One 、 Push platform features
vivo The push platform is vivo The message push service provided by the company to developers , By establishing a stable network between the cloud and the client 、 Reliable long connection , Provide developers with services to push messages to client applications in real time , Support 10 billion level notifications / Message push , Second touch mobile users .
The push platform is characterized by high concurrency 、 Large amount of news 、 High timeliness of delivery . At present, the highest push speed 140w/s, Maximum daily message volume 150 Billion , End to end second online delivery rate 99.9%.
Two 、 Push platform Redis Introduction
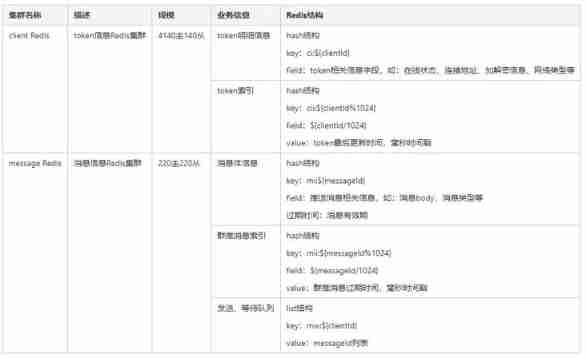
be based on vivo Features of push platform , High requirements for concurrency and timeliness , And there are a lot of messages , Short message validity . therefore , The push platform chooses to use Redis Middleware is used as message storage and transfer , as well as token Information storage . Before, we mainly used two Redis colony , use Redis Cluster Cluster pattern . The two clusters are as follows :
Yes Redis The operation of , It mainly includes the following aspects :
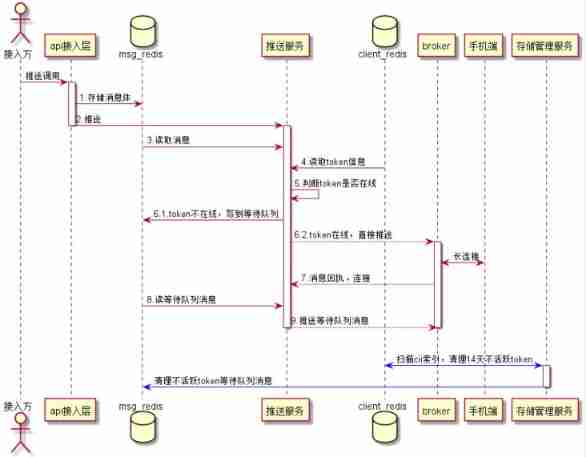
1) Push link , Store the message body in the access layer to msg Redis colony , Message expiration time is msg Redis The expiration time of the stored message .
2) The push service layer goes through a series of logic , from msg Redis The cluster finds the message body , Inquire about client Redis colony client Information , If client On-line , Push... Directly . If client Not online , The message is id Write to the waiting queue .
3) If connected , Push service layer , Read waiting queue messages , Push .
4) Storage management services , It will be scanned regularly cii Indexes , according to cii Last update time stored , If 14 It hasn't been updated for days , Description is inactive user , Will clean up the token Information , At the same time, clean the token Corresponding waiting queue message .
Push operation Redis The flow chart is as follows :
3、 ... and 、 Push platform online problems
As described above , The push platform uses Redis The main msg Clusters and client colony , As the business grows , The system requires higher and higher performance ,Redis There are some bottlenecks , among msg Redis Cluster before optimization , The scale has reached 220 individual master,4400G Capacity . As the size of the cluster grows , Increased difficulty in maintenance , The accident rate is getting higher . especially 4 month , So and so star divorce , Real time concurrent messages 5.2 Billion ,msg Redis The number of single node connections in the cluster 、 Memory explosion problem , The number of connections of one node reaches 24674, Memory reaches 23.46G, continued 30 About minutes . period msg Redis The cluster response to read and write is slow , Mean response time 500ms about , Affect the stability and availability of the overall system , Availability reduced to 85%.

