当前位置:网站首页>Naacl 2021 | contrastive learning sweeping text clustering task
Naacl 2021 | contrastive learning sweeping text clustering task
2022-07-05 02:02:00 【Necther】
introduction
After all, West Lake is in June , The scenery is not the same as the four seasons . The lotus leaves are endless , The lotus against the sun is different . Hello, guys , I'm a little boy selling hot and dry noodles , Today I share with you Amazon's publication on NAACL 2021 An article on :Supporting Clustering with Contrastive Learning. This article combines with popular traffic Xiaosheng 「 Comparative learning 」 Propose a simple and effective 「 Unsupervised text clustering 」 Method :SCCL. The model blew out 7 A short text clustering task ,6 To fly up ~

「 Address of thesis 」
https://arxiv.org/abs/2103.12953
「 Paper code 」
https://github.com/amazon-research/sccl
brief introduction
Here first QA The way is briefly introduced Supporting Clustering with Contrastive Learning What does this paper do .
Q1: What problem does the article want to solve ?
A1: The article is dedicated to solving 「 Unsupervised clustering 」 Mission . The so-called unsupervised clustering task is to distinguish different by specific similarity measures in the representation space 「 Semantic clusters 」. It can be seen that , This involves 2 aspect , Input how to characterize and how to measure the similarity between representations . The representation space obtained by the existing scheme has been 「 overlap 」, This start makes it difficult for subsequent clustering algorithms to break through its front ceiling .
Q2: How does the article solve the above problems ?
A2: The article combines 「 Comparative learning 」 Propose a method called SCCL(Supporting Clustering with Contrastive Learning) Model of . The model combines bottom-up Examples of comparative learning and top-down The clustering , Better clustering results are obtained .
Q3: How effective is the solution of the article ?
A3: This paper focuses on the task of short text clustering SCCL To evaluate . Experimental results show that ,SCCL In the vast majority benchmark The data set is significantly better than the previous SOTA Method . In terms of accuracy 3%-11% The advantages of rolling predecessors , The normalized mutual information is higher than 4%-15% The advantage of hanging before SOTA Model .

SCCL
Here is a brief introduction to comparative learning , Then I will introduce in detail the SCCL Model .
Comparative learning
Self supervised learning goes beyond CV field , stay CV Self supervision in the field can be divided into two types :「 Generative 」 and 「 Discriminant 」 Self supervised learning .VAE and GAN It is a typical representative of generative self supervised learning , This kind of method requires the model to reconstruct the image or part of the image , The task is relatively difficult , Pixel level reconstruction is required , The image coding in the middle must contain many details . Comparative learning is typical 「 Discriminant 」 Self supervised learning , Relative generative self supervised learning , The task of comparative learning is less difficult . However , At present, the effect of several comparative learning models has exceeded that of supervised models , The result is really exciting , No wonder the two giants of deep learning Bengio and LeCun stay ICLR 2020 Roll call Self-Supervised Learning(SSL, Self supervised learning ) yes AI The future of .
In recent years, comparative learning has become increasingly popular , All gods are like Hinton、Yann LeCun、Kaiming He Etc. have also frequently fought in this research direction . from CV In the field MoCo series 、SimCLR series 、BYOL、SwAV And more recently NLP In the field SimCSE, Various methods learn from each other , Each has its own innovation , It can be said that there are hundreds of disputes ( Inside ) singing ( volume ). Contrastive learning is a kind of self supervised learning , Such methods do not rely on annotation data , Instead, learn knowledge from unmarked data . The core idea of comparative learning is to construct similar instances and dissimilar instances , So as to acquire a representation learning model , Through this model , Similar instances are relatively close in the representation space , But dissimilar instances are far away in the representation space .
SCCL frame
SCCL The framework process is as follows Figure 2 Shown .

