当前位置:网站首页>Pytorch(六) —— 模型调优tricks
Pytorch(六) —— 模型调优tricks
2022-07-07 04:44:00 【CyrusMay】
Pytorch(六) —— 模型调优tricks
1.正则化 Regularization
1.1 L1正则化
import torch
import torch.nn.functional as F
from torch import nn
device=torch.device("cuda:0")
MLP = nn.Sequential(nn.Linear(128,64),
nn.ReLU(inplace=True),
nn.Linear(64,32),
nn.ReLU(inplace=True),
nn.Linear(32,10)
)
MLP.to(device)
loss_classify = nn.CrossEntropyLoss().to(device)
# L1范数
l1_loss = 0
for param in MLP.parameters():
l1_loss += torch.sum(torch.abs(param))
loss = loss_classify+l1_loss
1.2 L2正则化
import torch
import torch.nn.functional as F
from torch import nn
device=torch.device("cuda:0")
MLP = nn.Sequential(nn.Linear(128,64),
nn.ReLU(inplace=True),
nn.Linear(64,32),
nn.ReLU(inplace=True),
nn.Linear(32,10)
)
MLP.to(device)
# L2范数
opt = torch.optim.SGD(MLP.parameters(),lr=0.001,weight_decay=0.1) # 通过weight_decay实现L2
loss = nn.CrossEntropyLoss().to(device)
2 动量与学习率衰减
2.1 momentum
opt = torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.78,weight_decay=0.1)
2.2 learning rate tunning
- torch.optim.lr_scheduler.ReduceLROnPlateau() 当损失函数值不降低时使用
- torch.optim.lr_scheduler.StepLR() 按照一定步数降低学习率
opt = torch.optim.SGD(net.parameters(),lr=1)
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=opt,mode="min",factor=0.1,patience=10)
for epoch in torch.arange(1000):
loss_val = train(...)
lr_scheduler.step(loss_val) # 监听loss
opt = torch.optim.SGD(net.parameters(),lr=1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer=opt,step_size=30,gamma=0.1)
for epoch in torch.arange(1000):
lr_scheduler.step() # 监听loss
train(...)
3. Early Stopping
4. Dropout
model = nn.Sequential(
nn.Linear(256,128),
nn.Dropout(p=0.5),
nn.ReLu(),
)
by CyrusMay 2022 07 03
边栏推荐
- 3D reconstruction - stereo correction
- 图解GPT3的工作原理
- Chip information website Yite Chuangxin
- 这5个摸鱼神器太火了!程序员:知道了快删!
- Linux server development, detailed explanation of redis related commands and their principles
