当前位置:网站首页>Python机器学习算法:线性回归
Python机器学习算法:线性回归
2020-11-06 01:14:00 【人工智能遇见磐创】

作者|Vagif Aliyev 编译|VK 来源|Towards Data Science

线性回归可能是最常见的算法之一,线性回归是机器学习实践者必须知道的。这通常是初学者第一次接触的机器学习算法,了解它的操作方式对于更好地理解它至关重要。
所以,简单地说,让我们来分解一下真正的问题:什么是线性回归?
线性回归定义
线性回归是一种有监督的学习算法,旨在采用线性方法来建模因变量和自变量之间的关系。换句话说,它的目标是拟合一条最好地捕捉数据关系的线性趋势线,并且,从这条线,它可以预测目标值可能是什么。
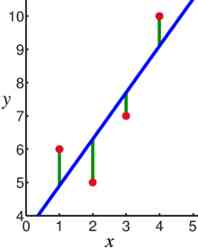
太好了,我知道它的定义,但它是如何工作的呢?好问题!为了回答这个问题,让我们逐步了解一下线性回归是如何运作的:
-
拟合数据(如上图所示)。
-
计算点之间的距离(图上的红点是点,绿线是距离),然后求平方,然后求和(这些值是平方的,以确保负值不会产生错误的值并阻碍计算)。这是算法的误差,或者更好地称为残差
-
存储迭代的残差
-
基于一个优化算法,使得该线稍微“移动”,以便该线可以更好地拟合数据。
-
重复步骤2-5,直到达到理想的结果,或者剩余误差减小到零。
这种拟合直线的方法称为最小二乘法。
线性回归背后的数学
如果已经理解的请随意跳过这一部分
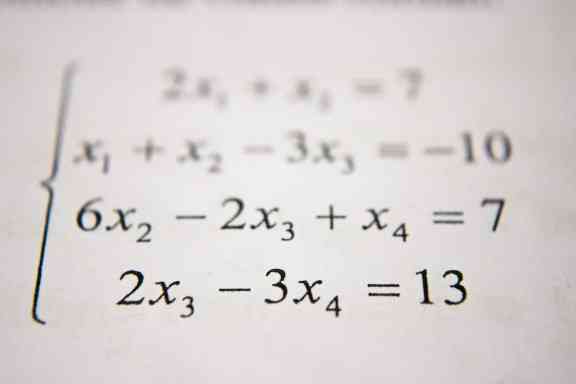
线性回归算法如下:

可以简化为:

以下算法将基本完成以下操作:
- 接受一个Y向量(你的数据标签,(房价,股票价格,等等…)

这是你的目标向量,稍后将用于评估你的数据(稍后将详细介绍)。
- 矩阵X(数据的特征):

这是数据的特征,即年龄、性别、性别、身高等。这是算法将实际用于预测的数据。注意如何有一个特征0。这称为截距项,且始终等于1。
- 取一个权重向量,并将其转置:


这是算法的神奇之处。所有的特征向量都会乘以这些权重。这就是所谓的点积。实际上,你将尝试为给定的数据集找到这些值的最佳组合。这就是所谓的优化。
- 得到输出向量:
这是从数据中输出的预测向量。然后,你可以使用成本函数来评估模型的性能。
这基本上就是用数学表示的整个算法。现在你应该对线性回归的功能有一个坚实的理解。但问题是,什么是优化算法?我们如何选择最佳权重?我们如何评估绩效?
成本函数
成本函数本质上是一个公式,用来衡量模型的损失或“成本”。如果你曾经参加过任何Kaggle比赛,你可能会遇到过一些。一些常见的方法包括:
-
均方误差
-
均方根误差
-
平均绝对误差
这些函数对于模型训练和开发是必不可少的,因为它们回答了“我的模型预测新实例的能力如何”这一基本问题?”. 请记住这一点,因为这与我们的下一个主题有关。
优化算法
优化通常被定义为改进某事物,使其发挥其全部潜力的过程。这也适用于机器学习。在ML的世界里,优化本质上是试图为某个数据集找到最佳的参数组合。这基本上是机器学习的“学习”部分。
我将讨论两种最常见的算法:梯度下降法和标准方程。
梯度下降
梯度下降是一种优化算法,旨在寻找函数的最小值。它通过在梯度的负方向上迭代地采取步骤来实现这个目标。在我们的例子中,梯度下降将通过移动函数切线的斜率来不断更新权重。
梯度下降的一个具体例子

