当前位置:网站首页>[mv-3d] - multi view 3D target detection network
[mv-3d] - multi view 3D target detection network
2022-07-02 03:27:00 【Fireworks at dawn in the city】
MV-3D: Multi view 3D Target detection network
One 、 Preface
At present, there are two main kinds of spatial point cloud detection . One is to take 3D point cloud as input directly , Directly into the convolution network or into voxels into . The other is to make 3D The point cloud is mapped to 2D, Mainly aerial view or front view . Generally speaking, the first method is rich in target detection information , But the corresponding amount of calculation is also large ; If the second method is handled properly, the amount of calculation is relatively small , But it will lead to the loss of information .
MV-3D The paper adopts the second method , But considering the loss of information , The front view and pictures are also used for fusion correction .
The paper : https://arxiv.org/abs/1611.07759
Two 、 The whole idea
As shown in the figure below :
Regional proposal network (PPN) It has become an important part of high-precision target detection .MV-3D Is based on RPN Architecture , It can be seen that the whole is mainly divided into two main parts :3D Proposal Network and Rregion-based Fusion Network. There are three types of network input : Top view (BV)、 Front view (FV) And images (RGB), After convolution network output and 3D Proposal Conduct ROI pooling The fusion , Then select 3D Bounding box .
3、 ... and 、 Algorithm analysis
1、3D Proposal Network
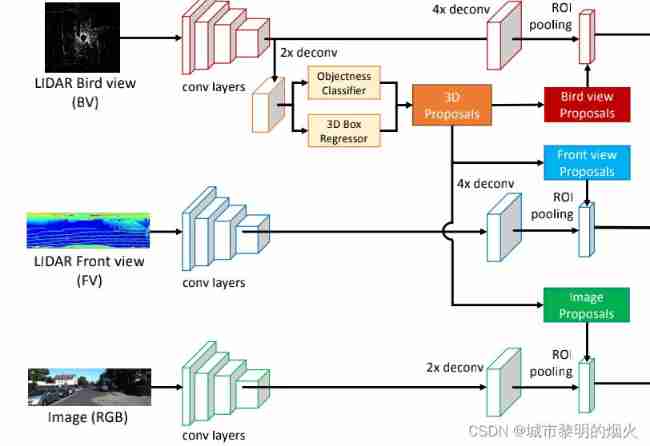
There are three types of network input : Top view (BV)、 Front view (FV) And images (RGB). The main idea is :
- The convolution layer in this paper adopts VGG-16, The last pool layer is removed , Therefore, the convolution part is 8 Next sampling .
- 3D The proposal is generated from the top view , Because projection to the aerial view can keep the size of the object more , And the difference in the vertical direction is small, which can be obtained more accurately 3D Bounding box .
- In addition, in order to deal with ultra small objects , We use feature approximation to obtain high-resolution feature maps . Specially , We insert a before entering the last convolution feature 2 The bilinear up sampling layer of times is mapped to 3D Proposal network . Similarly , We are BV/FV/RGB The branch ROI A 4x/4x/2x The upper sampling layer of .
- The generated 3D Proposal Project to each view and enter together with the convoluted network ROI pooling. From different views / Modal features usually have different resolutions , So use... For each view ROI Pool to get eigenvectors of the same length .
The aerial view shows
The aerial view is represented by the height 、 Intensity and density encoded , The projected point cloud is discretized into a resolution of 0.1m 2-D grid of .
- For each grid cell , The height feature is calculated as the maximum height of the midpoint of the element , In order to encode more detailed height information , Point clouds are equally divided into m A slice , Calculate the height map of each piece , obtain m Height map .
- The intensity feature is the reflection value of the point with the maximum height in each cell , Apply to the whole point cloud .
- The point cloud density represents the number of points in each cell , It also acts on the whole point cloud .
In general, the aerial view is encoded as (m+2) Channel features .
The front view shows
The front view representation provides supplementary information for the aerial view representation . Because the LIDAR point cloud is very sparse , Projecting it onto the image plane will produce a sparse two-dimensional point map . contrary , We project it onto a cylinder , To generate a dense front view map .
Let the coordinates of a point in the point cloud be P = (x,y,z), The corresponding coordinates in the front view are p f v = ( r , c ) p_{fv} = (r,c) pfv=(r,c). The mutual transformation relationship between the two is :
- C = [ arctan ( y , x ) Δ θ ] [ \frac{\arctan(y,x)}{\Delta \theta }] [Δθarctan(y,x)]
- r = [ arctan ( z , x 2 + y 2 ) Δ ϕ ] [ \frac{\arctan(z,\sqrt{x^2+y^2} )}{\Delta\phi }] [Δϕarctan(z,x2+y2)]
Among them , Δ θ \Delta \theta Δθ and D e l t a ϕ Delta\phi Deltaϕ They are the horizontal and vertical resolutions of the laser beam .
The renderings are as follows :
2、Rregion-based Fusion Network
A region based fusion network is designed , Effectively combine the characteristics of multiple perspectives , Jointly classify the target suggestions and carry out direction oriented three-dimensional border regression .
