当前位置:网站首页>[论文分享] Where’s Crypto?
[论文分享] Where’s Crypto?
2022-07-07 16:16:00 【fa1c4】
Where’s Crypto?: Automated Identification and Classification of Proprietary Cryptographic Primitives in Binary Code [USENIX 2021]
Carlo Meijer Radboud University The Netherlands [email protected]
Veelasha Moonsamy Ruhr University Bochum Germany [email protected]
Jos Wetzels Midnight Blue Labs The Netherlands [email protected]
概述
在许多行业的嵌入式系统中会使用专有密码技术,从物理访问控制系统和电信(telecommunications)到机器-机器身份验证,都对黑盒安全评估工作构成了重大障碍。深入的安全分析通常需要在大量的binary代码中定位和分类算法,即使在启发式辅助下进行人工检查,也很耗时。
本文提出了一种在二进制代码中自动识别和分类(专有)密码原语的新方法。方法基于数据流图(Data Flow Graph, DFG)同构,此前由Lestringant等人[43]提出。不过他们的DFG同构方法仅限于已知的原语,并且依赖于选择代码片段进行分析的启发式方法。通过将上述方法与符号执行相结合,克服了[43]的限制,并能够将分析扩展到未知的、专有的密码原语领域。
为了证明论文方案是可行的,作者开发了各种签名,每个签名都针对不同的加密原语类,并在一组二进制文件上对每个签名进行了实验评估,这些二进制文件包括公开可用的(这类提供可重现的结果)和专有的二进制文件。最后,作者为所提方法以IDA反汇编插件的形式发布了一个开源的实现,名为“Where’s Crypto?”。
一句话:结合DFG同构和符号执行识别和分类二进制文件中的密码学原语。
论文链接:https://www.usenix.org/conference/usenixsecurity21/presentation/meijer
github地址:https://github.com/wheres-crypto/wheres-crypto
导论
尽管学术界普遍认为密码学应该公开记录,但私有密码学的使用在许多行业垂直领域持续存在,从物理访问控制系统和电信到机对机认证。这种情况对认证、合规检查、安全评估或个人研究工作构成了重大障碍,因为它需要诉诸高度劳动密集型的逆向工程,以便在评估之前确定这些算法的存在和性质。此外,当特定算法被破坏时,由于保密协议或法院禁令,细节可能不会立即公布,这使得其他潜在受影响方重复这种昂贵的努力,并阻碍了有效的漏洞管理。因此,真正需要的是实际的解决方案,自动扫描二进制文件,以发现未知的密码算法。
标准
(也算是贡献, 之前的工作还没有满足这个标准要求
(i) 识别相关类型的未知加密算法
(ii) 高效支持大型真实的嵌入式二进制固件
(iii) 不依赖完整的固件模拟或动态插桩
贡献
(1 第一个结合子图同构和符号执行的工作, 解决了代码段选择的开放问题,消除了启发式的需要,从而克服了先前工作不适合识别未知密码的限制, 另外目前工业界或学术界没有解决识别未知密码算法问题的工作
(2 提出了一种新的领域特定语言(domain-specific language, DSL)来定义密码原语的结构属性
(3 提供开源的实现, 并根据分析时间和与真实世界相关的二进制文件的准确性进行评估
prior work
学术界和产业界前人的关于二进制密码识别的工作可以分为
(1 专用功能标识最简单、最直接的方法是以OS api的形式标识专用密码功能
(如Windows CryptoAPI/CNG),库导入或专用指令(如AES-NI)。这种方法天生无法检测未知算法。
(2 在实践中最常用的方法包括基于常数(例如IVs,无袖数字,填充)和查找表(如S-Boxes, P-Boxes)。该方法不适用于未知算法的检测。此外,这同样适用于不依赖于固定数据的已知算法,或那些依赖于固定数据的算法,例如,使用动态生成的s - box,而不是嵌入的s - box。
(3 代码启发式: 它们可以静态或动态地应用,比如助记常量元组,它考虑了字的大小、字节顺序、乘法和加法逆,但在其他方面与数据签名有相同的缺点。第二个启发式依赖于观察到对称密码例程往往由高比例的位算术指令组成,并试图根据阈值对函数进行分类。
(4 深度学习: 提出了一种基于动态卷积神经网络的方法,然而,由于其依赖于动态二进制仪器,其无法对未知算法进行分类.
