当前位置:网站首页>Elfk deployment
Elfk deployment
2022-07-05 02:29:00 【No such person found 0330】
Catalog
Elasticsearch Deploy ( stay Node1、Node2 Operation on node )
Logstash Deploy ( stay Apache Operation on node )
install Apahce service (httpd)
install Java Environmental Science
Set up Kibana Primary profile for
Create a log file , start-up Kibana service
Filter Functions of common plug-ins
ELFK= ES + logstash+filebeat+kibana
| Server type | Systems and IP Address | Components that need to be installed | Hardware aspect |
|---|---|---|---|
| node1 node | 192.168.52.110 | JDK、elasticsearch-6.7.2 | 2 nucleus 4G |
| node2 node | 192.168.52.120 | JDK、elasticsearch-6.7.2 | 2 nucleus 4G |
| apache node | 192.168.52.130 | JDK、apache、logstash-6.7.2、kabana-6.7.2、filebeat-6.7.2 | 2 nucleus 4G |
Environmental preparation
All nodes
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
Elasticsearch Deploy ( stay Node1、Node2 Operation on node )
install elasticsearch—rpm package
# Upload elasticsearch-6.7.2.rpm To /opt Under the table of contents
cd /opt
rpm -ivh elasticsearch-6.7.2.rpm
modify elasticsearch Master profile
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17-- uncomment , Specify the cluster name
cluster.name: my-elk-cluster
--23-- uncomment , Specify the node name :Node1 The node is node1,Node2 The node is node2
node.name: node1
node.master: true # whether master node ,false Why not
node.data: true # Whether the data node ,false Why not
--35-- uncomment , Specify the data storage path
path.data: /var/lib/elasticsearch
--39-- uncomment , Specify the log storage path
path.logs: /var/log/elasticsearch
--45-- uncomment , avoid es Use swap Swap partition
bootstrap.memory_lock: true
--57-- uncomment , Set listening address ,0.0.0.0 For all addresses
network.host: 0.0.0.0
--51-- uncomment ,ES The default listening port of the service is 9200
http.port: 9200 # Appoint es The cluster provides an interface for external access
transport.tcp.port: 9300 # Appoint es Internal communication interface of the cluster
--71-- uncomment , Cluster discovery is realized by unicast , Specify the nodes to discover
discovery.zen.ping.unicast.hosts: ["192.168.80.10:9300", "192.168.2.11:9300"]
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
es Performance tuning parameters
Optimize the maximum memory size and the maximum number of file descriptors
vim /etc/security/limits.conf
......
* soft nofile 65536
* hard nofile 131072
* soft memlock unlimited
* hard memlock unlimited
systemctl daemon-reexec
vim /etc/sysctl.conf
# The maximum number of memory mapped areas a process can have , Reference data ( Distribute 2g/262144,4g/4194304,8g/8388608)
vm.max_map_count=262144
sysctl -p
sysctl -a | grep vm.max_map_count
start-up elasticsearch Is it successfully opened
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
netstat -antp | grep 9200
View node information
Browser access http://192.168.52.110:9200 、 http://192.168.52.120:9200 Look at the node Node1、Node2 Information about .
Browser access http://192.168.239.10:9200/_cluster/state?prettyhttp://192.168.52.110:9200http://192.168.239.10:9200/_cluster/state?pretty Check the cluster status information .