Four 、 Push platform Redis Optimize
Redis It is generally optimized from the following aspects :
1) Capacity :Redis It belongs to memory storage , Compared with disk storage database , Storage costs are expensive , It is precisely because of the memory storage feature that it has high read and write performance , But the storage space is limited . therefore , When the business is in use , It should be noted that the storage content should be thermal data as much as possible , And the capacity can be evaluated in advance , It's best to set the expiration time . When designing storage , Make rational use of the corresponding data structure , For some relatively large value, It can be compressed and stored .
2) heat key tilt :Redis-Cluster Map all the physical nodes to [0-16383]slot( Slot ) On , Each node is responsible for a part of slot. When there is a request to call , according to CRC16(key) mod 16384 Value , It was decided that key Request to which slot in . because Redis-cluster This feature , Each node is responsible for only part of slot, therefore , In the design key Make sure that key The randomness of , In particular, use some hash Algorithm mapping key when , Guarantee hash Random distribution of values . in addition , Control hotspots key Concurrency issues , Current limiting degradation or local caching can be adopted , Prevent hot spots key Concurrent requests are too high, resulting in Redis Hot spots tilt .
3) The cluster is too large :Redis-Cluster Use a no center structure , Each node holds the data and the entire cluster state , Each node is connected to all other nodes . Each node saves all nodes and slot The mapping relationship . When there are many nodes , Each node will also save more mapping relationships . The more data carried in the message body of the heartbeat packet between nodes . During expansion and contraction , The cluster is restarted clusterSlots It's a relatively long time . There is a risk of congestion in the cluster , Stability is affected . therefore , When using clusters , Try to avoid too many cluster nodes , Finally, the cluster is split according to the business .
Here's the problem : Why? Redis-Cluster Use 16384 individual slot, Not more , How many nodes can there be at most ?
The official author gives explain , And explain in the explanation ,Redis-Cluster No more than 1000 Main node .

Based on the above optimization directions , And its own business characteristics , The push platform starts from the following aspects Redis The road to optimization .
- msg Redis Cluster capacity optimization ;
- msg Redis Large clusters are split according to business attributes ;
- Redis hotspot key screening ;
- client Redis Cluster concurrent call optimization .
4.1 msg Redis Cluster capacity optimization
Mentioned above ,msg Redis The scale of the cluster reaches 220 individual master、4400G Capacity , The used capacity has reached... During the peak period 3650G, Used 83% about , If the subsequent push increases the amount , Capacity expansion is needed , The cost is too high . So for msg Redis Cluster storage content analysis , The analysis tool used is snowball RDB Analysis tools RDR .github website : Not much here , You can go github Download the corresponding tools from the website and use . This tool can analyze Redis Snapshot situation , Include :Redis Capacity of different structure types 、key Number 、top 100 largest keys、 Prefix key Quantity and capacity .
The conclusion after analysis :msg Redis In the cluster ,mi: The proportion of the structure at the beginning 80% about , Among them, the proportion of single push messages 80%. explain :
- Single push :1 Message push 1 Users
- Group push :1 A message can be repeatedly pushed to multiple users , Messages can be reused .
The feature of single push is one-to-one push , Push completed or failed ( Controlled 、 Invalid user, etc ) The message body is no longer used .
Optimization plan :
- Clean up the single push messages in time , If the user has received a single push message , received puback receipt , Delete directly Redis news . If a single push message is restricted from being sent for reasons such as control , Directly delete the single push message body .
- For messages with the same content , Aggregate storage , Store a message with the same content , news id It is used many times when pushing the logo .
After this optimization , The volume reduction effect is obvious . After the full volume goes online, the capacity is reduced 2090G, The original maximum capacity is 3650G, Reduced capacity 58%.

