当前位置:网站首页>Kaggle竞赛-Two Sigma Connect: Rental Listing Inquiries
Kaggle竞赛-Two Sigma Connect: Rental Listing Inquiries
2022-07-06 09:16:00 【想成为风筝】
Kaggle竞赛,网址链接:Two Sigma Connect: Rental Listing Inquiries
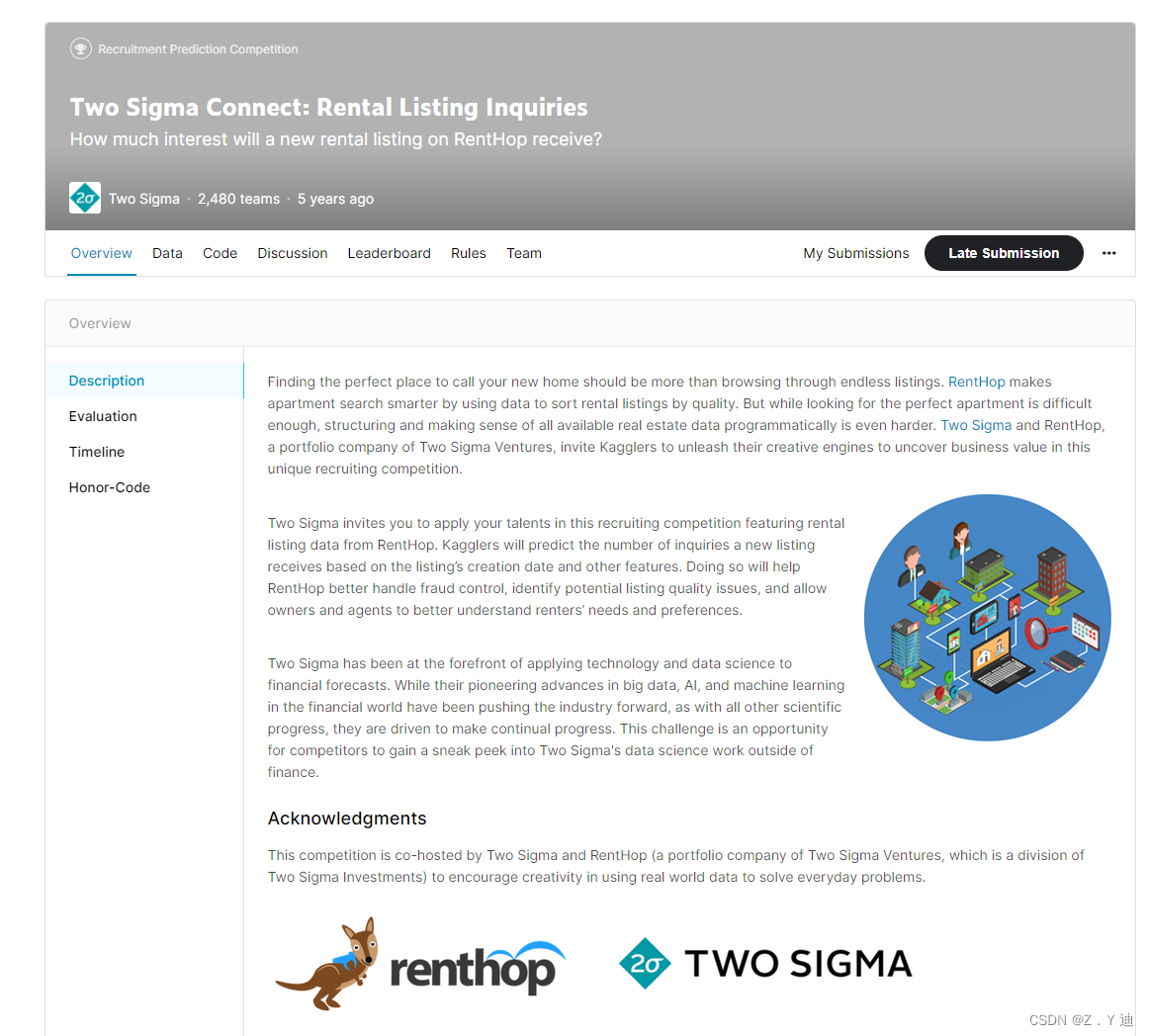
根据租房网站上的数据信息,预测房子的受欢迎程度。(这是一个分类问题,包含以下数据,有类别变量、整数变量、文本变量)。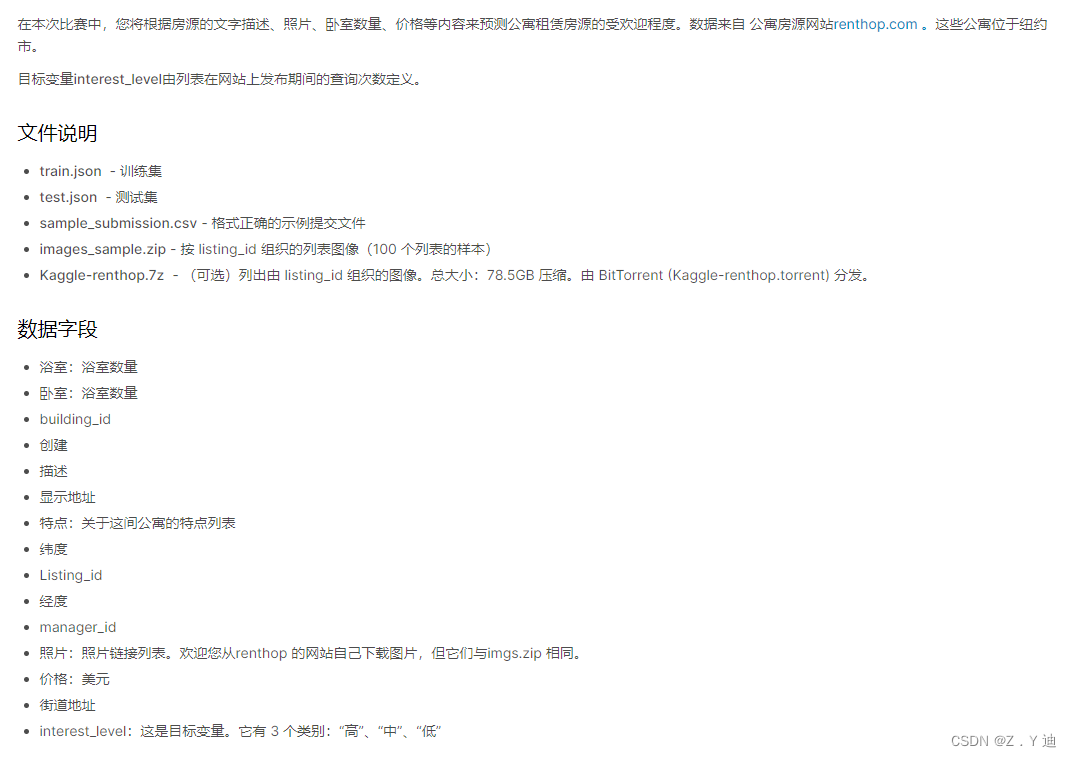
随机森林模型
使用sklearn完成建模预测。数据集可在竞赛官网下载。
import numpy as np
import pandas as pd
import zipfile #官网数据集是zip类型,使用zipfile打开
import os
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss
for dirname, _, filenames in os.walk(r'E:\Kaggle\Kaggle_dataset01\two_sigma'): #改下自己的路径
for filename in filenames:
print(os.path.join(dirname, filename))
train_df = pd.read_json(zipfile.ZipFile(r'E:\Kaggle\Kaggle_dataset01\two_sigma\train.json.zip').open('train.json'))
test_df = pd.read_json(zipfile.ZipFile(r'E:\Kaggle\Kaggle_dataset01\two_sigma\test.json.zip').open('test.json'))
#这里自定义了一个数据处理函数。
def data_preprocessing(data):
data['created_year'] = pd.to_datetime(data['created']).dt.year
data['created_month'] = pd.to_datetime(data['created']).dt.month
data['created_day'] = pd.to_datetime(data['created']).dt.day
data['num_description_words'] = data['description'].apply(lambda x:len(x.split(' ')))
data['num_features'] = data['features'].apply(len)
data['num_photos'] = data['photos'].apply(len)
New_data = data[['created_year','created_month','created_day','num_description_words','num_features','num_photos','bathrooms','bedrooms','latitude','longitude','price']]
return New_data
train_x = data_preprocessing(train_df)
train_y = train_df['interest_level']
test_x = data_preprocessing(test_df)
X_train,X_val,y_train,y_val = train_test_split(train_x,train_y,test_size=0.33) #数据切分
clf = RandomForestClassifier(n_estimators=1000) #随机森林模型
clf.fit(X_train,y_train)