为了更好地说明梯度下降,让我们看一个简单的例子。想象一个人在山顶上,他/她想爬到山底。他们可能会做的是环顾四周,看看应该朝哪个方向迈出一步,以便更快地下来。然后,他们可能会朝这个方向迈出一步,现在他们离目标更近了。然而,它们在下降时必须小心,因为它们可能会在某一点卡住,所以我们必须确保相应地选择我们的步长。
同样,梯度下降的目标是最小化函数。在我们的例子中,这是为了使我们的模型的成本最小化。它通过找到函数的切线并朝那个方向移动来实现这一点。算法“步长”的大小是由已知的学习速率来定义的。这基本上控制着我们向下移动的距离。使用此参数,我们必须注意两种情况:
-
学习速率太大,算法可能无法收敛(达到最小值)并在最小值附近反弹,但永远不会达到该值
-
学习率太小,算法将花费太长时间才能达到最小值,也可能会“卡”在一个次优点上。
我们还有一个参数,它控制算法迭代数据集的次数。
从视觉上看,该算法将执行以下操作:
由于此算法对机器学习非常重要,让我们回顾一下它的作用:
-
随机初始化权重。这叫做随机初始化
-
然后,模型使用这些随机权重进行预测
-
模型的预测是通过成本函数来评估的
-
然后模型运行梯度下降,找到函数的切线,然后在切线的斜率上迈出一步
-
该过程将重复N次迭代,或者如果满足某个条件。
梯度下降法的优缺点
优点:
-
很可能将成本函数降低到全局最小值(非常接近或=0)
-
最有效的优化算法之一
缺点:
-
在大型数据集上可能比较慢,因为它使用整个数据集来计算函数切线的梯度
-
容易陷入次优点(或局部极小值)
-
用户必须手动选择学习速率和迭代次数,这可能很耗时
既然已经介绍了梯度下降,现在我们来介绍标准方程。
标准方程(Normal Equation)
如果我们回到我们的例子中,而不是一步一步地往下走,我们将能够立即到达底部。标准方程就是这样。它利用线性代数来生成权重,可以在很短的时间内产生和梯度下降一样好的结果。
标准方程的优缺点
优点
-
无需选择学习速率或迭代次数
-
非常快
缺点
-
不能很好地扩展到大型数据集
-
倾向于产生好的权重,但不是最佳权重

特征缩放
这是许多机器学习算法的重要预处理步骤,尤其是那些使用距离度量和计算(如线性回归和梯度下降)的算法。它本质上是缩放我们的特征,使它们在相似的范围内。把它想象成一座房子,一座房子的比例模型。两者的形状是一样的(他们都是房子),但大小不同(5米!=500米)。我们这样做的原因如下:
-
它加快了算法的速度
-
有些算法对尺度敏感。换言之,如果特征具有不同的尺度,则有可能将更高的权重赋予具有更高量级的特征。这将影响机器学习算法的性能,显然,我们不希望我们的算法偏向于一个特征。
为了演示这一点,假设我们有三个特征,分别命名为A、B和C:
- 缩放前AB距离=>