(5 数据流分析: 依赖于函数及其输入和输出之间的静态关系。一种可行的方法是执行污点分析和评估函数I/O熵变化,这依赖于模拟,对于本篇论文标准第(iii)条是不合适的。另一种方法是将模拟或符号执行的函数I/O与参考实现或测试向量的集合进行比较,这在本质也上无法检测未知算法。
方案
假设
(1 试图构建语义等价类和DFGs之间的一对一映射超出了本工作的范围。当规范化将两个表达式映射到同一个DFG节点时,假设它们在语义上是等价的。虽然反过来不一定是真的.
(2 由于代码混淆对任何二进制分析方法都是一个固有的挑战,我们的方法假设它所操作的输入没有混淆,并将这种去混淆委托给手动和/或自动的预处理步骤。
(3 PoC评估和DSL示例中,作者将讨论限制在加密原语分类的一个子集。这不是论文方法的固有限制,而仅仅是给出的PoC及其评估的限制。论文方法基本上与所采用的分类法无关,它可以根据用户的需要进行扩展,并且只假设分析人员正在寻找的算法是在它的一个类中。鉴于绝大多数专有密码学都属于已建立的基元类[67]的一个特定子集,即流密码和块密码以及哈希函数,作者不认为这是个问题。
(4 误报: 某些基元类是其他类的子集,一些实例符合几个类的定义, 由此可能出现分类的误报. 假设工具只是辅助人工逆向, 不考虑误报带来的影响, 因为人工可以轻松剪枝误报的情况.
密码原语
方法基于加密原语的结构分类。作者的想法是,由于绝大多数专有密码学属于已建立的基本类[67],可以开发结构签名,允许在这些类中识别任何算法,而不需要依赖于算法的特殊知识。
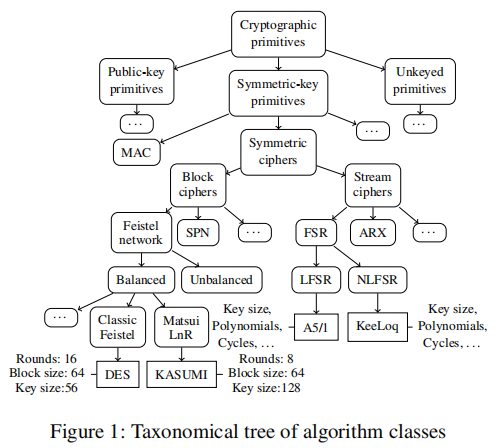
方法总体建立在两个基础之上:数据流图(DFG)同构和符号执行。这个方法的优势在于通过符号执行的增强效果突破原本单纯使用DFG同构做密码学原语识别的限制, 使得定位结构签名和分析二进制代码找到密码学原语匹配更有优势.
本篇论文主要研究对称密码和无键原语(unkeyed primitives)
加密原语本质上是一组表示输入/输出关系的算术和逻辑操作。这种在数据与操作之间的结构关系可以表示为DFG. 一般来说特定算法的在结构上会与一般性的密码原语相似, 那么识别一个未知算法属于哪一个密码基本类可以归结到DFG的子图同构问题.
然而,由于在实现和编译器特性上的细微差异,语义相同的算法的DFG表示可能会有所不同,在进行同构分析之前,需要对这种表示进行规范化。有趣的是理论上已经有结论, Lestringant等人[43]证明,通过对DFG重复应用一组重写规则,可以得到一个标准化版本,其中许多这些变化被删除。虽然不能保证等价的语义总是映射到相同的DFG,但结果“足够好”,可以作为该目的的数据结构。
DFG
假设有一个汇编指令序列, 则将每一条指令转换为一个操作集合 O i O_i Oi, 可以为空集或者有多个操作的集合. 然后对每个输入的类型进行区分
(1) 立即数: 创建一个顶点,代表G中的一个常量值。它通过一条边与 O i O_i Oi相连。
(2) 寄存器: 如果指令将寄存器作为输入操作数,则在最后写入该寄存器的值和 O i O_i Oi之间创建一条边
(3) 内存: 对于从内存中加载或存储的操作数,创建load和store操作。这两个操作都以内存地址顶点作为输入.
