当前位置:网站首页>根据csv文件某一列字符串中某个数字排序
根据csv文件某一列字符串中某个数字排序
2022-07-06 08:19:00 【不求大富大贵只求富可敌国】
**
文件如下所示:
**
根据第一列第四个数字大小进行排序(请注意“汉字”顺序需要与前面的视频顺序对应)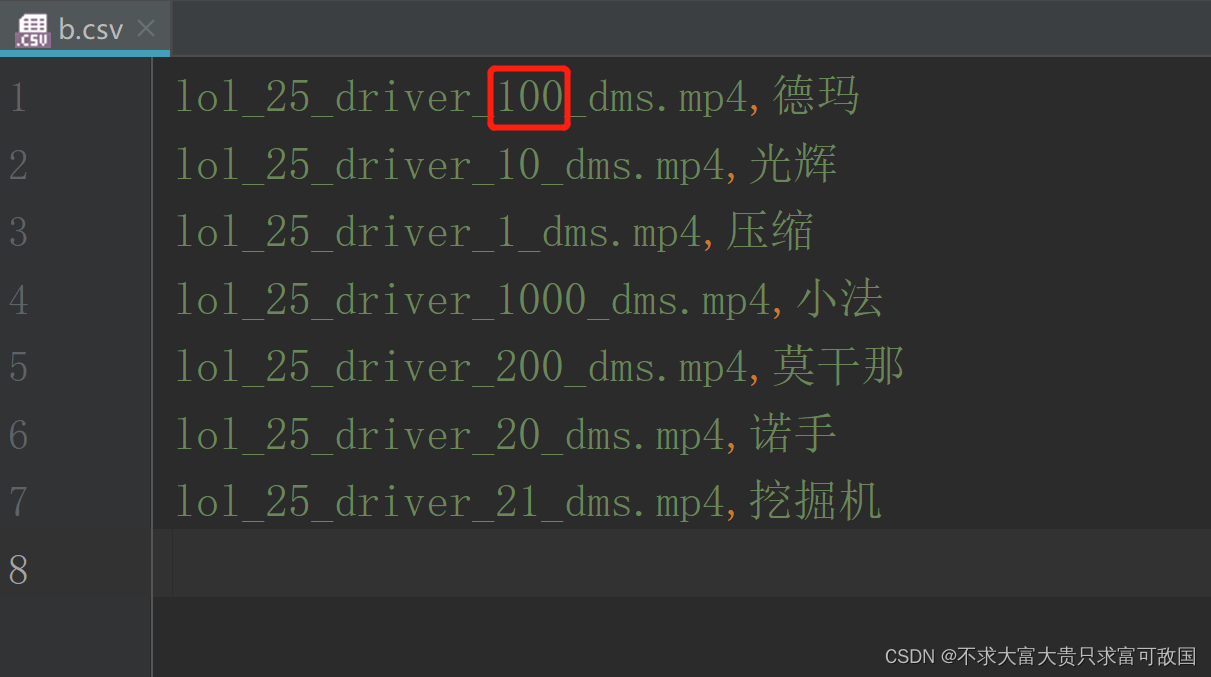
**
解决思路:
**
1、把数据提取出来
2、把第一列split成列表
3、zip组合:拆分后的列表与第二列,由于key是可哈希的且不能是列表,而value是可以修改,所以把第一列当value,第二列当key, dict转换为字典
4、依据value,使用sorted排序
5、通过for:循环排序后的结果,把拆分的数据join组合后,分别追加到两个空列表,再次zip即可(为了把两列的顺序调换回来)(可能有人会有疑问:为什么不采用“键值对”反转的形式,而搞得那么麻烦,在第二步骤也讲了,字典的key不能是列表,所以不能通过反转键值对解决)
**
具体代码如下:
**
import os
import pandas as pd
path=r"C:\Users\jam96\PycharmProjects\all_module\pandas_test\a"
dir_path=os.path.dirname(os.path.abspath(__file__))
result_path=os.path.join(dir_path,"data")
if not os.path.exists(result_path):
os.mkdir(result_path)
files=os.listdir(path)
print(files)
num=1
for i in files:
res=pd.read_csv(filepath_or_buffer=os.path.join(path,i),header=None)
a=res.values[:,0]
b=res.values[:,1]
d=[]
for i in a:
c=i.split("_")
d.append(c)
new=dict(zip(b,d))
#sorted返回的是列表
new1=sorted(new.items(),key=lambda x:int(x[1][3]))
k=[]
j=[]
for i in new1:
k.append(i[0])
j.append("_" .join(i[1]))
result=zip(j,k)
pd1=pd.DataFrame(data=result)
pd1.to_csv(result_path+os.path.sep+"C00"+str(num)+".csv",index=False,header=None)
num+=1
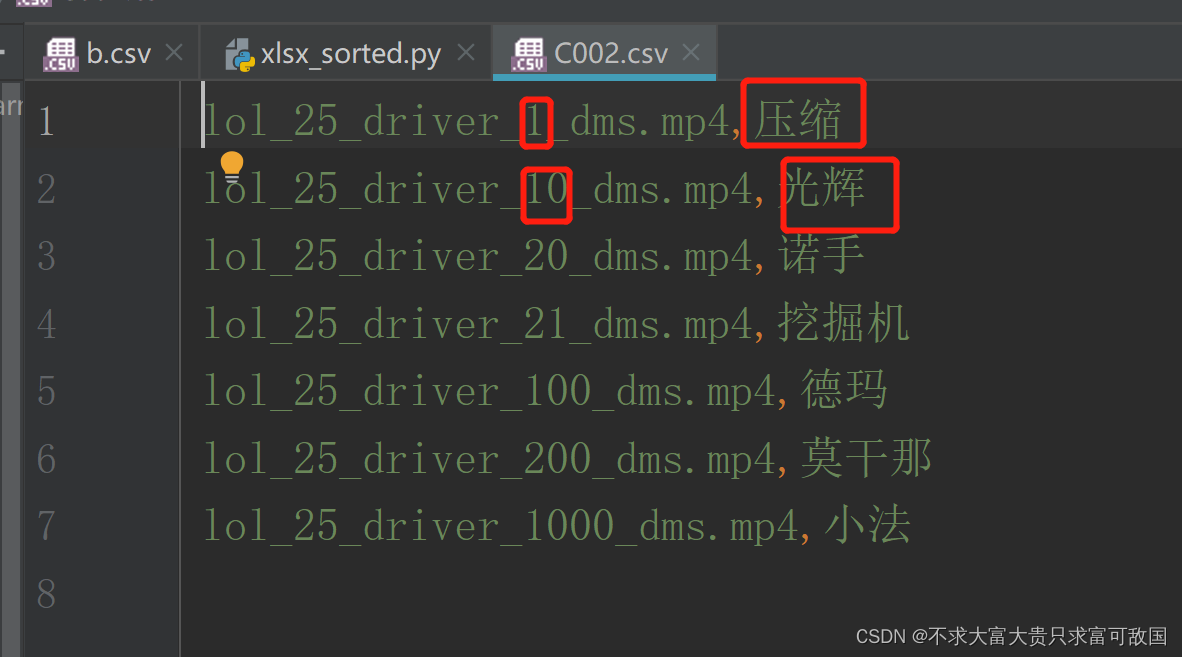
运行结果如下:
优化代码
后来发现以上代码写的冗余,其实没必要那么复杂,另一方面是由于对字典的掌握熟练度不够,优化后的代码如下:
import pandas as pd
#csv文件路径
path=r"D:\TestSet\csv\dms\abc.csv"
#读csv文件
res=pd.read_csv(path,encoding="gbk",header=None)
#得到第一列与第二列
a=res.values[:,0]
b=res.values[:,1]