SCCL from 3 Part of it is made up of : Neural network feature extraction layer 、clustering head and Instance-CL head. The feature extraction layer maps the input to the vector representation space ,SCCL It's using Sentence Transformer released distilbert-base-nli-stsb-mean-tokens Pre training model , The model download address :https://huggingface.co/sentence-transformers/distilbert-base-nli-stsb-mean-tokens/tree/main .Instance-CL head ( Write it down as ) and clustering head ( Write it down as ) Respectively use 「contrastive loss and clustering loss」.Instance-CL head from 「 monolayer MLP」 form , Its activation function uses ReLU. The input dimension is 768, The output dimension is 128. as for clustering head It is a 「 Linear mapping layer 」, Dimension is 768*K, among K Is the number of clusters . therefore , The overall network structure is very concise ~
The picture below is in SearchSnippets On dataset TSNE Visualization results . among Clustering and Instance-CL Respectively refers to using only SCCL One species head Result . You can see the combination 2 Kind of head Of SCCL Clustering results are more fragrant ~ That is, using comparative learning SCCL You can spread out the overlapping categories .

Instance-CL head
Instance-CL(Instance-wise Contrastive Learning) It is already the most dazzling new star in self supervision .Instance-CL First, we use data amplification method to enhance the sample data to get an auxiliary data set , Then optimize based on this data set . Use in the optimization process contrastive loss Make the enhanced samples from the same instance close to each other in the representation space , The enhanced samples from different instances are far away from each other in the representation space . In other words ,Instance-CL Disperse instances of different origins , To some extent, approximate instances are implicitly gathered . This attribute makes it possible to break up overlapping categories . Finally, cluster , Thus, different clusters can be better separated , At the same time, the cluster is more compact , That is, the distance between samples in the cluster is smaller .
Use Instance-CL Method , Different instances are well separated in the learned representation space , And maintain the local invariance of each instance . although Instance-CL Can come from different... In the representation space The instances of the original instance are divided into the same group , And ignore these instances that come from different original instances but are semantically similar . therefore ,Instance-CL The implicit grouping of is not very stable , And it depends on the amount of data , Thus, its generalization ability is insufficient .
One batch size by M Each instance of is obtained by data amplification 2 Amplified instances ( At this time, the expanded data set has 2M An example ). Examples of the same amplification source are regarded as a pair of positive samples , remainder 2M-2 Instances are regarded as negative samples .
For a pair of positive samples , about , Try to The loss function separated from all negative samples is as follows :
among Express clustering head Output of positive sample pair . Is an indicator function .sim The function is doc product, namely . therefore , On the entire expanded data set 「Instance-CL loss」 as follows :
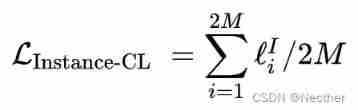
Besides , The article further explores 3 Two data amplification methods are right SCCL Influence , It turns out that contextual augmenter It works best .PS: More details are provided later .
Clustering head
meanwhile ,SCCL When encoding category semantic information 「 Unsupervised clustering 」. Clustering tasks and Instance-CL Different , Its focus is on high-level semantic concepts , And try to put together instances from the same semantic category . Suppose there is K Categories ( cluster ), Each category is represented by its centroid : . Original instance The representation in the representation space is as follows : .SCCL Use t The original instance of distributed computing is divided into k The probability of categories :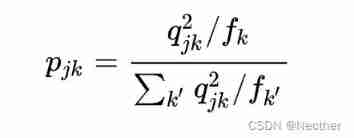
among Express t The degrees of freedom of distribution , Here the value is set to 1.
SCCL Use a linear mapping layer , namely Figure 2 Medium cluster head To approximate the center of each category , And an auxiliary distribution is used to iteratively optimize it . Auxiliary probability is defined as follows :
among Can be regarded as soft One of the cluster frequencies mini-batch The approximate . The target distribution first passes through a second-order soft Distribution probability Make it sharp , Then it is normalized by the frequency of related categories . This can promote learning from high confidence categories , At the same time, it will reduce the deviation caused by category imbalance .
adopt KL Divergence will distribute the probability of categories (
 ) Distribute to the target ( ) near :
) Distribute to the target ( ) near :
therefore , The clustering objective function is defined as follows :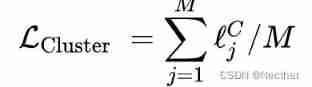
therefore , The overall objective function is as follows :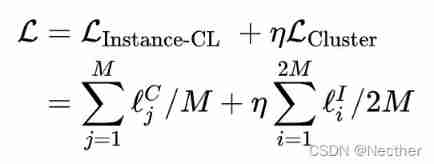
It should be noted that :clustering loss Optimize only on the original data set , It does not involve the expanded data set ; and Instance-CL loss It is for the expanded data set .
Experimental results
The article uses 8 Short text dataset validation SCCL The effectiveness of the , The evaluation index uses ACC(Accuracy) and NMI(Normalized Mutual Information). Specific evaluation results are as follows Table 1 Shown :