- 缩放前BC距离=>

- 缩放后AB距离=>

- 缩放后BC的距离=>

我们可以清楚地看到,这些特征比缩放之前更具可比性和无偏性。
从头开始编写线性回归
好吧,现在你一直在等待的时刻;实现!
注意:所有代码都可以从这个Github repo下载。但是,我建议你在执行此操作之前先遵循教程,因为这样你将更好地理解你实际在编写什么代码:
首先,让我们做一些基本的导入:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
是的,这就是所有需要导入的了!我们使用的是numpy作为数学实现,matplotlib用于绘制图形,以及scikitlearn的boston数据集。
# 加载和拆分数据
data = load_boston()
X,y = data['data'],data['target']
接下来,让我们创建一个定制的train_test_split函数,将我们的数据拆分为一个训练和测试集:
# 拆分训练和测试集
def train_test_divide(X,y,test_size=0.3,random_state=42):
np.random.seed(random_state)
train_size = 1 - test_size
arr_rand = np.random.rand(X.shape[0])
split = arr_rand < np.percentile(arr_rand,(100*train_size))
X_train = X[split]
y_train = y[split]
X_test = X[~split]
y_test = y[~split]
return X_train, X_test, y_train, y_test
X_train,X_test,y_train,y_test = train_test_divide(X,y,test_size=0.3,random_state=42)
基本上,我们在进行
-
得到测试集大小。
-
设置一个随机种子,以确保我们的结果和可重复性。
-
根据测试集大小得到训练集大小
-
从我们的特征中随机抽取样本
-
将随机选择的实例拆分为训练集和测试集
我们的成本函数
我们将实现MSE或均方误差,一个用于回归任务的常见成本函数:

def mse(preds,y):
m = len(y)
return 1/(m) * np.sum(np.square((y - preds)))
-
M指的是训练实例的数量
-
yi指的是我们标签向量中的一个实例
-
preds指的是我们的预测
为了编写干净、可重复和高效的代码,并遵守软件开发实践,我们将创建一个线性回归类:
class LinReg:
def __init__(self,X,y):
self.X = X
self.y = y
self.m = len(y)
self.bgd = False
- bgd是一个参数,它定义我们是否应该使用批量梯度下降。
现在我们将创建一个方法来添加截距项:
def add_intercept_term(self,X):
X = np.insert(X,1,np.ones(X.shape[0:1]),axis=1).copy()
return X
这基本上是在我们的特征开始处插入一个列。它只是为了矩阵乘法。
如果我们不加上这一点,那么我们将迫使超平面通过原点,导致它大幅度倾斜,从而无法正确拟合数据
缩放我们的特征:

def feature_scale(self,X):
X = (X - X.mean()) / (X.std())
return X
接下来,我们将随机初始化权重:
def initialise_thetas(self):
np.random.seed(42)
self.thetas = np.random.rand(self.X.shape[1])
现在,我们将使用以下公式从头开始编写标准方程:

def normal_equation(self):
A = np.linalg.inv(np.dot(self.X.T,self.X))
B = np.dot(self.X.T,self.y)
thetas = np.dot(A,B)
return thetas
基本上,我们将算法分为三个部分:
-
我们得到了X转置后与X的点积的逆
-
我们得到重量和标签的点积
-
我们得到两个计算值的点积
这就是标准方程!还不错!现在,我们将使用以下公式实现批量梯度下降:
def batch_gradient_descent(self,alpha,n_iterations):
self.cost_history = [0] * (n_iterations)
self.n_iterations = n_iterations
for i in range(n_iterations):
h = np.dot(self.X,self.thetas.T)
gradient = alpha * (1/self.m) * ((h - self.y)).dot(self.X)
self.thetas = self.thetas - gradient
self.cost_history[i] = mse(np.dot(self.X,self.thetas.T),self.y)
return self.thetas
在这里,我们执行以下操作:
-
我们设置alpha,或者学习率,和迭代次数
-
我们创建一个列表来存储我们的成本函数历史记录,以便以后在折线图中绘制
-
循环n_iterations 次,
-
我们得到预测,并计算梯度(函数切线的斜率)。
-
我们更新权重以沿梯度负方向移动
-
我们使用我们的自定义MSE函数记录值
-
重复,完成后,返回结果
让我们定义一个拟合函数来拟合我们的数据:
def fit(self,bgd=False,alpha=0.158,n_iterations=4000):
self.X = self.add_intercept_term(self.X)
self.X = self.feature_scale(self.X)
if bgd == False:
self.thetas = self.normal_equation()
else:
self.bgd = True
self.initialise_thetas()
self.thetas = self.batch_gradient_descent(alpha,n_iterations)
在这里,我们只需要检查用户是否需要梯度下降,并相应地执行我们的步骤。
让我们构建一个函数来绘制成本函数:
def plot_cost_function(self):
if self.bgd == True:
plt.plot(range((self.n_iterations)),self.cost_history)
plt.xlabel('No. of iterations')
plt.ylabel('Cost Function')
plt.title('Gradient Descent Cost Function Line Plot')
plt.show()
else:
print('Batch Gradient Descent was not used!')
最后一种预测未标记实例的方法:
def predict(self,X_test):
self.X_test = X_test.copy()
self.X_test = self.add_intercept_term(self.X_test)
self.X_test = self.feature_scale(self.X_test)
predictions = np.dot(self.X_test,self.thetas.T)
return predictions
现在,让我们看看哪个优化产生了更好的结果。首先,让我们试试梯度下降:
lin_reg_bgd = LinReg(X_train,y_train)
lin_reg_bgd.fit(bgd=True)
mse(y_test,lin_reg_bgd.predict(X_test))
OUT:
28.824024414708344
让我们画出我们的函数,看看成本函数是如何减少的:
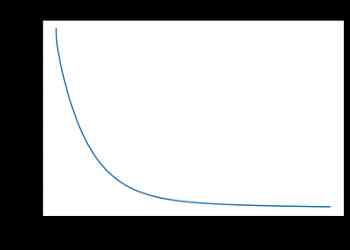
所以我们可以看到,在大约1000次迭代时,它开始收敛。
现在的标准方程是:
lin_reg_normal = LinReg(X_train,y_train)
lin_reg_normal.fit()
mse(y_test,lin_reg_normal.predict(X_test))
OUT:
22.151417764247284
所以我们可以看到,标准方程的性能略优于梯度下降法。这可能是因为数据集很小,而且我们没有为学习率选择最佳参数。
未来
-
大幅度提高学习率。会发生什么?
-
不应用特征缩放。有区别吗?
-
尝试研究一下,看看你能不能实现一个更好的优化算法。在测试集中评估你的模型
写这篇文章真的很有趣,虽然有点长,但我希望你今天学到了一些东西。
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4703067
边栏推荐
猜你喜欢


随机推荐
Electron应用使用electron-builder配合electron-updater实现自动更新
[译] 5个Vuex插件,给你的下个VueJS项目
不能再被问住了!ReentrantLock 源码、画图一起看一看!
高级 Vue 组件模式 (3)
面经手册 · 第16篇《码农会锁,ReentrantLock之公平锁讲解和实现》
ThreadLocal原理大解析
API 测试利器 WireMock
深度解读智能推荐系统搭建之路 | 会展云技术揭秘
9.2.2 parse and parseconfiguration method (XML configuration builder analysis) - SSM in depth analysis and project practice
面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
深入了解JS数组的常用方法
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
技术总监,送给刚毕业的程序员们一句话——做好小事,才能成就大事
被产品经理怼了,线上出Bug为啥你不知道
基于 Flink SQL CDC 的实时数据同步方案
Vue.js移动端左滑删除组件
普通算法面试已经Out啦!机器学习算法面试出炉 - kdnuggets
Clean架构能够解决哪些问题? - jbogard
6.9.2 session flashmapmanager redirection management
Azure DevOps 扩展之 Hub 插件的菜单权限控制配置