In order to combine information from different features , Deep fusion method is adopted , Fuse multi view features . In addition, the paper will also deeply integrate the network and early / The architecture of late converged networks is relatively .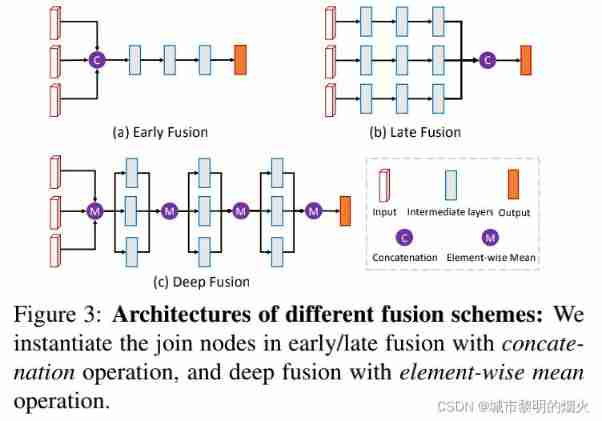
Those who have L Layer network , Early fusion combines the features of multiple views from the input phase f v {fv} fv:
H l , l = 1 , ⋅ ⋅ ⋅ , L {H_{l},l=1,···,L} Hl,l=1,⋅⋅⋅,L Is the characteristic transformation function , and ⊕ It is a connection operation ( for example , Connect 、 Sum up ).
by comparison , Later fusion uses independent subnets to learn feature transformation independently , And combine their output in the prediction stage :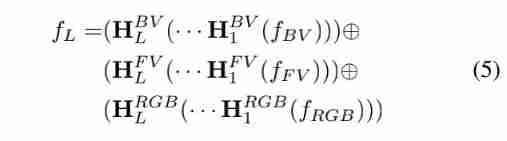
The deep fusion process designed in this paper is as follows :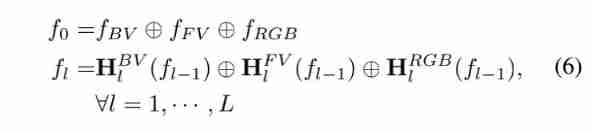
M Represent the element level mean to perform the connection operation of deep fusion , Because it is more flexible when combined with jumping training .
3、3D Bounding box regression
Considering the fusion characteristics of multi view Networks , We return from the 3D proposal to the oriented 3D bounding box . especially , The return goal is 3D Bounding box's 8 Corner : t = ( ∆ x 0 , ⋅ ⋅ ⋅ , ∆ x 7 , ∆ y 0 , ⋅ ⋅ ⋅ , ∆ y 7 , ∆ z 0 , ⋅ ⋅ ⋅ , ∆ z 7 ) t=(∆x_0,···,∆x_7,∆y_0, · · · , ∆y_7, ∆z_0, · · · , ∆z_7) t=(∆x0,⋅⋅⋅,∆x7,∆y0,⋅⋅⋅,∆y7,∆z0,⋅⋅⋅,∆z7). They are encoded as the corner offset normalized by the diagonal length of the suggestion box . Despite this 24d Vector representation is redundant , But it is found that this coding method is better than the center and size coding method .
In addition, the paper mentioned in the model , The direction of the object can be calculated from the predicted three-dimensional frame angle .( This does not give the calculation process )
Multi task loss is used to jointly predict object categories and three-dimensional boxes . In the generation proposal network , Category loss uses cross entropy , and 3D box Loss use smooth L1_loss.
During training , just / negative roi It is based on aerial view IoU Overlap to determine . If the aerial view IoU The overlap is greater than 0.5, be 3D The proposal is considered positive . In the process of reasoning , On the three-dimensional boundary box Three dimensional after regression box On the application NMS. We will 3D The box is projected into the aerial view , To calculate their IoU overlap . We use IoU The threshold for 0.05 In order to delete redundant box, To ensure that objects cannot occupy the same space in the aerial view .
4、 Network regularization
Compared with two-dimensional network , Regularization can effectively avoid over fitting of the network , Make the whole network go on effectively . In this paper, we use two methods to regularize the region based fusion network :drop-path training and auxiliary losses.
For each iteration , We randomly choose to make a global descent path or a local descent path, and its probability is 50%. If you choose the global descent path , We choose a single view from three views . If the local descent path is selected , Then the path of each connecting node is random, and the probability of decline is 50%. We ensure that for each connection node , Keep at least one input path .( This is translated , I always feel inaccurate )
In order to further enhance the presentation ability of each view , This paper adds auxiliary paths and losses to the network .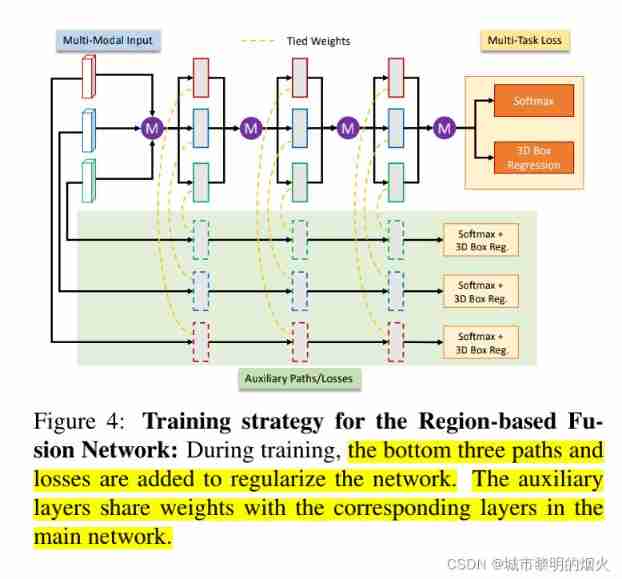
In the process of training , Add three paths and losses at the bottom , Regularize the network . The auxiliary layer shares the weight with the corresponding layer in the main network .
Be careful : During the inspection , These secondary paths will be deleted .
result
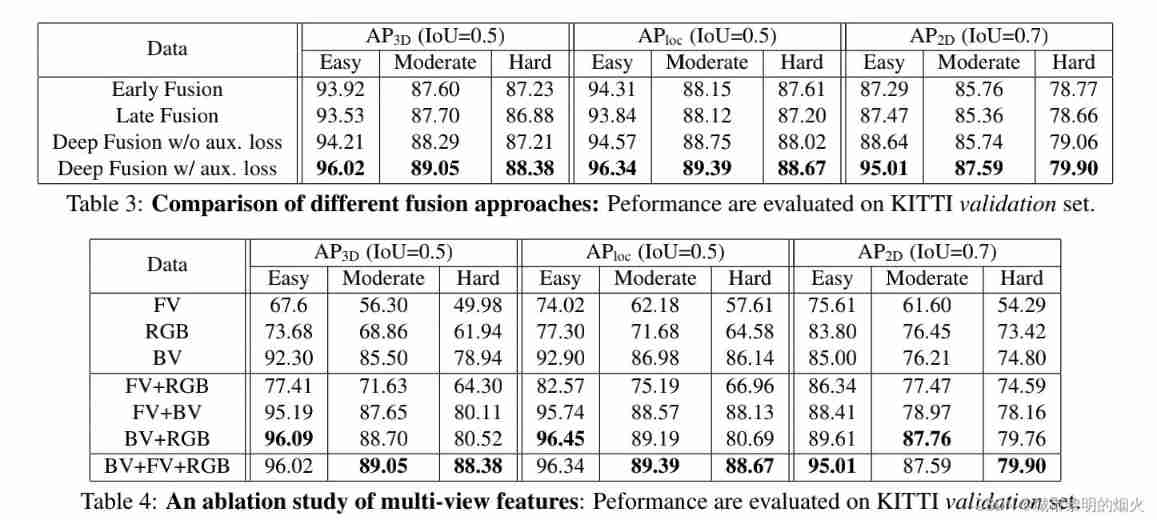
Reference resources :
Autopilot |3D object detection :MV3D-Net( One )
【 Interpretation of the thesis 】MV3D-Net Multi view for autopilot 3D Target detection network
边栏推荐
- West digital decided to raise the price of flash memory products immediately after the factory was polluted by materials
- Download and use of the super perfect screenshot tool snipaste
- 数据库文件逻辑结构形式指的是什么
- Exchange rate query interface
- Getting started with MQ
- 焱融看 | 混合云时代下,如何制定多云策略
- Spark Tuning
- GSE104154_scRNA-seq_fibrotic MC_bleomycin/normalized AM3
- 3048. Number of words
- PHP array processing
猜你喜欢