It can be seen from the experimental results above ,SCCL Before hanging on almost all data sets SOTA Method .SCCL stay Biomedical The frustration on the data set is entirely due to the low correlation between the task data and the pre training data set , Its SOTA The model is based on a large number of biomedical corpus ~
Melting research :Instance-CL and Clustering Is the optimization of separate or joint ?
SCCL There are two loss functions :Clustering loss and Instance-CL loss . So for this 2 Optimization of loss function , It's choice pipeline The way is optimized one by one , Or use joint optimization ? The article also further compares the effect of using only one of them , The specific experimental results are as follows Figure 3 Shown .

It can be seen from it that :
1) Use alone Instance-CL perhaps Clustering The effect is not as good as using both .
2) Joint optimization (SCCL) The effect is better than pipeline The way ( namely SCCL-Seq, Optimize first Instance-CL To optimize the Clustering) Optimize .
Which is the best amplification method ?
The article compares 3 Data amplification methods :
1)Augmenter WordNet (https://github.com/QData/TextAttack)
2)Augmenter Contextual(https://github.com/makcedward/nlpaug)
3)Paraphrase via back translation (https://github.com/pytorch/fairseq/tree/master/examples/paraphraser)
Above 3 The experimental results of these methods are as follows Table 3 Shown .

in general ,Contexual Augmenter (Ctxt) The effect is the best on all data sets . Under supplementary instructions ,Ctxt Is to use pre training Transformer( The thesis selects Bert-base and Roberta) Find top-n Insert or replace a suitable word . In addition, we can see , There are some datasets that show great differences under different amplification methods , such as SearchSnippers, Some of them are less sensitive , such as AgNews、Biomedical and GooglenewsTS.
The article also further tested the effect of mixed use of different amplification methods , The result is as follows Figure 5 Shown .