#把第一列的数据与第二列结合起来
c=dict(zip(a,b))
#根据key的第四项大小进行排序,请注意使用了“int”对结果进行了强制转换为整型
d=sorted(c.items(),key=lambda x:int(x[0].split("_")[3]))
#把排序后的结果再次写入新的csv
e=pd.DataFrame(data=d)
e.to_csv(path_or_buf=r"C:\Users\xdjiang6\PycharmProjects\日志结果批量修改标注集\data\a.csv",index=False,header=None)
边栏推荐
- 07- [istio] istio destinationrule (purpose rule)
- hcip--mpls
- Summary of MySQL index failure scenarios
- String to leading 0
- Wincc7.5 download and installation tutorial (win10 system)
- Yu Xia looks at win system kernel -- message mechanism
- Flash return file download
- "Designer universe": "benefit dimension" APEC public welfare + 2022 the latest slogan and the new platform will be launched soon | Asia Pacific Financial Media
- Huawei cloud OBS file upload and download tool class
- NFT smart contract release, blind box, public offering technology practice -- jigsaw puzzle
猜你喜欢
Database basic commands

National economic information center "APEC industry +": economic data released at the night of the Spring Festival | observation of stable strategy industry fund
Online yaml to CSV tool
你想知道的ArrayList知识都在这
ESP series pin description diagram summary
C language custom type: struct
Golang DNS write casually
![08- [istio] istio gateway, virtual service and the relationship between them](/img/fb/09793f5fd12c2906b73cc42722165f.jpg)
08- [istio] istio gateway, virtual service and the relationship between them
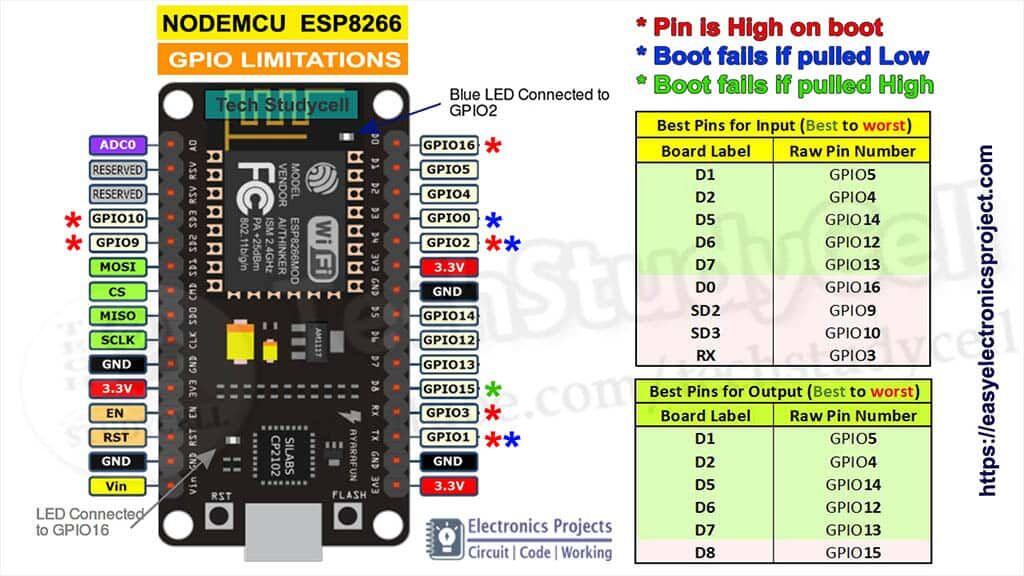
ESP系列引脚說明圖匯總