- Introduction to basic components of wechat applet
- misc ez_ usb
- Hands on deep learning (IV) -- convolutional neural network CNN
- Use and analysis of dot function in numpy
- A bit of knowledge - about Apple Certified MFI
猜你喜欢
![[guess-ctf2019] fake compressed packets](/img/a2/7da2a789eb49fa0df256ab565d5f0e.png)
[guess-ctf2019] fake compressed packets
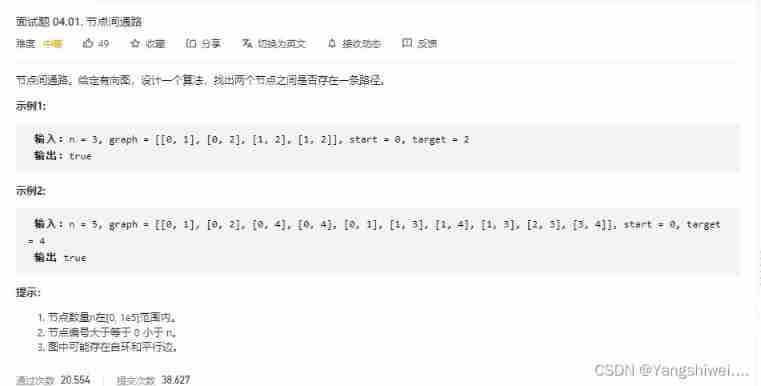
Li Kou interview question 04.01 Path between nodes

2022 recurrent training question bank and answers of refrigeration and air conditioning equipment operation
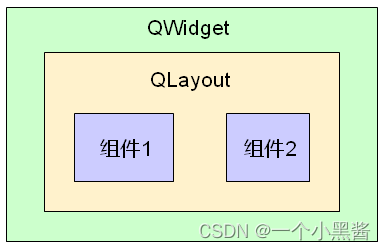
Qt学习26 布局管理综合实例
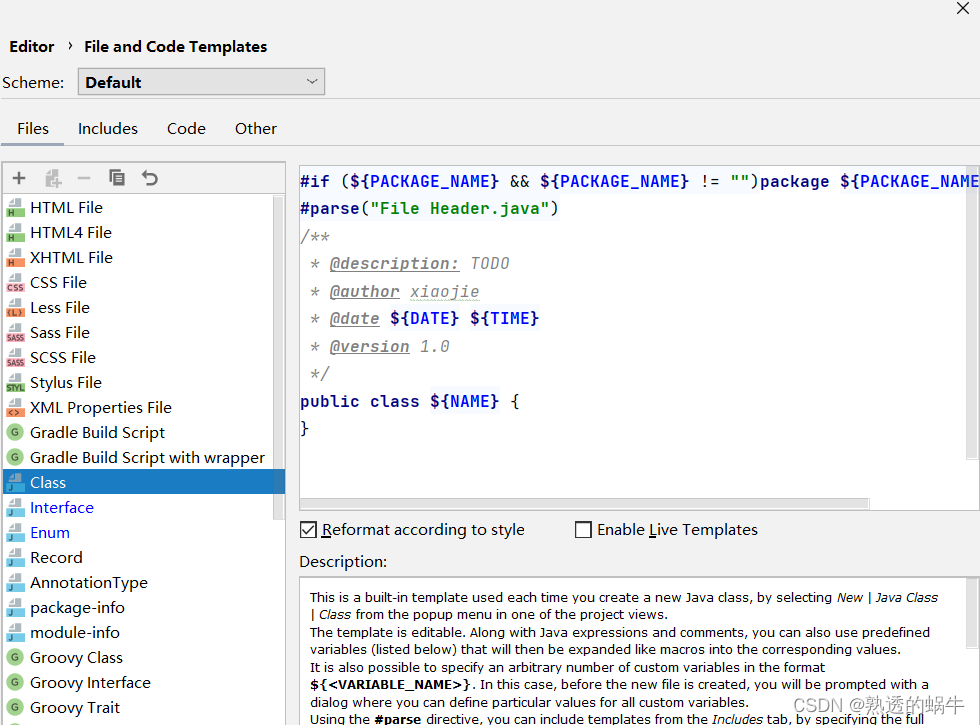
Idea add class annotation template and method template
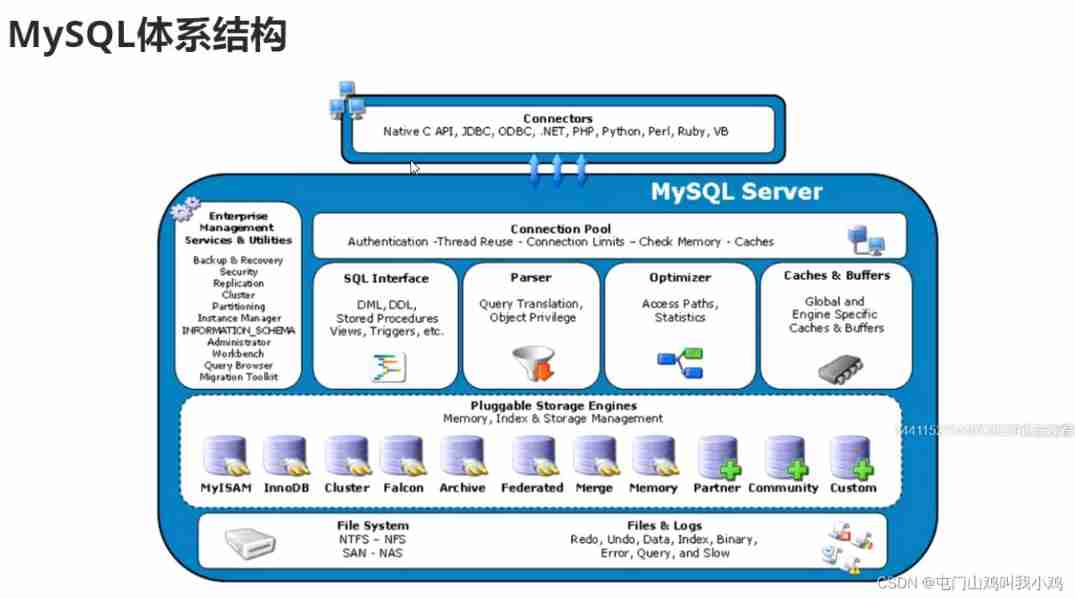
Linux server development, SQL statements, indexes, views, stored procedures, triggers
![[Stanford Jiwang cs144 project] lab4: tcpconnection](/img/fd/704d19287a12290f779cfc223c71c8.png)
[Stanford Jiwang cs144 project] lab4: tcpconnection
【webrtc】m98 screen和window采集
![[2022 ciscn] replay of preliminary web topics](/img/1c/4297379fccde28f76ebe04d085c5a4.png)
[2022 ciscn] replay of preliminary web topics

2022焊工(初级)判断题及在线模拟考试
随机推荐
What is the interval in gatk4??
Most elements
C语言队列
C语言通信行程卡后台系统
2022 National latest fire-fighting facility operator (primary fire-fighting facility operator) simulation questions and answers
开源生态|打造活力开源社区,共建开源新生态!
Custom class loader loads network class
pytest+allure+jenkins环境--填坑完毕
Yugu p1020 missile interception (binary search)
Common validation comments
Numbers that appear only once
Cnopendata geographical distribution data of religious places in China
Regular e-commerce problems part1
Leetcode 40: combined sum II
【VHDL 并行语句执行】
Linux server development, MySQL process control statement
Li Kou interview question 04.01 Path between nodes
Figure out the working principle of gpt3
2022年茶艺师(中级)考试试题及模拟考试
探索Cassandra的去中心化分布式架构