论文[43]遵循的方法是使用生成的DFG,并重复应用规范化重写规则,直到达到定点。这就是本篇的方法与他们的方法不同的地方,虽然本篇也应用了标准化,但在图的构建过程中会不断地应用。这提高了性能,并允许高效地跟踪符号执行期间应用的条件。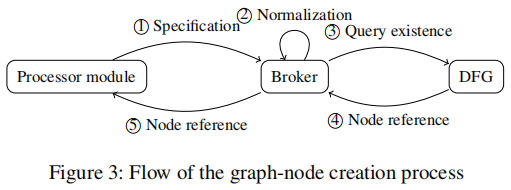
有一个处理器模块,它为特定的体系结构编写,将每个指令转换为图节点。处理器模块不能自主创建新的图节点。相反,它必须与代理交互。代理负责规范化重写规则的应用,并且与处理器架构无关。处理器模块向代理提供所需节点的规范,代理将规范化重写规则应用于规范。因此,结果要么与规范完全匹配,要么与语义上等价的不同的规范匹配。规范化之后,代理向DFG查询符合规范化规范的节点是否已经存在。如果是,则返回对它的引用,而不是创建一个新节点。因此,一个图中不可能有两个不同的节点符合相同的规范,或者在标准化下等价。
规范化重写规则: 包括操作简化、公共子表达式消除和随后(subsequent)的内存访问。
操作简化 假设我们遇到一个算术/逻辑运算,其中所有的输入参数都是常量。然后,该操作可以被其结果替换。
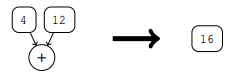
公共子表达式 消除通常在一个代码片段中,相同的值会被重新计算几次.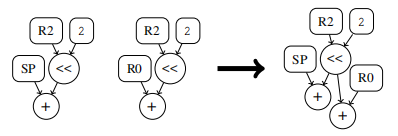
内存访问 从主内存中加载和存储数据是一种常见的操作。然而,这不必与语义有关系,但可能是由于寄存器填充和溢出。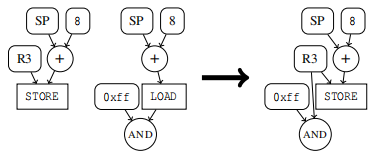
Advantages
在图的构造过程中应用规范化重写规则比在图完全生成之后这样做有几个优势。首先,如果归一化函数 h h h的运行时间复杂度是常数,那么包括归一化在内的构造阶段的运行时间复杂度随着汇编指令的数量线性增长,而在一个完全生成的DFG上重复应用则是二次元复杂度。
Purging and Subgraph isomorphism
构造完成DFG之后会进行purging, 这部分主要是对DFG的进一步简化, 具体可以参考论文, 此处略过. 之后以简化后的DFG作为输入执行子图同构搜索算法. 搜索子图同构是NPC问题, Ullmann[66]提出的解决方案是一种带修剪的递归回溯算法。本篇论文采用的就是UIImann算法进行同构子图搜索.