4.2 msg Redis Large clusters are split according to business attributes
Although the cluster capacity is optimized , But the rush hour msg Redis The pressure is still great .
Main cause :
1) Connect msg Redis There are many nodes , This leads to a high number of connections during peak periods .
2) The message body and the waiting queue are stored in a cluster , All push operations are required , Lead to Redis It's very concurrent , Fastigium cpu High load , arrive 90% above .
3) Old cluster Redis The version is 3.x, After break up , The new cluster uses 4.x edition . Compare with 3.x Version has the following advantages :
- PSYNC2.0: Optimized the previous version of , Switching between master and slave nodes will inevitably cause the problem of full replication .
- A new cache culling algorithm is provided :LFU(Least Frequently Used), The existing algorithms are optimized .
- Provides non blocking del and flushall/flushdb function , Effective solution deleted bigkey May cause Redis Blocking .
- Provides memory command , Achieve more comprehensive monitoring and statistics of memory .
- More memory saving , Store the same amount of data , Requires less memory space .
- Can do memory defragmentation , Gradually reclaim memory . When using Jemalloc Memory allocation scheme ,Redis You can use online memory defragmentation .
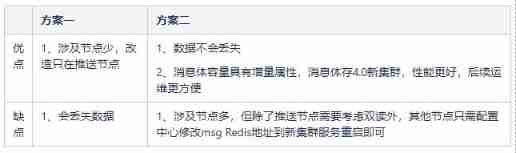
Splitting schemes are based on business attributes msg Redis Store information and split it , Split the message body and the waiting queue , Put them into two separate clusters . In this way, there are two splitting schemes .
Scheme 1 : Split the waiting queue from the old cluster
Just push the node to modify , But the sending waiting queue is continuous , A stateful , And clientId Online status related , Corresponding value Will be updated in real time , Switching will result in data loss .
Option two : Split the message body from the old cluster
All connections msg Redis Replace the node with a new address and restart , Push the node for double reading , Wait until the hit rate of the old cluster is 0 when , Directly switch to read new cluster . Because the message body is characterized by only write and read operations , No updates , Switching does not consider the state problem , As long as it can be written and read, there is no problem . And the message body capacity has the incremental attribute , Need to be able to expand capacity conveniently and quickly , The new cluster adopts 4.0 edition , Convenient for dynamic expansion and contraction .
Considering the impact on business and service availability , Make sure the message is not lost , Finally, we choose option 2 . The design adopts double reading and single writing scheme :
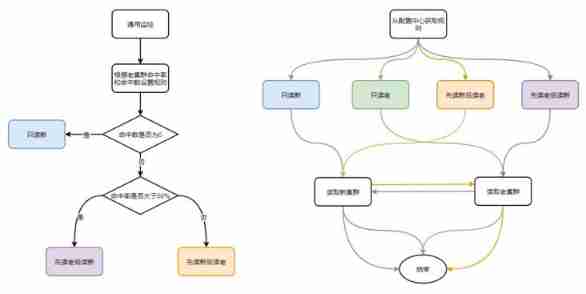
Because the message body is switched to the new cluster , That's during the switch for a while ( most 30 God ), The new message body is written to the new cluster , The old cluster stores the contents of the old message body . During this period, the push node needs double reading , Ensure that data is not lost . In order to ensure the efficiency of double reading , Need to support no code modification , Dynamic rule adjustment measures without restarting services .
The general rules are divided into 4 individual : Read only old 、 Read only new 、 Read the old before the new 、 Read the new before the old .
Design thinking : Server support 4 Strategies , Decide which rule to follow through the configuration of the configuration center .
The judgment basis of the rule : It is determined according to the hit number and hit rate of the old cluster . Initial online rule configuration “ Read the old before the new ”; When the hit rate of the old cluster is lower than 50%, Switch to " Read the new before the old "; When the number of hits in the old cluster is 0 after , Switch to “ Read only new ”.
The hit rate and hit number of old clusters are increased through general monitoring .
The flow chart of scheme 2 is as follows :
Split effect :
- Before splitting , The old msg Redis The peak load of the cluster in the same period 95% above .
- After break up , At the same time, the peak load is reduced to 70%, falling 15%.

