当前位置:网站首页>论文笔记: 图神经网络 GAT
论文笔记: 图神经网络 GAT
2022-07-06 02:00:00 【闵帆】
摘要: 分享对论文的理解. 原文见 Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, Graph attention networks, ICLR 2018, 1–12. 可以在 ArXiv: 1710.10903v3 下载. 完全难以估计影响力有多大!
1. 论文贡献
- 克服图卷积已有方法的缺点.
- 不需要耗时的矩阵运算 (如求逆).
- 不需要预知图的结构.
- 适用于归纳与演绎问题.
2. 基础思想
利用邻居的信息, 将图中节点原始属性映射到一个新的空间, 以支持后面的学习任务.
这个思想可能是不同图神经网络所共有的.
3. 方案
| 符号 | 含义 | 备注 |
|---|---|---|
| N N N | 节点数 | |
| F F F | 原始特征数 | |
| F ′ F' F′ | 原始特征数 | 例中为 4 |
| h \mathbf{h} h | 结点特征集合 | { h → 1 , … , h → N } \{\overrightarrow{h}_1,\dots, \overrightarrow{h}_N \} { h1,…,hN} |
| h → i \overrightarrow{h}_i hi | 第 i i i 个节点的特征 | 属于空间 R F \mathbb{R}^F RF |
| h ′ \mathbf{h}' h′ | 结点新的特征集合 | { h → 1 ′ , … , h → N ′ } \{\overrightarrow{h}'_1,\dots, \overrightarrow{h}'_N \} { h1′,…,hN′} |
| h → i ′ \overrightarrow{h}'_i hi′ | 第 i i i 个节点的新特征 | 属于空间 R F ′ \mathbb{R}^{F'} RF′ |
| W \mathbf{W} W | 特征映射矩阵 | 属于 R F × F ′ \mathbb{R}^{F \times F'} RF×F′, 所有节点共享 |
| N i \mathcal{N}_i Ni | 节点 i i i 的邻居集合 | 包括 i i i 自己, 例中基数为 6 |
| a → \overrightarrow{\mathbf{a}} a | 特征权值向量 | 属于 R 2 F ′ \mathbb{R}^{2F'} R2F′, 所有节点共享, 对应于单层网络 |
| α i j \alpha_{ij} αij | 节点 j j j 对 i i i 的影响 | 所有邻居节点的影响之和为 1 |
| α → i j \overrightarrow{\alpha}_{ij} αij | 节点 j j j 对 i i i 的影响向量 | 长度为 K K K, 对应于多头 |
将节点特征映射到新空间, 利用注意力机制 a a a 计算节点间的关系
e i j = a ( W h → i , W h → j ) (1) e_{ij} = a(\mathbf{W}\overrightarrow{h}_i, \mathbf{W}\overrightarrow{h}_j) \tag{1} eij=a(Whi,Whj)(1)
这里仅当 j j j 是 i i i 在网络上的邻居时, 才计算 e i j e_{ij} eij.
将它进行 softmax, 使得节点 i i i 对应的权值和为 1.
α i j = s o f t m a x j ( e i j ) = exp ( e i j ) ∑ k ∈ N i exp ( e i k ) (2) \alpha_{ij} = \mathrm{softmax}_j(e_{ij}) = \frac{\exp(e_{ij})}{\sum_{k \in \mathcal{N}_i} \exp(e_{ik})}\tag{2} αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)(2)
由于 a a a 将长度为 2 F ′ 2F' 2F′ 的列向量转换为一个标量, 可以将其写作一个相同长度的行向量 a → T \overrightarrow{\mathbf{a}}^{\mathrm{T}} aT. 再加上一个激活函数, 它就可以用单层的神经网络实现.