Symbolic execution
在分析函数时,我们可能会遇到条件指令。对于确定的条件,输入变量被限制在一个域中,这样就只有一个可能的评估结果. 比如, 由固定次数的迭代组成的循环结束时的条件跳转指令。相反,对于欠确定条件,输入变量没有足够的限制来决定一个固定的结果。
在构造任意函数 f f f的DFG过程中,保持状态 S = ( G , P , B ) S = (G,P,B) S=(G,P,B),其中 G = ( V , E ) G = (V,E) G=(V,E)为部分构造的DFG。 P P P是路径条件,在符号执行期间构造; 将未知变量限制在某个域中的谓词,这样,如果满足条件,执行路径将遵循DFG构造期间所采用的相同路径。换句话说: P P P的满足保证 G G G代表 f f f的输入/输出关系。相反的说法不一定是正确的。
对于不确定的条件分支, 朴素的想法是对于每个可能的分支都fork出一个实例继续向下执行, 结果就是一个DFGs的集合, 每个DFG表示一个可能的执行路径, 但是这种方法会遇到状态爆炸问题, 所以实际不可行. 那么论文提出一种权衡覆盖率和性能的方法:
何时应用分叉的策略与符号执行本身关系不大。因此,我们引入路径Oracle,一个在图构造阶段被查询的独立实体,每次出现欠定条件c。它决定c的计算结果是真还是假,或者构造分叉并遵循两个执行路径。
Path Oracle Policy
设B是记录oracle对路径所做决策的日志.
定义 d e , i ∈ { T A K E _ T R U E , T A K E _ F A L S E , T A K E _ B O T H } d_{e,i} ∈ \{TAKE\_TRUE,TAKE\_FALSE,TAKE\_BOTH\} de,i∈{ TAKE_TRUE,TAKE_FALSE,TAKE_BOTH}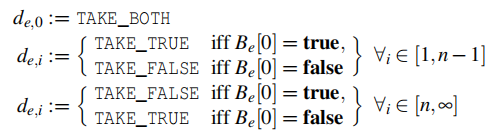
简单来说, 如果执行路径选择到了密码原语所在的分支, 那么在i = 0处的执行路径会让我们重新访问e。我们的目标是构造一个由原语的n次迭代组成的DFG,我们重复这个路径选择n - 1次,然后走相反的路径,导致执行流退出循环。最后,构建阶段产生两个DFG: 一个表示0次迭代,另一个表示n次迭代。
Signature Expression
为了检测子图同构,我们需要一种表示签名图的方法。图4描述了签名领域特定语言(DSL)的示意图。圆框表示关键字,而方框表示数据类型。通过表达式数据类型生成新的图节点.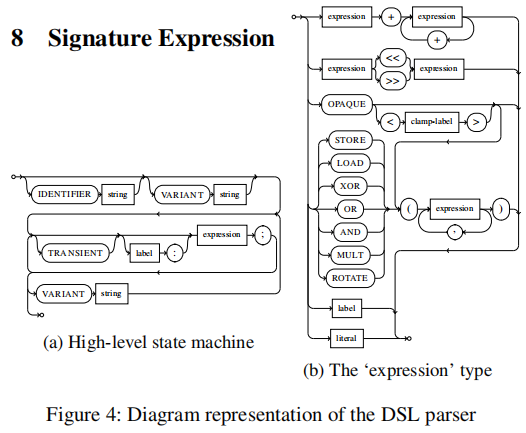
比如, LFSR算法的DFG为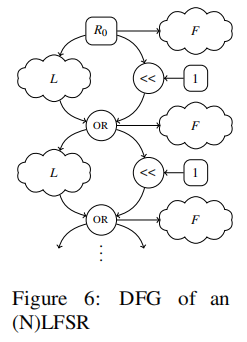
LFSR的签名为
最后生成的签名图也需要经过规范化和purging再与DFG进行同构匹配.
论文给每个特定的密码算法都定义了签名, 具体来说就是将每个密码原语的性质提炼出来抽象成一个DFG, 最后转化成用DSL来准确描述.
(具体的转化过程是具体算法具体分析, 论文没有给明确的伪代码描述.