命名块 verilog

Form custom verification rules

JS <2>

In the era of programmers' introspection, five-year-old programmers are afraid to go out for interviews
Detailed explanation of the difference between Verilog process assignment
Verilog 避免 Latch

数据传输中的成帧
Large screen visualization from bronze to the advanced king, you only need a "component reuse"!
Comment élaborer une stratégie nuageuse à l'ère des nuages mixtes
Verilog 过程连续赋值
随机推荐
3048. Number of words
spark调优
QT environment generates dump to solve abnormal crash
Unity脚本的基础语法(8)-协同程序与销毁方法
ORA-01547、ORA-01194、ORA-01110
Exchange rate query interface
Which of PMP and software has the highest gold content?
Global and Chinese market of handheld ultrasonic scanners 2022-2028: Research Report on technology, participants, trends, market size and share
Pycharm2021 delete the package warehouse list you added
ORA-01547、ORA-01194、ORA-01110
MySQL connection query and subquery
C#聯合halcon脫離halcon環境以及各種報錯解决經曆
Global and Chinese markets for hand hygiene monitoring systems 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of gynaecological health training manikin 2022-2028: Research Report on technology, participants, trends, market size and share
West digital decided to raise the price of flash memory products immediately after the factory was polluted by materials
Verilog avoid latch
竞争与冒险 毛刺
C # joint halcon out of halcon Environment and various Error Reporting and Resolution Experiences
Verilog reg register, vector, integer, real, time register
数据库文件逻辑结构形式指的是什么