Before splitting ,msg Redis The average response time of the cluster in the peak period in the same period 1.2ms, There are calls during peak hours Redis Slow response . After break up , The average response time is reduced to 0.5ms, There is no problem of slow response during peak hours .
4.3 Redis hotspot key screening
I said before ,4 Star hot events in August , appear msg Redis Number of single node connections 、 Memory explosion problem , The number of single node connections has reached 24674, Memory reaches 23.46G.
because Redis Virtual machines used by the cluster , At first, it was suspected that the host of the virtual machine was under pressure , Because according to the troubleshooting, the node with the problem is mounted on the host Redis There are many master nodes , Probably 10 about , While other host computers mount 2-4 Left and right master nodes , So for master A round of equalization optimization is carried out , Make the master nodes allocated by each host more balanced . After equalization , The overall situation has improved to a certain extent . however , At push peak , Especially when pushing at full speed and full volume , There are still occasional single node connections 、 Memory explosion problem . Observe the incoming and outgoing traffic of host network card , There are no bottlenecks , At the same time, it also eliminates the influence of other business nodes on the host . Therefore, it is doubtful that business use Redis There is a hot spot tilt problem .
Monitor the call chain by crawling during peak hours , You can see it in the picture below , We 11:49 To 12:59 During this period, call msg Redis Of hexists Commands are time-consuming , This command is mainly used to query whether the message is in mii Index , Link analysis is time-consuming key Mostly mii:0. At the same time, the problem nodes Redis Memory snapshot for analysis , Find out mii:0 The proportion of capacity is very high , There is a read mii:0 Hotspot issues .
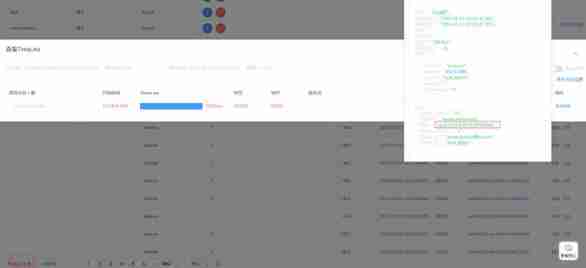
After analysis and investigation , Discovery generates messages id Generated by snowflake algorithm messageId, There is a tilt problem , Because the sequence values of the same millisecond are from 0 Start , And the sequence length is 12 position , Therefore, for the management background and..., the concurrency is not very high api node , Generated messageId Basically the last 12 Position as 0. because mii Indexes key yes mi:${messageId%1024},messageId Last 12 Position as 0,messageId%1024 That is to say 0, This leads to msg Redis in mii:0 This key It's big , High hit rate during query , So it led to Redis Heat of key problem .

Optimization measures :
1) Snowflake algorithm transformation , Generate messages id The use of sequence The initial value is no longer 0, But from 0~1023 Take a random number , Prevent hot spot tilt problems .
2) adopt msg The message type in the message body and the existence of the message body are used to replace the call hexists command .
Final effect : After optimization ,mii The index is evenly distributed ,Redis The number of connections is stable , Memory growth is also relatively stable , No more Redis Single node memory 、 Connection explosion problem .
4.4 client Redis Cluster concurrent call optimization
The upstream node calls the push node through clientId Be consistent hash Called , The push node caches clientInfo Information to local , Cache time 7 God , When pushing , Query local cache first , Judge that client Whether it works . For important and frequently changing information , Direct inquiry client Redis obtain , This leads to push peak ,client Redis There's a lot of pressure on the cluster , High concurrency ,cpu High load .
Before optimization, push node operation cache and client Redis flow chart :

Optimization plan : To the original clientInfo Split the cache , Split into three caches , Adopt a graded scheme .
- cache Or save the original clientInfo Some of the information , The information changes infrequently , Cache time is still 7 God .
- cache1 cache clientInfo Constantly changing information , Such as : Online status 、cn Address, etc .
- cache2 cache ci Encrypt some parameters , This part of the cache is only used when encryption is required , The frequency of change is not that high , Changes only when connected .
Due to the new cache , Cache consistency needs to be considered , So add a new measure :
1) Push cache verification , call broker node , according to broker The return information of , Update and clean up local cache information .broker New offline 、aes Mismatch error code . Next push or retry , Will come back from Redis Load in , Get the latest client Information .
2) According to the uplink event of the mobile terminal ,connect and disconnect when , Update and clean up local cache information , Next push or retry , Will come back from Redis Load in , Get the latest client Information .
Overall process : When the message is pushed , Query local cache first , Cache does not exist or has expired , Only from the client Redis Load in . Pushed to the broker when , according to broker Return information , Update or invalidate the cache . The upside , received disconnect、connect event , Update or invalidate the cache in time , Push again from client Redis load .
After optimization, push node operation cache and client Redis flow chart :