Logstash Deploy ( stay Apache Operation on node )
install Apahce service (httpd)
yum -y install httpd
systemctl start httpd
install Java Environmental Science
yum -y install java
java -version
install logstash
# Upload package logstash-6.7.2.rpm To /opt Under the table of contents
cd /opt
rpm -ivh logstash-6.7.2.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
install Kiabana
# Upload package kibana-6.7.2-x86_64.rpm To /opt Catalog
cd /opt
rpm -ivh kibana-6.7.2-x86_64.rpm
Set up Kibana Primary profile for
vim /etc/kibana/kibana.yml
--2-- uncomment ,Kiabana The default listening port of the service is 5601
server.port: 5601
--7-- uncomment , Set up Kiabana The monitoring address of ,0.0.0.0 For all addresses
server.host: "0.0.0.0"
--28-- uncomment , To configure es Server's ip, If it is a cluster, configure it master Node ip
elasticsearch.url: ["http://192.168.52.110:9200","http://192.168.52.120:9200"]
--37-- uncomment , Set in the elasticsearch Add .kibana Indexes
kibana.index: ".kibana"
--96-- uncomment , To configure kibana Log file path for ( You need to create... Manually ), Otherwise, the default is messages Keep a log in the library
logging.dest: /var/log/kibana.log
Create a log file , start-up Kibana service
touch /var/log/kibana.log
chown kibana:kibana /var/log/kibana.log
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601
Create index
take Apache Log of the server ( Access to the 、 FALSE ) Add to Elasticsearch And pass Kibana Show
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log" # Specify the exact directory location
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log" # Specify the error log directory
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.52.110:9200","192.168.52.120:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.52.110:9200","192.168.52.120:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
logstash -f apache_log.conf
At this time, the browser accesses http://192.168.52.130 Add access log
Browser access http://192.168.52.110:5601/ Sign in Kibana Create index
Filebeat+ELK Deploy
stay apache Operation on node
install Filebeat
# Upload package filebeat-6.7.2-linux-x86_64.tar.gz To /opt Catalog
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat
Set up filebeat Primary profile for
vim filebeat.yml
filebeat.prospectors:
- type: log # Appoint log type , Read message from log file
enabled: true
paths:
- /var/log/messages # Specify the log file to monitor
- /var/log/*.log
tags: ["sys"] # Set index label
fields: # have access to fields Configure options to set some parameter fields to output in
service_name: filebeat
log_type: syslog
from: 192.168.52.130
--------------Elasticsearch output-------------------
( Comment all out )
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.52.130:5044"] # Appoint logstash Of IP And port
# start-up filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#-e: Output to standard output , Ban syslog/ File output
#-c: Specify profile
#nohup: Run commands without hanging up in the background of the system , Quitting the terminal will not affect the running of the program
stay Logstash Create a new node on the node where the component is located Logstash The configuration file
cd /etc/logstash/conf.d
vim filebeat.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.52.110:9200","192.168.52.120:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
# start-up logstash
logstash -f filebeat.conf
Browser access http://192.168.52.130:5601 Sign in Kibana, single click “Create Index Pattern” Button to add an index “filebeat-*”, single click “create” Button to create , single click “Discover” Button to view chart information and log information .
At this time, add the cable
Filter plug-in unit
And for Logstash Of Filter, That's it Logstash The most powerful place .Filter There are many plug-ins , We often use it grok、date、mutate、mutiline Four plug-ins .
about filter The implementation process of each plug-in of , You can see the picture below :

Filter Functions of common plug-ins
grok : Divide several large text fields into small fields
date: Unify and format the time format in the data
mutate: Eliminate some useless fields , Or add fields
mutiline : Arrange multiple rows of data in a unified way , Split multiple lines
grok plug-in unit
Match format :(?< Field name > Regular expressions )
I'm gonna use it here logstash Of filter Medium grok plug-in unit .filebeat Send to logstash The contents of the log will be put in message In the field ,logstash Match this message Fields are OK . The configuration items are as follows :
Example 1
(?<remote_addr>%{IPV6}|%{IPV4} )(?<other_info>.+)
# Split the data ip Field called remote_addr, Other fields are named other_info
Example 2
(?<remote_addr>%{IPV6}|%{IPV4} )[\s\-]+\[(?<log_time>.+)\](?<other_info>.+)
# Add a match time field
Example 3
# Split multiple fields
(?<remote_addr>%{IPV6}|%{IPV4})[\s\-]+\[(?<log_time>.+)\]\s+\"(?<http_method>\S+)\s+(?<url-path>.+)\"\s+(?<rev_code>\d+)(?<other_info>.+)
Write this regular to the configuration file to filter the data
cd /etc/logstash/conf.d/
cp filebeat.conf filter.conf
vim filter.conf
input {
beats {
port => "5044"
}
}
filter {
grok {
match =>["message","(?<remote_addr>%{IPV6}|%{IPV4} )[\s\-]+\[(?<log_time>.+)\]\s+\"(?<http_method>\S+)\s+(?<url-path>.+)\"\s+(?<rev_code>\d+)(?<other_info>.+)"]
}
}
output {
elasticsearch {
hosts => ["192.168.52.110:9200","192.168.52.120:9200"]
index => "{[filter][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
logstash -f filter.conf# start-up
At this time, enter kibana View and add index
Add index
View add fields
边栏推荐
- The MySQL team development specifications used by various factories are too detailed. It is recommended to collect them!
- The most powerful new household god card of Bank of communications. Apply to earn 2100 yuan. Hurry up if you haven't applied!
- The steering wheel can be turned for one and a half turns. Is there any difference between it and two turns
- Chinese natural language processing, medical, legal and other public data sets, sorting and sharing
- 【附源码】基于知识图谱的智能推荐系统-Sylvie小兔
- [technology development-26]: data security of new information and communication networks
- How to find hot projects in 2022? Dena community project progress follow-up, there is always a dish for you (1)
- Pytest (5) - assertion
- 2022/02/13
- Last week's hot review (2.7-2.13)
猜你喜欢
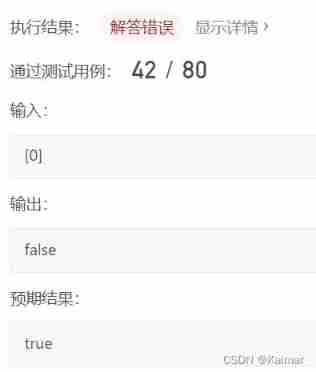
【LeetCode】98. Verify the binary search tree (2 brushes of wrong questions)

Comment mettre en place une équipe technique pour détruire l'entreprise?