α i j = exp ( L e a k y R e L u ( a → T [ W h → i ∥ W h → j ] ) ) ∑ k ∈ N i exp ( L e a k y R e L u ( a → T [ W h → i ∥ W h → k ] ) ) (2) \alpha_{ij} = \frac{\exp(\mathrm{LeakyReLu}(\overrightarrow{\mathbf{a}}^{\mathrm{T}}[\mathbf{W}\overrightarrow{h}_i \| \mathbf{W}\overrightarrow{h}_j]))}{\sum_{k \in \mathcal{N}_i} \exp(\mathrm{LeakyReLu}(\overrightarrow{\mathbf{a}}^{\mathrm{T}}[\mathbf{W}\overrightarrow{h}_i \| \mathbf{W}\overrightarrow{h}_k]))}\tag{2} αij=∑k∈Niexp(LeakyReLu(aT[Whi∥Whk]))exp(LeakyReLu(aT[Whi∥Whj]))(2)
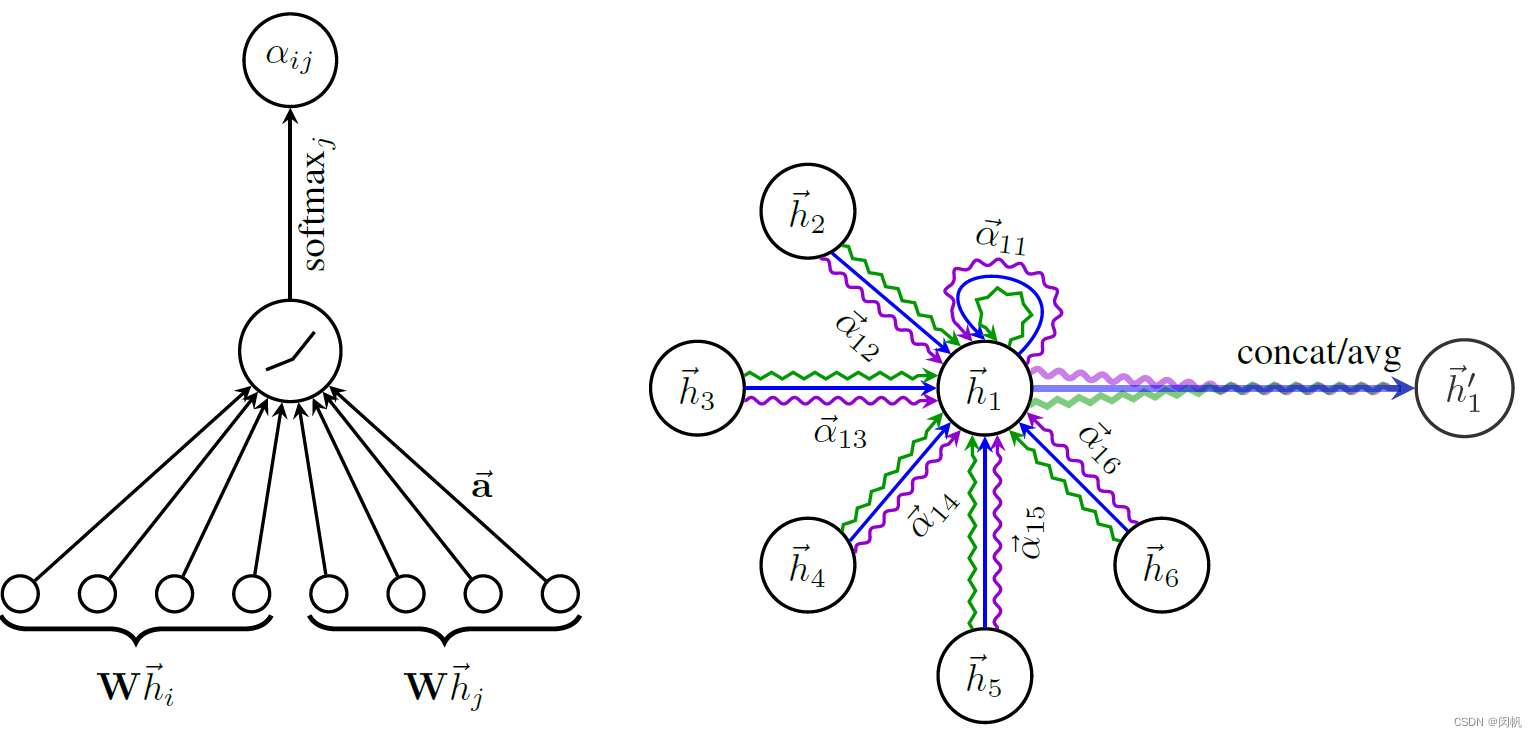
图 1. GAT 核心方案. 左: F ′ = 4 F' = 4 F′=4 的时候, 从 W \mathbf{W} W 映射到的新空间为 4 维. 相应的 2 F ′ = 8 2F' = 8 2F′=8 维. 向量 a → \overrightarrow{\mathbf{a}} a 由所有的节点共享. 右: K = 3 K = 3 K=3 个头.
