp(q·k^+/τ)+\sum_{k^-}exp(q·k^-/τ)} Lq,k+,{ k−}=−logexp(q⋅k+/τ)+∑k−exp(q⋅k−/τ)exp(q⋅k+/τ)
● give the result as follows :
● Then they use the best τ τ τ, Let its default value be 0.2 To do follow-up experiments :
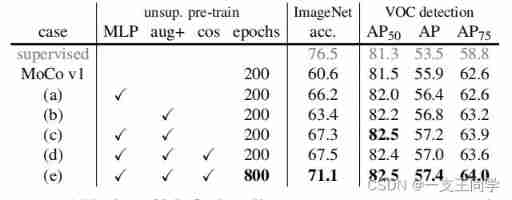
◆ Description of the above table :
① The gray line is the accuracy of self-monitoring (Top-1).
② The second line is “ Intact MoCo v1”.
③ Next “(a)、(b)、、(d)、(e)” It's different comparative experiments .
④ Sinister “unwup. pre-train” Aiming at “ImageNet Linear classification ”.
⑤ Dexter “VOC detection” Aiming at “VOC Object detection ”.
⑥ “MLP”: Contains a multi-layer perceptron [with an MLP head].
⑦ “aug+”: Image enhancement with additional Gaussian blur [with extra blur augmentation].
⑧ “cos”: Use cosine learning rate [cosine learning rate schedule].
● You can find ,“ImageNet Linear classification ” Than “VOC Object detection ” The benefits are greater .
4.3 Image enhancement [Augmentation]
● They expanded the original 『 Data to enhance (data augmentation)』 methods , New 『 Blur enhancement (blur augmentation)』. And they also found that SimCLR Used in the 『 Color distortion (color distortion)』 In their model, the return performance will decrease .
● Detailed results can be found in “4.2” That kind of picture . The last thing to say is :“ Accuracy of linear classification ” And “ Performance of migrating to target detection ” Not monotonically related . Because the former gains more , The latter is not very profitable .
4.4 and SimCLR Compare [Comparison with SimCLR]
● Obvious ,MoCo v2 Perfect victory SimCLR.
4.5 Calculate the cost [Computational cost]
● MoCo v2 Yes, it is 8 individual “V100 16G GPU” , And in Pytorch Implemented on the . It and “ End to end (end-to-end)” The required “ Space / Time cost ” Here's a comparison :

Ⅴ. Discussion
● There is no discussion in the paper . Write a personal opinion here . He Kaiming's team is great , Every time I read their MoCo A series of documents , I feel like I'm “ To see only one spot ”, Clear logic 、 The method is novel 、 The algorithm is concise 、 The results are eye-catching 、 Summarize in place . EH , Though not to , However, my heart is yearning for it .
Ⅵ. Summary
● MoCo v2 Is in SimCLR Published one after another , It's a very short article , Only 2 page . stay MoCo v2 in , The authors integrate SimCLR The two main promotion methods in... Are MoCo in , And verified SimCLR The effectiveness of the algorithm .SimCLR The two ways to raise points are :
① Use powerful 『 Data to enhance (data augmentation)』 Strategy , Specifically, additional use 『 Gaussian blur (Gaussian Deblur)』 Image enhancement strategies and the use of huge 『 Batch size (batch size)』, Let the self supervised learning model see enough at every step of training 『 Negative sample (negative samples)』, This will help the self supervised learning model to learn better 『 Visual representation (Visual Representation)』.
② Use prediction header “ Projection head g ( ⋅ ) g(·) g(⋅)”. stay SimCLR in ,『 Encoder (Encoder) 』 Got 2 individual 『 Visual representation (Visual Representation)』 Re pass “ Projection head g ( ⋅ ) g(·) g(⋅)” Further features , The prediction head is a 2 Layer of MLP, take 『 Visual representation (Visual Representation)』 This 2048 The vector of dimension is further mapped to 128 dimension 『 Hidden space (latent space)』 in , Get new 『 characterization (Representation)』. Or use the original to ask 『 Contrast the loss (contrastive loss)』 Finish training , Throw it away after training “ Projection head g ( ⋅ ) g(·) g(⋅)”, Retain 『 Encoder (Encoder) 』 Used to get 『 Visual representation (Visual Representation)』.
This article refers to appendix
MoCo v1 Original paper address :https://arxiv.org/pdf/2003.04297.pdf.
[2] 《7. Unsupervised learning : MoCo V2》.
️ ️
边栏推荐
- Educational Codeforces Round 122 (Rated for Div. 2) ABC
- Yolov5 model training and detection
- Cut! 39 year old Ali P9, saved 150million
- Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
- Prometheus monitors the correct posture of redis cluster
- LeetCode 314. Binary tree vertical order traversal - Binary Tree Series Question 6
- Chinese natural language processing, medical, legal and other public data sets, sorting and sharing
- Scientific research: are women better than men?
- STM32 series - serial port UART software pin internal pull-up or external resistance pull-up - cause problem search
- Talk about the things that must be paid attention to when interviewing programmers
猜你喜欢
Summary and practice of knowledge map construction technology

The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
Three properties that a good homomorphic encryption should satisfy

Stored procedure and stored function in Oracle

Practice of tdengine in TCL air conditioning energy management platform
【LeetCode】222. The number of nodes of a complete binary tree (2 mistakes)
Pytest (5) - assertion
Openresty ngx Lua Execution stage

Problem solving: attributeerror: 'nonetype' object has no attribute 'append‘
Grub 2.12 will be released this year to continue to improve boot security
随机推荐
CAM Pytorch
Process scheduling and termination
Character painting, I use characters to draw a Bing Dwen Dwen
Restful fast request 2022.2.1 release, support curl import
Official announcement! The third cloud native programming challenge is officially launched!
Codeforces Round #770 (Div. 2) ABC
Runc hang causes the kubernetes node notready
tuple and point
官宣!第三届云原生编程挑战赛正式启动!
Bert fine tuning skills experiment
如何搭建一支搞垮公司的技術團隊?
8. Commodity management - commodity classification
179. Maximum number - sort
[机缘参悟-38]:鬼谷子-第五飞箝篇 - 警示之一:有一种杀称为“捧杀”
Hmi-31- [motion mode] solve the problem of picture display of music module
JVM's responsibility - load and run bytecode
2022/02/13
Unpool(nn.MaxUnpool2d)
d3js小记
Day_ 17 IO stream file class