![07- [istio] istio destinationrule (purpose rule)](/img/be/fa0ad746a79ec3a0d4dacd2896235f.jpg)
07- [istio] istio destinationrule (purpose rule)
随机推荐
The Vice Minister of the Ministry of industry and information technology of "APEC industry +" of the national economic and information technology center led a team to Sichuan to investigate the operat
Data governance: metadata management
指针进阶---指针数组,数组指针
Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center
Convolution, pooling, activation function, initialization, normalization, regularization, learning rate - Summary of deep learning foundation
07- [istio] istio destinationrule (purpose rule)
Migrate data from a tidb cluster to another tidb cluster
[research materials] 2021 Research Report on China's smart medical industry - Download attached
Use Alibaba icon in uniapp
化不掉的钟薛高,逃不出网红产品的生命周期
Résumé des diagrammes de description des broches de la série ESP
Day29-t77 & t1726-2022-02-13-don't answer by yourself
将 NFT 设置为 ENS 个人资料头像的分步指南
"Friendship and righteousness" of the center for national economy and information technology: China's friendship wine - the "unparalleled loyalty and righteousness" of the solidarity group released th
Yu Xia looks at win system kernel -- message mechanism
logback1.3. X configuration details and Practice
flask返回文件下载
JS select all and tab bar switching, simple comments
ESP系列引脚说明图汇总
How to use information mechanism to realize process mutual exclusion, process synchronization and precursor relationship