实验
实验指标
准确性和运行时间
图构造
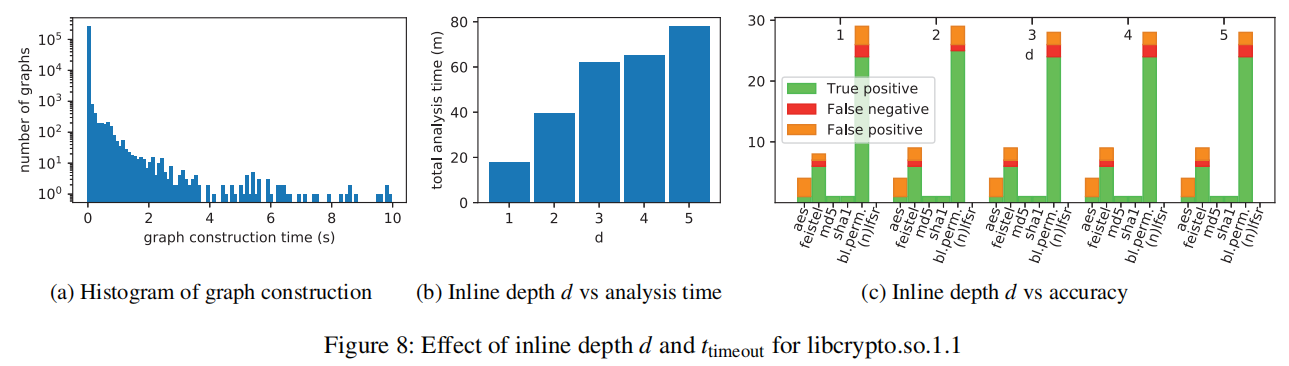
DFG构造受停机问题影响, 所以不能保证图形构造会终止。因此,我们引入了一个图构造超时 t t i m e o u t t_{timeout} ttimeout 图8a描述了libcrypto.so.1.1分析期间构造的所有图的图构造时间t的直方图。
它显示,对于绝大多数的图,构建在10秒内完成。所以可以取 t t i m e o u t t_{timeout} ttimeout = 10s。
此外,我们必须决定当所分析的函数调用另一个函数时采取什么操作。我们要么执行内联,从而将整个调用合并到生成的DFG中,要么通过单个CALL操作表示它。为了解决这个问题,我们定义了一个可调变量d,表示函数调用内联到的深度级别。通过在libcrypto.so.1.1上运行分析来研究d的影响,同时使用不同的值,并从运行时间和准确性方面衡量性能。图8b描述了在d的影响下,完成libcrypto.so.1.1中每个函数的整个分析所花费的时间。
图8c包含每个签名的精度测量值。省略了真正的否定,因为它们覆盖了绝大多数的结果,因此影响可读性。
密码识别
在OpenWRT是一个常用的网络程序库, 对应的二进制文件中包含常见的密码原语.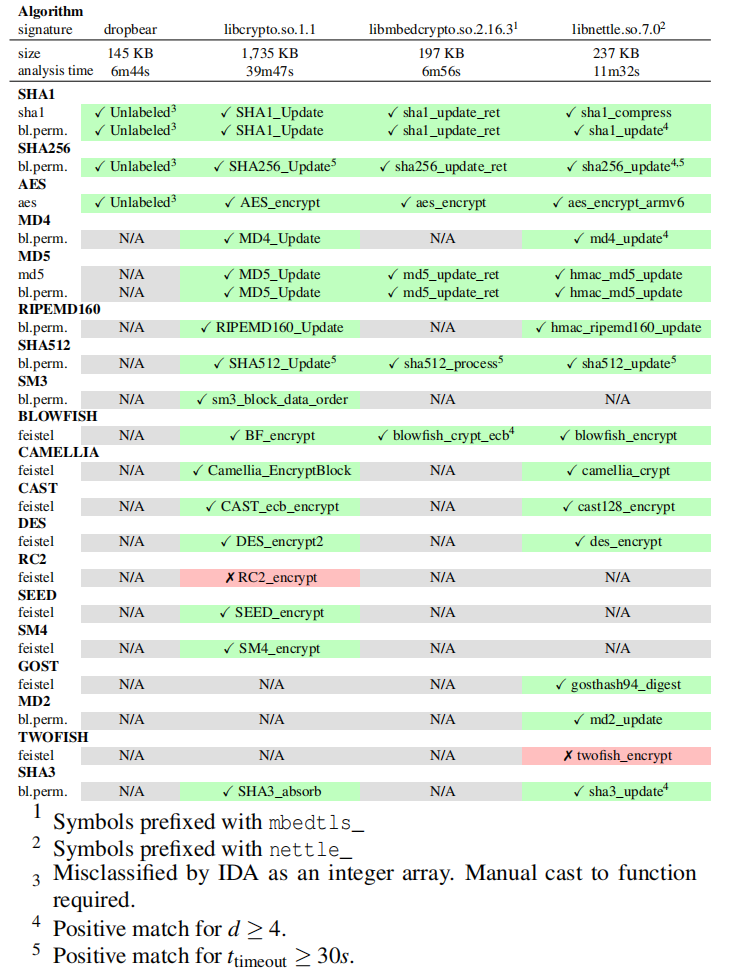
表中的每个单元描述第一个正结果对应的二进制中的符号名称,或者,在出现假阴性的情况下,描述期望正结果的符号名称。结果表明,论文的解决方案能够成功地及时识别各种二进制文件中存在的绝大多数密码原语。如果准确性优先于性能,则可以调优参数以改进检测。
总结
related work
[43] Pierre Lestringant, Frédéric Guihéry, and Pierre-Alain Fouque. Automated identification of cryptographic primitives in binary code with data flow graph isomorphism. In Proceedings of the 10th ACM Symposium on Information, Computer and Communications Security, pages 203–214. ACM, 2015.
[66] Julian R Ullmann. An algorithm for subgraph isomorphism. Journal of the ACM (JACM), 23(1):31–42, 1976.
[67] Roel Verdult. The (in) security of proprietary cryptography. PhD thesis, [Sl: sn], 2015.
Insights
(1) 现有的识别密码算法的方法没有结合符号执行进行, 引入符号执行和对密码原语的结构化描述, 可以获得更好的效果
(2) 参考对密码学原语的DSL描述, 可以对二进制文件中目标进行类似处理来辅助识别过程
(3) 利用综合, 优化, 语义等价做二进制代码去混淆
边栏推荐
- [trusted computing] Lesson 10: TPM password resource management (II)
- [principles and technologies of network attack and Defense] Chapter 5: denial of service attack
- Learn to make dynamic line chart in 3 minutes!