3.1 方案一: 单头
h → i ′ = σ ( ∑ j ∈ i α i j W h → j ) (4) \overrightarrow{h}'_i = \sigma\left(\sum_{j \in \mathcal{i}} \alpha_{ij} \mathbf{W} \overrightarrow{h}_j\right)\tag{4} hi′=σ(j∈i∑αijWhj)(4)
所有邻居节点先映射到新空间 (如 4 维), 然后根据其影响力加权求和, 并用 sigmoid 等非线性激活函数, 最终获得的还是 4 维向量.
3.2 方案二: 多头连接
h → i ′ = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h → j ) (5) \overrightarrow{h}'_i = \|_{k = 1}^K \sigma\left(\sum_{j \in \mathcal{N}_i} \alpha^k_{ij} \mathbf{W}^k \overrightarrow{h}_j\right)\tag{5} hi′=∥k=1Kσ⎝⎛j∈Ni∑αijkWkhj⎠⎞(5)
K K K 个头分别获得相应的新向量, 图 1 右展示了 3 个头, 因此最后的向量为 3 × 4 = 12 3 \times 4 = 12 3×4=12 维.
3.3 方案三: 多头平均
h → i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h → j ) (5) \overrightarrow{h}'_i = \sigma \left(\frac{1}{K} \sum_{k = 1}^K \sum_{j \in \mathcal{N}_i} \alpha^k_{ij} \mathbf{W}^k \overrightarrow{h}_j\right)\tag{5} hi′=σ⎝⎛K1k=1∑Kj∈Ni∑αijkWkhj⎠⎞(5)
仅仅是平均值, 最后的向量为 4 4 4 维.
4. 疑问
问题: 这里的 W \mathbf{W} W 与 a → \overrightarrow{\mathbf{a}} a 如何学习?
猜测: 可以从相关工作, 即图神经网络里面获得必要的知识. 这篇论文只是想描述不一样的核心技术.
如果将这个网络的输出作为其它网络的输入 (最终输出为类标签等), 有可能就可以进行相应学习.
唐文韬的解释: 本质上相当于矩阵相乘 (线性回归),从论文代码里可以看出:在训练阶段,输入的是整个训练集 (特征矩阵和样本的邻接矩阵),通过 W \mathbf{W} W 和 a → \overrightarrow{\mathbf{a}} a 得到训练集的预测标签 (先得到每个样本对于所有样本的自注意力权重,再根据邻接矩阵进行 mask,再归一化作为一层自注意力的权重), 然后进行 loss 的计算和传播。问题: 为什么计算影响力的时候使用 LeakyReLU, 而计算最终特征向量的时候使用 sigmoid?
强行解释: 前者只是与后者区别开 (非必要), 后者是改变线性 (有必要).