y_val_pred = clf.predict_proba(X_val)
log_loss(y_val,y_val_pred)
y_test_predict = clf.predict_proba(test_x)
labels2idx = {
label:i for i,label in enumerate(clf.classes_)}
sub = pd.DataFrame()
sub['listing_id'] = df['listing_id']
for label in labels2idx.keys():
sub[label] = y[:,labels2idx[label]]
#保存提交文件
#sub.to_csv('submission.csv',index=False) #竞赛提交文件!
运行上述代码,随机森林的效果并不是很好。有人会问为什么不对数据进行归一化预处理?其实使用随机森林时不需要对数据进行归一化处理,所以就没做。想做的话,自己尝试验证一下。如果想使用随机森林提高模型的鲁棒性,可以考虑改进特征工程部分,获取更好的特征!
边栏推荐
- XML文件详解:XML是什么、XML配置文件、XML数据文件、XML文件解析教程
- L2-007 family real estate (25 points)
- [Kerberos] deeply understand the Kerberos ticket life cycle
- MySQL与c语言连接(vs2019版)
- error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_ s instead
- Codeforces Round #771 (Div. 2)
- [CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
- Detailed explanation of nodejs
- Correspondence between STM32 model and contex M
- Vs2019 desktop app quick start
猜你喜欢
![[蓝桥杯2017初赛]方格分割](/img/e9/e49556d0867840148a60ff4906f78e.png)





随机推荐
Codeforces Round #771 (Div. 2)
Library function -- (continuous update)
Software I2C based on Hal Library
Principle and implementation of MySQL master-slave replication
Correspondence between STM32 model and contex M
Word排版(小計)
误删Path变量解决
Contiki源码+原理+功能+编程+移植+驱动+网络(转)
XML file explanation: what is XML, XML configuration file, XML data file, XML file parsing tutorial
Gallery之图片浏览、组件学习
4. Install and deploy spark (spark on Yan mode)
【yarn】CDP集群 Yarn配置capacity调度器批量分配
2020网鼎杯_朱雀组_Web_nmap
互联网协议详解
R & D thinking 01 ----- classic of embedded intelligent product development process
Mysql的索引实现之B树和B+树
[Presto] Presto parameter configuration optimization
sklearn之feature_extraction.text.CountVectorizer / TfidVectorizer
[BSidesCF_2020]Had_ a_ bad_ day
Redis interview questions