- Cartoon | who is the first ide in the universe?
- < code random recording two brushes> linked list
- Automated testing: a practical skill that everyone wants to know about robot framework
- 元宇宙带来的创意性改变
- Discuss | what preparations should be made before ar application is launched?
- Tips of this week 141: pay attention to implicit conversion to bool
- Hutool - 轻量级 DB 操作解决方案
猜你喜欢

Pro2: modify the color of div block
Yarn capacity scheduler (ultra detailed interpretation)
回归问题的评价指标和重要知识点总结

zdog.js火箭转向动画js特效
zdog. JS rocket turn animation JS special effects
小程序中实现付款功能

性能测试过程和计划
Ten thousand words nanny level long article -- offline installation guide for datahub of LinkedIn metadata management platform

【蓝桥杯集训100题】scratch从小到大排序 蓝桥杯scratch比赛专项预测编程题 集训模拟练习题第17题
Pro2:修改div块的颜色
随机推荐
Youth experience and career development
你真的理解粘包与半包吗?3分钟搞懂它
The report of the state of world food security and nutrition was released: the number of hungry people in the world increased to 828million in 2021
自动化测试:Robot FrameWork框架大家都想知道的实用技巧
[trusted computing] Lesson 13: TPM extended authorization and key management
< code random recording two brushes> linked list
swiper左右切换滑块插件
Classification of regression tests
USB通信协议深入理解
Discuss | what preparations should be made before ar application is launched?
Using stored procedures, timers, triggers to solve data analysis problems
Disk storage chain B-tree and b+ tree
通过 Play Integrity API 的 nonce 字段提高应用安全性
直播软件搭建,canvas文字加粗
Backup Alibaba cloud instance OSS browser
Main work of digital transformation
漫画 | 宇宙第一 IDE 到底是谁?
Mobile app takeout ordering personal center page
基于百度飞浆平台(EasyDL)设计的人脸识别考勤系统
js拉下帷幕js特效显示层