Blue means only Contextual Augmenter Data amplification , Orange means 「 successively 」 Use Contextual Augmenter and CharSwap Augmenter this 2 Data amplification methods . It can be seen from the experimental results that :
- stay GoogleNew-TS Mixed use on data sets 2 Two amplification methods will indeed improve , And it does not decrease with the increase of the proportion of replaced words in the enhanced amplification data ;
- stay StackOverflow Data sets are quite different , With the increase of replacement ratio , Use 2 Three amplification methods have led to a significant decline in performance .
To further explore the reasons , The researchers also compared different replacement ratios 、 Different hybrid amplification methods (1 Or 2 individual ) Next , Original text and expanded text cosine Similarity degree . From the above experimental results, it can be seen that , When mixed with 2 Two amplification methods ( Orange ) when , The similarity between the amplified text and the original text gradually decreases . let me put it another way , Use the 2 After three amplification methods ,StackOverflow The expanded data set deviates greatly from the original text in the representation space . This explains why mixed use 2 Two amplification methods do not necessarily improve the performance of the model .
summary
This paper is based on Instance-CL A model for unsupervised clustering task is proposed :SCCL.SCCL Through joint optimization Instance-CL Loss and clustering loss , Make the distance between different categories in the text semantic space larger , The distance within the class is shortened . Besides , stay 8 On a short text clustering dataset SCCL Make a full evaluation . Experimental results show that ,SCCL On most datasets SOTA result ,Accuracy Promoted 3% ~ 11%,NMI Promoted 4%~15%.
machine learning / Deep learning algorithm / Natural language processing communication group
Machine learning algorithm has been established - Natural language processing wechat communication group ! Students who want to study in the communication group , You can add my wechat directly :HIT_NLP. Make a remark when adding : You know + School + nickname ( I won't accept consent without remark , Hope to understand ), Want to enter pytorch Group , I don't know + School + nickname +Pytorch that will do . Then we can pull you into the group . There are already many college students in the group , The communication atmosphere is very good .
We highly recommend you to pay attention Machine learning algorithms and natural language processing Account number and Machine learning algorithms and natural language processing WeChat official account , Can quickly understand the latest high-quality dry goods resources .
Recommended reading
EMNLP 2021( Solicitation notice )+ Communication group
NAACL2021- Communication group
To novice alchemists :2021 Version adjustment can be found in the breaking up book
Distillation of knowledge : Give Way LSTM Back to the top !
The strongest Attention Function is born , Bring you an unexpected huge improvement !
New classification ! Full summary ! newest Awesome-SLU-Survey The repository is open source !
NaturalConv: A topic driven Chinese multi round conversation dataset
NUS&A* STAR: A simple and effective data augmentation method for n-shot Task based dialogue system
AAAI 2021 | Interpretation of the latest progress in machine translation
All over the world | Transformer carry Evolving Attention stay CV And NLP The whole field is rising
Facebook AI unified ! Use unity Transfomer Multimodal multi task learning
Google : Improve the state tracking ability of long text dialog
recommend ! Li Hongyi 《 machine learning 》 Mandarin Program (2021) go online !
CVPR 2021 The receiving result is released ! Employment 1663 piece , Acceptance rate 27%
Knowledge distillation technology in deep learning ( On )
There are a lot of big people AAAI 2021 Figure deep learning seminar
【 hiring 】 Tencent advertising business line
Sal's notes | Introduction to text level machine translation
GPT“ High imitation ” The series is open source ! Up to GPT-3 size , You can train on your own
ACL 2021 A guide to avoid pitfalls
Recommend some classics AI Books !
ICLR2021 under ! Admission 860 piece , The acceptance rate is 28.7%!
In computer vision Transformer
Complete diagram GPT-2: It's enough after reading this ( Two )
Complete diagram GPT-2: It's enough after reading this ( One )
One copy Python Lecture notes on Linear Algebra
The 20th Chinese Congress of computational linguistics (CCL 2021) Solicitation notice
NTU-Xavier Bresson Figure introduction to neural network video
2020 year arXiv Here are the top ten papers ! More than GPT-3、SimCLR、YOLOv4...
Daily essay delivery : Natural language processing (1 month 7 It's a new edition )
Weight decay and L2 Regularization doesn't make sense ?
Stanford university —— AI undergraduate 4 A list of courses for the year
exceed 500 A code attached AI/ machine learning / Deep learning / Computer vision /NLP project
Awesome Transformer for Vision Resources List library
2020 Top10 Computer vision paper summary : The paper , Code , Reading , also demo video !
156 A reference !Visual Transformer research survey
NLP Generate task pain points !58 page generation Review of evaluation
Machine learning drawing template ML Visuals to update
Google update 28 Page efficiency Transformer Model review
Papers with Code 2020 Looking back throughout the year
newest 14 page 《 Interpretability of graph neural network 》 A review paper
Written by Tao Dacheng et al ! newest 41 A summary of deep learning theory
Use PyTorch when , The most common 4 A mistake
Liu Bang, assistant professor, University of Montreal, Canada 2021/2022 Doctoral student
Article, understand PyTorch Internal mechanism
Recollection :AAAI 2021 The receiving list of papers is released !!!
Machine learning natural language processing : From the beginning, relationship extraction
Machine learning natural language processing :Transformer A family of !
Machine learning natural language processing :5 A common derivation of Neural Networks !
Machine learning natural language processing : The illustration Transformer( Full version )!
Machine learning natural language processing :2021 year , I finally decided to get started GCN
Machine learning natural language processing : Sort (rank) Rearranging (re-rank)?
Machine learning natural language processing : Formula modeling of Task-based dialogue system && Example is given to illustrate
Machine learning natural language processing : One article " See through " Multi task learning
Machine learning natural language processing : Collection |2021 On multi task learning
Machine learning natural language processing : Sort (rank) Rearranging (re-rank)?
Sal's notes | A brief introduction to comparative learning - You know (zhihu.com)
MLP Super detailed interpretation of the three major works :why do we need? - You know (zhihu.com)
ViLT: The simplest multimode Transformer - You know (zhihu.com)
Rethinking “Batch” in BatchNorm - You know (zhihu.com)
A review of the research on text emotional dialogue system - You know (zhihu.com)
100+ A collection of papers :GNN stay NLP Application in - You know (zhihu.com)
2021 Machine learning studies what the wind is ?MLP→CNN→Transformer→MLP! - You know (zhihu.com)
TransGAN: Two Transformer Can construct a powerful GAN - You know (zhihu.com)
Why Bayesian statistics is so important ? - You know (zhihu.com)
Sal's notes | An introduction to interpretable natural language processing - You know (zhihu.com)
Overview of natural language generation - You know (zhihu.com)
PyTorch Source code interpretation of distributed training to understand ? - You know (zhihu.com)
ICML2021 Accept the list of papers ! - You know (zhihu.com)
21 page NLP Overview of data augmentation methods on - You know (zhihu.com)
76 Page overview of the most complete dialogue system direction - You know (zhihu.com)
oriented Transformer Efficient pre training method of model - You know (zhihu.com)
Some problems of small target detection , Ideas and plans - You know (zhihu.com)
The latest review : Dialogically retrieve data set summary - You know (zhihu.com)
First facing NLP The map deep learning toolkit came out ! - You know (zhihu.com)
MLP is Best? - You know (zhihu.com)
FuPan's first scientific research experience in life - You know (zhihu.com)
ICLR2021 | Recent must read selected papers on Neural Networks - You know (zhihu.com)
AAAI near 20 Best collection of papers in - You know (zhihu.com)
边栏推荐
- Application and development trend of image recognition technology
- "2022" is a must know web security interview question for job hopping
- ICSI 311 Parser
- Limited query of common SQL operations
- The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
- PHP 约瑟夫环问题
- The application and Optimization Practice of redis in vivo push platform is transferred to the end of metadata by
- Vulnstack3
- R语言用logistic逻辑回归和AFRIMA、ARIMA时间序列模型预测世界人口
- Interesting practice of robot programming 16 synchronous positioning and map building (SLAM)
猜你喜欢

