当前位置:网站首页>Reasons and solutions for redis cache penetration and cache avalanche
Reasons and solutions for redis cache penetration and cache avalanche
2022-07-05 15:04:00 【Back end regular developers】
List of articles
In the production environment , There are many reasons why access requests bypass the cache , All need to access the database persistence layer , Although the Redsi Cache server will not cause impact , But the load of the database will increase , Reduce the effect of cache
One 、 Cache penetration
Cache penetration refers to querying a data that doesn't exist at all , Neither the cache layer nor the persistence layer will hit . In daily work, for the sake of fault tolerance , If no data can be found from the persistence layer, it will not be written to the cache layer , Cache penetration will cause nonexistent data to be queried in the persistence layer every request , Lost the meaning of cache protection and back-end persistence
Cache penetration diagram :
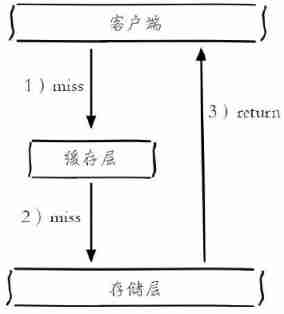
Cache penetration issues may increase back-end storage load , Because many backend persistence layers do not have high concurrency , It may even cause back-end storage downtime . You can usually count the total number of calls in the program 、 Cache layer hits 、 If the same Key The cache hit rate of is very low , Maybe there is a cache penetration problem .
There are two basic reasons for cache penetration . First of all , There is a problem with your own business code or data ( for example :set and get Of key atypism ), second , Some malicious attacks 、 Reptiles and so on cause a lot of empty hits ( Crawl online mall commodity data , The of super circular increasing commodities ID)
Solution :
1. Caching empty objects
Caching empty objects : It refers to the case that the persistence layer fails to hit , Yes key Conduct set (key,null)
There are two problems with caching empty objects :
- First of all ,value by null Doesn't mean it doesn't take up memory space , Null values are cached , It means that there are more keys in the cache layer , Need more memory space , The more effective way is to set a shorter expiration time for this kind of data , Let it automatically remove .
- second , The data of cache layer and storage layer will be inconsistent for a period of time , It may have some impact on the business . For example, the expiration time is set to 5 minute , If the storage layer adds this data at this time , Then there will be inconsistencies between the cache layer and the storage layer data in this period of time , At this time, you can use the message system or other ways to clear the empty objects in the cache layer
2. Boom filter intercept
Before accessing the cache layer and storage layer , There will be key Save in advance with a bloom filter , Do the first level intercept , When you receive a pair of key When requesting, first verify with Bloom filter that it is key There is no , If it exists before entering the cache layer 、 Storage layer . have access to bitmap Make a bloom filter . This method is suitable for data hit is not high 、 Data is relatively fixed 、 Application scenarios with low real-time performance , Code maintenance is more complex , But the cache space is less .
The bloom filter is actually a very long binary vector and a series of random mapping functions . The bloom filter can be used to retrieve whether an element is in a collection . Its advantage is that the space efficiency and query time are far more than the general algorithm , The disadvantage is that it has certain error recognition rate and deletion difficulty .
Algorithm description :
Initial state ,BloomFilter Is a length of m The number group of , Everyone is set to 0.
Additive elements x when ,x Use k individual hash Function to get k individual hash value , Yes m Remainder , Corresponding bit Bit is set to 1.
Judge y Whether it belongs to this set , Yes y Use k Hash function to get k Hash values , Yes m Remainder , All corresponding positions are 1, Think y Belongs to the collection ( Hash Collisions , There may be miscalculation ), Otherwise, I think y Does not belong to this set . You can reduce the false positive rate by increasing the hash function and increasing the length of the binary bit group .
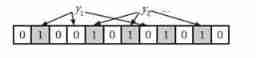
Reasons for misstatement :
One key Map multiple bits on the array , One will be killed by more than one key Use , That is, many to many relationship . If one key All bit values mapped are 1, It is judged to exist . But there may be key1 and key2 At the same time, map to the subscript 100 Bit ,key1 non-existent ,key2 There is , In this case, the error rate
Scheme comparison :