Avoid material "minefields"! Play with super high conversion rate
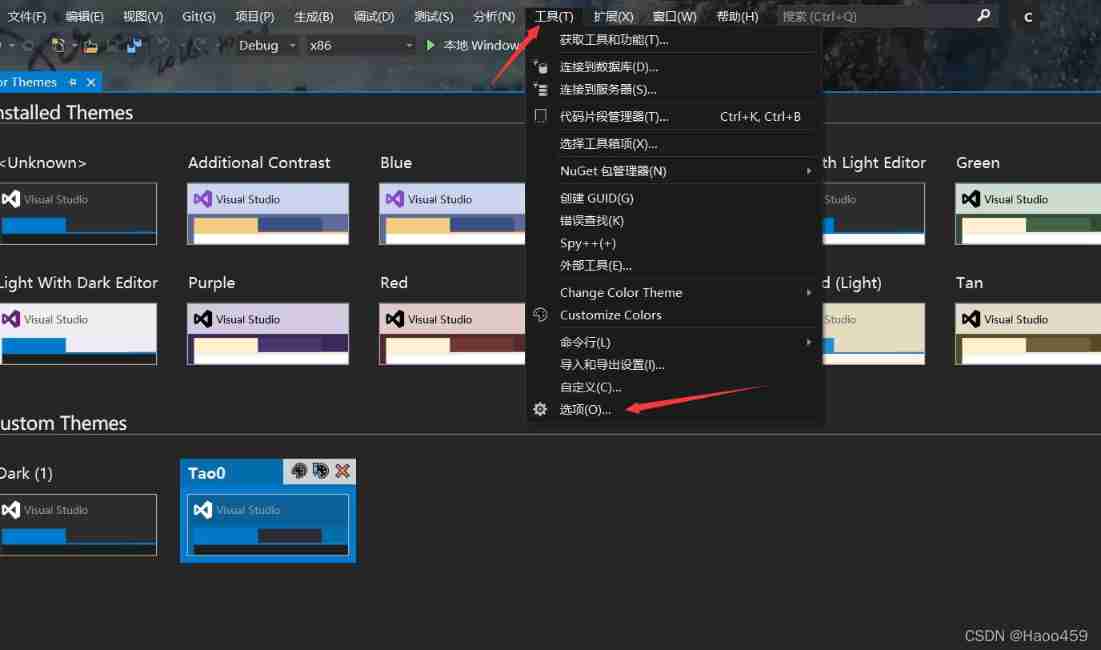
Visual studio 2019 set transparent background (fool teaching)
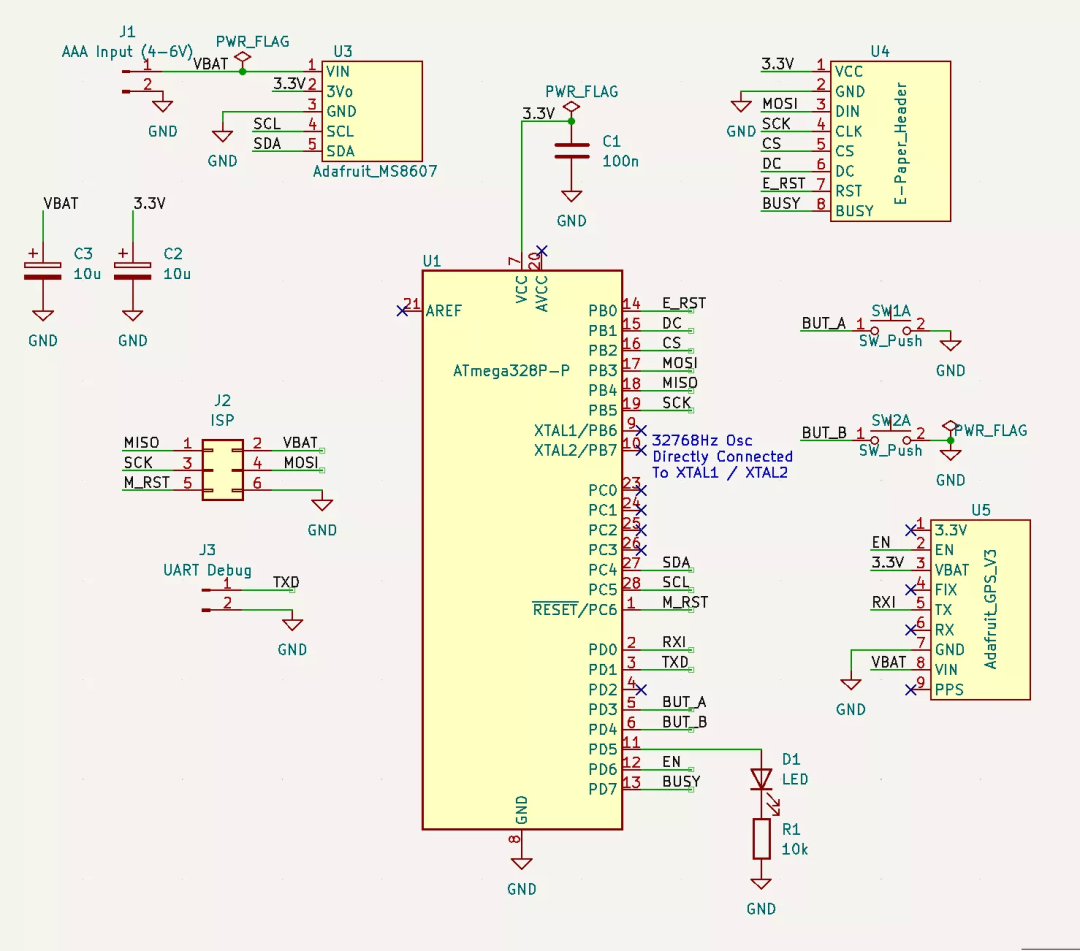
How to make a cool ink screen electronic clock?

【附源码】基于知识图谱的智能推荐系统-Sylvie小兔

Go RPC call

Missile interception -- UPC winter vacation training match
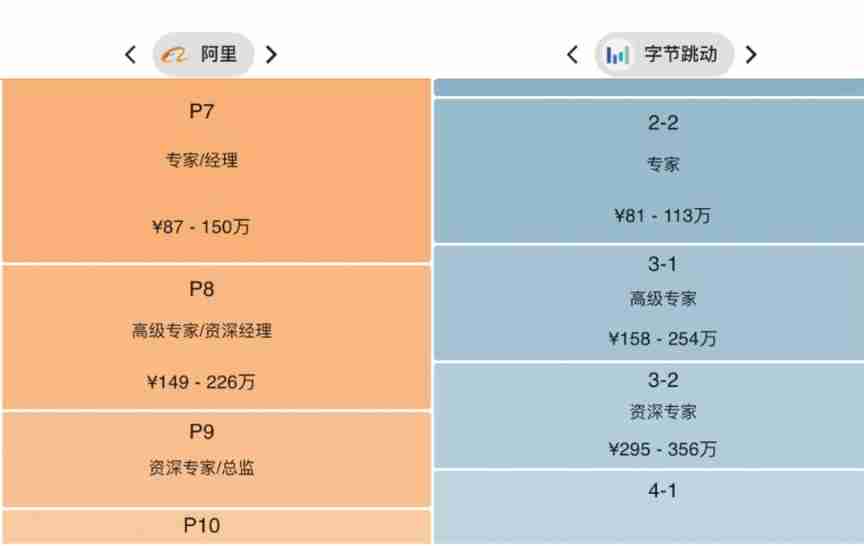
He was laid off.. 39 year old Ali P9, saved 150million
Security level
随机推荐
Avoid material "minefields"! Play with super high conversion rate
Exploration of short text analysis in the field of medical and health (I)
RichView TRVStyle MainRVStyle
Privatization lightweight continuous integration deployment scheme -- 01 environment configuration (Part 1)
Educational Codeforces Round 122 (Rated for Div. 2) ABC
[Yu Yue education] National Open University spring 2019 0505-22t basic nursing reference questions
Interpretation of mask RCNN paper
Pytest (4) - test case execution sequence
Learn game model 3D characters, come out to find a job?
ASP. Net core 6 framework unveiling example demonstration [01]: initial programming experience
Blue bridge - maximum common divisor and minimum common multiple
Some query constructors in laravel (2)
Problem solving: attributeerror: 'nonetype' object has no attribute 'append‘
Naacl 2021 | contrastive learning sweeping text clustering task
When the low alcohol race track enters the reshuffle period, how can the new brand break the three major problems?
Three properties that a good homomorphic encryption should satisfy
[uc/os-iii] chapter 1.2.3.4 understanding RTOS
JVM - when multiple threads initialize the same class, only one thread is allowed to initialize
[source code attached] Intelligent Recommendation System Based on knowledge map -sylvie rabbit
Talk about the things that must be paid attention to when interviewing programmers