Optimized effect :
1) newly added cache1 cache hit rate 52%,cache2 cache hit rate 30%.
2)client Redis The amount of concurrent calls has been reduced by nearly 20%.
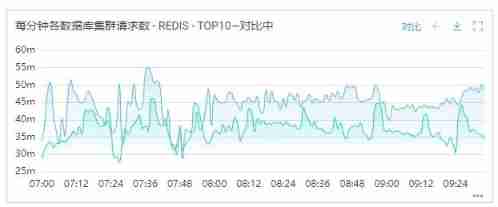
3) Fastigium Redis Load reduction 15% about .
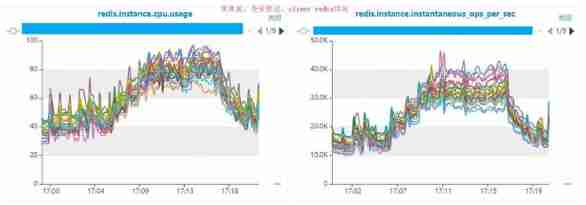
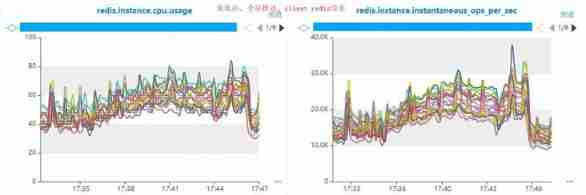
5、 ... and 、 summary
Redis Because of its high concurrency performance and supporting rich data structures , In high concurrency system, as cache middleware, it is a better choice . Of course ,Redis Whether it can play a high performance , It also depends on whether the business really understands and uses Redis. There are several points to pay attention to :
1) because Redis Cluster pattern , Each master node is responsible for only part of slot, Business in design Redis key Give full consideration to key The randomness of , Evenly dispersed in Redis On each node , At the same time, avoid large key appear . in addition , Business should avoid Redis Request hot issues , Request to call a few nodes at the same time .
2)Redis The actual throughput is also related to the request Redis Packet data size , Network card related , Official documents There are relevant instructions , The size of a single package exceeds 1000bytes when , Performance can degrade dramatically . So it's using Redis Try to avoid big key. in addition , It's best to base on the actual business scenario and the actual network environment , Pressure test the performance of bandwidth and network card , Find out the actual throughput of the cluster .
With our client Redis Clusters, for example :( For reference only )
- Network:10000Mb;
- Redis Version:3.x;
- Payload size:250bytes avg;
- command :hset(25%)、hmset(10%)、hget(60%)、hmget(5%);
- Performance : The number of connections 5500、48000/s、cpu 95% about .

Redis There is less support in real-time analysis , In addition to basic indicator monitoring , Real time memory data analysis is temporarily not supported . In the actual business scenario, if Redis bottleneck , Often the monitoring data is also missing , Positioning problems are difficult . Yes Redis Our data analysis can only rely on analysis tools for Redis Snapshot files for analysis . therefore , Yes Redis The use of depends on the business to Redis A full understanding of , When designing the scheme, fully consider . At the same time, according to the business scenario Redis Conduct performance pressure test , Know where the bottleneck is , Prepare for monitoring and capacity expansion and contraction .
author :vivo Internet server team -Yu Quan

![[flutter topic] 64 illustration basic textfield text input box (I) # yyds dry goods inventory #](/img/1c/deaf20d46e172af4d5e11c28c254cf.jpg)