Two 、 Cache avalanche
Because the cache layer carries a lot of requests , Effectively protects the storage tier , But if the cache layer is unavailable for some reason ( Downtime ) Or a large number of caches expire in the same time period due to the same timeout ( Large numbers key invalid / Hot data failure ), A lot of requests go directly to the storage tier , Excessive storage layer pressure leads to system avalanche .
Solution :
- The cache layer can be designed to be highly available , Even if individual nodes 、 Individual machines 、 Even the computer room went down , Services are still available . utilize sentinel or cluster Realization .
- Use multi-level cache , The local process acts as a first level cache ,redis As a second level cache , Different levels of cache have different timeout settings , Even if a level of cache expires , There are also other levels of cache bottoming
- The expiration time of the cache is a random value , Try to make different key The expiration time of is different ( for example : Create a new batch of scheduled tasks key, Set the expiration time to be the same )
3、 ... and 、 Cache breakdown
Attention should be paid to the following two problems in the system :
At present key It's a hot spot key( For example, a second kill ), The amount of concurrency is very large .
Rebuilding the cache cannot be done in a short time , It could be a complex calculation , For example, complicated SQL、 many times IO、 Multiple dependencies, etc .
In the moment of cache failure , There are a lot of threads to rebuild the cache , Cause the back-end load to increase , It might even crash the app .
Solution :
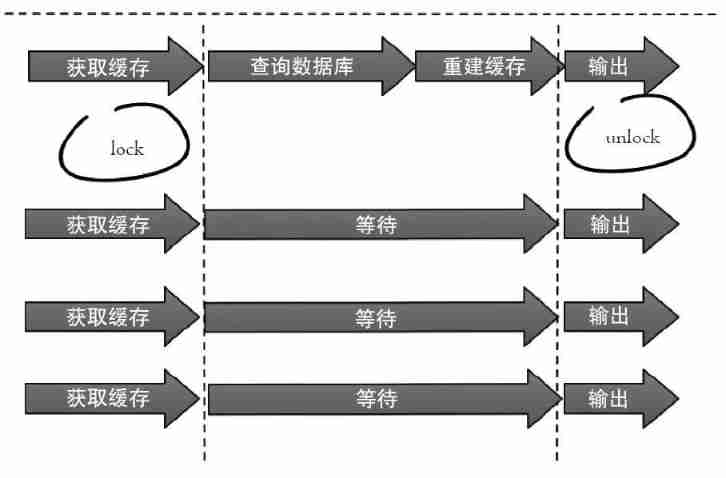
- Distributed mutex
Only one thread is allowed to rebuild the cache , Other threads wait for the thread to rebuild the cache to finish , Get the data from the cache again .set(key,value,timeout)
- Never expire
At the cache level , It's true that the expiration time is not set , So there will be no hot spots key Problems after expiration , That is to say “ Physics ” Not overdue .
From a functional point of view , For each value Set a logical expiration time , When it is found that the logical expiration time is exceeded , A separate thread will be used to update the buffer
2 Comparison of two schemes :
Distributed mutex : The idea of this scheme is relatively simple , But there are some hidden dangers , If you are querying the database + and Rebuild cache (key After failure, a lot of calculations were carried out ) drawn-out , There may also be a risk of deadlock and thread pool blocking , In the case of high concurrency, the throughput will be greatly reduced ! However, this method can better reduce the back-end storage load , And do a good job in consistency .
“ Never expire ”: This scheme does not set a real expiration time , In fact, there are no hot spots key A series of hazards , But there will be data inconsistencies , At the same time, the code complexity will increase .
from :https://blog.csdn.net/womenyiqilalala/article/details/105205532
边栏推荐
- Magic methods and usage in PHP (PHP interview theory questions)
- 12 MySQL interview questions that you must chew through to enter Alibaba
- 【NVMe2.0b 14-9】NVMe SR-IOV
- Fr exercise topic - simple question
- PyTorch二分类时BCELoss,CrossEntropyLoss,Sigmoid等的选择和使用
- Brief introduction of machine learning framework
- js亮瞎你眼的日期选择器
- Ecotone technology has passed ISO27001 and iso21434 safety management system certification
- 30岁汇源,要换新主人了
- Ctfshow web entry information collection
猜你喜欢
B站做短视频,学抖音死,学YouTube生?