唐文韬的解释: 计算影响力使用 LeakyReLU: 更多地关注与目标结点更加正相关的邻居结点。
最终特征向量使用 sigmoid 应该是为了防止数值过大,影响下一层的学习,因为自注意力机制较为不稳定(从我之前的实验中看出),对数值的范围和稠密性要求较高(范围小:0-1之类,较为稠密)。
此外,在 GAT 论文内给出的源代码中可以看出, 作者对所有数据集都仅使用了两层自注意力网络, 并且 dropout 都设为0.5-0.8, 可见其较容易过拟合。
5. 小结
- 利用 W \mathbf{W} W 线性映射到新空间.
- 利用 a → \overrightarrow{\mathbf{a}} a 计算各邻居的影响力 α i j \alpha_{ij} αij. a → \overrightarrow{\mathbf{a}} a 仅针对相应属性, 而不受邻居编号影响. α i j \alpha_{ij} αij 的计算涉及 LeakyReLU 激活函数的使用.
- 利用多头增加稳定性.
- 求均值、使用非线性函数激活都不会改变向量的维度.
边栏推荐
- 【SSRF-01】服务器端请求伪造漏洞原理及利用实例
- NLP第四范式:Prompt概述【Pre-train,Prompt(提示),Predict】【刘鹏飞】
- Leetcode3. Implement strstr()
- Paddle框架:PaddleNLP概述【飞桨自然语言处理开发库】
- You are using pip version 21.1.1; however, version 22.0.3 is available. You should consider upgradin
- [flask] response, session and message flashing
- 剑指 Offer 38. 字符串的排列
- Publish your own toolkit notes using NPM
- Comments on flowable source code (XXXV) timer activation process definition processor, process instance migration job processor
- Derivation of Biot Savart law in College Physics
猜你喜欢
Virtual machine network, networking settings, interconnection with host computer, network configuration
NLP第四范式:Prompt概述【Pre-train,Prompt(提示),Predict】【刘鹏飞】
Executing two identical SQL statements in the same sqlsession will result in different total numbers
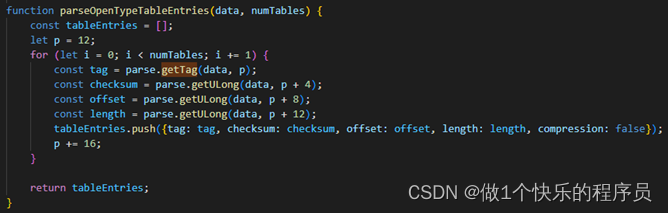
TrueType字体文件提取关键信息

02.Go语言开发环境配置

Redis-列表
【clickhouse】ClickHouse Practice in EOI

National intangible cultural heritage inheritor HD Wang's shadow digital collection of "Four Beauties" made an amazing debut!
Social networking website for college students based on computer graduation design PHP

Basic operations of databases and tables ----- primary key constraints
随机推荐
MySQL index
How does redis implement multiple zones?
Cadre du Paddle: aperçu du paddlelnp [bibliothèque de développement pour le traitement du langage naturel des rames volantes]
剑指 Offer 12. 矩阵中的路径
TrueType字体文件提取关键信息
National intangible cultural heritage inheritor HD Wang's shadow digital collection of "Four Beauties" made an amazing debut!
Redis-字符串类型
[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry
[understanding of opportunity-39]: Guiguzi - Chapter 5 flying clamp - warning 2: there are six types of praise. Be careful to enjoy praise as fish enjoy bait.
Force buckle 1020 Number of enclaves
国家级非遗传承人高清旺《四大美人》皮影数字藏品惊艳亮相!
LeetCode 322. Change exchange (dynamic planning)
Comments on flowable source code (XXXV) timer activation process definition processor, process instance migration job processor
Computer graduation design PHP animation information website
Leetcode skimming questions_ Verify palindrome string II
【Flask】响应、session与Message Flashing
This time, thoroughly understand the deep copy
[flask] response, session and message flashing
Basic operations of database and table ----- set the fields of the table to be automatically added
Redis如何实现多可用区?