【LeetCode】88. Merge two ordered arrays

官宣!第三届云原生编程挑战赛正式启动!
JVM - when multiple threads initialize the same class, only one thread is allowed to initialize
线上故障突突突?如何紧急诊断、排查与恢复
R language uses logistic regression and afrima, ARIMA time series models to predict world population

小程序容器技术与物联网 IoT 可以碰撞出什么样的火花

Logstash、Fluentd、Fluent Bit、Vector? How to choose the appropriate open source log collector
Main window in QT application
The steering wheel can be turned for one and a half turns. Is there any difference between it and two turns
Introduce reflow & repaint, and how to optimize it?
随机推荐
Application and development trend of image recognition technology
The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
Win: enable and disable USB drives using group policy
C语音常用的位运算技巧
Lsblk command - check the disk of the system. I don't often use this command, but it's still very easy to use. Onion duck, like, collect, pay attention, wait for your arrival!
【附源码】基于知识图谱的智能推荐系统-Sylvie小兔
Using openpyxl module to write the binary list into excel file
Exploration and Practice of Stream Batch Integration in JD
[OpenGL learning notes 8] texture
Prometheus monitors the correct posture of redis cluster
Valentine's Day flirting with girls to force a small way, one can learn
Collection of gmat750 wrong questions
Win: use shadow mode to view the Desktop Session of a remote user
A label making navigation bar
Nebula importer data import practice
流批一体在京东的探索与实践
How to make a cool ink screen electronic clock?
Yyds dry inventory jetpack hit dependency injection framework Getting Started Guide
Variables in postman
Unified blog writing environment