Live broadcast preview | how to implement Devops with automatic tools (welfare at the end of the article)
P1451 求细胞数量/1329:【例8.2】细胞

你童年的快乐,都是被它承包了
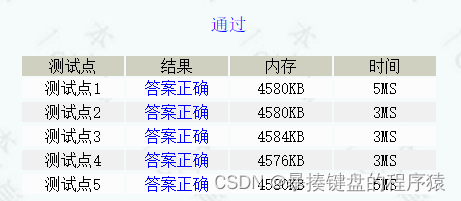
Ctfshow web entry explosion
Two Bi development, more than 3000 reports? How to do it?

MySQL之CRUD
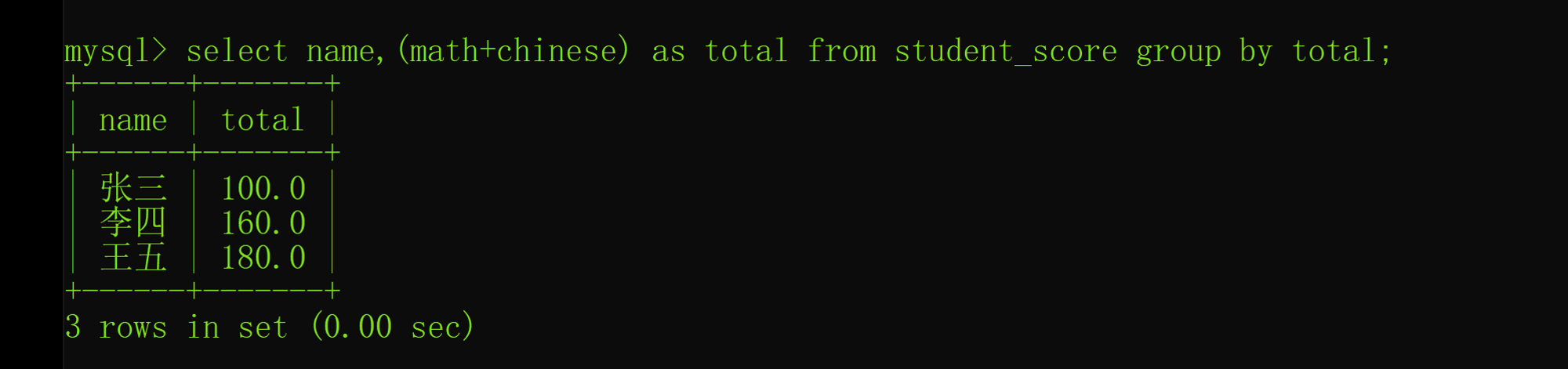
Interview shock 62: what are the precautions for group by?

Surpass palm! Peking University Master proposed diverse to comprehensively refresh the NLP reasoning ranking
如何将电脑复制的内容粘贴进MobaXterm?如何复制粘贴
随机推荐
Leetcode: Shortest Word Distance II
超越PaLM!北大硕士提出DiVeRSe,全面刷新NLP推理排行榜
超级哇塞的快排,你值得学会!
DVWA range clearance tutorial
黑马程序员-软件测试-10阶段2-linux和数据库-44-57为什么学习数据库,数据库分类关系型数据库的说明Navicat操作数据的说明,Navicat操作数据库连接说明,Navicat的基本使用,
两个BI开发,3000多张报表?如何做的到?
How to paste the contents copied by the computer into mobaxterm? How to copy and paste
Behind the ultra clear image quality of NBA Live Broadcast: an in-depth interpretation of Alibaba cloud video cloud "narrowband HD 2.0" technology
Easyocr character recognition
729. 我的日程安排表 I :「模拟」&「线段树(动态开点)」&「分块 + 位运算(分桶)」
【jvm】运算指令
Brief introduction of machine learning framework
What are the domestic formal futures company platforms in 2022? How about founder metaphase? Is it safe and reliable?
Where is the operation of convertible bond renewal? Is it safer and more reliable to open an account
qt creater断点调试程序详解
我想咨询一下,mysql一个事务对于多张表的更新,怎么保证数据一致性的?
Microframe technology won the "cloud tripod Award" at the global Cloud Computing Conference!
easyOCR 字符識別
useMemo,memo,useRef等相关hooks详解
裁员下的上海